
中间件之Mycat
一、概念
- 介绍
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
Mycat不负责存储数据,只是逻辑上多数据进行分处理,实际存储数据的为后端数据库。
Mycat拦截了用户发送过来的SQL 语句,对SQL 语句做了一些特定的分析: 如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL 发往后端的真实数据库并将返回的结果做适当的处理,最终再返回给用户。
- 分片
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个 数据库(主机) 上面,以达到分散单台设备负载的效果。 数据的 切分(Sharding) 根据其切分规则的类型,可以分为两种切分模式。
一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切分可以称之为数据的垂直(纵向)切分。
另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
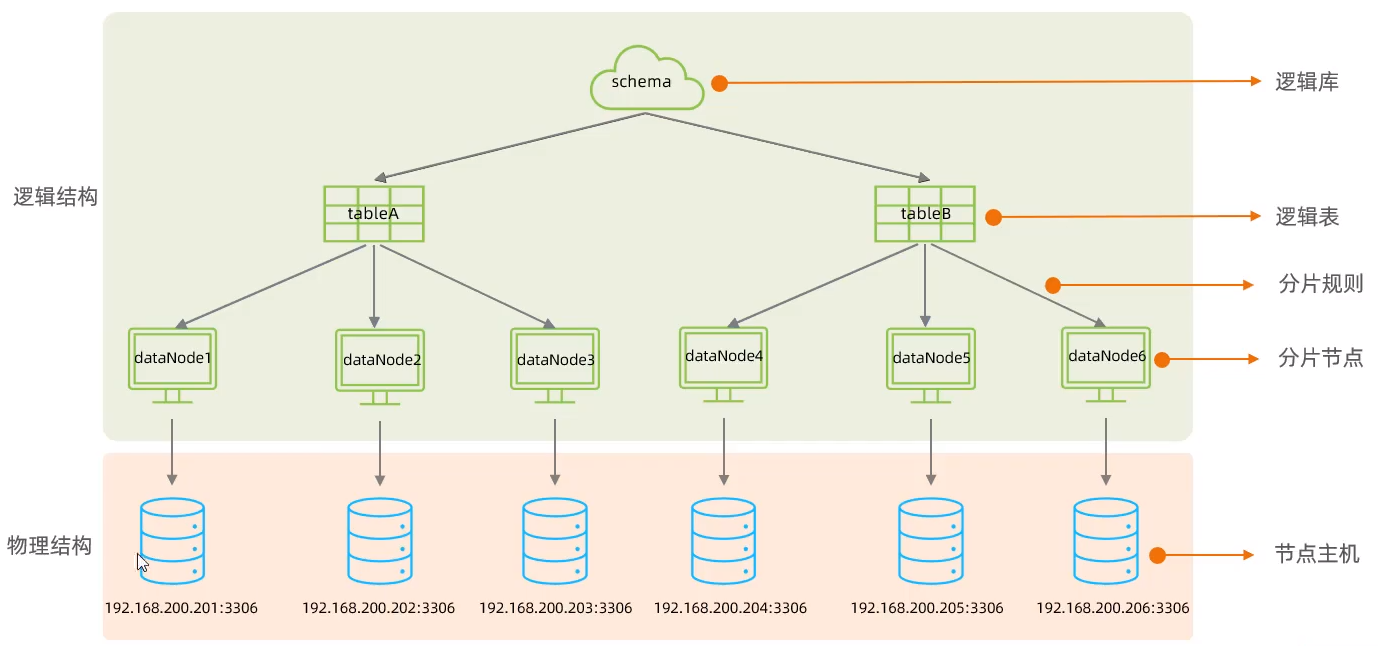
- 逻辑库(schema)
MyCat是一个数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
- 逻辑表(table)
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
- 分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是 分片节点(dataNode)。
- 节点主机(dataHost)
数据切分后,每个 分片节点(dataNode) 不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个 分片节点(dataNode) 所在的机器就是 节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的 分片节点(dataNode)均衡的放在不同的 节点主机(dataHost)。
- 分片规则(rule)
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
二、配置文件
1.server.xml :作为MyCat中最重要的配置文件之一,涵盖了MyCat的逻辑库、逻辑表、分片规则、分片节点及数据源的配置。
2.schema.xml :对应的物理数据库和数据库表的配置
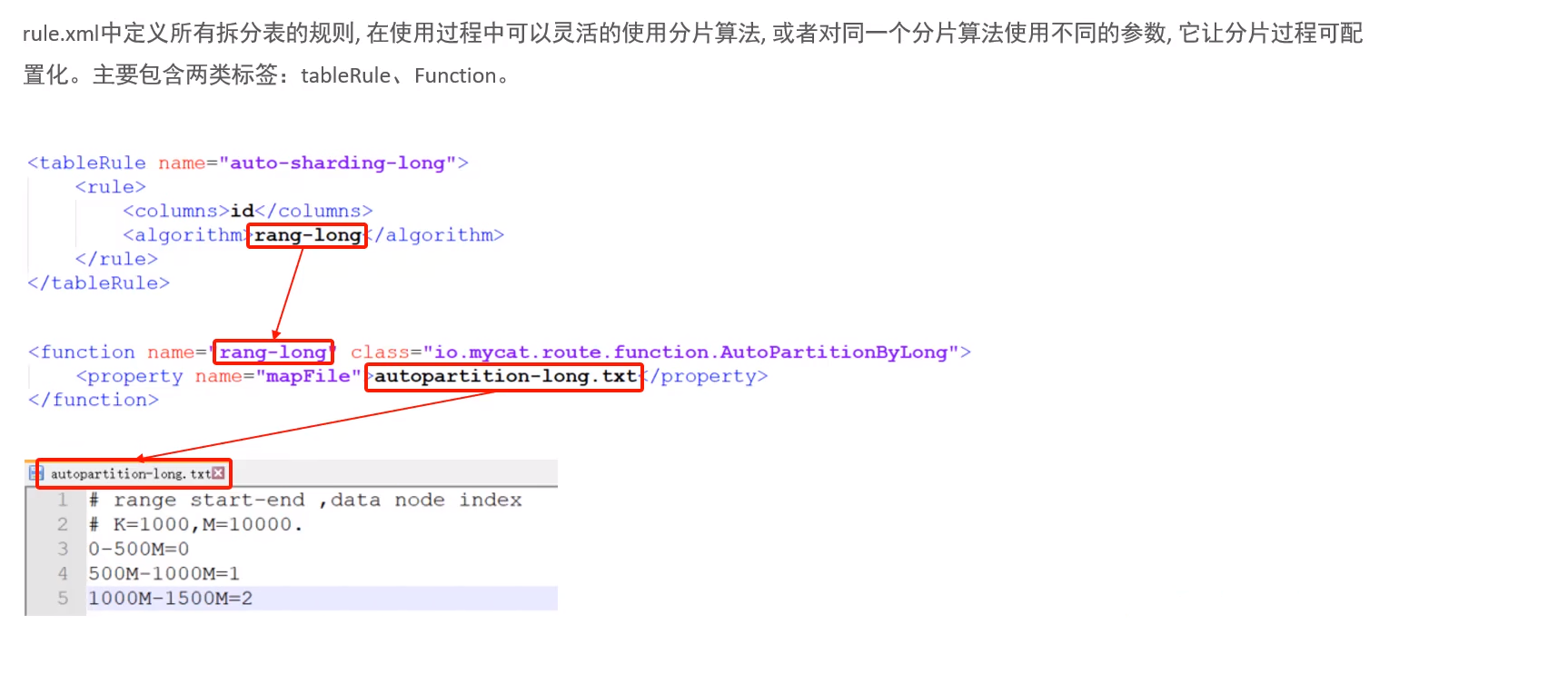
3.rule.xml :分片(分库分表)规则
schema:标签用于定义Mycat实例中的逻辑库
table:标签定义了MyCat中的逻辑表,rule用于指定分片规则,auto-sharding-long的分片规则是按ID值的范围进行分片 1-5000000 为第1片 5000001-10000000 为第2片....
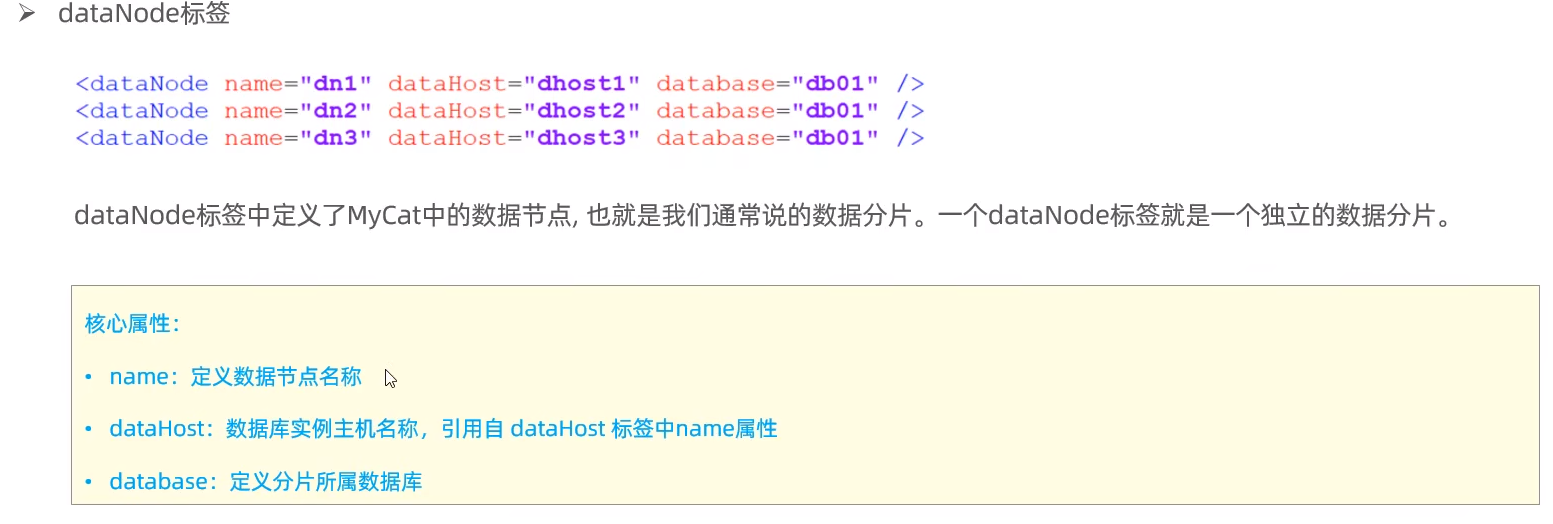
dataNode:标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
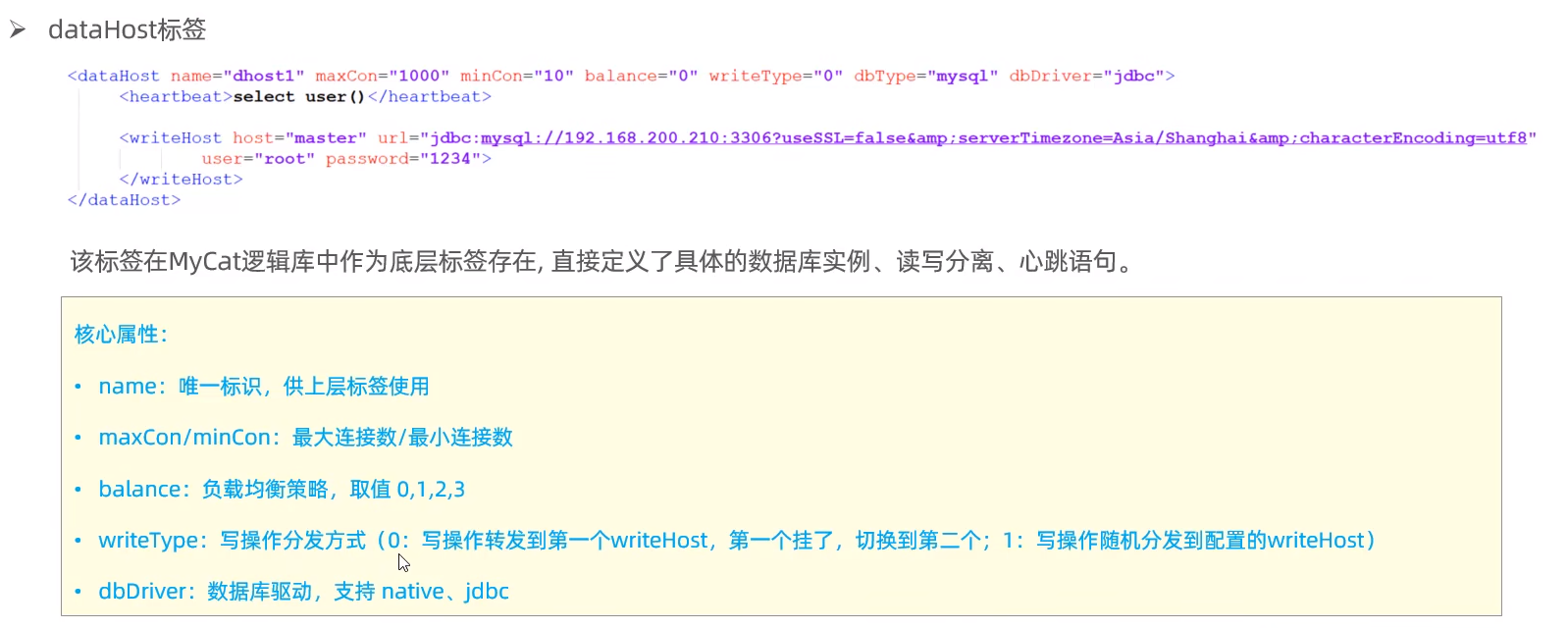
dataHost:标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
示例:

schema.xml



rule.xml
server.xml



 浙公网安备 33010602011771号
浙公网安备 33010602011771号