MySQL之磁盘I/O过高排查
导读
有个MySQL服务器的磁盘I/O总有过高报警,怎么回事?
有哪些原因
MySQL服务器最近总是报告磁盘I/O非常高,出现这种问题,一般来说,磁盘I/O很高无非是下面几个原因引起:
磁盘子系统设备性能差,或采用ext2/ext3之类文件系统,或采用cfq之类的io scheduler,所以IOPS提上不去;
SQL效率不高,比如没有索引,或者一次性读取大量数据,所以需要更多的I/O;
可用内存太小,内存中能缓存/缓冲的数据不多,所以需要更多的I/O。
方法论已有,接下来就是动手开始排查了。
怎么排查
先看磁盘I/O设备,是由十几块SSD组成的RAID 10阵列,按理说I/O性能应该不至于太差,看iops和%util的数据也确实如此。
再来看下文件系统、io scheduler的因素,发现采用xfs文件系统,而且io scheduler用的是noop,看来也不是这个原因。而且看了下iostat的数据,发现iops也不算低,说明I/O能力还是可以的。

再来看看当前的processlist,以及slow query log,也没发现当前有特别明显的slow query,所以也不是这个原因了。
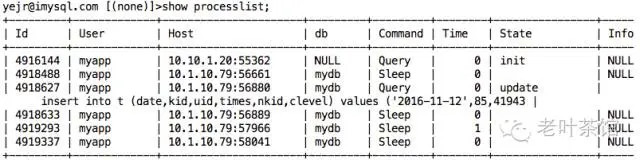
现在只剩下内存不足这个因素了,看了下服务器物理内存是64G,用系统命令 free 看了下,发现大部分都在cached,而free的也不多。观察InnoDB相关的配置以及status,看能不能找到端倪。
首先,看下 innodb-buffer-pool-size 分配了多少:

嗯,分配了18G,好像不是太多啊~
再看一下 innodb status:
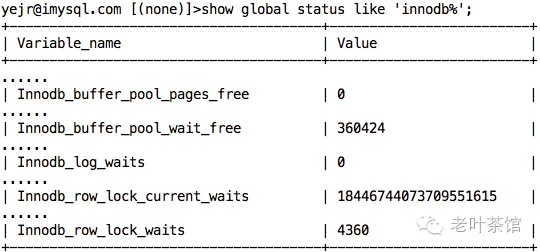
重点关注下几个wait值,再看下show engine innodb结果:

更为诡异的是,在已经停掉SLAVE IO & SQL线程后,发现redo log还在一直增长...
第一次看

停掉SLAVE线程后过阵子再看

看到这里,有经验的DBA应该基本上能想明白了,主要是因为 innodb buffer pool 太小,导致了下面几个后果:
- dirty page 和 data page 之间相互“排挤抢占”,所以会出现 Innodb_buffer_pool_wait_free 事件;
- redo log 也没办法及时刷新到磁盘中,所以在SLAVE线程停掉后,能看到LSN还在持续增长;
- 同时我们也看到unpurge的列表也积攒到很大(111万),这导致了ibdata1文件涨到了146G之大,不过这个可能也是因为有某些事务长时间未提交。
还有,不知道大家注意到没,Innodb_row_lock_current_waits 的值竟然是 18446744073709551615(想想bigint多大),显然不可能啊。事实上,这种情况已经碰到过几次了,明明当前没有行锁,这个 status 值却不小,查了一下官方bug库,竟然只报告了一例,bug id是#71520。
解决
既然知道原因,问题解决起来也就快了,我们主要做了下面几个调整:
- 调大innodb-buffer-pool-size,原则上不超过物理内存的70%,所以设置为40G;
- 调大innodb-purge-thread,原来是1,调整成4;
- 调大innodb_io_capacity和innodb_io_capacity_max,值分别为2万和2.5万;
调整完后,重启实例(5.7版本前调整innodb-buffer-pool-size 和 innodb-purge-thread 需要重启才生效)。再经观察,发现IOPS下降的很快,不再告警,同时 Innodb_buffer_pool_wait_free 也一直为 0,unpurge列表降到了数千级别。
IO延迟高可能的原因
压力测试过程中,如果因为资源使用瓶颈等问题引发最直接性能问题是业务交易响应时间偏大,TPS逐渐降低等。而问题定位分析通常情况下,最优先排查的是监控服务器资源利用率,例如先用TOP 或者nmon等查看CPU、内存使用情况,然后在排查IO问题,例如网络IO、磁盘IO的问题。 如果是磁盘IO问题,一般问题是SQL语法问题、MYSQL参数配置问题、服务器自身硬件瓶颈导致IOPS吞吐率问题。
今天主要是讲解MYSQL 参数配置不合理导致在高并发下磁盘IO问题,而MYSQL整体监控优化方案后面会整理《如何轻量化MYSQL服务性能监控》文章出来。
1、 打开日志跟踪引起的磁盘IO问题
例如:MySQL的日志包括错误日志(ErrorLog),更新日志(UpdateLog),二进制日志(Binlog),查询日志(QueryLog),慢查询日志(SlowQueryLog)等,正常情况下,在生产系统或者压力测试环境中很少有系统会时时打开查询日志。因为查询日志打开之后会将MySQL中执行的每一条Query都记录到日志中,会该系统带来比较大的IO负担,而带来的实际效益却并不是非常大.
2、 SQL写法问题引起磁盘IO高
例如:曾经在做某一个项目时,在看到数据库磁盘IO使用率偏高,前端查询业务交易loadrunner显示事物响应时间偏长,通过监控工具抓取对应SQL,通过计划分析,发现该SQL 中使用distinct 又多表关联且是大表、然后使用order by,最终显示10笔数据,而在产生中间过程数据进行筛选时,使用的是临时表,并把数据放入临时表中,内存刚好设置不大,于是放到磁盘中导致IO偏高。
备注:MySQL在执行SQL查询时可能会用到临时表,临时表存储,MySQL会先创建内存临时表,但内存临时表超过配置指定的值后,MySQL会将内存临时表导出到磁盘临时表;
3、 MYSQL参数配置问题
MYSQL默认配置性能低下,只能通过并发下尝试调整参数配置来逐步优化数据库性能,2017年底根据公司要求配合帮助某一家银行业务系统做性能测试,因为测试环境硬件资源有限,我跟公司申请了几台过时的笔记本,然后根据生产环境软件版本等配置要求,进行模拟搭建性能测试环境,基础软件包含:MYSQL5.6 、centos7.2、tomcat7、 JDK1.7、redis。使用的是联想L421 笔记本当MYSQL数据库服务器、L440当tomcat应用服务器,压力测试工具loadrunner、并发用户100,压力测试业务场景:用户登录退出、相关票据信息查询、电子汇票交易流程等,在压力测试过程中发现部分交易在50用户并发时,数据库磁盘I0使用率都偏高,特别是写操作一直很高,例如测试登录退出交易,经监控数据库磁盘IO率一直偏高,如下案例分析讲解:
4、 其它原因
- 一次请求读写的数据量太大,导致磁盘I/O读写值较大,例如一个SQL里要读取或更新几万行数据甚至更多,这种最好是想办法减少一次读写的数据量;
- SQL查询中没有适当的索引可以用来完成条件过滤、排序(ORDER BY)、分组(GROUP BY)、数据聚合(MIN/MAX/COUNT/AVG等),添加索引或者进行SQL改写吧;
- 瞬间突发有大量请求,这种一般只要能扛过峰值就好,保险起见还是要适当提高服务器的配置,万一峰值抗不过去就可能发生雪崩效应;
- 因为某些定时任务引起的负载升高,比如做数据统计分析和备份,这种对CPU、内存、磁盘I/O消耗都很大,最好放在独立的slave服务器上执行;
- 服务器自身的节能策略发现负载较低时会让CPU降频,当发现负载升高时再自动升频,但通常不是那么及时,结果导致CPU性能不足,抗不过突发的请求;
- 使用raid卡的时候,通常配备BBU(cache模块的备用电池),早期一般采用锂电池技术,需要定期充放电(DELL服务器90天一次,IBM是30天),我们可以通过监控在下一次充放电的时间前在业务低谷时提前对其进行放电,不过新一代服务器大多采用电容式电池,也就不存在这个问题了。
- 文件系统采用ext4甚至ext3,而不是xfs,在高I/O压力时,很可能导致%util已经跑到100%了,但iops却无法再提升,换成xfs一般可获得大幅提升;
- 内核的io scheduler策略采用cfq而非deadline或noop,可以在线直接调整,也可获得大幅提升。
转载至

 浙公网安备 33010602011771号
浙公网安备 33010602011771号