
Linux之CPU缓存
CPU 缓存
系统中最快的存储是处理器中的寄存器。但寄存器由于造价比较昂贵,提供的空间也非常有限。因此系统中必须使用存储量大但速度慢的主存(内存)。
高速缓存的速度都比主存快。主存的访问时间是8纳秒以上,而缓存的访问时间只有几个CPU时钟周期。在标准的 X86 平台下,一般有L1 L2 L3 三级缓存。
L1 是速度最快的但容量极小,一般位于 CPU 里面。L2比L1速度慢,但容量稍大一些,L3 是容量最大的般会有几 M,一般位于主板上,速度最慢。但依然比主存要快。
通过使用 lscpu 可以查看到 CPU 的缓存情况。
缓存架构
缓存被组织成缓存线(cacheline)。可以缓存特定的位置。一般都会有指令缓存和数据缓存。
在多核处理器系统中,每个CPU 都有独立的缓存并且有独立的缓存控制器,当处理器引用缓存时,缓存控制器先检查请求的地址是否存在于缓存中。
-
Cache-hit:缓存命中。
-
Cache-miss:请求的内存不在cache中,需要从主存中读取。
-
Cache line fill:处理器将数据存储在高速缓存的过程。
多处理器系统中,需要保持缓存一致性。如果一个处理器更新了缓存。它必须让系统中其他处理器知道缓存的更新,这种被称为 cache-snoop。
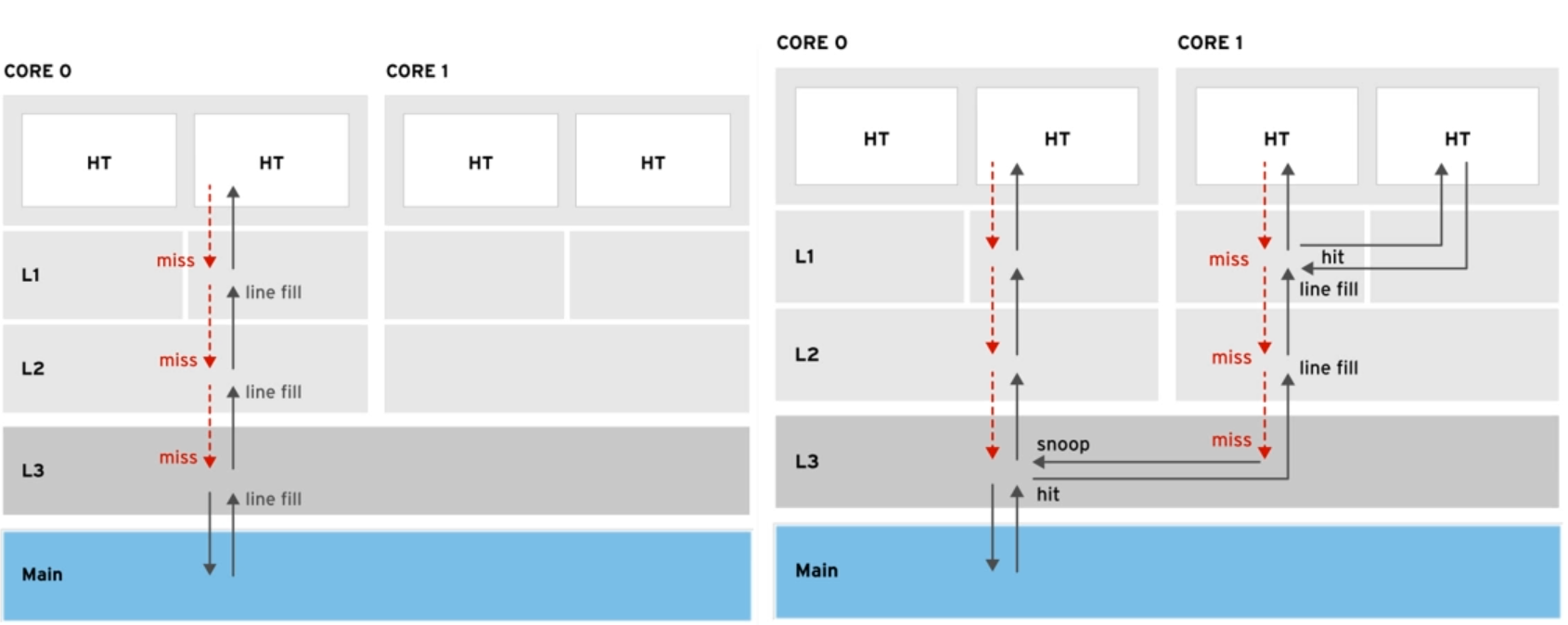
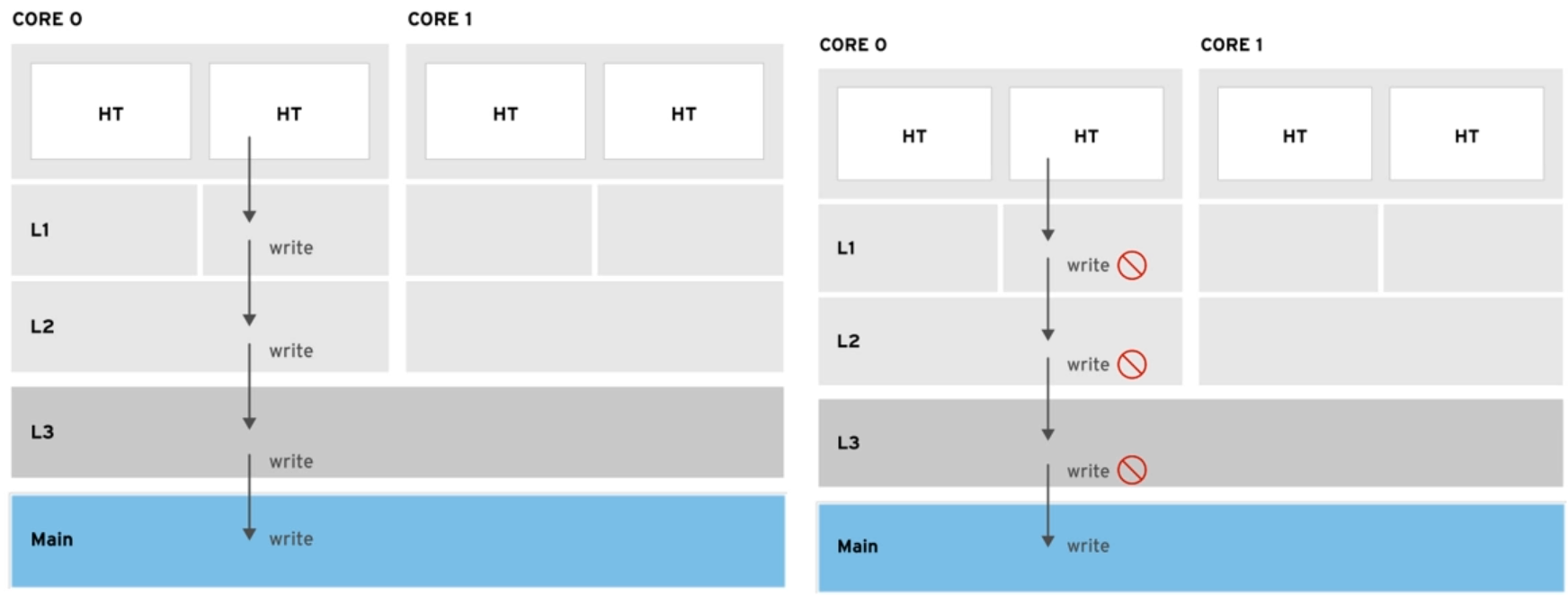
缓存写回策略
Wirte-through:立刻同步到主存。
Wirte-back:在重新分配缓存之前,缓存不会被立刻写入主存中。效率更高
缓存关联
-
直接映射:最便宜的缓存类型,缓存的每一行只能缓存主存中的特定位置。
-
全关联映射:最昂贵的缓存类型,可以缓存主存中的任意位置,这需要更多电路来实现。
-
组关联映射:是前两者的折中。也被称为N路关联。其中N是2的幂。
使用 Valgrind 分析 CPU 缓存
Valgrind 提供了一组用于内存调试和分析的工具,其中提供了 cachegrind 工具,它是进行缓存模拟。此工具记录一下内容:
-
L1:指令缓存的读和丢失(misses)
-
L2:数据缓存的读加载,读丢失,写加载和写丢失
-
L2:缓存的读加载和读丢失,以及写加载和写丢失
使用 valgrind 命令时,追加--tool=cachegrind 选项。
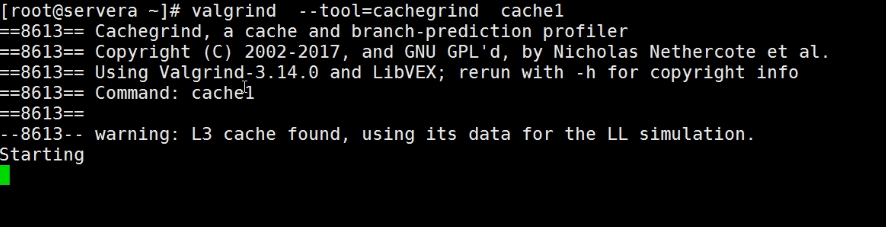
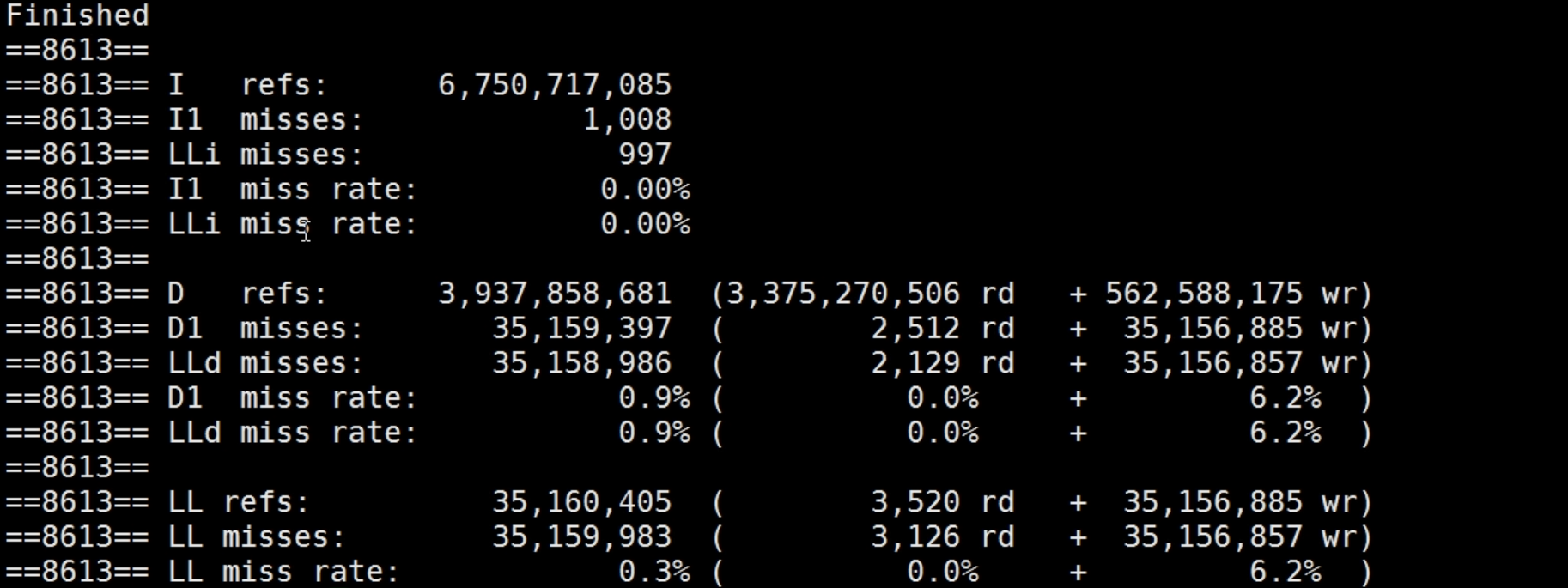

 浙公网安备 33010602011771号
浙公网安备 33010602011771号