
python爬虫应用:每日要闻邮件发送脚本
爬虫的编写参考我的另一篇博客:https://www.cnblogs.com/OverloadBachPunk/p/14472611.html
新版本的主要加入了以下功能:
- 基于html进行了样式的编辑,比如表格、分级标题、列表等
- 更多的信息爬取
主要问题在于中国天气网的服务器不够稳定,有时候爬取会失败。但是天气数据又是必须的,没法做一个错误抛出机制。之后可能考虑找一个更加稳定的网站来爬取天气信息。
html格式写入
def h1title(string):
html = '<h1 style="color: var(--title-color); box-sizing: border-box; break-after: avoid-page; break-inside: avoid; orphans: 2; margin: 6rem 0px 3rem; padding: 0px; width: inherit; position: relative; font-size: 3rem; font-family: SimSun; font-weight: 800; line-height: 3rem; text-align: center; text-transform: uppercase;">{}</h1>'.format(string)
return html
def h2title(string):
html = '<h2 style="color: var(--title-color); box-sizing: border-box; break-after: avoid-page; break-inside: avoid; orphans: 2; padding: 0px; width: inherit; position: relative; font-size: 2rem; margin: 4rem auto; font-family: SimSun; font-weight: 800; line-height: 3rem; text-align: center; text-transform: uppercase;">{}</h2>'.format(string)
return html
def h3title(string):
html = '<h4 style="color: var(--title-color); box-sizing: border-box; break-after: avoid-page; break-inside: avoid; orphans: 2; padding: 0px; width: inherit; position: relative; font-size: 1.5rem; margin: 3rem 0px; font-family: SimSun; font-weight: 600;">{}</h4>'.format(string)
return html
def plaintext(string):
html = '<p style="color: var(--text-color); box-sizing: border-box; line-height: inherit; orphans: 4; margin: 0px; padding: 0px; white-space: pre-wrap; width: inherit; position: relative;">{}</p>'.format(string)
return html
def urltext(string, url):
html = '<p style="color: var(--text-color); box-sizing: border-box; line-height: inherit; orphans: 4; margin: 0px; padding: 0px; white-space: pre-wrap; width: inherit; position: relative;"><a href="{}">{}</a></p>'.format(url, string)
return html
def quote(string):
html ='<blockquote style="margin: 0.8em 0px 0.8em 2em; padding: 0px 0px 0px 0.7em; border-left: 2px solid rgb(221, 221, 221);" formatblock="1"><i style=""><font color="#999999">{}</font></i></blockquote>'.format(string)
return html
def tablehead(thead):
html = ''
head = '<thead style="box-sizing: border-box; display: table-header-group;"><tr style="box-sizing: border-box; break-inside: avoid; break-after: auto;">'
end = '</tr></thead>'
html += head
trtemple = '<th style="box-sizing: border-box; margin: 0; border-bottom: 0px; padding: .5rem 1rem; background: var(--thead-bg); border: 1px solid var(--thead-bg);">{}</th>'
for each in thead:
html += trtemple.format(each)
html += end
return html
def tablebody(tbody):
html = ''
head = '<tbody style="box-sizing: border-box;">'
end = '</tbody>'
html += head
tdtemple = '<td bgcolor="var(--tbody-bg)" style="box-sizing: border-box; margin: 0; position: relative; overflow: hidden; padding: 0.5rem 1rem; background-color: var(--tbody-bg); border: 1px solid var(--thead-bg); color: var(--text-color);">{}</td>'
for row in tbody:
html += '<tr style="box-sizing: border-box; break-inside: avoid; break-after: auto;">'
for each in row:
html += tdtemple.format(each)
html += '</td>'
html += end
return html
def table(thead, tbody): #tablehead是一个一维数组,tablebody是一个二维数组
html = ''
head = '<figure style="color: var(--text-color); box-sizing: border-box; overflow-x: auto; margin: 0px; padding: 0px; display: block;"><table align="left" style="box-sizing: border-box; border-collapse: collapse; border-spacing: 0; overflow: auto; break-inside: auto; text-align: left; margin: 1.5rem auto; width: 98%;" width="98%">'
end = '</table></figure>'
html += head
html += tablehead(thead)
html += tablebody(tbody)
html += end
return html
def ul(urllist, stringlist):
head = '<ul style="color: var(--text-color); box-sizing: border-box; margin: 1.5rem auto 1.5rem 1.5rem; padding: 0px; position: relative; list-style: disc;">'
end = '</ul>'
html = ''
html += head
for each in zip(urllist, stringlist):
html += li(each[0], each[1])
html += end
return html
def li(url, string):
if url == '':
html = '<li style="box-sizing: border-box; margin: 0; position: relative; padding: 0; white-space: pre-wrap; margin-left: 1rem;">{}</li>'.format(string)
else:
html = '<li style="box-sizing: border-box; margin: 0; position: relative; padding: 0; white-space: pre-wrap; margin-left: 1rem;"><a href="{}">{}</a></li>'.format(url, string)
return html
def br():
return '<hr style="box-sizing: border-box;">'
def insertImg(url):
html = '<p style="box-sizing: border-box; line-height: inherit; orphans: 4; margin-top: 1rem; margin-bottom: 1rem; padding: 0; margin: 1rem auto; white-space: pre-wrap; width: inherit; position: relative;"><img src="{}" referrerpolicy="no-referrer" style="box-sizing: border-box; max-width: 100%; vertical-align: middle; border: 0; display: block; margin: 1.5rem auto; box-shadow: var(--img-shadow); border-radius: 5px;"></p>'.format(url)
return html
def htmlHead():
return '<div id="original-content"><div class="is-node" id="write" style="box-sizing: border-box; margin: 0px auto; height: auto; width: inherit; word-break: normal; overflow-wrap: break-word; position: relative; white-space: normal; overflow-x: visible; padding-top: 40px; font-family: var(--base-font); font-weight: 400; font-size: 1rem; line-height: 2rem; background: var(--write-bg); max-width: 914px; text-align: justify;">'
def htmlEnd():
return '</div></div>'
爬虫脚本
import requests
from lxml import etree
import json
import re
from ast import literal_eval
import datetime
import time
import random
from writehtml import *
def get_weather():
headers_weather = {
'Host': 'www.weather.com.cn',
'Referer': 'http://www.weather.com.cn/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81'
}
url = "http://www.weather.com.cn/weather/101010100.shtml" #海淀
res = requests.get(url, headers=headers_weather)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
weather = re.findall('"1d":(.*?),"23d"', res.text)[0]
weather = literal_eval(weather)
weather_list = []
for each in weather:
hourlist = each.split(',')
weather_list.append([hourlist[0]]+hourlist[2:-1])
return weather_list
def get_baidutop10():
headers = {
'Host': 'top.baidu.com',
'Referer': 'https://www.baidu.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81'
}
url = 'http://top.baidu.com/?fr=mhd_card'
res = requests.get(url, headers=headers)
res.encoding = 'gb2312'
html = etree.HTML(res.text)
top10_title = html.xpath('//*[@id="hot-list"]/li/a[1]/@title')
top10_link = html.xpath('//*[@id="hot-list"]/li/a[1]/@href')
return top10_link, top10_title
def get_weibotop10():
url = 'https://s.weibo.com/top/summary'
res = requests.get(url)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
top10_link = html.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[position()<=11]/td[2]/a/@href')
top10_title = html.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[position()<=11]/td[2]/a/text()')
top10_link = list(map(lambda x: 'https://s.weibo.com/'+x, top10_link))
return top10_link, top10_title
def get_huputop10():
headers_hupu = {
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81'
}
url = 'https://bbs.hupu.com/all-gambia'
res = requests.get(url, headers=headers_hupu)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
top10_title = html.xpath('//div[@class="bbsHotPit"]/div/ul/li[position()<=3]/span[1]/a/@title')[:10]
top10_link = html.xpath('//div[@class="bbsHotPit"]/div/ul/li[position()<=3]/span[1]/a/@href')[:10]
top10_link = list(map(lambda x: 'https://bbs.hupu.com'+x, top10_link))
return top10_link, top10_title
def get_ezutop10():
headers = {
'Host': 'www.douban.com',
'Referer': 'https://www.douban.com/group/blabla/?type=elite',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81'
}
url = 'https://www.douban.com/group/blabla/?type=essence'
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
top10_title = html.xpath('//table[@class="olt"]/tr[position()<=11]/td[1]/a/@title')
top10_link = html.xpath('//table[@class="olt"]/tr[position()<=11]/td[1]/a/@href')
return top10_link, top10_title
def get_rmtop10():
url = 'http://www.people.com.cn/GB/59476/index.html'
res = requests.get(url)
res.encoding = 'gb2312'
html = etree.HTML(res.text)
top10_link = html.xpath('//table[@id="ta_1"]/tr/td/li/a/@href')
top10_title = html.xpath('//table[@id="ta_1"]/tr/td/li/a/text()')
return top10_link, top10_title
def get_todayhistory(month, day): # month和day是字符串格式,带零。(‘03’,’08‘)
url = 'https://baike.baidu.com/cms/home/eventsOnHistory/{}.json'.format(month)
headers = {
'Host': 'baike.baidu.com',
'Referer': 'https://baike.baidu.com/calendar/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81',
'X-Requested-With': 'XMLHttpRequest'
}
res = requests.get(url, headers=headers)
content = json.loads(res.text)
history_list = []
for each in content[month][month+day]:
year = each['year']
title = ''.join(re.findall(r'[\u4e00-\u9fa5]', each['title']))
history_list.append([year, title])
return history_list
def get_randomsentence():
url = 'https://v2.jinrishici.com/sentence'
headers = {
'cookie': 'X-User-Token=9cA/6FT0nadkWlwpBAMfp8tVqHOihW0m',
}
res = requests.get(url, headers=headers)
content = json.loads(res.text)
note = content["data"]["content"]+' '+'————'+'《'+content["data"]["origin"]["title"]+'》, '+content["data"]["origin"]["author"]+', '+content["data"]["origin"]["dynasty"]
return note
def get_fastival(date): #日期格式:xx月xx日,3月8日,不带零
url = 'http://www.jieriya.com/'
res = requests.get(url)
res.encoding = 'gb2312'
url_list = re.findall('<li class=\"sj\">3月8日</li><li class=\"jr\"><a target=\"_blank\" href=\"../(.*?)\">', res.text)[:3]
name_list = re.findall('<li class=\"sj\">3月8日</li><li class=\"jr\"><a target=\"_blank\" href=\"../jieri.asp\?id=[0-9]*\">(.*?)</a>', res.text)[:3]
page_url = url+url_list[0]
page_res = requests.get(page_url)
page_res.encoding = 'gb2312'
html = etree.HTML(page_res.text)
text = html.xpath('//*[@id="content"]/div[2]/p[2]/text()')[0]
text = text.strip()
return url_list, name_list, text
def get_thing():
url = 'https://sbike.cn/'
res = requests.get(url)
res.encoding = 'utf-8'
order = int(12*random.random())+1
html = etree.HTML(res.text)
title = html.xpath('//li[%s]/h3[1]/a/text()'%(order))[0]
describe = html.xpath('//li[%s]/h4/text()'%(order))
img_url = url[:-1] + html.xpath('//li[%s]/a/img/@src'%(order))[0]
return title, describe, img_url
def write_email():
today = datetime.datetime.today()
week_day_dict = {
0 : '星期一',
1 : '星期二',
2 : '星期三',
3 : '星期四',
4 : '星期五',
5 : '星期六',
6 : '星期天',
}
week = week_day_dict[today.weekday()]
year = time.strftime("%Y", time.localtime())
month = time.strftime("%m", time.localtime())
day = time.strftime("%d", time.localtime())
md_date = '%d月%d日'%(int(month), int(day))
#with open('today_info'+' '+today.strftime('%Y-%m-%d')+'.txt', 'a') as f:
weather_list = get_weather()
todayhistory_list = get_todayhistory(month, day)
wbtop_list_url, wbtop_list = get_weibotop10()
hptop_list_url, hptop_list = get_huputop10()
ezutop_list_url, ezutop_list = get_ezutop10()
bdtop_list_url, bdtop_list = get_baidutop10()
rmtop_list_url, rmtop_list = get_rmtop10()
fastival_list_url, fastival_list, text = get_fastival(md_date)
sentence = get_randomsentence()
thing_title, thing_describe, thing_img_url = get_thing()
html = ''
html += htmlHead()
html += h1title('今日要闻')
html += plaintext('今天是%d年%d月%d日,'%(int(year), int(month), int(day))+week+'。')
html += '<br>'
if (len(fastival_list) != 0):
html += plaintext('今天是<b>%s</b>。'%(fastival_list[0])+text)
html += quote(sentence)
html += br()
html += h2title('今日天气')
html += table(['时间','天气','温度','风向','风级'], weather_list)
html += br()
html += h2title('今日热点')
html += h3title('百度新闻')
html += ul(bdtop_list_url, bdtop_list)
html += h3title('人民网')
html += ul(rmtop_list_url, rmtop_list)
html += h3title('微博热搜')
html += ul(wbtop_list_url, wbtop_list)
html += h3title('虎扑步行街')
html += ul(hptop_list_url, hptop_list)
html += h3title('豆瓣鹅组')
html += ul(ezutop_list_url, ezutop_list)
html += br()
html += h2title('每日百科')
html += h3title('历史上的今天')
html += table(['年份','事件'], todayhistory_list)
html += h3title('每日识物:'+thing_title)
html += insertImg(thing_img_url)
for each in thing_describe:
html += plaintext(each)
html += '<br>'
html += htmlEnd()
return html
def main():
html = write_email()
#today = datetime.datetime.today()
#with open('today_info'+' '+today.strftime('%Y-%m-%d')+'.txt', 'a') as f:
with open('/home/lin/文档/today_info.html', 'a') as f:
f.write(html)
main()
邮件效果
网页端
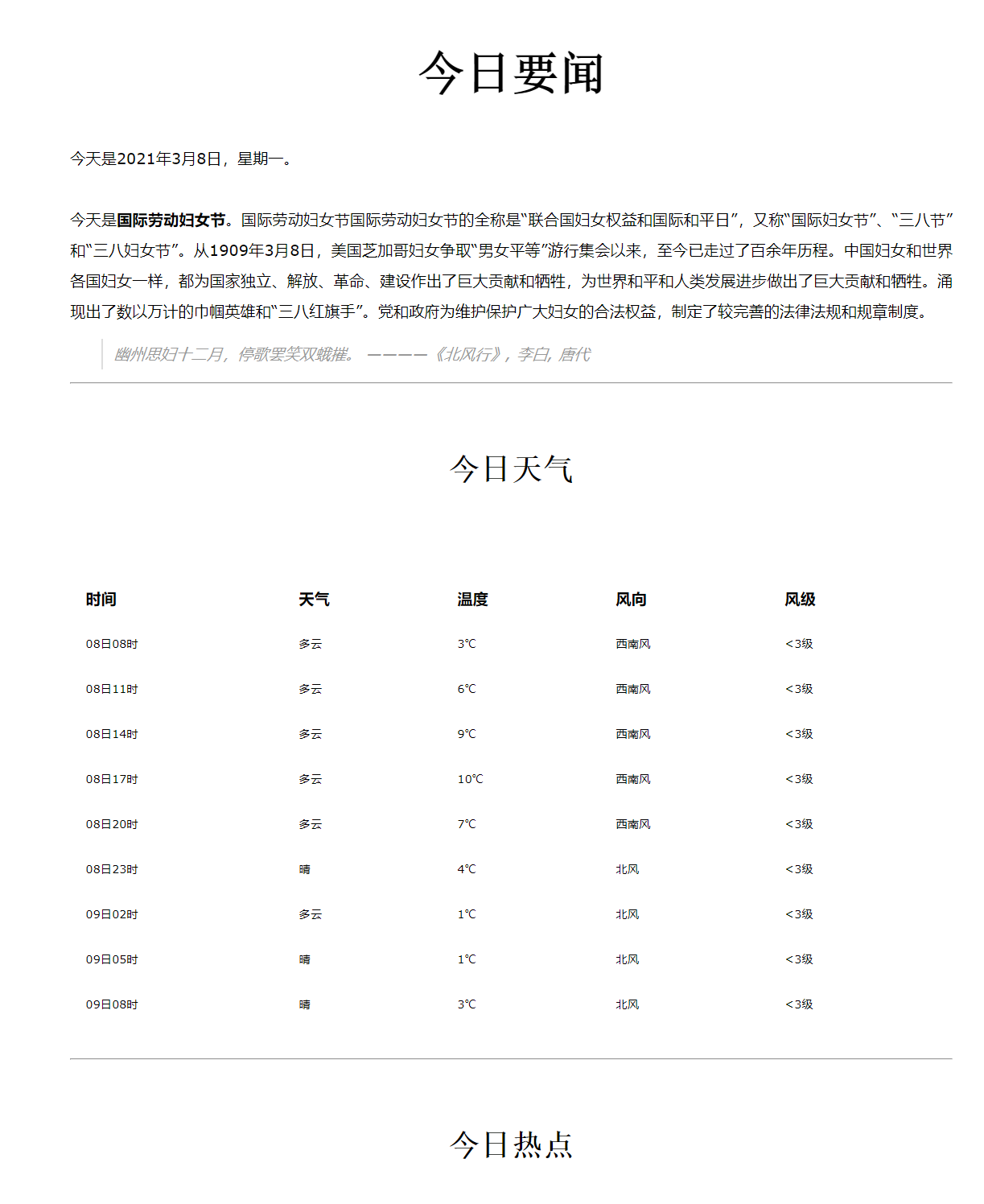
移动端


 浙公网安备 33010602011771号
浙公网安备 33010602011771号