
[GPU架构|GPU体系结构] 深度解析AMD GPU中的Hierarchical Z以及Early-z被诸多限制的原因
深度解析AMD GPU Hierarchical Z & Early-z被诸多限制的原因
前言
改编自鄙人在OpenGPU上的发表的回帖,如果想进一步探讨关于Visibility Test的话题,可以在本文中回复,也可以在http://www.opengpu.org/bbs/viewthread.php?tid=352&extra=page%3D1中发表评论:〉
OpenGPU.org(http://www.opengpu.org/bbs/index.php)主要聚焦图形硬件(包括GPU体系结构)以及各种图形算法。
在图形硬件方面不只讨论当前的GPU,而且讨论曾经的GPU,或是未来潜在的GPU体系结构。这包括从SGI时代开始的那些大型工作站硬件,以及Render Farm,渲染机群,Embedd GPU HW,Desktop GPU HW,甚至上古时期的嵌入式PPU(Picture Processor Unit)硬件,还包围未来的有可能成承担图形处理的硬件体系结构,也包括Reconfiguration Architecture,Stream precessor,甚至各种Dataflow Machine等等……希望能够和朋友很开心的交流:〉
正文
对于Direct Lighting Graphics Application来说,人们总是使用各种手法来避免对于Invisible Fragment Rendering。在90年代初,由于Desktop PC上并没有普及3D Graphics Hardware,wolf3D使用了带有约束的Raycasting来避免无效的渲染,但是这种渲染对于场景有严格的限制[1]。几乎只能表达室内场景,对于室外场景来说,效果基本上不可接受,如下图:
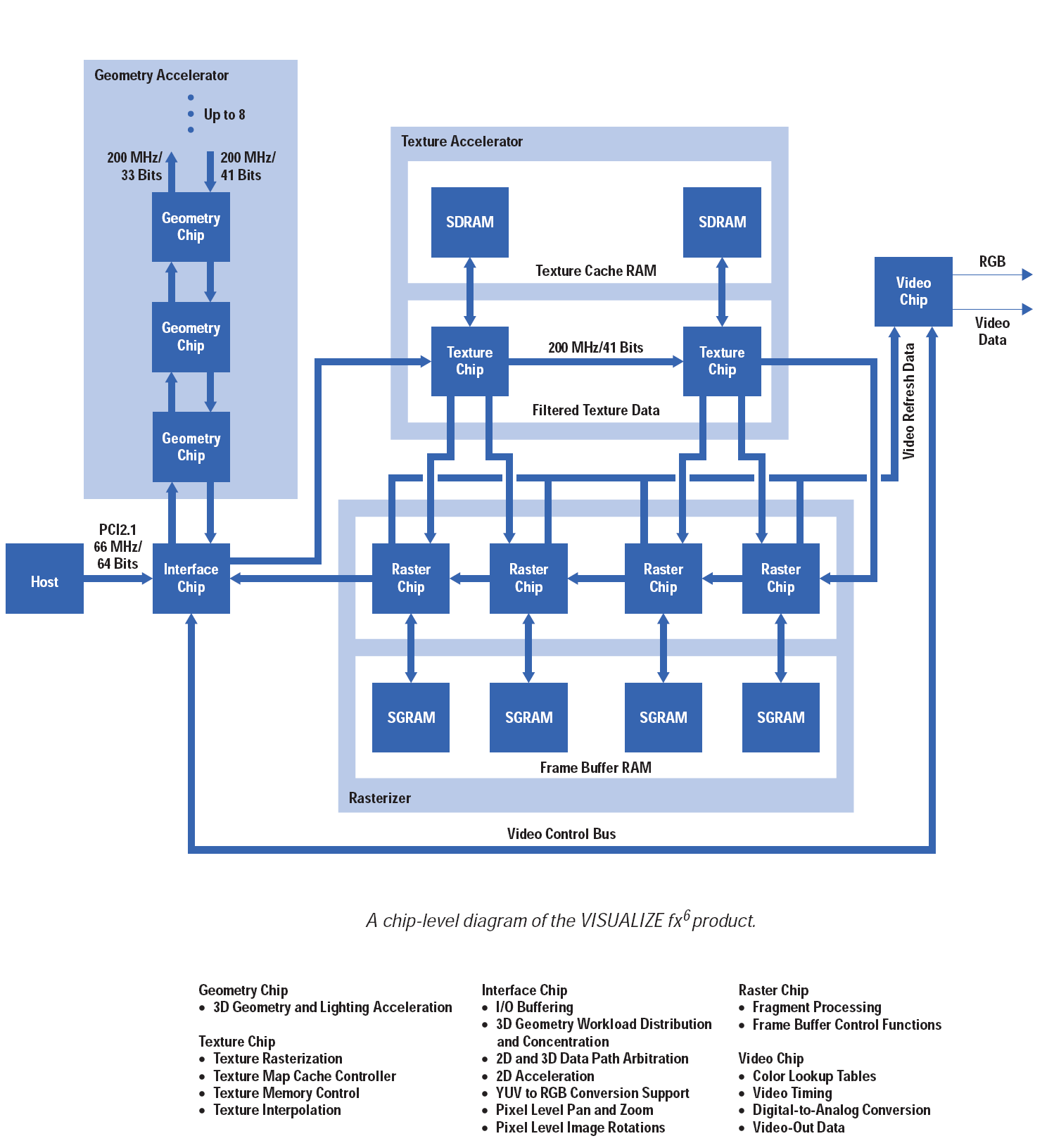
而后为了更真实并且更灵活的场景效果 ,并且随着OGL的开放,人们广泛开始使用被SGI大型图形工作站一直所采用的Polygon-based Rasterization。为了加速这种Application,各种3D Graphics Hardware迅速占领了市场。但是在2000年以前,这些3D Graphics HW都仅仅是SGI-like Graphics Pipeline的一个子集[2],不具备任何的超越SGI-like Graphics Pipeline的能力。Traditional SGI Graphics Pipeline有一个很严重的问题就是不能避免Invisible Fragment Rendering。只能通过一些简单的Face Culling & Geometry Clipping在几何级别作一些Reject Invisible Fragment 的工作。这一点主要原因是OGL Spec中把Depth Test放到了Texture Mapping后面,OGL Pipeline本身没有对于Invisible Fragment进行优化,直到HP的VISUALIZE fxN出来以后,才能通过Occlusion Culling显式的来Reject Invisible Fragment[3]。不过这种Graphics Hardware不是一般人能消费得起的。如下图:
为了避免Invisible Fragment Rendering ,在Rasterization Graphics Pipeline人们开发了很多技术,有些技术完全的不同于SGI-like Graphics Pipeline,而有些技术则是在SGI-like Graphics Pipeline上做各种改进,譬如Ray-casting、Tile-based Rendering(如PowerVR的TBDR)[4]、Deferred Shading[5]、Early-Z[6]……
而对于AMD GPU上所使用的HyperZ来说,他们使用几种技术组合来加速Reject Invisible Fragment,这其中包括了Hierarchical Z, Early Z, Z compression , Fast Z clear。具体可以看附件/Files/OpenGPU/Depth_in-depth.pdf [6].
我们下面的探讨主要是根据上面这篇PDF进行的,轻先阅读后再继续看本文:〉
其实这个PDF我刚刚看过的时候,第一个感觉是就,AMD的HZB实在是弱到家了……在Tile上只能记录一个MAX Depth或是MIN Depth。这是Siggraph 93那篇HZB Paper上标准的做法,但是很多厂商都会优化,不可能直接用,没想到AMD R600竟然直接用了……
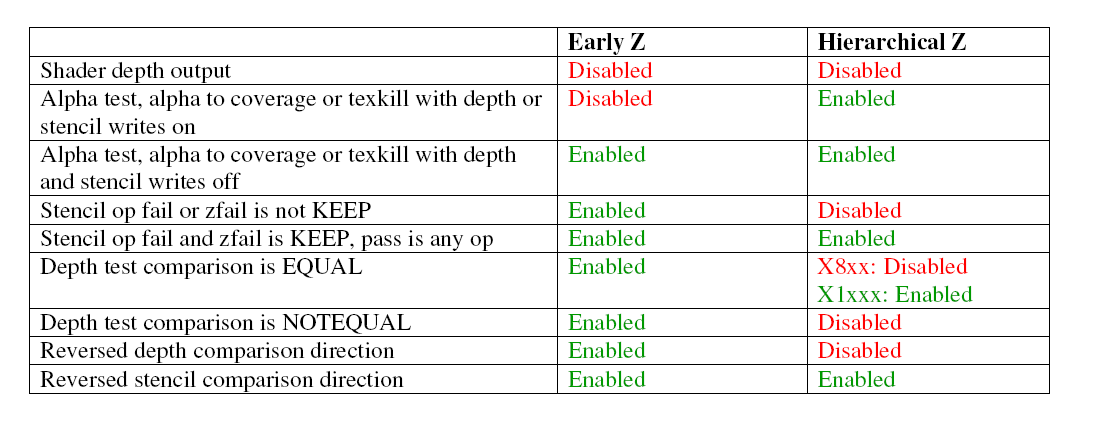
上图是这片文档的总结。文档上写的很详细 Alpha test, alpha to coverage or texkill with depth or stencil writes on都会令Early Z实效。这点不难理解。之所以这样是因为AMD R600 Arch同时满足了以下两个条件:


第一个,AMD的设计中再Early Z Stage就要更新Z-buffer,即Write Z-buffer。
第二个,D3D Graphics Pipeline把Alpha Test放在了Depth Test前面。
那么假如你一个Fragment在Alpha Test不通过,则Z-buffer就看不见这个Fragment,更新Z-buffer就无从谈起了,但是你一旦把Depth Test给Early了之后,那就等于还没有进行Alpha Test的时候这个Fragment就要访问Z-buffer。如果不写Z-buffer的话,倒也无所谓,读了就读了,Read-only是不会破坏现场的。但是AMD的策略是Early-Z的时候就要Update Z-buffer,那就没招了……所以Alpha Test和Early-Z一定是Mutex的!
Alpha to Coverage是DX10的新特性,是一种Dithering-like Transparent Alogrithm,用来实现一定程度上的OIT(Order-independent Transparent)。但是DX10 Functional Spec 并没有规定这个Feature的算法,甚至连一个性能或是行为指标都没有给。所以各家厂商实现就不一样了。至于AMD这个为什么会和Early-z冲突,没有具体Algorithm Spec我也不好下结论!我只能说AMD的这个算法肯定是对应于Alpha小于等于某个值的时候,则Cull掉这个Fragment而不生成任何得 Subsample Mask,这相当于一种变相的Alpha Test。所以在Early-z方面,行为和Alpha Test一样,与之发生冲突。
至此位置,我们可以看出,凡是在Depth Test之前能Fragment Culling的特性都会和Early-z有冲突,这也就不难解释texkill Instruction on PS 怎么会和Early-Z互斥了。
但是为什么不会和HZB冲突呢?答案很简单,HZB是On-chip的,所以当PS之后更新也不会影响性能。所以HZB在PS之后更新。而在PS之前只是Read-only的。但是为什么Early-Z也不这样做呢?答案很简单,Early-z是Off-chip的,难道要一个Fragment在Graphics Pipeline上访问两次Depth Buffer?这不是和Reduce Z Traffic的初衷相反了么?!在GPU上,Memory Bandwidth是永远不够用的。所以,没人愿意同一件事干两次。(当然,兄弟们就不要拿Z-first Rendering和我抬杠了…,我知道我说的不严谨)
第二个,D3D Graphics Pipeline把Alpha Test放在了Depth Test前面。
那么假如你一个Fragment在Alpha Test不通过,则Z-buffer就看不见这个Fragment,更新Z-buffer就无从谈起了,但是你一旦把Depth Test给Early了之后,那就等于还没有进行Alpha Test的时候这个Fragment就要访问Z-buffer。如果不写Z-buffer的话,倒也无所谓,读了就读了,Read-only是不会破坏现场的。但是AMD的策略是Early-Z的时候就要Update Z-buffer,那就没招了……所以Alpha Test和Early-Z一定是Mutex的!
Alpha to Coverage是DX10的新特性,是一种Dithering-like Transparent Alogrithm,用来实现一定程度上的OIT(Order-independent Transparent)。但是DX10 Functional Spec 并没有规定这个Feature的算法,甚至连一个性能或是行为指标都没有给。所以各家厂商实现就不一样了。至于AMD这个为什么会和Early-z冲突,没有具体Algorithm Spec我也不好下结论!我只能说AMD的这个算法肯定是对应于Alpha小于等于某个值的时候,则Cull掉这个Fragment而不生成任何得 Subsample Mask,这相当于一种变相的Alpha Test。所以在Early-z方面,行为和Alpha Test一样,与之发生冲突。
至此位置,我们可以看出,凡是在Depth Test之前能Fragment Culling的特性都会和Early-z有冲突,这也就不难解释texkill Instruction on PS 怎么会和Early-Z互斥了。
但是为什么不会和HZB冲突呢?答案很简单,HZB是On-chip的,所以当PS之后更新也不会影响性能。所以HZB在PS之后更新。而在PS之前只是Read-only的。但是为什么Early-Z也不这样做呢?答案很简单,Early-z是Off-chip的,难道要一个Fragment在Graphics Pipeline上访问两次Depth Buffer?这不是和Reduce Z Traffic的初衷相反了么?!在GPU上,Memory Bandwidth是永远不够用的。所以,没人愿意同一件事干两次。(当然,兄弟们就不要拿Z-first Rendering和我抬杠了…,我知道我说的不严谨)
引用:
[1]F. Permadi,"Ray-Casting Tutorial",http://www.opengpu.org/bbs/viewthread.php?tid=369&extra=page%3D1
[2]Paul Hsieh,"Graphics Accelerators -- what are they?",http://www.opengpu.org/bbs/viewthread.php?tid=268&extra=page%3D2
[3]Noel D.Scott,"An Overview of the VISUALIZE fx Graphics Accelerator Hardware"
[4]Kristof Beets,"PowerVR Tile Based Rendering",http://www.opengpu.org/bbs/viewthread.php?tid=243&extra=page%3D1
[5]nVIDIA,"Deferred Shading" , http://http.download.nvidia.com/developer/presentations/2004/6800_Leagues/6800_Leagues_Deferred_Shading.pdf
后记:其实本文还可以写的更长,在Visibility Test方面的确有很多东西可以写,不过以后我会更多的写一些关于图形硬件方面的东西,希望朋友们批评 :〉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号