
ELK
ELK
ELK是Elasticsearch(ES)、Logstash、Kibana的结合,是一个开源日志收集软件。
-
Elasticsearch(ES):开源分布式搜索引擎,提供搜集、分析、存储数据功能。
-
Logstash:日志搜集、分析、过滤,支持大量数据获取。其自带输入(input)、过滤语法(grok)、输出(output)三部分。
其输入有两种方式:①由各beat采集器输入,经过滤后输出到ES ②本机数据输入,经过滤后输出到ES。
-
Kibana:提供日志分析友好的 Web 界面。数据存储到ES中后,可以在Kibana页面上增删改查,交互数据,并生成各种维度表格、图形。
-
Filebeat:Filebeat是一个轻量级的日志收集处理工具(Agent),占用资源少,官方也推荐此工具。还有其他beat等,可以在各服务器上搜集信息,传输给Logastash。
总的来说就是:beats+Logstash收集,ES存储,Kibana可视化及分析。
Elasticsearch结构
elasticsearch是面向文档型数据库
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。Elasticsearch 7.X之前。
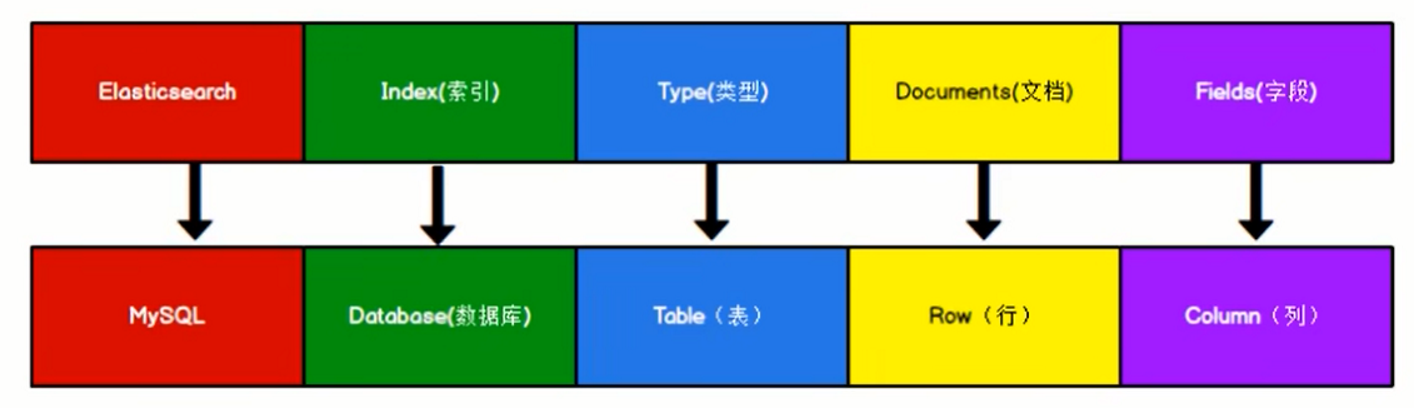
Elasticsearch 7.X之前,ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type。
Elasticsearch 7.X 中,Type 的概念已经被删除了,所以在7.X之后版本,索引也可以类似mysql中的表概念。
- MySQL 中的表(Table)对应于 Elasticsearch 中的索引(Index)。
- MySQL 中的行(Row)对应于 Elasticsearch 中的文档(Document)。
- MySQL 中的字段(Field)对应于 Elasticsearch 中的字段(Field)。
ES集群组件
1、Cluster
- ES的集群标识为集群名称,默认为"elasticsearch"。节点就是靠此名字来决定加入到哪个集群中。一个节点只能属于一个集群。
- 在 Elasticsearch 中,集群(Cluster)是由一个或多个节点(Node)组成的分布式系统。这些节点协同工作,共同存储、索引和搜索数据,提供高可用性、可伸缩性和容错性。
2、Node
- 运行了单个ES实例的主机即为节点。用于存储数据、参与集群索引及搜索操作。节点的标识靠节点名。
- Elasticsearch中的节点(Node)指的是Elasticsearch实例的运行实例,即一个独立的Elasticsearch服务进程。
- 每个节点都是一个独立的工作单元,负责存储数据、参与数据处理(如索引、搜索、聚合等)以及参与集群的协调工作。
3、Shard
- 将索引切割成为的物理存储组件,但每一个shard都是一个独立且完整的索引。
- 创建索引时,ES默认将其分割为5个shard,用户也可以按需自定义。创建完成后不可修改。
- 索引可以包含一个或多个分片(Shards),每个分片都是一个 Lucene 实例,可以独立地进行搜索和存储操作。
- 分片允许 Elasticsearch 在多个服务器上水平扩展,从而处理更多的数据和查询。
- shard有两种类型,primary shard和replica
4、Replicas
- 每个分片可以有零个或多个副本(Replicas),副本是分片的完整拷贝,用于提供数据的冗余和容错性。当某个分片所在的服务器出现故障时,可以从其副本中恢复数据。
- Replicas用于数据冗余及査询时的负载均衡,每个主shard的副本数量可自定义,且可动态修改。
5、索引(index)
- 文档的集合(容器),类似于关系型数据库(MySQL)中的表。
- 索引是具有类似属性的文档的集合,类似于表。每一个索引都对应一个物理文档。
- 索引名字必须是小写;
6、类型(type)
- 类型是索引内部的逻辑分区,其意义完全取决于用户需求,
- 一个索引内部可以定义一个和多个类型;
- 类型是拥有相同域的文档的预定义,可以在一个索引中存储不同类型的数据。相当于表结构。
- 类型是定义数据的格式
7、文档(document)
在 Elasticsearch 中,文档(Document)是存储在索引(Index)中的基本数据单位。每个文档都是一个 JSON 格式的数据对象,它包含了一系列字段(Field)和对应的值。文档可以被索引、检索、更新和删除。
- 文档是Lucene索引和搜索的原子单位,包含了一个或多个域(字段),是域的容器,文档就是一条一条数据。
- 文档(Document)在 Elasticsearch 中相当于 MySQL 中的行(Row)。就像 MySQL 中的每一行代表一个数据记录,而 Elasticsearch 中的每个文档也代表着一个数据实体。因此,文档和行都是存储在数据库中的基本数据单位,它们都包含了一系列的字段和对应的值。
- 文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
8、映射(mapping)
- 原始内容存储为文档之前需要事先进行分析;
- 映射定义此分析机制该如何实现;
- ES还为映射提供了诸如将域中的内容排序等功能;
- 映射是定义格式里的数据该如何被分析
ES集群的工作过程
启动时,通过多播(默认)或单播方式在9300/tcp查找同一集群中的其它节点,并与之建立通信。
集群中的所有节点会选举出一个主节点负责管理整个集群状态,以及在集群范围内决定各shards的分布方式。站在用户角度而言,每个均可接收并响应用户的各类请求。
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引,创建索引,那么索引将会有个5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard ,又称复制分片)
- 三节点集群
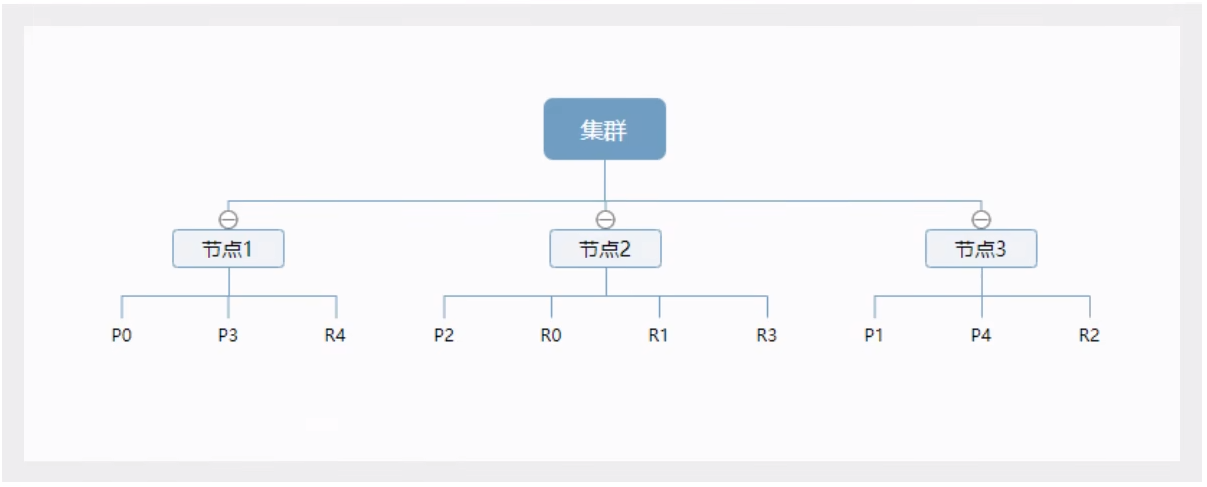
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至干丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引原理
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。
这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
- 案例
现在有两个文档,每个文档包含如下内容:
study every day,good good up to forever # 文档1包含的内容
To forever,study every day,good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档。
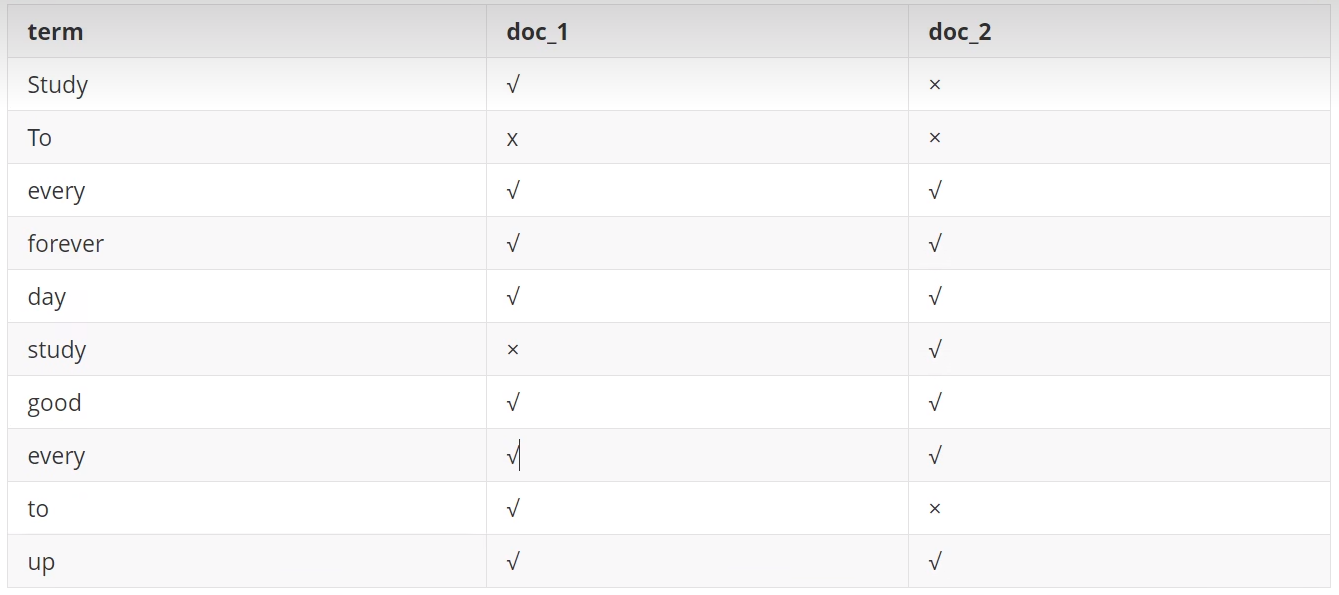
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档。

两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回
- 案例
比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
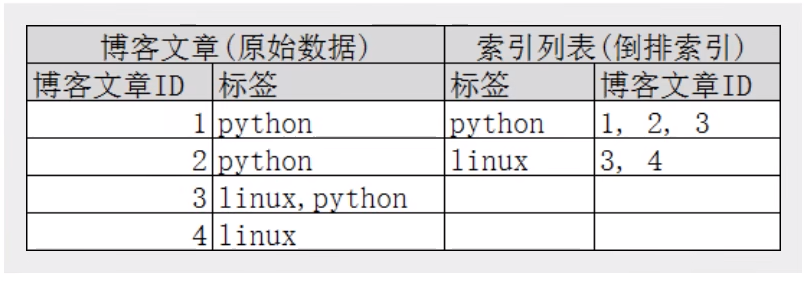
如果要捜索含有 python 标签的文章,那相对于査找所有原始数据而言,査找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。
所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
安装
1、安装Elasticsearch
参考
2、安装Kibana
官网
- 解压安装
# tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz
# ln -sv kibana-7.6.1-linux-x86_64 kibana
"kibana" -> "kibana-7.6.1-linux-x86_64"
# cd kibana
- 修改配置
# vim config/kibana.yml
server.port: 5601 #kibana端口
server.host: "0.0.0.0" #所有主机都能访问,或者也可以指定一个ip
elasticsearch.hosts: "http://es服务公网IP:9200" #配置es的访问地址
kibana.index: ".kibana"
- 启动kibana
# chown -R es:es /data/apps/kibana-7.6.1-linux-x86_64 #Kibana和es一样,不能用root用户启动需要创建es用户( 如果安装es时已创建es用户并且安装在同一台服务器只需要给kibana目录授权即可 )
# su es
$ cd kibana
$ cd bin/
$ ./kibana
-
访问
http://服务器IP:5601/
选择开发工具
-
WEB界面汉化
修改配置文件
# vi kibana.yml
i18n.locale: "zh-CN"
重启kibana服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号