【信息学奥赛一本通 提高组】第三章 深搜的剪枝技巧
深度优先搜索的优化技巧
1、优化搜索顺序
在一些搜索问题中,搜索树的各个层次,各个分支之间的顺序不是固定的。不同的搜索顺序会产生不同的搜索树形态,其规模大小也相差甚远。
2、排除等效冗余
在搜索过程中,如果我们能够判定从搜索树的当前节点上沿着某几条不同分支到达的子树是等效的,那么只需要对其中的一条分支执行搜索。
3、可行性剪枝
在搜索过程中,及时对当前状态进行检查,如果发现分支已经无法到达递归边界,就执行回溯。这好比我们在道路上行走时,远远看到前方是一个死胡同,就应该立即折返绕路,而不是走到路的尽头再返回。
某些题目条件的范围限制是一个区间,此时可行性剪枝也被称为”上下界剪枝“
4、最优化剪枝
在最优化问题的搜索过程中,如果当前花费的代价已经超过当前搜到的最优解,那么无论采取多么优秀的策略到达递归边界,都不可能更新答案。此时可以停止对当前分支的搜索,执行回溯。
5、记忆化
可以记录每个状态的搜索结果,在重复遍历一个状态时直接检索并返回。这好比我们对图进行深度优先遍历时标记一个节点是否已经被访问过。
【例题1】数的划分(可行性剪枝,上下界剪枝)
题目描述
输入
输出
样例输入
7 3
样例输出
4
【思路】:
本题就是求把数字n无序划分成k份的方案数。也就是求方程x1+x2+……+xk = n,1<=x1<=x2<=……xk的解数。
搜索的方法是依次枚举x1,x2……xk的值,然后判断。如果这样直接搜索,程序的运行速度是非常慢的。但由于本题的数据规模比较小,如果控制好扩展结点的“上界”和“下界”,也是能够很快得出解的。
约束条件:
1、由于分解数不考虑顺序,因此我们设定分解数依次递增,所以扩展结点时的“下界”应是不小于前一个扩展结点的值,即a[i-1]<=a[i]
2、假设我们将n已经分解成了a[1]+a[2]+……+a[i-1],则a[i]的最大值为将i~k这k-i+1份平均划分,即设m=n-(a[1]+a[2]+……+a[i-1]),则a[i]<=m/(k-i+1),所以扩展结点的“上界”为 m/(k-i+1)


1 #include<bits/stdc++.h> 2 using namespace std; 3 int n,m,ans; 4 int a[10]; 5 void dfs(int k){ //分第k份 6 if( n==0 ) return ; 7 if( k == m ) { 8 if( n >= a[k-1] ) 9 ans ++; 10 return ; 11 } 12 for (int i=a[k-1];i<=n/(m-k+1);i++){ //第k份的上下界 13 a[k] = i ; //第k份的值 14 n-=i; 15 dfs(k+1); 16 n+=i; 17 } 18 } 19 int main() 20 { 21 scanf("%d%d",&n,&m); 22 a[0] = 1 ; //初始值起步为1 23 dfs(1); 24 printf("%d\n",ans); 25 return 0; 26 }
【例题2】生日蛋糕
题目描述

设从下往上数第i(1<=i<=M)层蛋糕是半径为Ri, 高度为Hi的圆柱。当i<M时,要求Ri>Ri+1且Hi>Hi+1。
由于要在蛋糕上抹奶油,为尽可能节约经费,我们希望蛋糕外表面(最下一层的下底面除外)的面积Q最小。
令Q= Sπ,请编程对给出的N和M,找出蛋糕的制作方案(适当的Ri和Hi的值),使S最小。(除Q外,以上所有数据皆为正整数)
输入
输出
样例输入
100
2
样例输出
68
提示
体积V=πR2H
侧面积A’=2πRH
底面积A=πR2
【思路】:
搜索框架,从下往上搜索,(最上面的一层是第1层),从下往上搜索,枚举搜索面对的状态有:正在搜索蛋糕第dep层,当前外表面面积S,当前体积V,第dep+1层的高度和半径。不妨用数组h和r分别记录每层的高度和半径。
整个蛋糕的“上表面”面积之和等于最底层的圆面积,可以在第M层直接累加到S中,这样,第M-1层往上的搜索,只需要计算侧面积。
剪枝:
1、上下界剪枝:
在第dep层时,只在下面的范围内枚举半径和高度即可。
首先枚举R∈[ dep , min( {sqrt(N-V)} , R[dep+1] - 1 ) ]
其次枚举H∈[ dep , min( { (N-V)/ R2 }, h[dep+1]-1) ]
上面两个区间右边界中的式子可以通过圆柱体积公式 πR2H = π(N-v)得到
2、最优化搜索:
在上面确定的范围中,使用倒序枚举。
3、可行性剪枝:
可以预处理出从上往下前i(1≤i≤M)层的最小体积和侧面积,显然,当第1~i层的半径分别取1,2,3,……i,高度也分别去1,2,3,……i时,有最小体积和侧面积。
如果当前体积v加上1~dep-1层的最小体积大于N,则可以剪枝。
4、最优化剪枝一
如果当前表面积S加上1~dep-1层的最小侧面积大于已经搜到的结果,剪枝。
5、最优化剪枝二:
利用h与r数组,1~dep-1层的体积可表示为n-v = Σ H[k] * R[k]2 ,1~dep-1层的表面积可表示为2 *Σ H[i] *R[i]
∵2 *Σ H[i] *R[i] = ( 2/r[dep] ) * Σ H[i] *R[i] * r[dep] >= ( 2/r[dep] ) * Σ H[i] *R[i]2 其中Σ H[i] *R[i]2 = n-v
∴2 *Σ H[i] *R[i] >= 2(n-v)/R[dep]
∴当2(n-v)/R[dep] + s 大于已经搜到的结果时,可以剪枝。
加入以上五个剪枝后,搜索算法就可以快速求出该问题的最优解。
实际上,搜索算法面对的状态可以看做一个多元组,其中每一元都是问题状态空间的一个”维度“,例如,本题中的层数dep、表面积S、体积V、第dep+1层的高度和半径就构成状态空间中的五个维度,其中每一个维度发生变化,都会移动状态空间中的另一个”点“。这些维度通常在题目描述中也有所体现,它们一般在输入变量、限制条件、待求解变量等非常关键的位置出现。读者一定要注意提取这些”维度“,从而设计出合适的搜索框架。
搜索过程中的剪枝,其实是针对每个”维度“,与该维度的边界条件,加以缩放、推导,得出一个相应的不等式,以减少搜索树分支的扩张。例如,本题中的剪枝1、剪枝3和剪枝4,就是考虑与半径、高度、体积、表面积这些维度的上下界进行比较而直接得到的。
为了进一步提高剪枝的效果,除了当前花费的”代价“之外,我们还可以对未来至少需要花费的代价进行预算,这样更容易接近每个维度的上下界。例如,本题中求前dep-1层最小体积、最小侧面积。剪枝5则通过表面积与体积之间的关系,对不等式进行缩放。
1 #include<bits/stdc++.h> 2 using namespace std; 3 int n,m; 4 int a[22],b[22],ans=0x7fffffff; //当前层数的最小的体积,最小的面积 5 6 // 当前的体积,面积,层数(倒序),上一次计算的半径,高度 7 // 搜索方向是从最小层到最上层的顺序 8 void dfs(int V,int S,int dep,int R,int H){ 9 if ( dep == 0 ){ //到达最上层 10 if( V == n ) { //当前的体积为V 11 ans = min(ans,S); 12 } 13 return ; 14 } 15 //剪枝部分 16 17 //体积+上一层数的最小值 > n 18 if( V + a[dep-1] > n ) 19 return ; 20 21 //面积+上一层数的最小值 >= 过程中的最小值 22 if( S + b[dep-1] >= ans ) 23 return ; 24 25 //面积+(由体积推导的面积的最小值)>= 过程中的最优值 26 if( S + 2*(n-V)/R >= ans ) 27 return ; 28 29 30 for(int r=min((int)(sqrt(n-V))+1,R-1); r>=dep ; r-- ){ 31 //从上往下看,上视图看到的面积由最外层的面积决定 32 if( dep == m ){ 33 S = r*r ; 34 } 35 for(int h=min((n-V-a[dep-1])/(r*r),H-1); h>=dep ;h-- ){ 36 dfs( V+r*r*h,S+2*r*h,dep-1,r,h); 37 } 38 } 39 } 40 int main() 41 { 42 scanf("%d%d",&n,&m); 43 for(int i=1;i<=20;i++){ 44 a[i] = i*i*i + a[i-1] ; 45 b[i] = i*i*2 + b[i-1] ; 46 } 47 dfs(0,0,m,n+1,n+1); 48 printf("%d\n",ans==0x7fffffff? 0 :ans ); 49 return 0; 50 }
【例题3】小木棍(最优性剪枝,可行性剪枝)
题目描述
现在,他想把小木棍拼接成原来的样子,但是却忘记了自己开始时有多少根木棍和它们的长度。
给出每段小木棍的长度,编程帮他找出原始木棍的最小可能长度。
输入
第一行为一个单独的整数N表示看过以后的小木柜的总数,其中N≤60,第二行为N个用空个隔开的正整数,表示N跟小木棍的长度。
输出
样例输入
9
5 2 1 5 2 1 5 2 1
样例输出
6
【思路】:
从题意来看,要得到原始最短木棍的可能长度,可以按照分段数的长度,依次枚举所有的可能长度len,每次枚举len时,用深度搜索判断是否能用截断后的木棍拼合出整个len,能用的话,找出最小的len即可。对于1s的时间限制,用不加任何剪枝的深度搜索时,时间效率为指数级,效率非常低,程序运行将严重超时。对于此题,可以从可行性和最优性上加以剪枝。
从最优性方面分析,可以做以下两种剪枝:
1、设所有木棍的长度和是sum,那么原长度(也就是答案)一定能够被sum整除,不然就没法拼了,即一定拼出整数根。
2、木棍原来的长度一定大于等于所有木棍最长的那根。
综合上述的两点,可以确定原木棍的商都len在最长木棍的长度与sum之间,且sum能被len整除。所以,在搜索原木棍的长度时,可以设定为截断后所有木棍最长的长度开始,每次增加长度后,必须能整除sum。这样可以有效地优化程序。
从可行性方面分析,可以再做以下七种剪枝:
1、一根长木棍肯定比几根短木棍拼成同样长度的用处小,即短小的可以更灵活组合,所以可以对输入的所有木棍按长度从大到小排序。
2、在截断后的排序好的木棍中,当用木棍i拼合原始木棍时,可以从第 i+1 后的木棍开始搜。因为根据优化1,i前面的木棍已经用过了。
3、用当前最长长度的木棍开始搜,如果拼不出当前设定的原木棍长度len,则直接返回,换一个原始木棍长度len。
4、相同长度的木棍不要搜索多次。用当前长度的木棍搜下去得不到结果时,用一支同样长度的还是得不到结果,所以,可以提前返回。
5、判断搜到的几根木棍组成的长度是否大于原始长度len,如果大于,没必要搜下去,可以提前返回。
6、判断当前剩下的木棍棍数是否够拼成木棍,如果不够,肯定拼合不成功,直接返回。
7、找到结果后,在能返回的地方马上返回上一层的递归出。
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 70; 4 int n,sum,len,tot; 5 int a[N],vis[N]; 6 bool cmp(int u,int v){ 7 return u > v ; 8 } 9 // 第k根,还需要now的长度,枚举第pos根木棍 10 bool dfs(int k,int now,int pos){ 11 12 if( k == tot + 1 ) return true; //已经拼完了前tot根,所以返回答案 13 14 if( now == 0 ){ 15 // 如果当前木棍已经拼接好,接着拼下一根,直到拼完tot根为止 16 return dfs(k+1,len,1); 17 } 18 // 剪枝2,如果当前用了第i个,则从i+1根开始拼 19 for(int i=pos;i<=n;i++){ 20 if( !vis[i] && a[i]<=now ){ // 选择当前木棍,必须是没选中过,同时适合拼接下去 21 vis[i] = 1 ; 22 if( dfs(k,now-a[i],i+1) ) return true; 23 vis[i] = 0 ; 24 if( now == len || now == a[i] ) // 剪枝3、如果拼不出来直接返回,原因是不可能再继续下去 25 return false; 26 while( a[i] == a[i+1] ) i++; // 剪枝4,相同长度不要多次搜索 27 } 28 } 29 return false; 30 } 31 int main() 32 { 33 scanf("%d",&n); 34 for(int i=1;i<=n;i++){ 35 scanf("%d",&a[i]); 36 sum += a[i] ; 37 } 38 sort ( a+1 , a+1+n , cmp ); 39 // 最优性方面分析 40 41 for(int i=a[1];i<=sum;i++){ //长度下界一定是所有木棍中最长的。 42 if( sum%i == 0 ){ //答案一定是能整除sum的。 43 memset(vis,0,sizeof vis) ; 44 len = i ; // 设为全局变量,木棍的长度 45 tot = sum/i; // 木棍的数目 46 if(dfs(1,len,1)){ 47 printf("%d\n",len); 48 return 0; 49 } 50 } 51 } 52 return 0; 53 }
【例题4】Addition Chains (ZOJ 1937)【优化搜索顺序】
题目描述
a0 = 1
am = n
a0<a1<a2<...< am-1<am
For each k (1<=k<=m) there exist two (not neccessarily different) integers i and j (0<=i, j<=k-1) with ak=ai+aj
You are given an integer n. Your job is to construct an addition chain for n with minimal length. If there is more than one such sequence, any one is acceptable.
For example, <1,2,3,5> and <1,2,4,5> are both valid solutions when you are asked for an addition chain for 5.
输入
输出
Hint: The problem is a little time-critical, so use proper break conditions where necessary to reduce the search space.
样例输入
5
7
12
15
77
0
样例输出
1 2 4 5
1 2 4 6 7
1 2 4 8 12
1 2 4 5 10 15
1 2 4 8 9 17 34 68 77
【思路】:
由于ak = ai+aj ( 0<= i, j < k ),所以我们在搜索的过程中可以采用由小到大搜索数列的每一项的方法进行试算,在一般搜索的时候,我们习惯于从小到大依次搜索每一个数的取值,但是在这道题目这样的搜索顺序,程序执行时间十分不理想。
由于题目要求的是m的最小值,也就是需要我们尽快得到数n,所以每次构造的数应当是尽可能大的数。根据题目的这个特性,我们将搜索顺序改为从大到小搜索每一个数。后一种搜索顺序使程序执行
1 #include<bits/stdc++.h> 2 using namespace std; 3 int n,m,flag,ans[105]; 4 void dfs(int step,int last){ 5 if( step == m+1 ){ 6 if( ans[m] == n ) 7 flag = 1 ; 8 return ; 9 } 10 11 for(int i=step-1; i>=last;i--){ 12 for(int j=i;j>=1;j--){ 13 ans[step] = ans[i] + ans[j] ; 14 long long s = ans[step] ; 15 //计算当前的位置得到,第m项最大值 16 for (int k=step ;k<=m;k++) s *= 2 ; 17 if ( s < n ) break ; 18 if ( ans[step] <= n ) dfs(step+1,i+1); 19 if ( flag ) return ; 20 } 21 } 22 } 23 int main() 24 { 25 ans[1] = 1; 26 while(~scanf("%d",&n),n){ 27 if( n==1 ){ 28 puts("1"); continue; 29 } 30 for ( flag = 0 , m=2 ; m<=n ; m++ ){ 31 dfs(2,1); 32 if( flag ){ 33 for(int i=1;i<=m;i++){ 34 printf("%d%c",ans[i],i==m?'\n':' '); 35 } 36 break; 37 } 38 } 39 } 40 return 0; 41 42 }
【例题5】weight
【题目描述】
已知原数列 a1,a2,a3,……an 中的前1项,前2项,前 3 项, ,前 n 项的和,以及后 1 项,后 2 项,后 3 项, ,后 n 项的和,但是所有的数都被打乱了顺序。此外,我们还知道数列中的数存在于集合 S 中。试求原数列。当存在多组可能的数列时,求字典序最小的数列。
【输入】
第 1 行,一个整数 n 。
第 2 行,2*n 个整数,注意:数据已被打乱。
第 3 行,一个整数 m ,表示 S 集合的大小。
第 4 行, m 个整数,表示 S 集合中的元素。
【输出】
输出满足条件的最小数列。
【样例输入】
5
1 2 5 7 7 9 12 13 14 14
4
1 2 4 5【样例输出】
1 1 5 2 5
【样例解释】
1 = 1
2 = 1 + 1
7 = 1 + 1 + 5
9 = 1 + 1 + 5 + 2
14 = 1 + 1 + 5 + 2 + 5
5 = 5
7 = 2 + 5
12 = 5 + 2 + 5
13 = 1 + 5 + 2 + 5
14 = 1 + 1 + 5 + 2 + 5
【数据规模】
n<=1000 , S属于{1,2,……500}
【思路】
因为题目S,最坏的情况下,每个数可以取到的值有500种,从数学方面很难找到较好方法予以解决,而采用搜索是一种很好的解决办法,根据数列从左往右依次搜索原数列每个数可能的值,然后与所知道的值进行比较。这样,我们得到了一个最简单的搜索方法A。
但是搜索方法A在最坏的情况下扩展的节点为5001000,求解时间太长了。
在这个算法中,我们对数列中的每个数分别进行了500次搜索,由此导致了搜索量很大。如何有效地减少搜素量是提高本体算法效率的关键。
搜索方法B:回过头来看一看题目提供给我们的约束条件,我们用Si表示前i项的和,用Ti表示后i项的和。
根据题目,我们得到的数应该是数列中的S1,S2……Sn,以及T1,T2,……Tn。其中的任意Si+1-Si和Ti+1-Ti都属于集合S。另一个比较容易发现的约束条件是对任意的i,有Sn=Tn=Si+Ti+1。同样的,在搜索的过程中尽可能利用这些约束条件是提高程序效率的关键。
那么当我们从已知的数据中任意取出两个数的时候,只会出现两种情况:
1、两个数同属于Si或者Ti
2、两个数分别属于Ti和Si
当两个数同属于Si或者Ti时,两个数之差就是途中Sj-Si那一段,而当j=i+1是,Sj-Si必然是题目给出的集合S。由此可知,当每次得到一个数Si或者Ti时,如果我们已知Si-1或者Ti-1退出Si和Ti的可能取值。
因为题目的约束条件都在Si和Ti中,我们改变搜索的对象,不再搜索原数列中的每个数,而是搜索给出的数出现在Si或者Ti中的位置。又由于约束条件中的Si+1与Si的约束关系,在搜索时可以按照Si和Ti递增或者递减的顺序搜索。
例如,原数列:1 1 5 2 5,由它得到的值为:1 2 7 9 14 5 7 12 13 14
排序为:1 2 5 7 7 9 12 13 14 14
由于最大的两个数为所有数的和,在搜索中不用考虑它们,去掉14,得到数列,1 2 5 7 7 9 12 13.
观察发现,数列中的最小值1,只可能出现在所求数列的头部或者尾部。再假设1的位置已经得到了,去掉它以后,我们再观察剩下的数列中最小的数2,显然也可能在当前状态的头部或者尾部加上一个数得到2。这样,每搜索一个数,都只会将它放在头部或者尾部,也就是放入Si中或者Ti中。
推而广之,我们从小到大对已排序的数进行搜索,判断每个数是出现在原数列头部还是尾部。此时我们由原数列的两头向中间搜索,而不是先前的从一头搜向另一头。由之前的分析已经知道,每个数只可能属于Si和Ti中。当我们已经搜索出原数列的S1,S2……Sn和T1,T2……Tj,此时对于正在搜索的数K,只能在Si+1和Ti+1中,分别搜索这两个集合的元素,即判断K-Si和K-Ti是否属于已知集合S,并且在每搜索出一个数K的时候,我们从排序后的数列中去掉Sn-K。这样当K-Si(Ti)不属于集合S或者
Sn - K 时回溯。
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 1e4+10; 4 int n,m; 5 int S[505],a[N],ans[N],sum; 6 void dfs(int L,int R ,int Sum_L , int Sum_R , int k ){ 7 if ( L == R ){ 8 if( sum - Sum_L - Sum_R <= 500 && S[(sum - Sum_L - Sum_R)] ){ 9 ans[L] = sum - Sum_L - Sum_R ; 10 for(int i=1;i<=n;i++){ 11 printf("%d%c",ans[i],i==n?'\n':' '); 12 } 13 exit(0); 14 } 15 return ; 16 } 17 18 if ( (a[k] - Sum_L) <= 500 && S[(a[k] - Sum_L)] ){ 19 ans[L] = (a[k] - Sum_L) ; 20 dfs( L+1 , R , a[k] , Sum_R , k+1 ); 21 } 22 if ( (a[k] - Sum_R) <= 500 && S[(a[k] - Sum_R)] ){ 23 ans[R] = (a[k] - Sum_R) ; 24 dfs( L , R-1 , Sum_L , a[k] , k+1 ); 25 } 26 } 27 int main() 28 { 29 scanf("%d",&n); 30 for(int i=1;i<=n*2;i++){ 31 scanf("%d",&a[i]); 32 } 33 scanf("%d",&m); 34 for(int i=1,x;i<=m;i++){ 35 scanf("%d",&x); 36 S[x] = 1 ; 37 } 38 sort( a+1 ,a+1+2*n) ; 39 sum = a[2*n]; 40 dfs(1,n,0,0,1); 41 return 0; 42 }
【习题1】埃及分数
题目描述

最好的是最后一种,因为 1/18比 1/180,1/45,1/30,1/18都大。
注意,可能有多个最优解。如:

由于方法一与方法二中,最小的分数相同,因此二者均是最优解。
给出 a,b,编程计算最好的表达方式。保证最优解满足:最小的分数

输入
输出
样例输入
19 45
样例输出
5 6 18
提示
【思路】:
【最优性剪枝】
根据题目要求确定合适的搜索顺序,
题目要求的是个数尽量少,同时如果个数相同的话,那么需要用最小的那个分数需要尽量大。
【可行性剪枝】
可以确定上下界来进行剪枝。
下界:是通过比上一次挑选的数字要更大,同时也要比floor(y/x)大,

上界:主要是和个数有关,外循环已经确定了个数,所有在搜索到第i个数的时候,必须满足 (x/y) / (1/t) < ( len - i + 1 ),
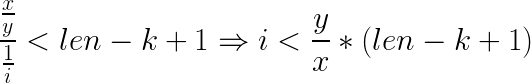
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 1000; 4 typedef long long ll; 5 ll len , s[N] , ans[N] , Min = 0x7fffffff; 6 // 第k个数,上一次的所选的数,当前的分子,当前的分母 7 void dfs(int k,ll Last , ll x,ll y ){ 8 if( k > len ){ 9 if ( !x && s[len] < Min ){ 10 for(int i=1;i<=len;i++){ 11 ans[i] = s[i] ; 12 } 13 Min = s[len]; 14 } 15 return ; 16 } 17 //下界必须是 比上一次选的数要大,同时必须是大于floor(y/x) 18 ll L = max( Last+1 , y/x ); 19 //上界是根据 划分的个数来限定的。 20 //根据 (x/y) / (1/t) < (len-k+1) 21 ll R = y/x * (len-k+1) ; 22 for( ll i=L ; i<=R ; i++ ){ 23 ll tx = x*i - y ; 24 ll ty = y*i ; 25 if ( tx < 0 ) continue ; 26 s[k] = i ; 27 dfs( k+1 , i , tx ,ty ) ; 28 } 29 } 30 int main() 31 { 32 ll x,y ; 33 scanf("%lld%lld",&x,&y); 34 for( len = 2 ; ; len++ ){ 35 dfs(1,1,x,y) ; 36 if( Min < 0x7fffffff ) break; 37 } 38 for(int i=1;i<=len;i++){ 39 printf("%lld%c",ans[i],i==len?'\n':' '); 40 } 41 return 0; 42 }
【习题2】平板涂色
题目描述

为了避免颜料渗漏使颜色混合,一个矩形只能在所有紧靠它上方的矩形涂色后,才能涂色。例如图中矩形F必须在C和D涂色后才能涂色。注意,每一个矩形必须立刻涂满,不能只涂一部分。
写一个程序求一个使APM拿起刷子次数最少的涂色方案。注意,如果一把刷子被拿起超过一次,则每一次都必须记入总数中。
输入
颜色号为1到20的整数。
平板的左上角坐标总是(0, 0)。
坐标的范围是0..99。
N小于16。
输出
样例输入
7
0 0 2 2 1
0 2 1 6 2
2 0 4 2 1
1 2 4 4 2
1 4 3 6 1
4 0 6 4 1
3 4 6 6 2
样例输出
3
【题解】
这个题目还考察了,类似拓补序列 的预处理,然后依照题目剪枝即可。
【最优化剪枝】
如果找到一个答案比当前搜索路线中的暂存值还要优,则剪枝。
【按题意行事】
预处理所有前置木板的情况,然后套搜索框架。具体看代码即可。
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 105; 4 typedef struct Node { 5 int x1,y1,x2,y2,color ; 6 }Node ; 7 int n,ind[N],G[N][N],vis[N]; 8 //ind[],需要涂色这块平板还有多少前置平板要涂色 9 int ans = 0x7fffffff; 10 Node a[N]; 11 //预处理所有平板之间的关系 12 void Init(){ 13 for(int i=1;i<=n;i++){ 14 for(int j=1;j<=n;j++){ 15 if( a[i].x2 == a[j].x1 &&!( a[j].y2 < a[i].y1 || a[i].y2 < a[j].y1 ) ){ 16 G[i][j] = 1 ; 17 ind[j] ++ ; 18 } 19 } 20 } 21 } 22 23 // 已经涂色的个数,当前刷子的颜色,放下刷子的次数。 24 void dfs(int step,int Color,int cnt ){ 25 //最优化剪枝 26 if( ans <= cnt ) return ; 27 if( step == n ){ 28 ans = cnt ; 29 return ; 30 } 31 for(int i=1;i<=n;i++){ 32 //如果当前这个平板还没涂色,并且前置平板都已经涂色了 33 if( !vis[i] && !ind[i] ){ 34 //选择当前的色板涂色 35 vis[i] = 1 ; 36 //并把以这块平板为前置色板的标记清除 37 for(int j=1;j<=n;j++) if( G[i][j] ) ind[j] -- ; 38 //如果颜色刚好相同 39 if( Color == a[i].color ){ 40 dfs(step+1,Color,cnt); 41 }else{ //就算颜色不同就硬涂 42 dfs(step+1,a[i].color,cnt+1); 43 } 44 //恢复 45 for(int j=1;j<=n;j++) if( G[i][j] ) ind[j] ++ ; 46 vis[i] = 0 ; 47 } 48 } 49 } 50 int main() 51 { 52 scanf("%d",&n); 53 for(int i=1,x1,x2,y1,y2,color;i<=n;i++){ 54 scanf("%d%d%d%d%d",&x1,&y1,&x2,&y2,&color); 55 a[i] = (Node) {x1,y1,x2,y2,color}; 56 } 57 Init() ; 58 dfs(0,0,0); 59 printf("%d\n",ans); 60 return 0; 61 }
【习题3】质数方阵
题目描述
+---+---+---+---+---+
| 1 | 1 | 3 | 5 | 1 |
+---+---+---+---+---+
| 3 | 3 | 2 | 0 | 3 |
+---+---+---+---+---+
| 3 | 0 | 3 | 2 | 3 |
+---+---+---+---+---+
| 1 | 4 | 0 | 3 | 3 |
+---+---+---+---+---+
| 3 | 3 | 3 | 1 | 1 |
+---+---+---+---+---+
The prime numbers' digits must sum to the same number.
The digit in the top left-hand corner of the square is pre-determined (1 in the example).
A prime number may be used more than once in the same square.
If there are several solutions, all must be presented (sorted in numerical order as if the 25 digits were all one long number).
A five digit prime number cannot begin with a zero (e.g., 00003 is NOT a five digit prime number).
输入
输出
样例输入
11 1
样例输出
11351
14033
30323
53201
13313
11351
33203
30323
14033
33311
13313
13043
32303
50231
13331
【题解】:
这个解法不是最优的,不能过全部数据。
【搜索顺序】
从左往右,一直到二维数组的最后。
【剪枝策略】:
主要是处理5位数的质数的前后缀进行剪枝,如果填入的数不合法即可剪枝。
1 #include<bits/stdc++.h> 2 using namespace std; 3 typedef long long ll; 4 const int N = 1e6 + 100; 5 bitset<N> isPrime; 6 int prime[N],cnt,S,A; 7 bool Lsum[N],Rsum[N]; 8 int tot, Line1 , Line2 ; 9 int G[6][6],Row[10],Col[10] ; 10 int Pow[]={0,1,10,100,1000,10000,100000}; 11 //欧拉筛选素数 12 inline void Euler(){ 13 isPrime.set(); 14 isPrime[0] = 0 ; 15 for(ll i=2;i<N;i++){ 16 if( isPrime[i] ){ 17 prime[cnt++] = i ; 18 int tmp = i , t=0 ; 19 while ( tmp ){ 20 t = t + (tmp%10); 21 tmp /=10 ; 22 } 23 //同时处理所有前后缀的质数 24 if( 10000<i && i<100000 && t == S ){ 25 Lsum[i/10000] = Lsum[i/1000] = Lsum[i/100] = Lsum[i/10] = Lsum[i] = true; 26 Rsum[i%10000] = Rsum[i%1000] = Rsum[i%100] = Rsum[i%10] = Rsum[i] = true; 27 } 28 } 29 for(ll j=0; j<cnt && i*prime[j]<N ; j++ ){ 30 isPrime[ i*prime[j] ] = 0 ; 31 if( i%prime[j] == 0 ) break; 32 } 33 } 34 } 35 //搜索顺序是按照从左往右,只要超过列宽则下一行 36 inline void dfs( int x,int y ){ 37 if ( y==6 ){ 38 x = x + 1 ; 39 y = 1 ; 40 } 41 if ( x==6 ){ 42 tot ++ ; 43 if( tot!=1 ) 44 putchar('\n'); 45 for(register int i=1;i<=5;i++){ 46 printf("%d\n",Row[i]); 47 } 48 return ; 49 } 50 51 bool F[5] ; 52 for(register int i=0;i<=9;i++){ 53 //当前行 54 F[1] = Lsum[ Row[x] * 10 + i ]; 55 //当前列 56 F[2] = Lsum[ Col[y] * 10 + i ]; 57 //当前正对角线 58 F[3] = (x!=y) || ( x==y && Lsum[Line1*10+i] ) ; 59 //当前次对角线 60 F[4] = (x+y!=6) || ( x+y==6 && Rsum[Line2+i*Pow[x]] ); 61 62 //如果里面只要有一个不符合质数前缀则剪枝 63 if ( !( F[1] && F[2] && F[3] && F[4] ) ) 64 continue; 65 66 //放置i 67 Row[x] = Row[x] * 10 + i ; 68 Col[y] = Col[y] * 10 + i ; 69 if( x==y ) Line1 = Line1 * 10 + i ; 70 if( x+y == 6 ) Line2 = Line2 + i * Pow[x] ; 71 72 dfs( x , y + 1 ); 73 74 //恢复i 75 Row[x] /= 10 ; 76 Col[y] /= 10 ; 77 if( x==y ) Line1 /= 10; 78 if( x+y == 6 ) Line2 %= Pow[x]; 79 } 80 } 81 int main() 82 { 83 scanf("%d%d",&S,&A); 84 Euler(); 85 memset(G,-1,sizeof(G)) ; 86 G[1][1]=A; 87 Row[1]=Col[1]=Line1=A; 88 dfs(1,2); 89 if( tot == 0 ) { 90 printf("NONE\n"); 91 } 92 return 0; 93 }
【习题4】靶形数独
题目描述
靶形数独的方格同普通数独一样,在 9 格宽×9 格高的大九宫格中有 9 个 3 格宽×3 格高的小九宫格(用粗黑色线隔开的)。在这个大九宫格中,有一些数字是已知的,根据这些数字,利用逻辑推理,在其他的空格上填入 1 到 9 的数字。每个数字在每个小九宫格内不能重复出现,每个数字在每行、每列也不能重复出现。但靶形数独有一点和普通数独不同,即每一个方格都有一个分值,而且如同一个靶子一样,离中心越近则分值越高。(如图)

上图具体的分值分布是:最里面一格(黄色区域)为 10 分,黄色区域外面的一圈(红色区域)每个格子为 9 分,再外面一圈(蓝色区域)每个格子为 8 分,蓝色区域外面一圈(棕色区域)每个格子为 7 分,最外面一圈(白色区域)每个格子为 6 分,如上图所示。比赛的要求是:每个人必须完成一个给定的数独(每个给定数独可能有不同的填法),而且要争取更高的总分数。而这个总分数即每个方格上的分值和完成这个数独时填在相应格上的数字的乘积的总和
总分数即每个方格上的分值和完成这个数独时填在相应格上的数字的乘积的总和。如图,在以下的这个已经填完数字的靶形数独游戏中,总分数为 2829。游戏规定,将以总分数的高低决出胜负。

输入
输出
输出可以得到的靶形数独的最高分数。如果这个数独无解,则输出整数-1。
样例输入
7 0 0 9 0 0 0 0 1
1 0 0 0 0 5 9 0 0
0 0 0 2 0 0 0 8 0
0 0 5 0 2 0 0 0 3
0 0 0 0 0 0 6 4 8
4 1 3 0 0 0 0 0 0
0 0 7 0 0 2 0 9 0
2 0 1 0 6 0 8 0 4
0 8 0 5 0 4 0 1 2
样例输出
2829
【题解】:
数独其实跟八皇后差不多。
按照最朴素的做法做的,但是对于某些厉害的数据是过不了的,因为这个真的太朴素了。代码是参考黄学长的。
按照逐个数填入,然后判断是否合法,然后填充后撤回来进行。
因为太朴素了,所以是真的不能过
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 10; 4 int read( ){ 5 int x = 0 ; 6 char c = getchar() ; 7 for( ; !('0'<=c&&c<='9') ;c=getchar() ); 8 for( ; '0'<=c&&c<='9' ; c=getchar() ){ 9 x = x*10+c-'0' ; 10 } 11 return x ; 12 } 13 int a[N][N],b[N][N]; 14 int Row[N][N] , Col[N][N] , S[N][N] ; 15 int getScore[N][N][N]; 16 int Score,ans=-1; 17 //计算得分范围 18 inline int CulScore(int x,int y,int k){ 19 if( x==5 && y==5 ) return 10*k; 20 else if( 4<=x && x<=6 && 4<=y && y<=6 ) return 9*k; 21 else if( 3<=x && x<=7 && 3<=y && y<=7 ) return 8*k; 22 else if( 2<=x && x<=8 && 2<=y && y<=8 ) return 7*k; 23 else if( 1<=x && x<=9 && 1<=y && y<=9 ) return 6*k; 24 } 25 //放置k到x,y的位置上,并添加标记 26 inline int Fillin(int x,int y,int k){ 27 if( Row[x][k] || Col[y][k] || S[(x-1)/3*3+(y-1)/3+1][k]) return 0; 28 b[x][y] = k ; 29 Row[x][k] = S[(x-1)/3*3+(y-1)/3+1][k] = Col[y][k] = 1 ; 30 Score += getScore[x][y][k] ; 31 return 1 ; 32 } 33 //删除(x,y)位置上的标记 34 inline void Del (int x,int y,int k) { 35 Row[x][k] = Col[y][k] = S[(x-1)/3*3+(y-1)/3+1][k] = 0 ; 36 } 37 inline void dfs(int x,int y){ 38 if( y == 10 ){ 39 x=x+1 ; y=1; 40 } 41 if( x==10 && y==1 ){ 42 //得出最优的答案 43 if( Score < ans ) ans = Score ; 44 return ; 45 } 46 if( b[x][y] ) //如果当前有数则跳过 47 dfs(x,y+1); 48 else{ //否则尝试填入 49 for(register int i=1;i<=9;i++){ 50 int tmp = Score ; 51 if( Fillin(x,y,i) ){ //尝试填入是否合法 52 dfs(x,y+1); 53 Del(x,y,i); 54 Score = tmp ; 55 } 56 } 57 b[x][y] = 0 ; 58 } 59 } 60 int main() 61 { 62 //预处理所有得分情况 63 for(register int i=1;i<=9;i++){ 64 for(register int j=1;j<=9;j++){ 65 for(register int k=1;k<=9;k++) 66 getScore[i][j][k] = CulScore(i,j,k); 67 } 68 } 69 //输入的过程中把对应的位置进行标记 70 for(register int i=9;i>=1;i--){ 71 for(register int j=9;j>=1;j--){ 72 a[i][j] = read() ; 73 if( a[i][j] ) Fillin(i,j,a[i][j]); 74 } 75 } 76 //按照从左往右的顺序历遍 77 dfs(1,1); 78 printf("%d\n",ans); 79 return 0; 80 }
【二进制优化】:
这个是参考洛谷题解中某位大佬的做法,我觉得这个优化十分强悍,主要体现在把整个九个九宫格直接hash,
全部转化为01串,1代表可以进行选择,0则不行,数独是涉及三个维度,行,列,以及小九宫格。通过三个01串进行&操作,即可找到我们需要的位置,再用lowbit来找到下一个”1“的位置在哪。这个做法是非常强悍的,深深佩服想到这个思路的dalao。
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N = 12; 4 const int M = 520; 5 int a[N][N]; 6 int Row[N] , Col[N] , B[N] ; 7 int Cnt[M] , Num[M]; 8 int getScore[N][N][N]; 9 int Score,ans=-1; 10 11 int read( ){ 12 int x = 0 ; 13 char c = getchar() ; 14 for( ; !('0'<=c&&c<='9') ;c=getchar() ); 15 for( ; '0'<=c&&c<='9' ; c=getchar() ){ 16 x = x*10+c-'0' ; 17 } 18 return x ; 19 } 20 21 inline int CulScore(int x,int y,int k){ 22 if( x==4 && y==4 ) return 10*k; 23 else if( 3<=x && x<=5 && 3<=y && y<=5 ) return 9*k; 24 else if( 2<=x && x<=6 && 2<=y && y<=6 ) return 8*k; 25 else if( 1<=x && x<=7 && 1<=y && y<=7 ) return 7*k; 26 else if( 0<=x && x<=8 && 0<=y && y<=8 ) return 6*k; 27 } 28 29 inline void flip ( int x,int y,int k ){ 30 Row[x] ^= (1<<k) ; 31 Col[y] ^= (1<<k) ; 32 B[ x/3*3 + y/3 ] ^= (1<<k) ; 33 } 34 35 inline bool dfs( int Now , int Score ){ 36 37 if ( Now == 0 ){ 38 if ( ans < Score ){ 39 ans = Score ; 40 } 41 return true ; 42 } 43 int tot = 10 ; // 找最少的允许空间的入手. 44 int x,y; // 同时记录当时的横纵坐标 45 int val; 46 // 找出还未填补的地方,并同时找到选择可能最少的位置出来优先填补。 47 for(int i=0;i<9;i++){ 48 for(int j=0;j<9;j++){ 49 if( a[i][j] != -1 ) continue; 50 val = Row[i] & Col[j] & B[ i/3*3 + j/3 ]; 51 if( !val ) return false ; 52 if( Cnt[val] < tot ){ 53 tot = Cnt[val] ; 54 x = i , y = j ; 55 } 56 } 57 } 58 //恢复原来的值,val值转化为01串后,1的位置就是允许选择的位置,0则不可以。 59 val = Row[x] & Col[y] & B[ x/3*3 + y/3 ] ; 60 bool flag = false ; 61 int k; 62 // num 数组是找出01串位置,num[2^i] = i 的过程 63 for( ; val ; val -= val & -val ){ 64 k = Num[val&-val] ; 65 //(x,y) 填上k值 66 a[x][y] = k+1 ; 67 flip( x,y,k ); 68 if ( dfs( Now-1 , Score+getScore[x][y][k+1] ) ) 69 flag = true; 70 //(x,y) 撤回k值 71 a[x][y] = -1 ; 72 flip( x,y,k ); 73 } 74 // 如果在过程中找到就返回flag 75 return flag ; 76 } 77 int main() 78 { 79 //初始化得分位置 80 for(register int i=0;i<9;i++) 81 for(register int j=0;j<9;j++) 82 for(register int k=1;k<=9;k++) 83 getScore[i][j][k] = CulScore(i,j,k); 84 //初始化Num 次幂 转 指数 85 for(int i=0;i<9;i++){ 86 Num[1<<i] = i ; 87 } 88 //初始化Cnt 将Cnt[num] = num转为01串的1的个数 89 for(int i=0;i<(1<<9);i++){ 90 for(int j=i ; j ; j-=j&-j ){ 91 Cnt[i] ++ ; 92 } 93 } 94 //初始化,行,列,及小九宫格的所有位置 95 for(int i=0;i<9;i++){ 96 Row[i] = Col[i] = B[i] = (1<<9) - 1 ; 97 } 98 //输入 99 int Empty = 0 ,Init_Score = 0 ; 100 for(register int i=0;i<9;i++){ 101 for(register int j=0;j<9;j++){ 102 a[i][j] = read() ; 103 if( a[i][j] ) { 104 flip(i,j,a[i][j]-1); 105 Init_Score += getScore[i][j][a[i][j]]; 106 } 107 else{ 108 a[i][j] = -1 ,Empty++ ; 109 } 110 } 111 } 112 //搜索 113 dfs(Empty,0); 114 if ( ~ans ) ans = ans + Init_Score ; 115 printf("%d\n",ans); 116 return 0; 117 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号