logstash通过kafka传输nginx日志(三)
单个进程 logstash 可以实现对数据的读取、解析和输出处理。但是在生产环境中,从每台应用服务器运行 logstash 进程并将数据直接发送到 Elasticsearch 里,显然不是第一选择:第一,过多的客户端连接对 Elasticsearch 是一种额外的压力;第二,网络抖动会影响到 logstash 进程,进而影响生产应用;第三,运维人员未必愿意在生产服务器上部署 Java,或者让 logstash 跟业务代码争夺 Java 资源。
所以,在实际运用中,logstash 进程会被分为两个不同的角色。运行在应用服务器上的,尽量减轻运行压力,只做读取和转发,这个角色叫做 shipper;运行在独立服务器上,完成数据解析处理,负责写入 Elasticsearch 的角色,叫 indexer。
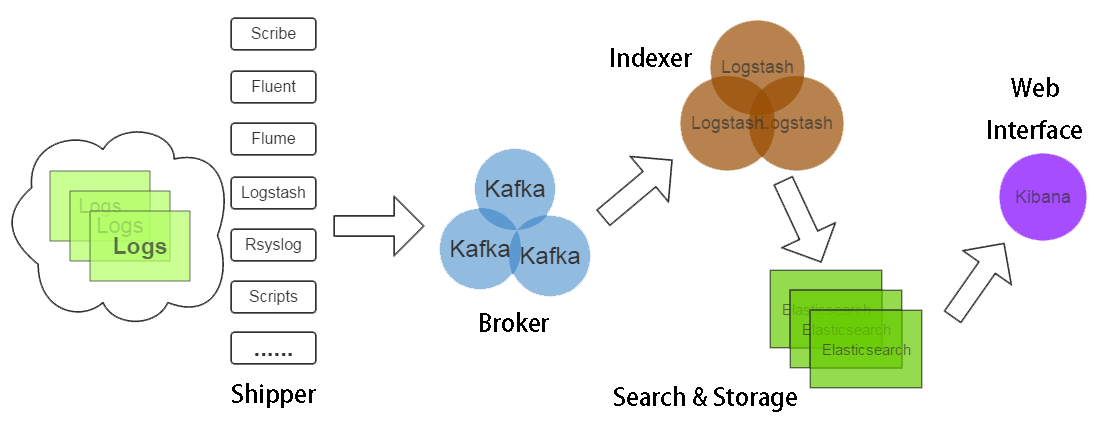
Kafka 是一个高吞吐量的分布式发布订阅日志服务,具有高可用、高性能、分布式、高扩展、持久性等特性。和Redis做轻量级消息队列不同,Kafka利用磁盘做消息队列,所以也就无所谓消息缓冲时的磁盘问题。生产环境中还是推荐使用Kafka做消息队列。此外,如果公司内部已经有 Kafka 服务在运行,logstash也可以快速接入,免去重复建设的麻烦。
一、Logstash搭建
详细搭建可以参考Logstash安装搭建(一)。
二、配置Shipper
Shipper 即为Nginx服务器上运行的 logstash 进程,logstash 通过 logstash-input-file 写入,然后通过 logstash-output-kafka 插件将日志写入到 kafka 集群中。
Logstash使用一个名叫 FileWatch 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录在 .sincedb 的数据库文件来跟踪被监听的日志文件的当前读取位置。
.sincedb 文件中记录了每个被监听的文件的 inode, major number, minor number 和 pos。
Input配置实例
input { file { path => "/var/log/nginx/log_access.log" type => "nginx-access" discover_interval => 15 #logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。 sincedb_path => "/etc/logstash/.sincedb" #定义sincedb文件的位置 start_position => "beginning" #定义文件读取的位置 } }
其他配置详解:
exclude 不想被监听的文件可以排除出去。 close_older 已经监听的文件,若超过这个时间内没有更新,就关闭监听该文件的句柄。默认为:3600s,即一小时。 ignore_older 在每次检查文件列表时,若文件的最后修改时间超过该值,则忽略该文件。默认为:86400s,即一天。 sincedb_path 定义 .sincedb 文件路径,默认为 $HOME/.sincedb 。 sincedb_write_interval 间隔多久写一次sincedb文件,默认15s。 stat_interval 每隔多久检查被监听文件状态(是否有更新),默认为1s。 start_position logstash从什么位置开始读取文件数据。默认为结束位置,类似 tail -f 的形式。设置为“beginning”,则从头读取,类似 cat ,到最后一行以后变成为 tail -f 。
Output配置实例
以下配置可以实现对 kafka producer 的基本使用。生产者更多详细配置请查看 Kafka 官方文档中生产者部分配置文档。
output { kafka { bootstrap_servers => "localhost:9092" #生产者 topic_id => "nginx-access-log" #设置写入kafka的topic compression_type => "snappy" #消息压缩模式,默认是none,可选gzip、snappy。 } }
logstash-out-kafka 其他配置详解:
compression_type 消息压缩模式,默认是none,有效值为:none、gzip、snappy。 asks 消息确认模式,默认为1,有效值为:0、1、all。设置为0,生产者不等待 broker 回应;设置为1,生产者会收到 leader 写入之后的回应;设置为all, leader 将要等待 in-sync 中所有的 replication 同步确认。 send_buffer_bytes TCP发送数据时的缓冲区的大小。
logstash-kafka 插件输入和输出默认 codec 为 json 格式。在输入和输出的时候注意下编码格式。消息传递过程中 logstash 默认会为消息编码内加入相应的时间戳和 hostname 等信息。如果不想要以上信息(一般做消息转发的情况下),可以使用以下配置,例如:
output { kafka { codec => plain { format => "%{message}" } } }
三、搭建配置Kafka
搭建配置Kafka可以参考 Kafka集群搭建。
四、配置Indexer
是用logstash-input-kafka插件,从kafka集群中读取数据。
Input配置示例:
input { kafka { zk_connect => "localhost:2181" #zookeeper地址 topic_id => "nginx-access-log" #kafka中topic名称,记得创建该topic group_id => "nginx-access-log" #默认为“logstash” codec => "plain" #与Shipper端output配置项一致 consumer_threads => 1 #消费的线程数 decorate_events => true #在输出消息的时候回输出自身的信息,包括:消费消息的大小、topic来源以及consumer的group信息。 type => "nginx-access-log" } }
更多 logstash-input-kafka 配置可以从 logstash 官方文档 查看。
Logstash 是一个 input | decode | filter | encode | output 的数据流。上述配置中有 codec => "plain" ,即logstash 采用转发的形式,不会对原有信息进行编码转换。丰富的过滤器插件(Filter)的存在是 logstash 威力强大的重要因素,提供的不单单是过滤的功能,可以进行复杂的逻辑处理,甚至无中生有添加新的logstash事件到后续的流程中去。这里只列举 logstash-output-elasticsearch 配置。
logstash-output-elasticsearch 配置实例:
output { elasticsearch { hosts => ["localhost:9200"] //Elasticsearch 地址,多个地址以逗号分隔。 index => "logstash-%{type}-%{+YYYY.MM.dd}" //索引命名方式,不支持大写字母(Logstash除外) document_type => "%{type}" //文档类型 workers => 1 flush_size => 20000 //向Elasticsearch批量发送数据的条数 idle_flush_time => 10 //向Elasticsearch批量发送数据的时间间隔,即使不满足 flush_size 也会发送 template_overwrite => true //设置为true,将会把自定义的模板覆盖logstash自带模板 } }
到此就已经把Nginx上的日志转发到Elasticsearch中。
作者:Orgliny
出处:https://www.cnblogs.com/Orgliny
本文采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号