
SQL Server 解读【已分区索引的特殊指导原则】(3) - 非聚集索引分区(转载)
一、前言
在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。
SQL Server 解读【已分区索引的特殊指导原则】(1)- 索引对齐
SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区
二、解读
【对非聚集索引进行分区】
“对唯一的非聚集索引进行分区时,索引键必须包含分区依据列。对非唯一的非聚集索引进行分区时,默认情况下 SQL Server 将分区依据列添加为索引的非键(包含性)列,以确保索引与基表对齐。如果索引中已经存在分区依据列,SQL Server 将不会向索引中添加分区依据列。“
(一) “对唯一的非聚集索引进行分区时,索引键必须包含分区依据列。“对唯一的非聚集索引进行分区,首先它是有唯一约束的,你可以参考:SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区
(二) 其实上面这个描述中,我最关心的是否真的会默认创建包含性列?下面我们进行测试:
1) 创建一个名为[ClassifyResult]的分区表,这个分区方案是以[ClassId]作为分区依据列,[Id]+ [ClassId]作为聚集索引,并且是主键(唯一约束),
--创建测试表 CREATE TABLE [dbo].[ClassifyResult]( [Id] [bigint] IDENTITY(1,1) NOT NULL, [ClassId] [int] NOT NULL CONSTRAINT [DF_ClassifyResult_ClassID] DEFAULT ((0)), [ArchiveId] [int] NOT NULL CONSTRAINT [DF_ClassifyResult_ArchiveID] DEFAULT ((0)), [Url] [nvarchar](400) NOT NULL CONSTRAINT [DF_ClassifyResult_Url] DEFAULT (''), CONSTRAINT [PK_ClassifyResult] PRIMARY KEY CLUSTERED ( [Id] ASC, [ClassId] ASC ) ON [Sch_ClassifyResult_ClassId]([ClassId]), CONSTRAINT [IX_ClassifyResult_Temp_ClassIdUrl] UNIQUE NONCLUSTERED ( [ClassId] ASC, [Url] ASC )WITH (IGNORE_DUP_KEY = ON) ON [Sch_ClassifyResult_ClassId]([ClassId]) ) ON [Sch_ClassifyResult_ClassId]([ClassId])
2) 为[ClassifyResult]创建一个非唯一的非聚集索引:[IX_ClassifyResult_ArichiveId],这个索引键值只有一个:[ArchiveId],并且使用了和表一样的分区方案。
--创建一个非唯一的非聚集索引 CREATE NONCLUSTERED INDEX [IX_ClassifyResult_ArichiveId] ON [dbo].[ClassifyResult] ( [ArchiveId] ASC ) ON [Sch_ClassifyResult_ClassId]([ClassId])
3) 按照“对非唯一的非聚集索引进行分区时,默认情况下 SQL Server 将分区依据列添加为索引的非键(包含性)列,以确保索引与基表对齐。“的说法,上面创建索引的SQL语句就等同于下面的SQL语句:
--创建一个非唯一的非聚集索引(include) CREATE NONCLUSTERED INDEX [IX_ClassifyResult_ArichiveId] ON [dbo].[ClassifyResult] ( [ArchiveId] ASC )INCLUDE([ClassId]) ON [Sch_ClassifyResult_ClassId]([ClassId])
4) 下面就来验证上面的说法是否正确,应该怎么验证呢?首先你需要了解INCLUDE有什么作用:SQL Server 索引中include的魅力(具有包含性列的索引),所以我们就测试在Select时候返回不同的列值时候的执行计划。执行计划如Figure1所示:
--SQL_1查询返回[Id]和[ArchiveId] SELECT top 10 [Id],[ArchiveId] FROM [ClassifyResult] where ArchiveId = 107347
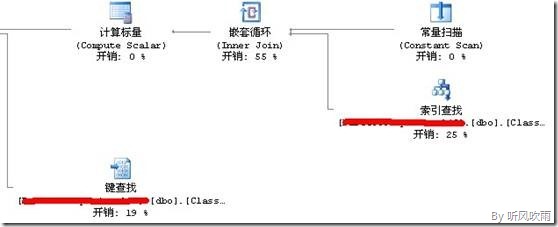
(Figure1:执行计划)

(Figure2:索引查找的详细信息)
5) Figure1是上面SQL_1语句的执行计划,从中可以看出为了返回Id值,SQL Server需要通过【键查找】检索Id值;使用下面的SQL_2返回[ClassId]和[ArchiveId],如果真的如:“默认情况下 SQL Server 将分区依据列添加为索引的非键(包含性)列”所说的那样,那么SQL_2就会只使用[IX_ClassifyResult_ArichiveId]索引就能返回[ClassId]和[ArchiveId]两个字段的值了,SQL_2的执行计划如Figure3所示:
--SQL_2查询返回[ClassId]和[ArchiveId] SELECT top 10 [ClassId],[ArchiveId] FROM [ClassifyResult] where ArchiveId = 107347
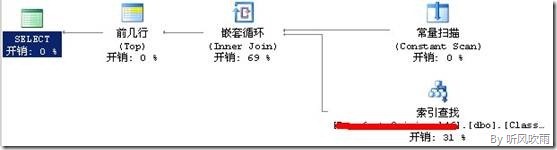
(Figure3:执行计划)
6) ”对非唯一的非聚集索引进行分区时,默认情况下 SQL Server 将分区依据列添加为索引的非键(包含性)列,以确保索引与基表对齐。”为什么放到包含列就能保证对齐呢?
三、参考文献
Special Guidelines for Partitioned Indexes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号