1.关键字一览
| 关键字 |
说明 |
| SELECT |
从表中查询数据 |
| WHERE |
对结果进行筛选 |
| ORDER BY |
排序 |
| LIMIT |
限制返回的行数 |
| UPDATE |
更新表的数据 |
| INSERT INTO |
插入数据 |
| DELETE |
删除表的数据 |
2.基本查询
SELECT * FROM users
SELECT username, email FROM users
SELECT * FROM users WHERE id = 1
3.进阶查询
- 模糊查询:通过 LIKE 关键字来声明模糊匹配,模糊匹配的部分使用%代替
//查询https开头的行
SELECT * FROM websites WHERE url LIKE 'https://%'
- 条件运算符:可以使用各种条件运算符(如 =, <, >, <=, >=, !=)
//过滤Alexa > 10 的行
SELECT * FROM websites WHERE Alexa > 10
- 逻辑运算:可使用与或非进行逻辑运算(AND, OR, NOT)
//过滤 2 < Alexa < 20 的行
SELECT * FROM websites WHERE Alexa > 2 AND Alexa < 20
- 范围查询:BETWEEN XX AND YY,查询介于 XX 和 YY 之间的数据,包括XX和YY
SELECT * FROM access_log where Visit_count BETWEEN 45 AND 100
- 多匹配查询:使用 IN 进行多值匹配,只保留括号中的数据
SELECT * FROM access_log WHERE Date IN ('2016-05-10','2016-05-13')
SELECT * FROM access_log LIMIT 5
- 分页查询:通过 LIMIT 配合 OFFSET 来跳过一些数据,达到分页查询的效果
//跳过前3条数据,返回2条(4,5)
SELECT * FROM websites LIMIT 2 OFFSET 3
4.排序
- 通过 order by 来指定根据哪个列来对查询结果进行排序,默认升序 ASC
- 根据age进行升序
SELECT * FROM users order by age
SELECT * FROM users order by age ASC
SELECT * FROM users order by age DESC
- 多级排序:先按第一列的条件排序,如果第一列的值一样,则按第二列的值再排序,越是前面的列,优先级越高
SELECT * FROM websites order by Country,Alexa
5.更新数据
- 使用 UPDATE 声明要更新的表,使用 SET 声明要更新的列,使用 WHERE 来指定要更新的行
UPDATE websites SET name = '谷歌' WHERE Id = 1
UPDATE websites SET name = '谷歌',Url = 'https://www.google.com.hk/' WHERE Id = 1
6.插入数据
- 通过 INSERT INTO 语句来插入数据,传入列名和数据(以下标进行匹配)
INSERT INTO users (username, email, birthdate, is_active)
VALUES ('test', 'test@runoob.com', '1990-01-01', true);
INSERT INTO users (username, email, birthdate, is_active)
VALUES
('test1', 'test1@runoob.com', '1985-07-10', true),
('test2', 'test2@runoob.com', '1988-11-25', false),
('test3', 'test3@runoob.com', '1993-05-03', true);
7.删除数据
- 通过 DELETE 来删除表的数据,一般通过 WHERE 指定要删除的行
DELETE FROM websites WHERE ID = 1
DELETE FROM websites
8.关联查询
- INNER JOIN:只返回左右表中都能匹配上的记录,例如查询用户带出部门信息,要求部门id不能为空,且部门表必须要有这个id记录,否则过滤出这个用户,,左右表是融合关系
- LEFT JOIN:会返回左表中的所有记录,即使右表中没有匹配的记录,例如查询用户带出部门信息,无论是否能查询到部门信息,都要返回这个用户,左右表是主副关系,配合ON使用,表示他们直接的匹配关系
//查询订单列表时(订单表),根据订单号带出客户信息(客户表)
SELECT
orders.id AS orderId,
orders.orderNumber,
customers.id AS customerId,
customers.name AS customerName,
customers.email AS customerEmail
FROM
orders
LEFT JOIN
customers ON orders.customerId = customers.id;
- RIGHT JOIN:与LEFT JOIN 是对称的,它们的功能可以通过交换表的位置来实现
- SQL JOIN:来自两个或多个表的行结合起来,基于这些表之间的共同字段
//把token表的数据(token)同步到users表中
UPDATE users u
JOIN token t ON u.id = t.userId
SET u.token = t.token;
9.外键及其约束
- 外键含义:当一个表需要引用另一个表的数据时,需要定义一个用于匹配关联的字段,这个字段就是"外键"
- 外键约束:为了保证维护数据完整性和一致性(被引用的数据不得为空),要做到2点,第一,当新增记录时,先对引用数据进行判断,不存在则抛出异常,阻止后续操作,第二,当引用源数据后期被删或者修改时,当前表的对应记录可以做出对应的操作,例如删除,或者置为null等,这些行为在代码中进行逻辑判断也是可以实现的,但是数据库有了这些功能,就可以少写些代码,便于维护
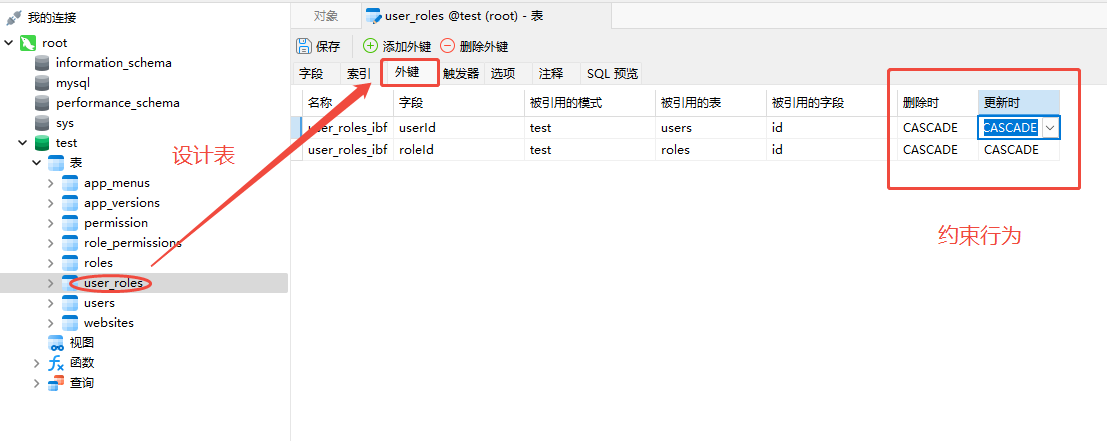
- 在Navicat中设置或者查看外键信息
![]()
10.函数和聚合操作
- COUNT():用于计算符合条件的行数,参数一般为*,如果需要对列进行进一步过滤,则可以传入列名,之后会过滤该列值为NULL的行
//以count字段返回地区为CN的网站数量
SELECT COUNT(*) AS count FROM `websites` WHERE country = 'CN';
//以count字段返回地区为CN的,且网站不为NULL的网站数量
SELECT COUNT(url) AS count FROM `websites` WHERE country = 'CN';
- MAX():传入列名,计算最大值,它可以应用于数值列、字符列(根据字母顺序)、日期时间列等
//以max_age字段返回最大的年龄
SELECT MAX(age) AS max_age FROM `user`;
- SUM():传入列名,计算符合条件行在此列维度上的总和
//计算所有订单金额的总和
SELECT SUM(amount) AS total_amount FROM orders;
- SUM():传入列名,计算符合条件行在此列维度上的平均值
//计算所有员工薪资的平均值
SELECT AVG(salary) AS average_salary FROM employees

 浙公网安备 33010602011771号
浙公网安备 33010602011771号