
Linux三剑客之awk
Linux三剑客区别
- grep:普通搜索,更适合单纯的查找或匹配文本
- sed:每次读入一行来处理的,sed 适合简单的文本替换和搜索,sed读取一行,以行作为单位,进行处理。
- awk:每次读入一行来处理的(同sed),但awk读取一行,切割成字段,以字段为单位,进行细节处理。
awk工作原理
根据处理的模式,一次从文件中读取一行文本,依次从文件中取出一行文本,按照字符串的分隔符进行切割。默认使用空白字符当作分隔符。用$变量引用。
源文本:this is a test
切割后:
this is a test
$1 $2 $3 $4
AWK 工作流程可分为三个部分:
- 读输入文件之前执行的代码段(由BEGIN关键字标识)。
- 主循环执行输入文件的代码段。
- 读输入文件之后的代码段(由END关键字标识)。
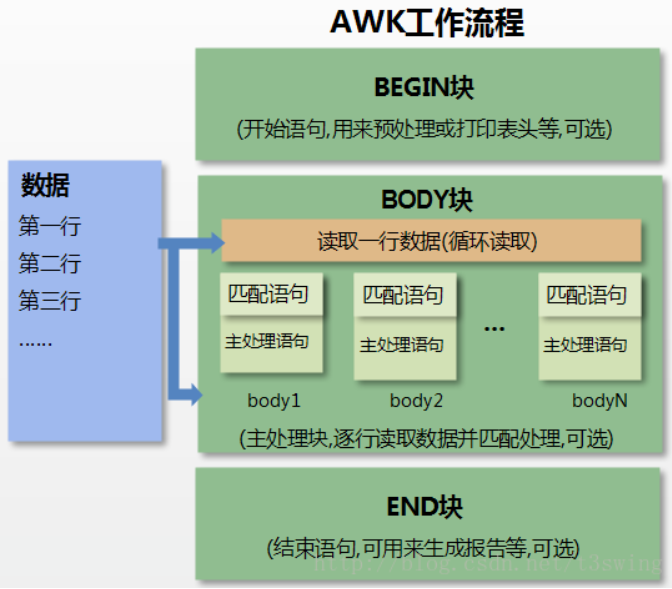
1、通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。
2、完成 BEGIN 块的执行,开始执行body块。
3、读入有 \n 换行符分割的记录。
4、将记录按指定的域分隔符划分域,填充域,$0 则表示所有域(即一行内容),$1 表示第一个域,$n 表示第 n 个域。
5、依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。
6、循环读取并执行各行直到文件结束,完成body块执行。
7、开始 END 块执行,END 块可以输出最终结果。
awk的用法
awk options 'pattern {action}' file
- options:选项参数
- pattern:模式,可选,用于指定动作执行的条件。如果没有指定模式,动作将对所有输入记录执行。
- action:动作,必须指定,用于定义当模式匹配时 awk 应该执行的操作
options 参数说明:
-F <分隔符> 或 --field-separator=<分隔符>: 指定输入字段的分隔符,默认是空格。使用这个选项可以指定不同于默认分隔符的字段分隔符。
-v <变量名>=<值>: 设置 awk 内部的变量值。可以使用该选项将外部值传递给 awk 脚本中的变量。
-f <脚本文件>: 指定一个包含 awk 脚本的文件。这样可以在文件中编写较大的 awk 脚本,然后通过 -f 选项将其加载。
-V 或 --version: 显示 awk 的版本信息。
-h 或 --help: 显示 awk 的帮助信息,包括选项和用法示例。
awk的内置变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 定义行分隔符(默认行分割符是换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
awk的printf格式
在 awk 中,printf 函数提供了多种格式化选项,类似于 C 语言中的 printf。
以下是一些常用的格式说明符:
- %d 或 %i:用于打印一个十进制的整数。
- %u:用于打印一个无符号整数。
- %x 或 %X:用于打印一个十六进制数,%x 输出小写字母,%X 输出大写字母。
- %o:用于打印一个八进制数。
- %f:用于打印一个浮点数,默认情况下会打印六位小数。
- %.精度f:指定浮点数打印的精度(小数点后的位数)。
- %e:科学计数法打印浮点数,例如:1.2345e+02。
- %E:与 %e 类似,但是使用大写字母 E。
- %g:通用格式,根据数值的大小自动选择 %f 或 %e。
- %G:与 %g 类似,但是使用大写字母 E 表示科学计数法。
- %c:打印一个字符。
- %s:打印一个字符串。
- %%:打印 % 字符。
除了这些基本格式说明符外,awk 的 printf 还支持一些额外的格式化选项,包括:
- 宽度:例如 %10d 表示至少打印 10 个字符宽的整数,如果数值不足 10 位,则左边填充空格。
- 精度:只对浮点数有效,例如 %.2f 表示打印小数点后两位的浮点数。
- 填充字符:例如 %010d 使用 0 作为填充字符,而不是空格。
- 对齐:- 表示左对齐,例如 -%10s 表示字符串至少打印 10 个字符宽,如果不足则右边填充空格。
- 千位分隔符:%'d 表示在整数中每隔三位添加一个分隔符(通常是逗号)。
案例
- 文本样式
# cat log.txt
2 this is a test
3 Do you like awk
This's a test
10 There are orange,apple,mongo
1、各字段之间以逗号进行隔开,而输出结果则以空白字符分割。也就是awk默认输出结果也是以空白符作为分隔符。
# awk '{print $1,$4}' log.txt
2 a
3 like
This's
10 orange,apple,mongo
2、awk,必须外层单引号,内层双引号内置变量 $1、$2 都不得添加双引号,否则会识别为文本,尽量别加引号
print打印文本时,文本字符串使用用双引号,不能使用单引号
# awk '{print $1,"hello"$4}' log.txt
2 helloa
3 hellolike
This's hello
10 helloorange,apple,mongo
hello
3、执行BEGIN模式,不需要指定文本就可以打印出。
[root@prome-01 ~]# awk 'BEGIN {print"line one\nline two\nline three"}'
line one
line two
line three
4、输入输出分隔符
awk -F: 指定输入分隔符
OFS="#" 指定输出分隔符
FS=":" 指定输入分隔符
# awk 'BEGIN {OFS="#"} {print $1,$3}' log.txt
2#is
3#you
This's#test
10#are
#
5、打印文件每行字段的个数
# awk '{print NF}' log.txt
5
5
3
4
0
6、awk定义变量并赋值,awk中打印变量无需加$符号
# awk 'BEGIN{var="variable testing";print var}'
variable testing
# awk -v test="hello awk" 'BEGIN{print test}'
hello awk
7、pintf
# awk 'BEGIN{ printf "Hello, world!\n" }'
Hello, world!
"%-10s%-10s\n" 是一个格式化字符串,其中 %-10s 表示左对齐并占用10个字符宽度的字符串,\n 表示换行符。
# awk '{printf "%-10s%-10s\n",$1,$3}' log.txt
2 is
3 you
This's test
10 are
8、正则表达式模式
使用斜杠 / 包围的模式,可以是复杂的正则表达式。例如,awk '/^#/ { print }' 会打印所有以 "#" 开头的行。
匹配以r开头的行
# awk '/^r/{print $1}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
# awk -F: '/^r/{print $1}' /etc/passwd
root
9、条件模式
使用运算符进行条件表达式
显示用户的ID号大于等于500的用户
# awk -F: '$3>=500{print $1,$3}' /etc/passwd
polkitd 999
chrony 998
nginx 997
# awk -F: '$3+1>=500{print $1,$3}' /etc/passwd
polkitd 999
chrony 998
nginx 997
这个 awk 命令是用来从 /etc/passwd 文件中筛选出使用 Bash shell 的用户
# awk -F: '$7~"bash$"{print $1,$7}' /etc/passwd
root /bin/bash
'$7~"bash$":这是一个条件表达式,
$7 指的是每行的第七个字段,通常这个字段表示用户的登录 shell。
~ 是正则表达式匹配运算符,"bash$" 是一个简单的正则表达式,表示匹配字段以 "bash" 结尾的行。
取反
# awk -F: '$7!~"bash$"{print $1,$7}' /etc/passwd
10、范围模式
使用方括号 [] 包围的字符集,可以匹配其中的任意单个字符。例如,awk '/[A-Z]/ { print }' 会打印包含任意大写字母的行。
匹配第一个以r开头的行到第一个以m开头的行
# awk -F: '/^r/,/^m/{print $1,$7}' /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
# awk -F: '$3==0,$7~"nologin" {print $1,$3,$7}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
# awk -F: '$3==0,$7~"nologin" {printf "%-10s%-10s%-20s\n",$1,$3,$7}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
11、BEGIN/END:特殊模式,
仅在awk命令执行前运行一次或结束前运行一次
打印表头
# awk -F: 'BEGIN{print "Username ID Shell"} {printf "%-10s%-10s%-20s\n", $1, $3, $7}' /etc/passwd
Username ID Shell
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
sshd 74 /sbin/nologin
postfix 89 /sbin/nologin
chrony 998 /sbin/nologin
grafana 997 /sbin/nologin
es 1000 /bin/bash
打印表尾
# awk -F: 'BEGIN{print "Username ID Shell"} {printf "%-10s%-10s%-20s\n", $1, $3, $7}END {print "End of report"}' /etc/passwd
Username ID Shell
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
sshd 74 /sbin/nologin
postfix 89 /sbin/nologin
chrony 998 /sbin/nologin
grafana 997 /sbin/nologin
es 1000 /bin/bash
12、语句
# awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' /etc/passwd
root Admin
bin Common User
daemon Common User
adm Common User
lp Common User
sync Common User
shutdown Common User
halt Common User
mail Common User
operator Common User
games Common User
ftp Common User
nobody Common User
systemd-network Common User
dbus Common User
polkitd Common User
sshd Common User
postfix Common User
chrony Common User
nginx Common User
ntp Common User
apache Common User
tcpdump Common User
named Common User
# awk -F: '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "common User"}' /etc/passwd
root : Admin
bin : common User
daemon : common User
adm : common User
lp : common User
sync : common User
shutdown : common User
halt : common User
mail : common User
operator : common User
games : common User
ftp : common User
nobody : common User
systemd-network: common User
dbus : common User
polkitd : common User
sshd : common User
postfix : common User
chrony : common User
nginx : common User
ntp : common User
apache : common User
tcpdump : common User
named : common User
# awk -F: -v sum=0 '{if ($3>=500) sum++} END{print sum}' /etc/passwd
3
# awk -F: '{i=1;while (i<=3) {print $i;i++}}' /etc/passwd
13、数组
array [index-expression]
index-expression可以使用任意字符串;需要注意的是,如果某数据组元素事先不存在,那么在引用其时,an会自动创建此元素并初始化为空串;因此,要判新某数据组中是否存在某元素,需要使用index in array的方式,
要遍历数组中的每一个元素,需要使用如下的特殊结构:
for (var in varry ) {statement1,...}
其中var用于引用数组下标,而不是元素值:
# netstat -ant | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]}'
LISTEN 12
ESTABLISHED 125
SYN_SENT 4
TIME_WAIT 1
/^tcp/:匹配以"tcp"开头的行,即TCP连接的行。
{++S[$NF]}:对于每行匹配的行,增加S数组中最后一个字段($NF表示最后一列)的计数。这里假设最后一个字段是连接状态。
END {for(a in S) print a,S[a]}:在处理完所有行后,打印S数组中的每个键(连接状态)和对应的值(该状态的计数)
# awk '{counts[$1]++}; END {for(url in counts) print counts[url], url}' /var/log/httpd/access_log
统计Apache HTTP服务器访问日志文件(/var/log/httpd/access_log)中的URL访问次数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号