SVM-AdaBoost推导
SVM白板推导
二次规划优化算法
硬间隔
\(L_2\)范数的矩阵计算 \(||w|| = w * w^T\)

凸二次规划问题,只有最小值,约束是现行的,且默认满足强对偶关系

最优化问题一般是求解最小值,所以将这里的求max,转换成求min


软间隔

SVM附录
1. 范数
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
向量的范数定义:向量的范数是一个函数||x||,满足非负性||x|| >= 0,齐次性||cx|| = |c| ||x|| ,三角不等式||x+y|| <= ||x|| + ||y||。
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
向量的范数定义:向量的范数是一个函数||x||,满足非负性||x|| >= 0,齐次性||cx|| = |c| ||x|| ,三角不等式||x+y|| <= ||x|| + ||y||。
2. 点到直线的距离
起因
今天在 PPT 里看到一个点到超平面的距离公式 \(d = 1 ∥ w ∥ ∣ w ⋅ x 0 + b ∣ d = \frac{ 1 }{ \left\| \boldsymbol w \right\| }| \boldsymbol w \cdot \boldsymbol x_0 + \boldsymbol b |*d*=∥**w**∥1∣**w**⋅**x**0+**b**∣\),看了半天没看懂为什么这样算,遂去问学霸,答曰“平面情况下就是点到直线的距离公式”。
万分惭愧,我连初中数学都忘了。
三角形面积法
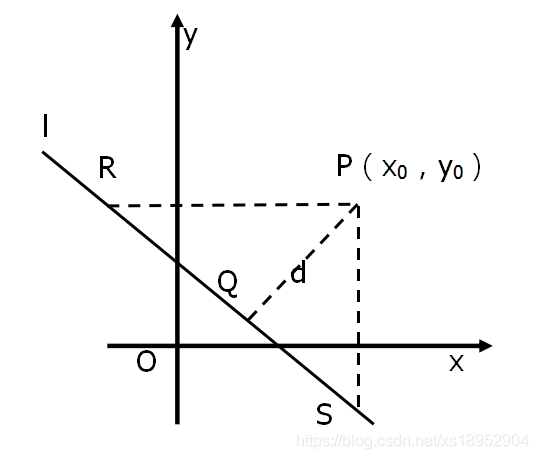
直线 l ll 方程为 A x + B y + C = 0 Ax + By + C = 0A**x+B**y+C=0,A AA、B BB 均不为 0 00,点 P ( x 0 , y 0 ) P(x_0, y_0)P(x0,y0),设点 P PP 到 l ll 的距离为 d dd。
设点 R ( x R , y 0 ) R(x_R, y_0)R(x**R,y0),点 S ( x 0 , y S ) S(x_0, y_S)S(x0,y**S)。
由 R , S R, SR,S 在直线 l ll 上,得到
\(A x R + B y 0 + C = 0\)
\(Ax_R + By_0 + C = 0\)
$A x 0 + B y S + C = 0 $
\(Ax_0 + By_S + C = 0*A**x*0+*B**y**S*+*C*=0\)
所以
\(x R = − B y 0 − C A x_R = \frac{ -By_0 - C }{ A }*x**R*=*A*−*B**y*0−*C*y S = − A x 0 − C B y_S = \frac{ -Ax_0 - C }{ B }*y**S*=*B*−*A**x*0−*C\)*
即
\(| P R ∣ = ∣ x 0 − x R ∣ = ∣ x 0 − − B y 0 − C A ∣ = ∣ A x 0 + B y 0 + C A ∣ | PR | = | x_0 - x_R | = | x_0 - \frac{ -By_0 - C }{ A } | = | \frac{ Ax_0 + By_0 + C }{ A } |∣*P**R*∣=∣*x*0−*x**R*∣=∣*x*0−*A*−*B**y*0−*C*∣=∣*A**A**x*0+*B**y*0+*C*∣∣ P S ∣ = ∣ y 0 − y S ∣ = ∣ y 0 − − A x 0 − C B ∣ = ∣ A x 0 + B y 0 + C B ∣ | PS | = | y_0 - y_S | = | y_0 - \frac{ -Ax_0 - C }{ B } | = | \frac{ Ax_0 + By_0 + C }{ B } |∣*P**S*∣=∣*y*0−*y**S*∣=∣*y*0−*B*−*A**x*0−*C*∣=∣*B**A**x*0+*B**y*0+*C*∣\)
于是
\(∣ R S ∣ = P R 2 + P S 2 = A 2 + B 2 A B ⋅ ∣ A x 0 + B y 0 + C ∣ | RS | = \sqrt{ { PR }^2 + { PS }^2 } = \frac{ \sqrt{ A^2 + B^2 } }{ AB } \cdot | Ax_0 + By_0 + C |∣*R**S*∣=*P**R*2+*P**S*2=*A**B**A*2+*B*2⋅∣*A**x*0+*B**y*0+*C*∣\)
由$ Δ P S R \Delta_{PSR}Δ*PSR$ 得
$d ⋅ ∣ R S ∣ = ∣ P R ∣ ⋅ ∣ P S ∣ d \cdot | RS | = | PR | \cdot | PS $
\(|d⋅∣RS∣=∣PR∣⋅∣PS∣\)
即
\(d=∣R*S∣∣P*R∣⋅∣P*S∣=A*B*A*2+B*2⋅∣A*x*0+*B*y*0+C*∣∣A*A*x*0+*B**y*0+*C*∣⋅∣B*A*x*0+B*y*0+C∣=A*2+*B*2∣A*x*0+*B*y*0+C∣\)
另一种形式
设函数 \(f ( x , y ) = A x + B y + C f(x, y) = Ax + By + C*\)f(x,y)=Ax+By+C$,直线 l : \(A x + B y + C = 0 l: Ax + By + C = 0*l*:*A**x*+*B**y*+*C*=0\) 的法向量为 v ( A , B ) \boldsymbol v(A, B)v(A,B*)。
则点 P ( x 0 , y 0 ) P(x_0, y_0)P(x0,y0) 到直线 l ll 的距离 d dd 为
\(d = ∣ A x 0 + B y 0 + C ∣ A 2 + B 2 = f ( x 0 , y 0 ) ∥ v ∥ d = \frac{ | Ax_0 + By_0 + C | }{ \sqrt{ A^2 + B^2 } } = \frac{ f(x_0, y_0) }{ \left\| \boldsymbol v \right\| }*d*=*A*2+*B*2∣*A**x*0+*B**y*0+*C*∣=∥**v**∥*f*(*x*0,*y*0)\)
注:∥ v ∥ \left| \boldsymbol v \right|∥v∥ 为向量 v \boldsymbol vv 的 2-范数
3. 为什么某个拉格朗日乘子大于等于0
转载:【整理】深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件 - mo_wang - 博客园 (cnblogs.com)
(1) 无约束条件
这是最简单的情况,解决方法通常是函数对变量求导,令求导函数等于0的点可能是极值点。将结果带回原函数进行验证即可。
(2)等式约束条件
举个二维最优化的例子:
min f(x,y)
s.t. g(x,y) = c
这里画出z=f(x,y)的等高线(函数登高线定义见百度百科):

绿线标出的是约束g(x,y)=c的点的轨迹。蓝线是f(x,y)的等高线。箭头表示斜率,和等高线的法线平行。从梯度的方向上来看,显然有d1>d2。绿色的线是约束,也就是说,只要正好落在这条绿线上的点才可能是满足要求的点。如果没有这条约束,f(x,y)的最小值应该会落在最小那圈等高线内部的某一点上。而现在加上了约束,最小值点应该在哪里呢?显然应该是在f(x,y)的等高线正好和约束线相切的位置,因为如果只是相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与约束函数的交点的值更大或者更小,只有到等高线与约束函数的曲线相切的时候,可能取得最优值。
如果我们对约束也求梯度∇g(x,y),则其梯度如图中绿色箭头所示。很容易看出来,要想让目标函数f(x,y)的等高线和约束相切,则他们切点的梯度一定在一条直线上(f和g的斜率平行)。
也即在最优化解的时候:∇f(x,y)=λ(∇g(x,y)-C) (其中∇为梯度算子; 即:f(x)的梯度 = λ* g(x)的梯度,λ是常数,可以是任何非0实数,表示左右两边同向。)
即:▽[f(x,y)+λ(g(x,y)−c)]=0λ≠0
那么拉格朗日函数: F(x,y)=f(x,y)+λ(g(x,y)−c) 在达到极值时与f(x,y)相等,因为F(x,y)达到极值时g(x,y)−c总等于零。
min( F(x,λ) )取得极小值时其导数为0,即▽f(x)+▽∑ni=λihi(x)=0,也就是说f(x)和h(x)的梯度共线。
简单的说,在F(x,λ)取得最优化解的时候,即F(x,λ)取极值(导数为0,▽[f(x,y)+λ(g(x,y)−c)]=0)的时候,f(x)与g(x) 梯度共线,此时等高线与约束函数g(x)相切,此时就是在条件约束g(x)下,f(x)的最优化解。
(3)不等式约束条件
设目标函数f(x),不等式约束为g(x),有的教程还会添加上等式约束条件h(x)。此时的约束优化问题描述如下:
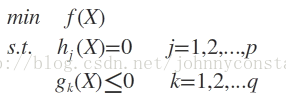
则我们定义不等式约束下的拉格朗日函数L,则L表达式为:
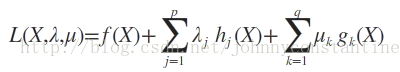
其中f(x)是原目标函数,hj(x)是第j个等式约束条件,λj是对应的约束系数,gk是不等式约束,uk是对应的约束系数。
常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + ag(x)+bh(x),
KKT条件是说最优值必须满足以下条件:
1)L(a, b, x)对x求导为零;
2)h(x) =0;
3)a*g(x) = 0;
求取这些等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
接下来主要介绍KKT条件,推导及应用。详细推导过程如下:


4. SMO算法
两个变量二次规划的求解方法
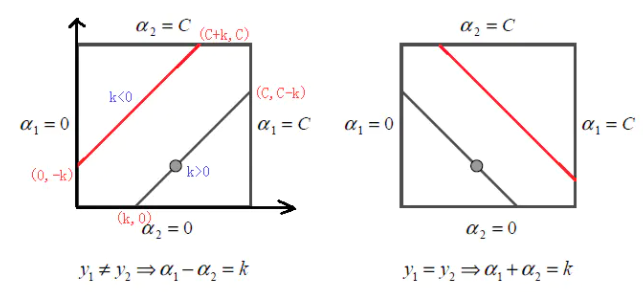
根据上面的约束条件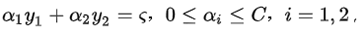 ,又由于y1,y2均只能取值1或者-1, 这样α1,α2 在[0,C]和[0,C]形成的盒子里面,并且两者的关系直线的斜率只能为1或者-1,也就是说α1,α2 的关系直线平行于[0,C]和[0,C]形成的盒子的对角线,
,又由于y1,y2均只能取值1或者-1, 这样α1,α2 在[0,C]和[0,C]形成的盒子里面,并且两者的关系直线的斜率只能为1或者-1,也就是说α1,α2 的关系直线平行于[0,C]和[0,C]形成的盒子的对角线,
\(α_1 - α_2 = ζ\)
\(α_2 - α_1 = ζ\)
\(α_1 + α_2 = ζ\)
如下图所示:


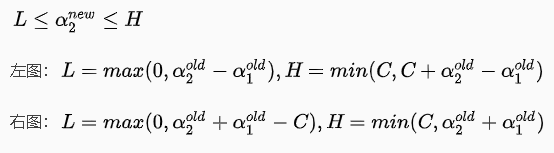
alpha
2. AdaBoost算法
思想:从训练数据中学习一系列弱分类器,并将这些若分类器组合成为一个强分类器
假设给定一个二分类的训练数据集
\(T = {(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}\)
\(x\) 是实例空间,\(y\)是标记合集
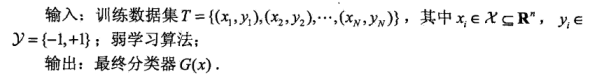
(1)初始化训练数据的权值分布
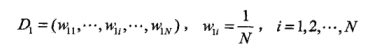
(2)对\(m=1,2,..,M\)
(a)使用具有权值分布\(D_m\)的训练数据集学习,得到基本分类器
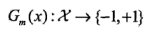
(b)计算\(G_m(x)\)在训练数据集上的分类误差率
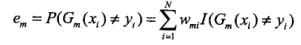
(c)计算\(G_m(x)\)的系数
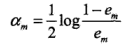
这里的对数是自然对数
(d)更新训练数据集的权值分布
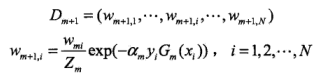
这里,\(Z_m\)是规范化因子
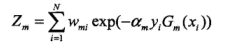
它使\(D_m+1\)成为一个概率愤怒
(3)构建基本分类器的线性组合
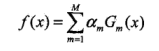
得到最终分类器



 浙公网安备 33010602011771号
浙公网安备 33010602011771号