爬取笔趣阁小说
仅供学习参考,其他用途概不负责
爬取链接:辰东的深空彼岸 https://www.bbiquge.net/book_132488/
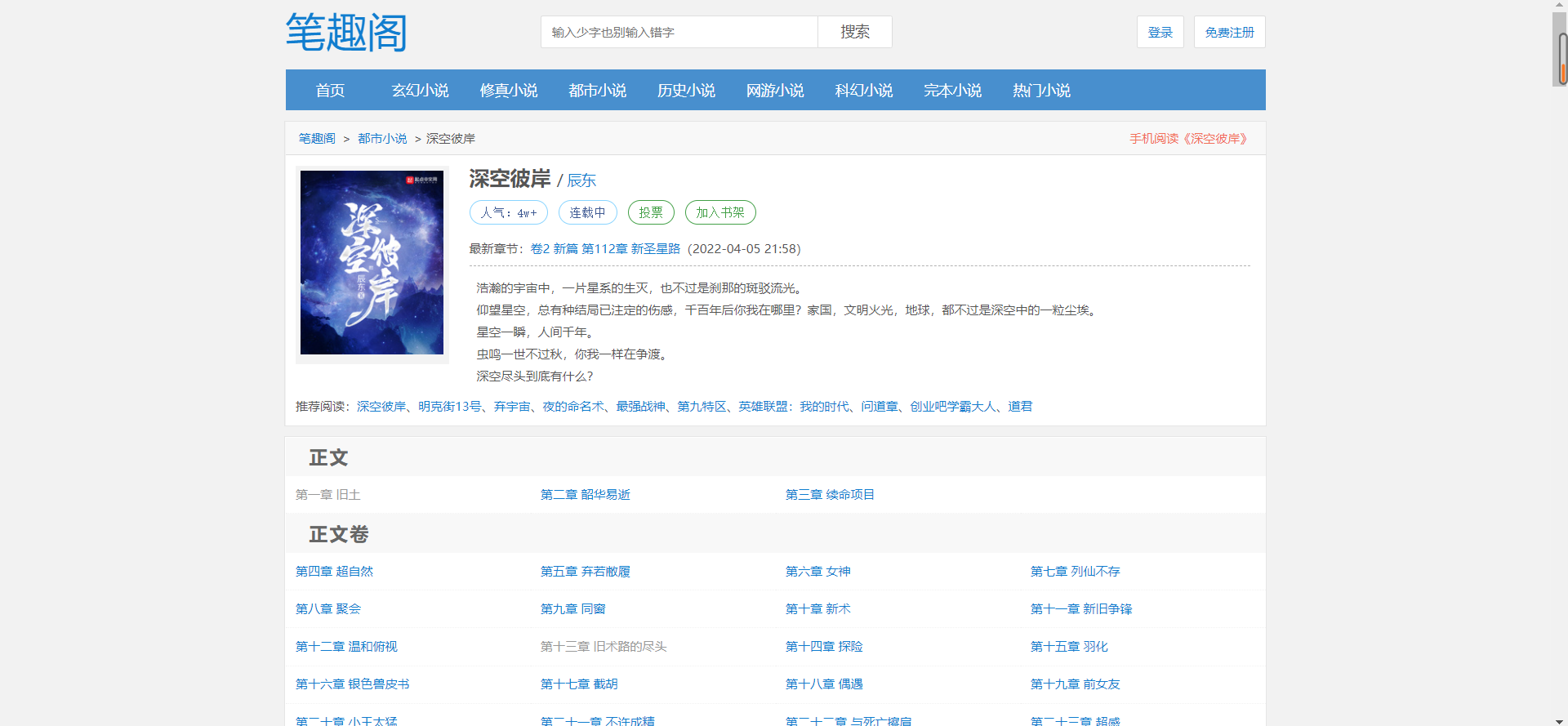
当然也可以爬取其他小说,改一下id就行
book_id字段
https://www.bbiquge.net/book_132488
1. 爬取思路
- 向服务器发起请求
- 获取服务器响应response
- 解析html网页,得到想要的信息
- 保存我们爬取的信息
2. 爬取准备
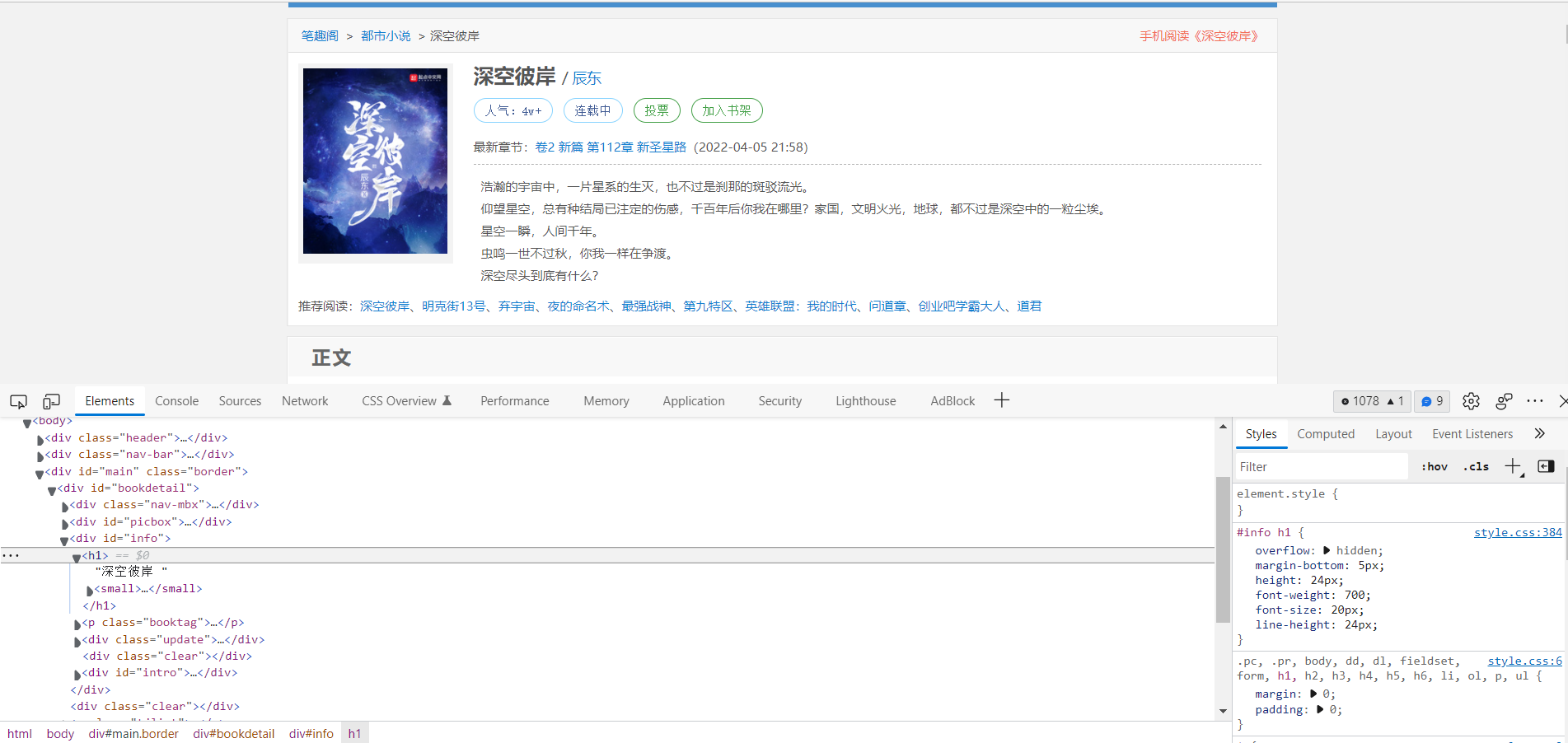
从书籍详情页爬取书籍名称,作者,还有每一章的链接,这里我们使用parsel的CSS选择器
构建方式也很简单
selector = parsel.Selector(html)
book_name = selector.css('#info h1::text').get() # 小说名字
author = selector.css('#info small a::text').get() # 作者
hrefs = selector.css('.zjlist dd a::attr(href)').getall() # 小说章节url
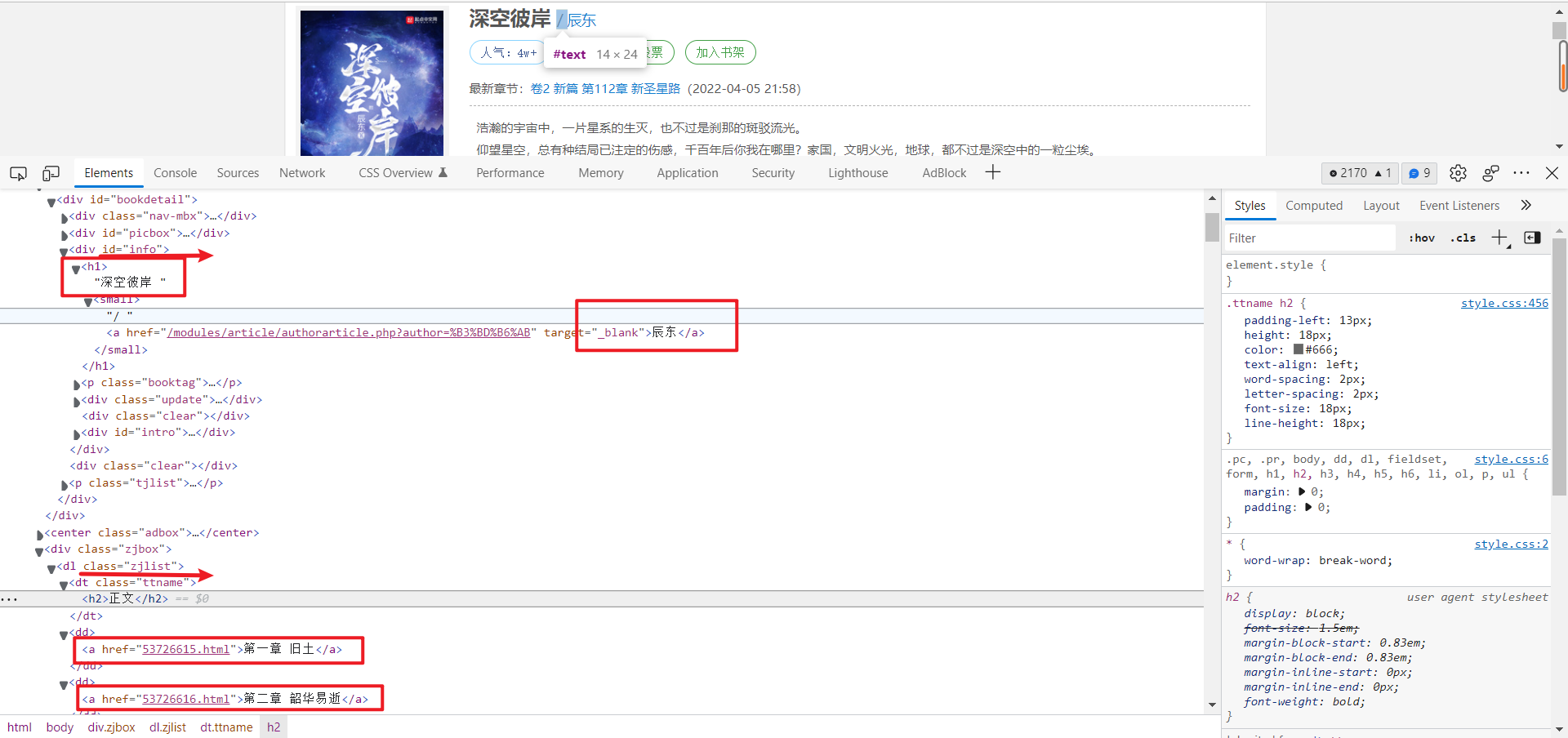
得到每章的标题和小说内容
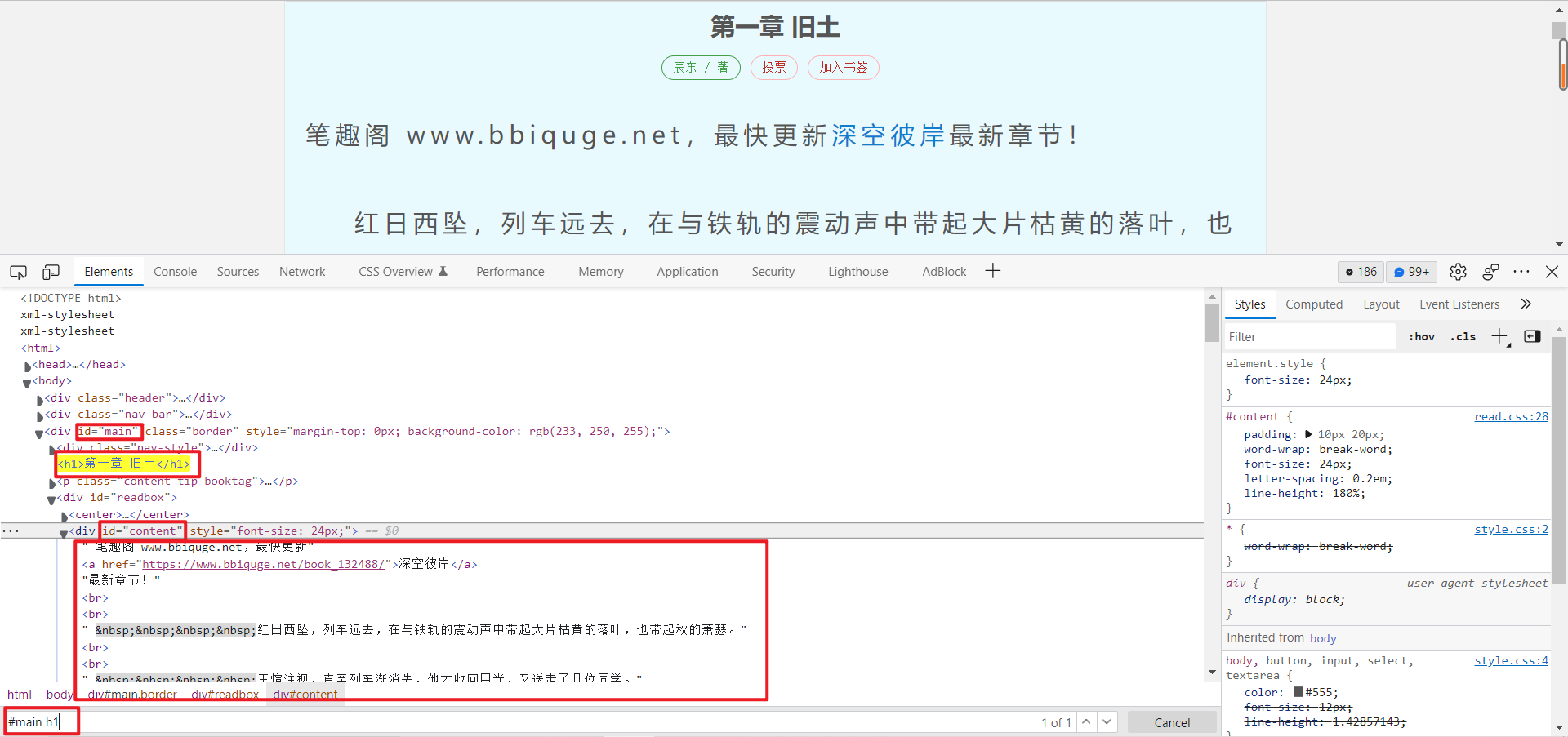
title = selector1.css('#main h1::text').get() # 每章的标题
content_list = selector1.css('#main #content::text').getall() # 小说内容以列表存储
3. 代码部分
import requests
import parsel
url = 'https://www.bbiquge.net/book_132488/'
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
selector = parsel.Selector(html)
book_name = selector.css('#info h1::text').get() # 小说名字
author = selector.css('#info small a::text').get() # 作者
hrefs = selector.css('.zjlist dd a::attr(href)').getall() # 小说章节url
for href in hrefs:
# https://www.bbiquge.net/book_132488/53726615.html
url1 = url + href # 每章的url
response1 = requests.get(url1, timeout=30)
response1.encoding = 'gbk' # 小说网页采取gbk编码,直接给出编码方式提高爬取速度
selector1 = parsel.Selector(response1.text)
title = selector1.css('#main h1::text').get() # 每章的标题
content_list = selector1.css('#main #content::text').getall() # 小说内容以列表存储
content = '\n'.join(content_list).replace(' 笔趣阁 www.bbiquge.net,最快更新\n最新章节!', '') # 去除每章开头的无关部分
with open('./book/' + book_name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
print(title)
print('下载完成!!!')
4. 总结
爬取笔趣阁比较简单,不需要伪装headers,主要是对爬取下来的网页的信息提取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号