python学习Day27
Day 27
今日内容概要
- re模块
- 网络爬虫简介
- 第三方模块简介
- 网络爬虫实战—爬取网页信息
- openpyxl模块
- openpyxl实操
今日内容详细
1.re模块
在python中如果想用正则表达式 re模块是'选择之一'
import re
1.findall通过正则表达式筛选文本'符合所有条件'的数据
res=re.findall('a','abcabca')#在文本中筛选出符合'a'的所有内容 结果为列表
print(res)#['a','a','a']
2.finditer通过正则表达式筛选文本符合所有条件的数据并转换成'迭代器对象',用于节省内存
res1=re.finditer('a','abcabca')#在文本中筛选出符合'a'的所有内容 结果为迭代器对象
print(res1)#<callable_iterator object at 0x0000015FE33C69A0>
3.search通过正则表达式匹配到'一个符合条件'的内容就结束
res2=re.search('a','abcabca')
print(res2)#<re.Match object; span=(0, 1), match='a'>
print(res2.group())#a
4.match通过正则表达式从头开始匹配,如果'头不符合就结束'
res3=re.match('a','bcabca')
print(res3)#None
res4=re.match('a','abcabca')
print(res4)#<re.Match object; span=(0, 1), match='a'>
5.compile能够提前准备好正则,后续反复使用减少代码冗余
obj=re.compile('a')
print(re.findall(obj,'asdsdfsa'))#['a','a']
print(re.findall(obj,'sdfaadsa'))#['a','a','a']
print(re.findall(obj,'asfaadfa'))#['a','a','a','a']
补充:
1.分组
import re
1)findall针对分组()里的正则表达式优先展示:用abc去匹配结果只要b
res1=re.findall('a(b)c','abcabcabc')
print(res1)#['b','b','b']
#取消分组优先展示:(?:)
res2=re.findall('a(?:b)c','abcabcabc')
print(res2)#['abc','abc','abc']
2)search针对分组()里的正则表达式不影响(如果加了索引就是取分组里的数据)
res=re.search('a(b)(c)','abcabcabc')
print(res.group())#abc 不写索引默认所有
print(res.group(0))#abc 索引0取所有
print(res.group(1))#b 索引1取第一个分组
print(res.group(2))#c 索引2取第二个分组,当没有时会报错
2.别名 (?P<id>正则表达式)
res=re.search('a(?P<id>b)c','abcabcabc')
print(res.group())#abc 起别名不影响正常运行
print(res.group(1))#b 起别名可以用索引获取
print(res.group('id'))#b 起别名也可以用别名获取
2.网络爬虫简介
1.什么是互联网?
将全世界的计算机连接到一起组成的网络
2.互联网发明的目的是什么?
将连接到互联网的计算机数据彼此共享
3.上网的本质是什么?
基于互联网访问其他人计算机上的共享数据(服务器存在的意义就是让其他人来访问)
4.网络爬虫的本质:
模拟计算机浏览器朝目标网址发送请求数据并筛选想要的数据
只要是浏览器可以访问到的数据,网络爬虫理论上都可以
2.1.第三方模块简介
1.第三方模块必须先下载才可以导入使用
2.python下载第三方模块需要借助于pip工具
cmd命令栏里可以打pip+3.8(多版本共存需加版本号来决定用哪个python版本的) 出来的结果就是python解释器提供给我们用来帮我们在网络上下载模块的工具。#如果打了pip没结果 那是因为下载python环境变量时没添加Scripts路径 建议看之前视频
3.下载命令
pip3.8 install 模块名 (多版本共存用不同版本解释器下载就会下载到相应版本里)
"""
1.下载速度慢
pip工具默认是从国外的地址下载模块所以速度慢
2.可以选择切换下载国内镜像源地址(百度pip源)
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
1).用命令切换下载地址命令:
pip3.8 install 模块名 -i 源地址
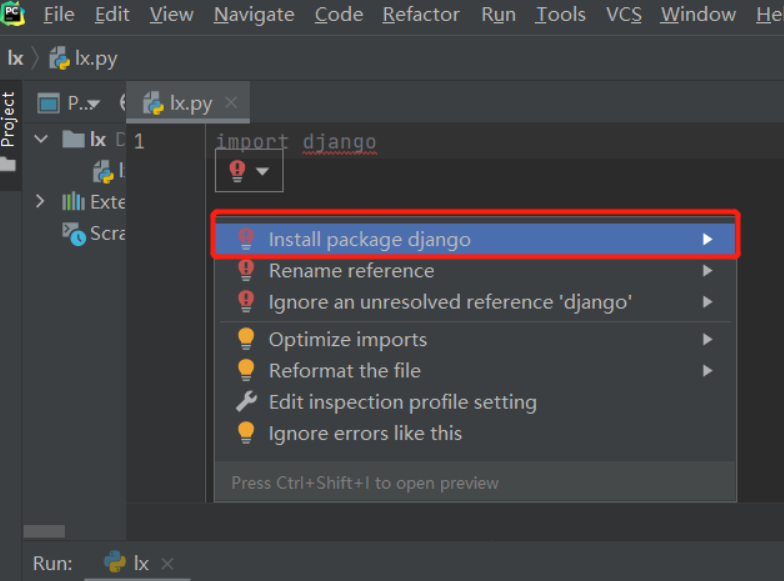
2).pycharm提供第三方模块下载的快捷方式
如下图
3).pycharm内部也可自行下载模块
如下图
4).也可以直接修改python解释器原文件
百度搜索
4.下载报错问题
1).pip工具版本过低,直接拷贝提示信息里面的更新命令即可
python38 -m pip install --upgrade pip
2).网络波动,关键字是 Read timed out
重新下载几次即可,或者切换一个网络稳定的网
3).有些模块在下载使用前需要提前配置指定的环境
根据具体情况百度搜索
5.模块也有版本
pip3.8 install 模块名==版本号
pip3.8 install django==1.11.11
"""
2)pycharm提供第三方模块下载的快捷方式:
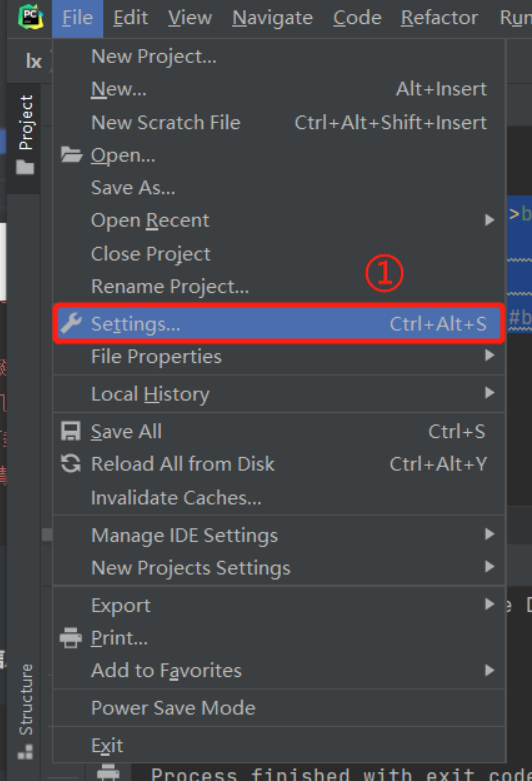
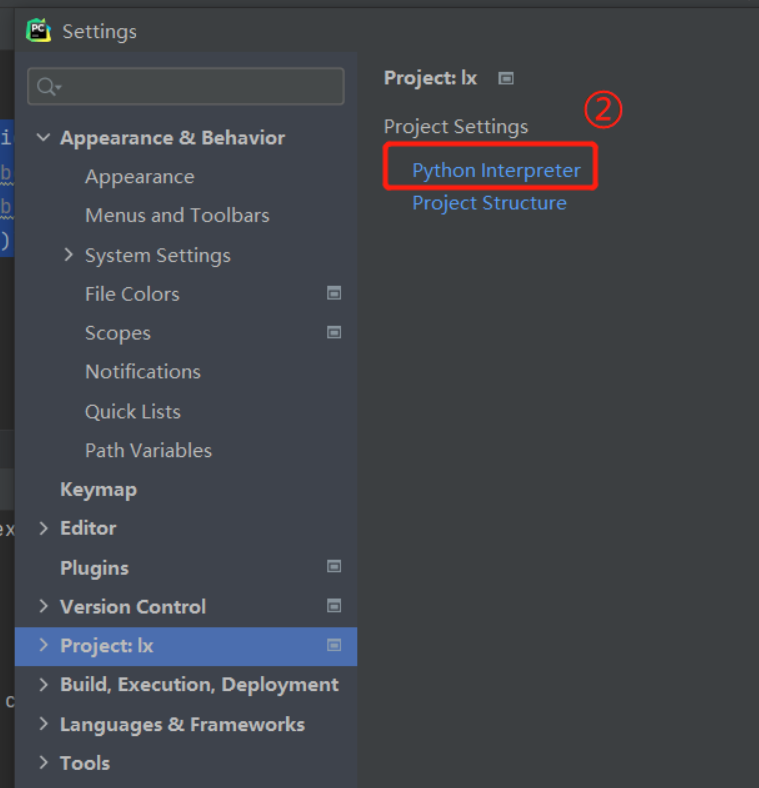
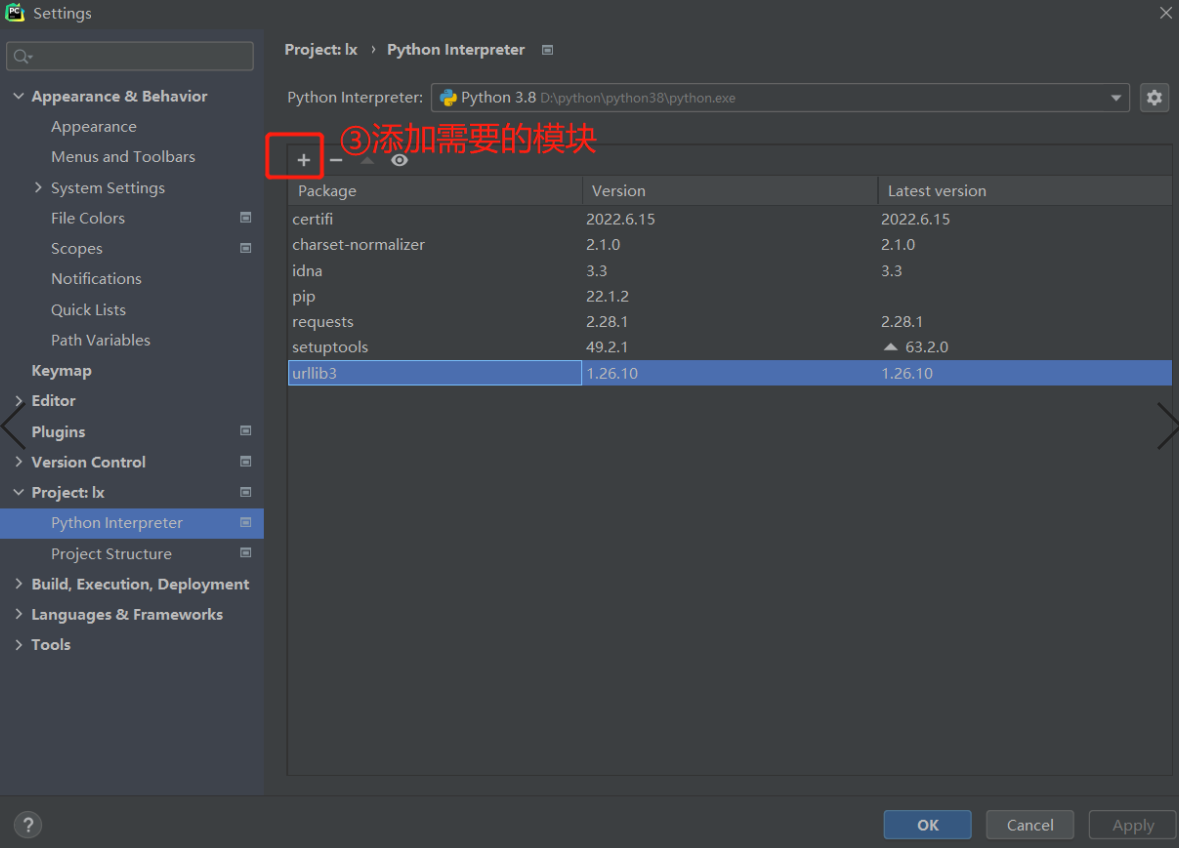
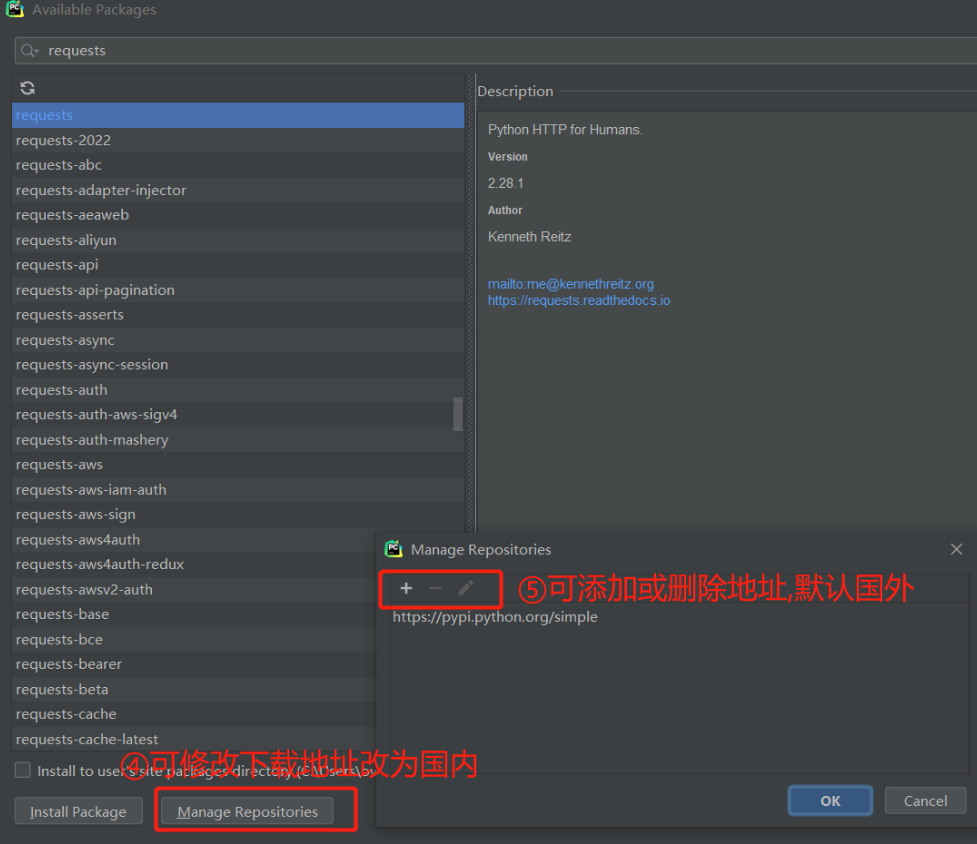
3)pycharm内部自行下载模块
2.2.网络爬虫实战—爬取网页信息
1.获取红牛分公司数据 http://www.redbull.com.cn/about/branch
import re
import requests
#朝目标地址发送网络请求获取响应数据,相当于在浏览器地址栏输入地址后敲回车
res=requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content)#获取bytes类型数据
# print(res.text)#获取解码该页面的数据
#为了避免每次执行程序都要发送网络请求,可以提前保存页面数据到文件
with open(r'hn.html','wb')as f:
f.write(res.content)
#读取页面数据
with open(r'hn.html','r',encoding='utf8')as f:
data=f.read()
# print(data)
#研究目标数据的特征 编写正则筛选
#1.获取分公司名称:
company_name_list=re.findall('<h2>(.*?)</h2>',data)#['红牛杭州分公司', '红牛广西分公司', '红牛广州分公司']
#2.获取所有分公司地址:
company_addr_list=re.findall("<p class='mapIco'>(.*?)</p>",data)#['杭州市上城区庆春路29号远洋大厦11楼A座', '南宁市金湖路59号地王国际商会中心50层D1、E1室', '广东省广州市天河珠江新城华夏路10号富力中心写字楼1904房]
#3.获取所有分公司邮编:
company_email_list=re.findall("<p class='mailIco'>(.*?)</p>",data)#['310009', '530021', '510623']
#4.获取所有分公司电话:
company_phone_list=re.findall("<p class='telIco'>(.*?)</p>",data)#['0571-87045279/7792', '0771-5592660/61/62', '020-38927681]
#5.整合获取到的数据
#zip(),给它传多个容易类型,可以按位置顺序一一对应整合一起
res=zip(company_name_list,company_addr_list,company_email_list,company_phone_list)#结果是迭代器
#6.处理数据(展示、保存、Excel)
for i in res:#('红牛杭州分公司', '杭州市上城区庆春路29号远洋大厦11楼A座', '310009', '0571-87045279/7792')
print("""
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s
"""%i)
3.openpyxl模块
1.主要用于操作excel表格 也是pandas底层操作表格的模块
2.在python中能操作excel表格的模块邮很多:
openpyxl属于近几年比较流行的模块
epenpyxl针对03版本之前的excel文件兼容性不好
xlwt、xlrd也可以操作excel表格
兼容各版本excel文件 但是使用方式没openpyxl简单
3.excel版本问题
03版本前excel文件后缀名为.xlsx
03版本后excel文件后缀名为.xls
苹果电脑excel文件后缀是.csv
4.下载模块 cmd指令
pip3.8 install openpyxl
3.1.openpyxl实操
1.创建excel文件
from openpyxl import Workbook#导入模块 Workbook是用来创建文件的
wb=Workbook()#创建excel文件
wb1=wb.create_sheet('成绩表')#创建sheet工作簿
wb2=wb.create_sheet('财务表',0)#创建sheet工作簿 并要求在第一个sheet页上
'当文件打开时不能创建修改'
wb1.title='学员表'#给wb1工作簿改名
wb1.sheet_properties.tabColor="1072BA"#给wb1工作簿改颜色
wb.save(r'111.xlsx')#保存文件
2.在excel工作簿中写入数据
#写入后要跟保存 不然文件没保存
1)第一种写入方式
wb1['A1']='张三'
2)第二种写入方式
wb1.cell(row=3,column=2,value='李四')#在.单元格中第三行,第二列,写入'李四'
3)第三种写入方式(批量写入)
wb1.append(['name','pwd','age','gender','hobby'])
#在单元格中数最上方分别写入该数据(默认没数值的下一行)
wb1.append(['张三',123,18,'男','读书'])
wb1.append(['李四',None,18,'男','读书'])#当少数据时需自己加None 不然会错行
3.还可以写入公式:
wb1['A10']='=sum(A2:A9)' #给wb1工作簿A2:A9求和
作业
1.整理今日内容及博客
2.尝试将红牛分公司数据保存到excel表格中
3.自行查阅openpyxl官网学习更多操作
4.预习明日内容及ATM项目
https://www.cnblogs.com/Dominic-Ji/p/16097121.html
# 尝试将红牛分公司数据保存到excel表格中
#1.获取红牛网站的数据http://www.redbull.com.cn/about/branch
#2.创建excel表格存储分公司数据
import re
from openpyxl import Workbook
#1.3.读取该页面数据
with open(r'hn.html','r',encoding='utf8')as f:
data=f.read()
#1.4.用正则表达式获取公司名称
company_name_list=re.findall('<h2>(.*?)</h2>',data)
#1.5.用正则表达式获取公司地址
company_addr_list=re.findall("<p class='mapIco'>(.*?)</p>",data)
#1.6.用正则表达式获取公司邮编
company_email_list=re.findall("<p class='mailIco'>(.*?)</p>",data)
#1.7.用正则表达式获取公司电话
company_phone_list=re.findall("<p class='telIco'>(.*?)</p>",data)
#1.8.用zip()整合数据
res=zip(company_name_list,company_addr_list,company_email_list,company_phone_list)
#2.1.创建excel文件
wb=Workbook()
wb1=wb.create_sheet('红牛分公司信息',0)
#2.2.在该excel工作簿中写入数据
wb1.append(['公司名称','公司地址','公司邮编','公司电话'])
for i in res:
#添加一个条件判断,当i的值有空时,赋值给None然后继续循环
if i=='':
i=None
wb1.append(i)
#2.3保存excel文件
wb.save(r'红牛分公司信息表.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号