济南 S NOIP 刷题实战梳理营游记(上)
前言
期末砸力。
这次暑假去两个营,一个在烟台,一个在济南。在烟台的都是学算法,扔到目录里了,这篇文章就是来讲济南营的。
一共十二天,每天从八点到晚上八点半。上午八点到十二点打比赛,然后吃饭,然后讲题。
Day -1
6h6h 的大巴,绷不住了,中途在潍坊西休息,热死了。
到了济南,住在酒店旁边,楼下全是吃的,很赞。
顺便和 LCE 玩了会 MC,然后又和一个印度人玩了玩,印度人说他是全校最帅的和最聪明的,数学考了很多 100100,我反手告诉他我考了 120120,十分赞。
Sleep...
Day 1
数据结构专题。
80+0+20+0=10080+0+20+0=100 pts。Rank 19/58。
A 大嘴乌鸦(沁志)
题意
大嘴乌鸦有 nn 个水瓶,第 ii 个水瓶的重量为 aiai。
大嘴乌鸦要喝水,所以他找来了一堆石子,这些石子的重量和为 kk。
乌鸦发现,如果一个区间的水瓶的重量的异或和是 kk 的因子,则这个区间是一个喝水区间。
乌鸦想知道,有多少个不同的喝水区间。
数据范围:n≤105,1≤ai,k≤nn≤105,1≤ai,k≤n。
输入格式
第一行两个数字 nn 表示水瓶个数,以及石子的重量和 kk。
第二行 nn 个正整数,第 ii 个数表示 aiai。
输出格式
一行一个整数表示有多少不同的喝水区间。
样例输入
5 3
1 2 3 4 5
样例输出
6
考场思路
大暴力。
枚举左端点 ll,右端点 rr。rr 的范围是 11 到 nn。令 sumsum 为 ll 到 rr 的异或和,同前缀和,显然可以分别求出 [l,l∼n][l,l∼n] 的 sumsum,复杂度 O(n2)O(n2)。
代码(8080 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define here printf("here\n"); int n,K; int a[100001]; int yihuo,ans; int main() { cin>>n>>K; int i; for(i=1;i<=n;i++) cin>>a[i]; yihuo = a[1]; for(i=2;i<=n;i++) yihuo ^= a[i]; int j,k; for(i=1;i<=n;i++) { for(j=i;j<=n;j++) { int yh = a[i]; for(k=i+1;k<=j;k++) { yh ^= a[k]; } if(yh) { if(K%yh==0) { ans++; } } } } cout<<ans<<endl; return 0; }
正解
先处理出 kk 的因子,放入 bb。然后前缀异或一下 aa 数组(就是前缀和改个符号)。开一个桶 visvis,统计 aiai 出现的次数。并依次枚举左端点和因子,看看桶内有没有 ai×bjai×bj,如果有,那么答案就加上 visai×bjvisai×bj。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; int a[1000001],n,sum[1000001]; int k; int vis[1000001],cnt; vector<int> b; int ans; int main() { cin>>n>>k; int i; for(i=1;i<=n;i++) cin>>a[i]; for(i=1;i<=n;i++) sum[i] = sum[i-1]^a[i]; for(i=1;i<=k;i++) if(k%i==0) b.push_back(i); for(i=1;i<=n;i++) { vis[sum[i-1]]++; for(auto j:b) { ans += vis[sum[i]^j]; } } cout<<ans<<endl; return 0; }
B 艾莎
题意
艾莎给你一个长度为 nn 的序列 aa,mm 次操作,共两种操作类型:
1. 给定 l,r,xl,r,x,将 al⋯aral⋯ar 加上 xx。
2. 给定 l,rl,r,查询 maxl≤L<R≤rR∑i=LaiR−L+1maxl≤L<R≤rR∑i=LaiR−L+1。
数据范围:1≤n,m≤106,|ai|,|x|≤1031≤n,m≤106,|ai|,|x|≤103,保证都是整数。对于操作 22,保证不存在 l=rl=r 的情况。
输入格式
第一行:n,mn,m;
第二行:aa 序列;
接下来 mm 行,每行 1,l,r,x1,l,r,x 或 2,l,r2,l,r 表示一个操作。
输出格式
对于每个操作 22,输出一行,包含一个最简分数(形如a/b、-a/b或0/1;a,ba,b 是互质的)。
样例输入
5 8
-7 -8 -1 5 8
1 4 5 -3
1 2 3 7
1 5 5 3
1 1 4 1
2 4 5
1 3 4 -1
1 1 2 7
2 4 5
样例输出
11/2
5/1
考场思路
操作 22 的人话:求 [l,r][l,r] 中最大的子段的平均值。
线段树 ++ 暴力,但爆零。
代码(00 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define ls (p<<1) #define rs (p<<1|1) #define int long long int n; const int N = 100005; int a[N]; struct point { int l,r; int sum,lazy; }t[N*4]; void push_up(int p) { t[p].sum = t[ls].sum+t[rs].sum; } void push_down(int p) { if(t[p].lazy) { t[ls].sum += t[p].lazy*(t[ls].r-t[ls].l+1); t[rs].sum += t[p].lazy*(t[rs].r-t[rs].l+1); t[ls].lazy += t[p].lazy; t[rs].lazy += t[p].lazy; t[p].lazy = 0; return; } } void build(int p,int l,int r) { t[p].l = l; t[p].r = r; if(l==r) { t[p].sum = a[l]; return; } int mid = (t[p].l+t[p].r)/2; build(ls,l,mid); build(rs,mid+1,r); push_up(p); } void add(int p,int l,int r,int d) { if(t[p].l>=l&&t[p].r<=r) { t[p].sum += (t[p].r-t[p].l+1)*d; t[p].lazy += d; return; } push_down(p); int mid = (t[p].l+t[p].r)/2; if(l<=mid) add(ls,l,r,d); if(mid<r) add(rs,l,r,d); push_up(p); } int get(int p,int l,int r) { if(l<=t[p].l&&t[p].r<=r) return t[p].sum; push_down(p); int ans = 0; int mid = (t[p].l+t[p].r)/2; if(l<=mid) ans += get(ls,l,r); if(mid<r) ans += get(rs,l,r); return ans; } int gcd(int a,int b) { return b?gcd(b,a%b):a; } main() { int t; cin>>n>>t; int i,j; for(i=1;i<=n;i++) cin>>a[i]; build(1,1,n); while(t--) { int op; cin>>op; if(op==1) { int l,r,k; cin>>l>>r>>k; add(1,l,r,k); } else { int l,r; cin>>l>>r; double ma = -114514.0; int fmm,fzz; for(i=l;i<r;i++) { for(j=i+1;j<=r;j++) { int fm = get(1,i,j); int fz = j-i+1; double fs = fm*1.0/fz; if(fs>ma) ma = fs,fmm = fm,fzz = fz; } } int g = gcd(fmm,fzz); if(fzz>0&&fmm<0) fzz = -fzz,fmm = -fmm; cout<<fmm/g<<'/'<<fzz/g<<endl; } } return 0; }
正解
先来挖掘一个很奇妙的性质:
- 考虑任意一个长度 ≥4≥4 的区间,可以被划分成两个长度 ≥2≥2 的区间。而根据常识,这两个区间的平均值一定有一个不比原区间的平均值小,故答案区间 ≤3≤3。
然后用线段树维护每个长度为 22 的区间和长度为 33 的区间的最大值即可。时间复杂度 O(nlogn)O(nlogn)。
证明:
考虑取得 maxmax 的 L,RL,R,取 R−L+1R−L+1 最小的那组,以及序列 aa 的前缀和 si=i∑j=1ajsi=i∑j=1aj。假设 R−L+1>3R−L+1>3:
定义 F(L,R)=sR−sLR−LF(L,R)=sR−sLR−L,则:
由斜率的性质 F(L−1,R)<min(F(L−1,L),F(R−1,R))F(L−1,R)<min(F(L−1,L),F(R−1,R)),构造连续函数 f(x)f(x) 满足 f(i)=sf(i)=s,在 i−1<x<ii−1<x<i 时 f(x)f(x) 为斜率 F(i−1,i)F(i−1,i) 的一次函数,则由零点存在定理等可以找出 f(x)f(x) 在区间 (L,R−1)(L,R−1) 上与经过 (L−1,sL−1)(L−1,sL−1) 和 (R,sR)(R,sR) 的一次函数的交点,取最左的交点下取整为 L−1<M,M+1<RL−1<M,M+1<R,于是 F(L−1,M)≥F(L−1,R)F(L−1,M)≥F(L−1,R) 且 F(M+1,R)≥F(L−1,R)F(M+1,R)≥F(L−1,R),矛盾。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define ll long long int n,m; int a[1000005]; struct Tree{ int l,r,len; ll tar,w,s2=-1e18,L,R; ll s3=-1e18,LL=-1e18,RR=-1e18; }t[4000005]; void update(int p){ t[p].w=t[p<<1].w+t[p<<1|1].w; t[p].L=t[p<<1].L,t[p].R=t[p<<1|1].R; if(t[p<<1].len>=2) t[p].LL=t[p<<1].LL; else t[p].LL=t[p<<1].w+t[p<<1|1].L; if(t[p<<1|1].len>=2) t[p].RR=t[p<<1|1].RR; else t[p].RR=t[p<<1|1].w+t[p<<1].R; t[p].s2=max(max(t[p<<1].s2,t[p<<1|1].s2),t[p<<1].R+t[p<<1|1].L); t[p].s3=max(max(t[p<<1].s3,t[p<<1|1].s3),max(t[p<<1].RR+t[p<<1|1].L,t[p<<1].R+t[p<<1|1].LL)); } void build(int p,int l,int r){ t[p].l=l,t[p].r=r,t[p].len=t[p].r-t[p].l+1; if(l==r){ t[p].w=a[l]; t[p].L=a[l],t[p].R=a[l]; return; } int mid=((ll)l+(ll)r)>>1; build(p<<1,l,mid),build(p<<1|1,mid+1,r); update(p); } void push(int p){ if(t[p].tar){ t[p<<1].w+=(t[p<<1].r-t[p<<1].l+1)*t[p].tar; t[p<<1|1].w+=(t[p<<1|1].r-t[p<<1|1].l+1)*t[p].tar; t[p<<1].L+=t[p].tar,t[p<<1].R+=t[p].tar; t[p<<1|1].L+=t[p].tar,t[p<<1|1].R+=t[p].tar; if(t[p<<1].len>=2) t[p<<1].s2+=2*t[p].tar,t[p<<1].LL+=2*t[p].tar,t[p<<1].RR+=2*t[p].tar; if(t[p<<1|1].len>=2) t[p<<1|1].s2+=2*t[p].tar,t[p<<1|1].LL+=2*t[p].tar,t[p<<1|1].RR+=2*t[p].tar; if(t[p<<1].len>=3) t[p<<1].s3+=3*t[p].tar; if(t[p<<1|1].len>=3) t[p<<1|1].s3+=3*t[p].tar; t[p<<1].tar+=t[p].tar,t[p<<1|1].tar+=t[p].tar; t[p].tar=0; } } void add(int p,int l,int r,int x){ if(l<=t[p].l&&t[p].r<=r){ t[p].tar+=x; t[p].L+=x,t[p].R+=x; if(t[p].len>=2) t[p].s2+=2*x,t[p].LL+=2*x,t[p].RR+=2*x; if(t[p].len>=3) t[p].s3+=3*x; t[p].w+=t[p].len*x; return; } push(p); int mid=(t[p].r+t[p].l)>>1; if(l<=mid) add(p<<1,l,r,x); if(mid<r) add(p<<1|1,l,r,x); update(p); } Tree query2(int p,int l,int r){ if(l<=t[p].l&&t[p].r<=r){ return t[p]; } push(p); int mid=((ll)t[p].r+(ll)t[p].l)>>1; Tree left,right,now; if(r<=mid){ return query2(p<<1,l,r); } if(l>mid){ return query2(p<<1|1,l,r); } left=query2(p<<1,l,r),right=query2(p<<1|1,l,r); now.L=left.L,now.R=right.R; now.s2=max(max(left.s2,right.s2),left.R+right.L); now.w=left.w+right.w; return now; } Tree query3(int p,int l,int r){ if(l<=t[p].l&&t[p].r<=r){ return t[p]; } push(p); int mid=((ll)t[p].r+(ll)t[p].l)>>1; Tree left,right,now; if(r<=mid){ return query3(p<<1,l,r); } if(l>mid){ return query3(p<<1|1,l,r); } left=query3(p<<1,l,r),right=query3(p<<1|1,l,r); now.L=left.L,now.R=right.R; now.s2=max(max(left.s2,right.s2),left.R+right.L); if(left.len>=2) now.LL=left.LL; else now.LL=left.R+right.L; if(right.len>=2) now.RR=right.RR; else now.RR=left.R+right.L; now.s3=max(max(left.s3,right.s3),max(left.RR+right.L,left.R+right.LL)); now.w=left.w+right.w; return now; } int main(){ cin>>n>>m; for(int i=1;i<=n;++i) cin>>a[i]; build(1,1,n); for(int i=1;i<=m;++i){ int op,l,r; scanf("%d %d %d",&op,&l,&r); if(op==1){ int x; cin>>x; add(1,l,r,x); }else{ ll maxx2=query2(1,l,r).s2; ll maxx3=query3(1,l,r).s3; if(maxx2*3>maxx3*2){ if(maxx2%2==0) cout<<maxx2/2<<"/"<<"1\n"; else cout<<maxx2<<"/"<<"2\n"; }else{ if(maxx3%3==0) cout<<maxx3/3<<"/"<<"1\n"; else cout<<maxx3<<"/"<<"3\n"; } } } return 0; }
C 沙奈朵
题意
沙奈朵给定一个长度为 nn 的序列 aa,每个位置都是一个 [1,n][1,n] 内的整数。
定义 f(i,j)f(i,j) 表示有多少个 xx 满足 i≤x<ji≤x<j 且 ax≠ax+1ax≠ax+1。
有 mm 次操作:
1.1 l r x:表示将 ll 位置修改为 xx。
2.2 l r x:表示查询区间 [l,r][l,r] 中,对于任意 l≤i<j≤rl≤i<j≤r,且 ai=aj=xai=aj=x,f(i,j)f(i,j) 的和。
注意,为了让两种操作读入一致,11 操作的 rr 卵用没有。
数据范围:
对于 20%20% 的数据,没有 11 操作。
对于全部数据:1≤n,m≤5×105,1≤l≤r≤n,1≤ai,x≤n1≤n,m≤5×105,1≤l≤r≤n,1≤ai,x≤n。
输入格式
第一行两个数 n,mn,m。
第二行 nn 个用空格隔开的数表示序列 aa。
之后 mm 行,每行四个用空格隔开的数 opt,l,r,xopt,l,r,x 表示一次操作。
输出格式
对每个 22 操作,输出一行一个数表示答案。
样例输入
10 10
2 1 2 1 8 3 2 1 2 2
2 6 9 2
2 3 10 2
2 2 10 2
2 1 3 2
2 4 10 1
1 2 4 2
2 3 10 2
2 2 7 1
2 2 7 2
2 3 6 2
样例输出
2
20
20
2
4
20
0
8
0
考场思路
暴力。
代码(2020 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; const int N = 500001; int a[N]; int n,m; int opt[N],l[N],r[N],x[N]; int baoli_f(int l,int r) { int res = 0; int i; for(i=l;i<r;i++) res += a[i]!=a[i+1]; return res; } int main() { cin>>n>>m; int i,j; for(i=1;i<=n;i++) cin>>a[i]; for(i=1;i<=m;i++) cin>>opt[i]>>l[i]>>r[i]>>x[i]; int tzfakioi; for(tzfakioi=1;tzfakioi<=m;tzfakioi++) { if(opt[tzfakioi]==1) a[l[tzfakioi]] = x[tzfakioi]; else { int ans = 0; for(i=l[tzfakioi];i<r[tzfakioi];i++) { for(j=i+1;j<=r[tzfakioi];j++) { if(a[i]==a[j]&&a[i]==x[tzfakioi]) ans += baoli_f(i,j); } } cout<<ans<<endl; } } return 0; }
正解
先考虑 O(n)O(n) 来求区间 [l,r][l,r] 的解。
先考虑维护以下信息:
1. 从 ll 到 ii 的所有值为 xx 的数到 ii 的颜色段数量和aa。
2. 从 ll 到 ii 有多少个值为 xx 的数 numnum。
3. 区间 [l,i][l,i] 的解 ansans。
可以发现以上信息是好维护的。
复杂度为 O(nm)O(nm)。
具体的维护方式:
- 若 ai+1=xai+1=x,则 ans=ans+a,num=num+1ans=ans+a,num=num+1;
- 若 ai+1≠aiai+1≠ai,则 a=a+numa=a+num。
接下来考虑分块,即对于区间维护以上信息。
考虑要维护的信息:
1. 从 ll 到 rr 的所有值为 xx 的数到 rr 的颜色段数量和 aiai;
2. 从 rr 到 ll 的所有值为 xx 的数到 ll 的颜色段数量和 bibi;
3. 从 ll 到 rr 的颜色段数量 cc;
4. 从 ll 到 rr 有多少个值为 xx 的数 numnum;
5. 区间 [l,r][l,r] 的解 ansans;
6. 区间最左边和最右边的元素 leftleft 和 rightright。
发现这些信息也是好维护的。
具体的维护方式:
- newans=lans+rans+la×rnum+r×lnum+[lright≠rleft]×lnum×rnumnewans=lans+rans+la×rnum+r×lnum+[lright≠rleft]×lnum×rnum;
- newa=ra+la×(rc+[lright≠rleft])newa=ra+la×(rc+[lright≠rleft])。
newbnewb 的维护方法类似。
其他变量的维护方法都是普通的,不再赘述。
再捋一遍思路: - 对于每个块维护以上信息,每次修改的时候跑一遍(做法与一开始的 O(n)O(n) 求去见答案类似,不再赘述),然后每次询问散块暴力跑,整块用合并方式来跑。
复杂度 O(√(n)(n+m))O(√(n)(n+m))。
代码:
点击查看代码
#include <bits/stdc++.h> using namespace std; const int maxn = 5e5 + 10, maxs = 720; int n, m, B, A[maxn]; struct node { int opt, l, r, x; inline void input() {cin >> opt >> l >> r >> x; if(opt == 1) r = l; } } Q[maxn]; struct Msg { int num, siz, l, r; long long ans, toL, toR; Msg(int Num = 0, int Siz = 0, int L = 0, int R = 0, long long Ans = 0, long long ToL = 0, long long ToR = 0) : num(Num), siz(Siz), l(L), r(R), ans(Ans), toL(ToL), toR(ToR) {} //num: 该颜色数量, siz: 除了右端点所在段的颜色段个数, l: 左侧颜色, r: 右侧颜色 //ans: 区间答案, toL: 该颜色到左边界颜色段个数-1的和, toR: 该颜色到右边界颜色段个数和 Msg operator + (const Msg &rhs) { Msg res; const Msg &lhs = *this; res.l = lhs.l, res.r = rhs.r, res.num = lhs.num + rhs.num, res.siz = lhs.siz + rhs.siz + (lhs.r != rhs.l); res.ans = lhs.ans + rhs.ans + lhs.toR * rhs.num + rhs.toL * lhs.num - (lhs.r == rhs.l) * lhs.num * rhs.num; res.toL = lhs.toL + rhs.toL + rhs.num * (lhs.siz + 1 - (lhs.r == rhs.l)); res.toR = rhs.toR + lhs.toR + lhs.num * (rhs.siz + 1 - (lhs.r == rhs.l)); return res; } bool operator == (const Msg &rhs) const { return num == rhs.num && siz == rhs.siz && l == rhs.l && r == rhs.r && ans == rhs.ans && toL == rhs.toL && toR == rhs.toR; } } mes[maxn], ans[maxn]; ostream& operator <<(ostream& out, const Msg &x) { out << x.num << ' ' << x.siz << ' ' << x.l << ' ' << x.r << ' ' << x.ans << ' ' << x.toL << ' ' << x.toR; return out; } int Count[maxn]; inline Msg Build(int l, int r) { for(int i = l; i <= r; i ++) mes[A[i]] = Msg(); int lst = 0, siz = 0; for(int i = l; i <= r; i ++) { if(lst == A[i]) mes[A[i]] = mes[A[i]] + Msg(1, 0, A[i], A[i], 0, 0, 1); else { if(mes[A[i]] == Msg()) { mes[A[i]] = Msg(1, siz, A[l], A[i], 0, siz, 1); siz ++, lst = A[i]; } else { int add = siz - mes[A[i]].siz - 1; mes[A[i]] = mes[A[i]] + Msg(1, add, 0, A[i], 0, add, 1); lst = A[i], siz ++; } } } for(int i = l; i <= r; i ++) if(siz - 1 != mes[A[i]].siz) { int add = siz - mes[A[i]].siz - 2; mes[A[i]] = mes[A[i]] + Msg(0, add, 0, A[r], 0, 0, 0); } return Msg(0, siz - 1, A[l], A[r], 0, 0, 0); } inline Msg Query(int l, int r, int x) { Msg res(A[l] == x, 0, A[l], A[l], 0, 0, A[l] == x); for(int i = l + 1; i <= r; i ++) res = res + Msg(A[i] == x, 0, A[i], A[i], 0, 0, A[i] == x); return res; } inline void calc(int l, int r) { Msg T = Build(l, r); for(int i = 1; i <= n; i ++) Count[i] = 0; for(int i = l; i <= r; i ++) Count[A[i]] ++; for(int kase = 1; kase <= m; kase ++) { auto &q = Q[kase]; if(q.r < l || q.l > r) continue; //和现在处理的区间没关系. if(q.opt == 1) { Count[A[q.l]] --; Count[q.x] ++; A[q.l] = q.x, T = Build(l, r); continue; } if(q.l >= l && q.l <= r) { //左端散块 ans[kase] = Query(q.l, min(r, q.r), q.x); } else if(q.r >= l && q.r <= r) { //右端散块 ans[kase] = ans[kase] + Query(l, q.r, q.x); } else if(q.l < l && q.r > r) { //中间的整块 if(Count[q.x] == 0) ans[kase] = ans[kase] + T; else ans[kase] = ans[kase] + mes[q.x]; } else { cerr << l << ' ' << r << ' ' << q.l << ' ' << q.r << '\n'; assert(false); } } } int main() { ios::sync_with_stdio(false), cin.tie(0); cin >> n >> m; B = sqrt(n); for(int i = 1; i <= n; i ++) cin >> A[i]; for(int i = 1; i <= m; i ++) Q[i].input(); for(int l = 1, r = B; l <= n; l += B, r += B) calc(l, min(r, n)); for(int i = 1; i <= m; i ++) if(Q[i].opt == 2) cout << ans[i].ans << '\n'; return 0; }
D 绒绒鸹
题意
nn 个点,每一个点都一个父亲,每次操作在一个点上放一个绒绒鸹,随即立刻输出这个点的绒绒鸹的数量。接下来,每一个绒绒鸹都会同时向他所在点的父亲移动。
数据范围:1≤n,m≤5×105,1≤ai≤n1≤n,m≤5×105,1≤ai≤n。
输入
第一行 nn;
第二行,序列 aa;
第三行 mm;
第四行,每次输入一个整数 xx,表示 xx 位置放一只绒绒鸹。
本题强制在线,即对于输入的 mm 次操作的数,第 ii 次的数需要异或上第 i−1i−1 次操作的答案。
输入格式
第一行一个整数 nn。
接下来 nn 行,第 ii 行表示 aiai。
接下来一行一个整 mm。
接下来 mm 行每行一个整数 xx,表示在 xx 位置放置一只绒绒鸹。
本题强制在线,即对于输入的 mm 次操作的数,第 ii 次的数需要异或上第 i−1i−1 次操作的答案。
输出格式
输出 mm 行,第 ii 行输出一个整数,表示第 ii 次操作的答案。
样例输入
6
1 2 1 3 3 6
5
1 4 7 3 7
样例输出
1 1 1 1 2
考场思路
最后三分钟写的,卡点交,少一个加号,爆零。
开三个数组 a,b,ca,b,c,aa 是原序列,bb 是操作时的序列,cc 是跳完之后的序列。
然后模拟,注意不要搞混了。
代码(00 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; int n,m,a[250001],b[250001],c[250001]; int ans[250001]; int main() { int i,j,x; cin>>n; for(i=1;i<=n;i++) cin>>a[i]; int la = 0; cin>>m; for(i=1;i<=m;i++) { cin>>x; x ^= la; b[x]++; la = b[x]; cout<<b[x]<<endl; memset(c,0,sizeof c); for(j=1;j<=n;j++) c[a[j]] += b[j]; for(j=1;j<=n;j++) b[j] = c[j]; } return 0; }
正解做法一
其实图就是一个基环树森林,环上的做法是简单的。
考虑树上如何处理:
考虑什么时候点 yy 会对点 xx 产生贡献,发现当 timey−timex=depy−depxtimey−timex=depy−depx 时才会产生贡献,即此时只要开个桶即可。
可以大力树剖来计算答案,复杂度 O(nlog2n)O(nlog2n)。
正解做法二
nn 个位置构成环套树森林,可以拆分为一些有根树和有向环,且有根树的根的后继为有向环上的点。
对有根树进行轻重链剖分,对于一个球,经过 O(logn)O(logn) 条轻边后可以到达环上。
对于一条重链或一个环,维护一个序列表示每个位置的球的个数。
当一个球经过一条轻边时,修改离开的重链和进入的重链环数。
每次操作后,环对应的序列会循环移动一位,重链对应的序列会向深度较浅的方向移动一位(由于球离开重链导致移位出界的情况已被处理,重链上也可视为循环移位)。
这些移位不需要直接处理,只需要在需要修改/查询序列的某个位置时,将操作位置加上对应的偏移量即可。
另一个做法是对环用数组维护,考虑去掉环剩下的每棵树,每次加入球就在对应位置记录这个球的加入时间+离根的距离,查询时查一个点子树内加入时间+离根的距离等于相应值得球的个数就行了。
对每个值 xx,用支持维护有序集合、查询区间元素个数的数据结构维护加入时间+离根的距离 =x=x 的球的 DFS 序编号,查询为对某个 xx,问 DFS 序在区间内球的个数。
时间复杂度 O(n+mlogn)O(n+mlogn),空间复杂度 O(n+m)O(n+m)。
代码:
点击查看代码
#include <bits/stdc++.h> using namespace std; const int N = 5e5 + 10, M = 1e6 + 10; int n, m, f[N], id[N], pos[N], A[N]; bool in_tr[N]; vector<int> update[N + M], vec[2 * N]; int h[N], e[M], ne[M], idx; inline void add(int a, int b) {e[idx] = b, ne[idx] = h[a], h[a] = idx ++; } int siz[N], hson[N], top[N], dep[N]; inline void Init() { static int ind[N]; for(int i = 1; i <= n; i ++) ind[f[i]] ++; static int que[N], ql = 0, qr = 0; for(int i = 1; i <= n; i ++) if(!ind[i]) que[++qr] = i, siz[i] = 1; while(ql != qr) { int u = que[++ql]; in_tr[u] = true; if(!(--ind[f[u]])) que[++qr] = f[u]; siz[f[u]] += siz[u]; if(siz[hson[f[u]]] < siz[u]) hson[f[u]] = u; } for(int i = qr; i; i --) if(!top[que[i]]) { int u = que[i]; int v = u; while(v) { top[v] = u, dep[v] = dep[f[v]] + 1; pos[v] = vec[u].size(), vec[u].emplace_back(v), id[v] = u; v = hson[v]; } } for(int i = 1; i <= n; i ++) if(!id[i]) { assert(!in_tr[i]); int u = i; while(!id[u]) {id[u] = n + i, vec[id[u]].emplace_back(u); u = f[u]; } reverse(vec[id[u]].begin(), vec[id[u]].end()); for(int j = 0; j < vec[id[u]].size(); j ++) pos[vec[id[u]][j]] = j; } } int main() { ios::sync_with_stdio(false), cin.tie(0); memset(h, -1, sizeof h); cin >> n; for(int i = 1; i <= n; i ++) cin >> f[i]; cin >> m; Init(); int lastans = 0; for(int T = 0; T < m; T ++) { for(auto &Id : update[T]) { int x = f[vec[Id][0]], y = vec[Id][(T - 1) % vec[Id].size()]; //cerr << x << ' ' << y << ' ' << get(x, T + 1) << '\n'; A[vec[id[x]][(pos[x] + T) % vec[id[x]].size()]] += A[y], A[y] = 0; if(in_tr[x]) update[T + (dep[x] - dep[top[x]]) + 1].emplace_back(id[x]); } int x, y; cin >> x; x = x xor lastans; int Id = id[x], p = pos[x]; y = vec[Id][(p + T) % vec[Id].size()]; if(in_tr[x]) update[T + (dep[x] - dep[top[x]]) + 1].emplace_back(id[x]); cout << (lastans = ++A[y]) << '\n'; //for(int i = 1; i <= n; i ++) cerr << A[i] << " \n"[i == n]; } return 0; }
Day 2
数据结构+DP。
100+60+0+0=160100+60+0+0=160 pts。Rank 38/58。
A OBG
题意
小 L 在某论坛 codeforces 上一共发出了 nn 条评论,第 ii 条评论有 aiai 个赞,bibi 个踩,其中一个赞会抵消一个踩,一个踩也会抵消一个赞。
对于每条评论,如果抵消后留下的是赞,则它的 Contribuion 值加上赞的个数整除 1010 的下取整;如果留下的是踩,那么它的 Contribution 减去踩得个数整除 1010 的下取整。
数据范围:1≤n≤100,ai≤108,bi≤1081≤n≤100,ai≤108,bi≤108。
输入格式
第一行,一个整数 nn,代表有 nn 条评论。
第二行,nn 个整数 ai(1≤i≤n)ai(1≤i≤n)。
第二行,nn 个整数 bi(1≤i≤n)bi(1≤i≤n)。
输出格式
一个整数,表示一共获得的 Contribution。
样例输入
2
11 1
1 11
样例输出
0
考场思路
模拟。
代码(100100 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,cnt; struct node { int a,b,sum; }a[101]; main() { int i; cin>>n; for(i=1;i<=n;i++) cin>>a[i].a; for(i=1;i<=n;i++) cin>>a[i].b; for(i=1;i<=n;i++) a[i].sum = a[i].a-a[i].b; for(i=1;i<=n;i++) { if(a[i].sum>=0) cnt += a[i].sum/10; else cnt += a[i].sum/10; } cout<<cnt<<endl; return 0; }
正解
和思路一样。
B FTT
题意
nn 只青蛙排成一个序列,第 ii 只青蛙的叫声为 aiai,其中任意两只青蛙的叫声都不一致。
现在要选 k+1k+1 只青蛙作为一个集训队,集训队的成员编号为 0,1,…,k0,1,…,k。
集训队要求:对于第 ii 名队员和第 jj 名队员,i<ji<j 且 ai<ajai<aj。
你需要求出有多少种选出青蛙集训队的方案,方案数对 998244353998244353 取模。
数据范围:1≤n≤105,0≤k≤10,1≤ai≤n1≤n≤105,0≤k≤10,1≤ai≤n。
输入格式
第一行输入两个数 n,kn,k。
接下来输入 nn 行,每行一个数,其中第 ii 行输入 aiai,表示第 ii 只青蛙的叫声。
输出格式
输出一个数,答案对 998244353998244353 取模后的结果。
样例输入
5 2
1 2 3 5 4
样例输入
7
考场思路
观察到此题就是一个 LIS,因此考虑 DP。
设 dpi,jdpi,j 为前 ii 个青蛙,选了 jj 个青蛙的方案数,容易得:
- 可以三重循环求出。为目前选了多少只青蛙和 ii 与 jj 的位置。
- 当 ak<aiak<ai 时,dpi,j=(dpi,j+dpk,j−1)dpi,j=(dpi,j+dpk,j−1),注意初始为 dp0,0=1dp0,0=1。
- 答案为所有的 dpi,kdpi,k 的和,注意取模。
还有一个坑点:是 k+1k+1 只青蛙而不是 kk 只青蛙!!
代码(6060 分,裸 DP,代码变量与题意略有出入):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long const int mod = 998244353; int n,K; int a[100001],dp[10001][11]; int ans; main() { cin>>n>>K; K++; int i,j,k; for(i=1;i<=n;i++) cin>>a[i]; dp[0][0] = 1; for(j=1;j<=K;j++) { for(i=1;i<=n;i++) { for(k=0;k<i;k++) { if(a[k]<a[i]) dp[i][j] = (dp[i][j]+dp[k][j-1])%mod; } } } for(i=1;i<=n;i++) ans += dp[i][K],ans %= mod; cout<<ans%mod<<endl; return 0; }
正解
用树状数组或线段树优化,这里用树状数组比较简单。
我们需要开很多个树状数组,其中:
find(r,l)表示查询 ll 到 rr 区间的和。modify(x,y,z)作用是对于第 zz 个树状数组的第 xx 个位置,将值加上 yy。
然后就很简单了,初始化就让第一个树状数组的第一个位置为 11,最后输出find(n+1,k+1)。注意为了好实现,find()倒序实现。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,k; int a,b[100005]; int c[100005][15]; int mod = 998244353; int lowbit(int x) { return x & -x; } void modify(int x,int y,int z) { int i; for(i=x;i<=n+1;i+=lowbit(i)) c[i][z] += y,c[i][z] %= mod; return; } int find(int x,int y) { int res = 0; while(x) res += c[x][y],res %= mod,x -= lowbit(x); return res; } main() { cin>>n>>k; k++; modify(1,1,1); int i,j; for(i=1;i<=n;i++) { cin>>a; for(j=1;j<=k;j++) modify(a+1,find(a,j),j+1); } cout<<find(n+1,k+1)<<endl; return 0; }
C G-CAT
题意
有一个长度为 nn 的序列,第 ii 个位置为 cici。
qq 次询问,每次给定一个 1≤l≤r≤n1≤l≤r≤n,考虑子序列 cl,cl+1,…,crcl,cl+1,…,cr,你需要选出若干个互不相交的区间,满足每个区间的元素之和为 00。要求最大化选择区间的数量,求出你可以选出多少区间。
数据范围:1≤n,q≤4×105,−109≤ci≤109,1≤li≤ri≤n1≤n,q≤4×105,−109≤ci≤109,1≤li≤ri≤n。
输入格式
输入的第一行包含一个整数 nn。
接下来一行,包含 nn 个整数 c1,c2,⋯,cnc1,c2,⋯,cn。
接下来一行,包含一个整数 qq。
接下来 qq 行,每行两个整数 l,rl,r,描述一组询问。
输出格式
对于每组询问,输出一行一个整数,表示答案。
样例输入
10
1 2 -3 0 1 -4 3 2 -1 1
3
1 10
1 5
2 9
样例输出
4
2
2
考场思路
DP。
样例全过,大样例答案正确,超时。
但是爆零,就不讲解思路了。
代码(00 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,q; int a[400088]; int dp[400088]; main() { cin>>n; int i; for(i=1;i<=n;i++) cin>>a[i]; cin>>q; while(q--) { int l,r; scanf("%d %d",&l,&r); memset(dp,0,sizeof(dp)); unordered_map<int,int> last; last[0] = 0; int sum = 0; for(i=l;i<=r;i++) { sum += a[i]; if (last.find(sum)!=last.end()) dp[i] = dp[last[sum]]+1; dp[i] = max(dp[i],dp[i-1]); last[sum] = i; } printf("%d\n",dp[r]); } return 0; }
正解
记 nxtnxt 数组表示 nxtinxti 是 ii 右边的第一个满足 nxti∑j=iaj=0nxti∑j=iaj=0 的数。
考虑选择了 ii 之后的选择,不难发现是 maxnxti+1≤i≤nnxtimaxnxti+1≤i≤nnxti。
发现选择关系构成了一棵树,建树倍增判断是否走出区间即可。
时间复杂度 O((n+m)logn)O((n+m)logn)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; using ll = long long; int nxt[400005],st[400005]; ll sum[400005]; int n,Q; struct node { int l,r,s; }q[400001]; main() { ios_base::sync_with_stdio(false); cin.tie(nullptr); cin>>n; int i,j,k; for(i=1;i<=n;i++) { cin>>sum[i]; sum[i] += sum[i-1]; } multiset<ll> s{0}; int l,r; l = 1,r = 0; for(;l<=n;l++) { while(r<=n) { if(s.count(sum[r])>=2) break; r++; s.emplace(sum[r]); } nxt[l] = r+1; s.erase(s.find(sum[l-1])); } cin>>Q; for(i=1;i<=Q;i++) { cin>>q[i].l>>q[i].r; q[i].s = 0; } st[n+1] = st[n+2] = n+2; for(j=log2(n)+1;j>=0;j--) { for(i=1;i<=n;i++) st[i] = nxt[i]; for(k=1;k<=j;k++) for(i=1;i<=n;i++) st[i] = st[st[i]]; for(i=1;i<=Q;i++) { if(st[q[i].l]<=q[i].r+1) { q[i].s += (1<<j); q[i].l = st[q[i].l]; } } } for(i=1;i<=Q;i++) cout<<q[i].s<<'\n'; return 0; }
先别走啊!!
在输出答案时,我一开始用的 cout<<q[i].s<<endl;,结果 100→50100→50;改成 cout<<q[i].s<<'\n' 就过了。
警钟撅烂磨成粉!!!
做题前一定要 #define endl '\n'!!!!
OIL
题意
给你一个长度为 nn 的序列 aa。
定义 maxpre(l,r) 是区间 [l,r] 的最大前缀和;maxsuf(l,r) 是区间 [l,r] 的最大后缀和。
最大前缀和最大后缀都可以是空串。
求:n∑l=1n∑r−l+1r−1∑i=l×maxpre(l,i)×maxsuf(i+1,r)
答案对 109+7 取模。
数据范围:1≤n≤105,−109≤ai≤109。
输入格式
第一行一个数 n 表示这个序列的长度。
之后一行包含 n 个整数,表示这个序列。
保证序列中所有元素都在 [−109,109] 中。
输出格式
输出一行一个整数表示答案。
输入样例
5
1 -2 3 -4 5
输出样例
76
考场思路
不会,随便输出了一个数。
代码(0 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; int main() { cout<<219352; return 0; }
正解
考虑对于 i 求出 prei=∑ij=1maxprej 与 sufi=∑nj=imaxsufi。
则 ∑n−1i=1prei×sufi+1 即为答案(以下表达中 maxpre 可以 ≤0)。
考虑那些 maxpre 会对 pre 产生贡献,发现要 maxpre≥0。
考虑平衡树,从 1 枚举到 n,之前的所有 maxpre 都加入 ai 然后插入当前的 ai,然后查询大于零的数的和即为 prei。
全局加可以转化为打 tag,suf 和 pre 的求法类似,时间复杂度为 O(nlogn)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define ll long long const int mod=1e9+7; int n; ll a[100005]; priority_queue<pair<ll,int> > Q; ll f[100005],g[100005],ans,tag; int main(){ cin>>n; for(int i=1;i<=n;++i) cin>>a[i]; for(int i=1;i<=n;++i){ int cnt=0; Q.push({-tag,1}); tag=(tag+a[i]); while(!Q.empty()&&(Q.top().first+tag)>0){ ans=(ans+(Q.top().first+tag)%mod*Q.top().second%mod)%mod; cnt+=Q.top().second;Q.pop(); } if(cnt) Q.push({-tag,cnt}); f[i]=ans; } while(!Q.empty()) Q.pop(); ans=0,tag=0; for(int i=n;i>=1;--i){ int cnt=0; Q.push({-tag,1}); tag=(tag+a[i]); while(!Q.empty()&&(Q.top().first+tag)>0){ ans=(ans+(Q.top().first+tag)%mod*Q.top().second%mod)%mod; cnt+=Q.top().second;Q.pop(); } if(cnt) Q.push({-tag,cnt}); g[i]=ans; } ans=0; for(int i=1;i<n;++i) ans=(ans+f[i]*g[i+1]%mod)%mod; cout<<ans<<endl; return 0; }
Day 3
图论专场。
100+30+0+0=130 pts。Rank 25/58。
A 开关(switch)
题意
两个 4×4 的棋盘,每个元素为 0 或 1,1 表示有棋子。
你需要移动第一个棋盘的棋子,可以上下左右移动一个格子,最小化移动次数,使两个棋盘完全一致。
输入格式
八行四列,分别为两个棋盘,棋子用 1 表示。
样例输出
输出一个整数表示最小移动次数。
样例输入
0100
0000
0001
0000
0000
0001
0001
0000
样例输出
3
考场思路
BFS,用二进制记录状态,复杂度 O(216×16)。
代码(100 分):
点击查看代码
#include <iostream> #include <bits/stdc++.h> using namespace std; const int N = 4; const int dx[] = {1, -1, 0, 0}; const int dy[] = {0, 0, 1, -1}; bool in(int x, int y) { return x >= 0 && x < N && y >= 0 && y < N; } int move(int state, int x1, int y1, int x2, int y2) { int pos1 = x1 * N + y1; int pos2 = x2 * N + y2; return state ^ (1 << pos1) ^ (1 << pos2); } int a[11][11]; int b[11][11]; map<int,int> vis; queue<int> q; int main() { int i,j; for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { char c; cin>>c; a[i][j] = c-'0'; } } for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { char c; cin>>c; b[i][j] = c-'0'; } } int start = 0; int idx = 0; for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { if (a[i][j]) { start |= (1 << idx); } idx++; } } int end = 0; idx = 0; for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { if (b[i][j]) { end |= (1 << idx); } idx++; } } q.push(start); vis[start] = 1; int steps = 0; while (!q.empty()) { int size = q.size(); while (size--) { int cur = q.front(); q.pop(); if (cur == end) { cout << steps << endl; return 0; } for (i = 0; i < N; i++) { for (j = 0; j < N; j++) { int pos = i * N + j; if ((cur >> pos) & 1) { int k; for (k = 0; k < 4; k++) { int nx = i + dx[k]; int ny = j + dy[k]; if (in(nx, ny)) { int newpos = nx * N + ny; if (!((cur >> newpos) & 1)) { int state = move(cur, i, j, nx, ny); if (!vis[state]) { q.push(state); vis[state] = 1; } } } } } } } } steps++; } return 0; }
正解
同思路。
B 陷阱(trap)
题意
有两个国,W 国和 Y 国,W 国军掉进了 Y 国的陷阱。
陷阱由 n 个点,m 条隧道构成。第 i 条隧道连接着 ui 和 vi。任意两个点都可以通过隧道到达,现在 W 国军队在 1 号节点。
假如 W 国军队可以到达每个节点,那他们就可以把所有节点都破坏,逃出陷阱。为了防止 W 国军队逃出,Y 国在每条隧道里都放着屏障,第 i 条隧道里的屏障强度为 ai。只要一个隧道里的屏障不失效,W 国军队就不能使用这条隧道移动。
然而,W 国军队携带着一个总能量为 x 的破障机,它可以消耗能量来使屏障失效。具体的,如果想要让一个强度为 y 的屏障失效,破障机就要消耗 y 的能量。破障机不能透支能量,所以,在消耗 y 的能量之前,它剩余能量必须大于等于 y。
为了防止 W 国军队逃出,Y 国决定使用强化核心。第 i 条隧道里的屏障与强化核心的适配度为 bi ,当 Y 国使用了一个强化核心,则所有屏障都会强化,对于每个屏障,其强度上升其适配度。具体的,假如 Y 国使用了 k 个强化核心,则对于每个屏障,其强度会变成 ai+kbi
请你求出,Y 国最少使用几个强化核心,可以使得 W 国军队无法逃出。
数据范围:2≤n≤3×105,n−1≤m≤3×105,1≤ui≤vi≤n,1≤ai≤109,1≤bi≤103,1≤x≤1014。
输入格式
第一行三个整数 n,m,x。
接下来 m 行每行四个正整数表示 ui,vi,ai,bi。
输出格式
输出一个整数,表示 Y 国最少使用强化核心数。
样例输入
3 3 100
1 2 3 1
2 3 1 2
1 3 3 2
样例输出
33
考场思路
二分+最小生成树。
大样例全过但是二分细节出错,70→30,有个小地方漏判断了,不然能 100。
代码(80 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int unsigned long long int n,m,x; struct node { int u,v,a,b; }e[300001]; int k,ans,cnt; int fa[300001]; bool cmp(node a,node b) { return a.a+a.b*k<b.a+b.b*k; } int find(int a) { while(a!=fa[a]) a = fa[a] = fa[fa[a]]; return a; } void kru() { ans = cnt = 0; sort(e+1,e+1+m,cmp); int i; for(i=1;i<=m;i++) { int fu = find(e[i].u),fv = find(e[i].v); if(fu==fv) continue; ans += e[i].a+e[i].b*k; fa[fv] = fu; if(++cnt==n-1) break; } return; } bool check(int mid) { int i; for(i=1;i<=n;i++) fa[i] = i; k = mid; kru(); return x<ans; } main() { // freopen("ex_trap5.in","r",stdin); cin>>n>>m>>x; int i; for(i=1;i<=m;i++) cin>>e[i].u>>e[i].v>>e[i].a>>e[i].b; int l,r; l = 0,r = 1e14+114; while(l<r) { int mid = (l+r+1)>>1; if(check(mid)) r = mid-1; else l = mid; } cout<<r+1<<endl; return 0; }
正解
把思路的代码改改细节就过了。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,m,x; struct node { int u,v,a,b; }e[300001]; int k,ans,cnt; int fa[300001]; bool cmp(node a,node b) { return a.a+a.b*k<b.a+b.b*k; } int find(int a) { while(a!=fa[a]) a = fa[a] = fa[fa[a]]; return a; } int bj; void kru() { bj = 0; ans = cnt = 0; sort(e+1,e+1+m,cmp); int i; for(i=1;i<=m;i++) { int fu = find(e[i].u),fv = find(e[i].v); if(fu==fv) continue; ans += e[i].a+e[i].b*k; if(ans>x) { break; } fa[fv] = fu; if(++cnt==n-1) break; } return; } bool check(int mid) { int i; for(i=1;i<=n;i++) fa[i] = i; k = mid; kru(); return x<ans; } main() { // freopen("ex_trap5.in","r",stdin); cin>>n>>m>>x; int i; for(i=1;i<=m;i++) cin>>e[i].u>>e[i].v>>e[i].a>>e[i].b; int l,r; l = 0,r = 1e14+114514; int anss = x; while(l<=r) { int mid = (l+r)>>1; if(check(mid)) r = mid-1,anss = mid; else l = mid+1; } cout<<anss<<endl; return 0; }
C 包围(besiege)
题意
给你一个图,判断最短路和次短路相同的情况下,最短路和次短路有无交点,有,输出
NO,否则输出YES。
数据范围:1≤n,m≤3×105,1≤ui,vi≤n,1≤wi≤109。
输入格式
第一行两个正整数 n,m。
接下来 m 行,每行三个正整数 ui,vi,wi。
输出格式
如果有解,输出YES,否则输出NO。
样例输入
4 5
1 3 5
2 4 4
3 2 3
4 3 1
2 3 3
样例输出
YES
考场思路
跑一遍 Dijsktra,然后乱搞。
纯属猜的。
大样例全过,但,0 分。
代码(0 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; const int INF = 1e9; int n,m; struct node { int to,w; }; vector<node> g[300001]; void add(int u,int v,int w) { g[u].push_back({v,w}); } int dist[300001]; void dij(int s,int n) { memset(dist,0x3f,sizeof(dist)); priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq; dist[s] = 0; pq.push({0,s}); while(!pq.empty()) { int sec = pq.top().second; int fir = pq.top().first; pq.pop(); if(fir>dist[sec]) continue; for(auto i:g[sec]) { int v = i.to; int w = i.w; if(dist[sec]+w<dist[v]) { dist[v] = dist[sec]+w; pq.push({dist[v],v}); } } } } bool check(int n) { int i; for(i=2;i<=n;i++) { for(auto j:g[i]) { int u = i,v = j.to,w = j.w; if(dist[u]+w==dist[v]) { if(dist[u]>dist[n]) return 1; } } } return 0; } int main() { cin>>n>>m; int i; int cnt = 0; for(i=0;i<m;i++) { int u,v,w; cin>>u>>v>>w; add(u,v,w); add(v,u,w); } dij(1,n); if(!check(n)) puts("YES"); else puts("NO"); return 0; }
正解
建立最短路 DAG,假如存在一个点只有一个前驱,那么显然题目条件不可能满足。
假如所有点都有至少两个前驱,那么一定可以。可以通过构造证明:
取两条 1 到 i 的最短路,假设两条最短路出了 i 之外最后的交点为 k,令第一条路线中 k 的后继是 j,假如 j 存在的另一个前驱为 l,把第一条路线换成 1 到 l 的最短路再接上第一条路线本来 j 到 i 的路线。发现这样替换后,两个路线的最后交点会越来越提前,直到 1 为止。
复杂度 O((n+m)logn)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,m; struct node { int to,w,nxt; }e[600001]; int cnt,head[300001]; void add(int u,int v,int w) { e[++cnt].to = v; e[cnt].w = w; e[cnt].nxt = head[u]; head[u] = cnt; } int dis[300001]; priority_queue<pair<int,int>,vector<pair<int,int> >,greater<pair<int,int> > > pq; void dij() { memset(dis,0x7f,sizeof(dis)); dis[1] = 0; pq.push({0,1}); while(!pq.empty()) { int fir = pq.top().first; int sec = pq.top().second; pq.pop(); if(fir!=dis[sec]) continue; int i; for(i=head[sec];i;i=e[i].nxt) { int v = e[i].to; int w = e[i].w; if(dis[sec]+w<dis[v]) { dis[v] = dis[sec]+w; pq.push({dis[v],v}); } } } return; } main() { cin>>n>>m; int i,j; for(i=1;i<=m;i++) { int u,v,w; cin>>u>>v>>w; add(u,v,w); add(v,u,w); } dij(); for(i=2;i<=n;i++) { int c = 0; for(j=head[i];j;j=e[j].nxt) { int v = e[j].to; if(dis[v]+e[j].w==dis[i]) { c++; if(v==1) c++; } } if(c<2) { puts("NO"); return 0; } } puts("YES"); return 0; }
D 武器(weapon)
题意
Y 国有 n 个机甲,第 i 个机甲版本号为 i。还有 m 个武器,每个武器有伤害 ai。
对于第 i 个武器,只能在版本号为 [li,ri] 内的机甲装配,一个机甲最多装一个武器。
你需要帮助他们配武器,使得尽可能多的机甲有武器,还要让伤害最大。
数据范围:1≤n≤500,1≤m≤106,1≤li≤ri≤n,1≤ai≤103。
输入样例
第一行两个整数 n,m。
接下来 m 行每行三个正整数表示 li,ri,ai。
输出格式
输出两个整数,第一个整数表示最大装配数量,第二个整数表示在那基础上,被装配的武器的攻击力和最大值。
样例输入
4 4
3 4 1
1 2 9
1 2 3
1 2 4
样例输出
3 15
考场思路
觉得像网络流,但想了想,应该是二分图最大匹配。
大样例全过,但,0 分。
代码(0 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; vector<int> g[501],match; map<int,int> vis; struct node { int l,r,a; }wuqi[1000001]; void add(int cnt,int l,int r,int a) { wuqi[cnt].l = l; wuqi[cnt].r = r; wuqi[cnt].a = a; } bool cmp(node a,node b) { return a.r<b.r; } int n,m; bool dfs(int u) { for(auto v:g[u]) { if(!vis[v]) { vis[v] = 1; if(match[v]==-1||dfs(v)) { match[v] = u; return 1; } } } return 0; } int solve(int n) { int cnt = 0; match.assign(n,-1); int i; for(i=0;i<n;i++) { vis.clear(); if(dfs(i)) cnt++; } return cnt; } int main() { scanf("%d %d",&n,&m); int i,j; for(i=0;i<m;i++) { int l,r,a; scanf("%d %d %d",&l,&r,&a); add(i,l,r,a); } sort(wuqi,wuqi+m,cmp); for(i=0;i<m;i++) for(j=wuqi[i].l;j<=wuqi[i].r;j++) g[j].push_back(i+n); int cnt = solve(n+m); int ans = 0; for(i=0;i<m;i++) { if(match[i+n]!=-1) ans += wuqi[i].a; } printf("%d %d\n",cnt,ans); return 0; }
正解
其实网络流能拿 25 分,但正解不是网络流。
我们考虑将右侧点按照点权倒序排序,然后依次使用匈牙利尝试加入匹配,能加就加。
证明:
显然,对于每个前缀,我们以任意顺序把点加入匹配 不会改变最大匹配,当每次最大匹配数改变时,我们加入的都是最大的那个点,所以一定最优。现在复杂度为 O(n2m)。
这样太慢了,发现匹配成功只会发生 O(n) 次。我们考匈牙利是怎么进行的,我们从一个未匹配的右侧点开始,走一条未匹配边,再走一条匹配边,再走一条未匹配边,……,直到做到一个未匹配的左侧点。那么其实我们可以逆过来考虑,我们从所有未匹配的左侧点开始广搜,一个左侧点可以走到所有能到达它的右侧点,一个右侧点只能走到它现在的匹配点,那么加入一个右侧点时,只需要判定其能到达的左侧点是否有点被搜索到过。如果有,那么更新匹配,否则无事发生、
用前缀和帮助判定,总复杂度 O(n3+mlogn),复杂度瓶颈在排序。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; int n,m; int ans,k; int lmatch[501],rmatch[501],pre[501]; int vis[501],s_vis[501]; struct node { int l,r,a; }a[1000001]; bool cmp(node a,node b) { return a.a>b.a; } vector<int> v; queue<int> q; void build() { memset(vis,0,sizeof(vis)); int i,j; for(i=1;i<=n;i++) if(!lmatch[i]) vis[i] = 1,pre[i] = 0,q.push(i); while(!q.empty()) { int u = q.front(); q.pop(); // cout<<v.size()<<endl; for(i=0;i<v.size();i++) { if(u>=a[v[i]].l&&u<=a[v[i]].r) { if(!vis[rmatch[i+1]]) vis[rmatch[i+1]] = 1,pre[rmatch[i+1]] = u,q.push(rmatch[i+1]); } } } for(i=1;i<=n;i++) s_vis[i] = s_vis[i-1]+vis[i]; return; } signed main() { cin>>n>>m; int i; for(i=1;i<=m;i++) cin>>a[i].l>>a[i].r>>a[i].a; sort(a+1,a+1+m,cmp); ans = 0; build(); for(i=1;i<=m&&v.size()<n;i++) { int l = a[i].l; int r = a[i].r; int w = a[i].a; if(!(s_vis[r]-s_vis[l-1])) continue; ans += w; // cout<<ans<<endl; v.push_back(i); int u = 0,lst = v.size(); int j; for(j=l;j<=r;j++) if(vis[j]) { u = j; break; } while(u) { rmatch[lst] = u; swap(lmatch[u],lst); u = pre[u]; } build(); } cout<<v.size()<<' '<<ans<<endl; return 0; }
Day 4
100+0+0+0 pts。Rank 39/38。
A 权力(authority)
题意
给定一个 n 个点的有根树,询问有几个点的子树大小超过整个树的一半。
数据范围:1≤n≤3×105。
样例输入
13
1 2 2 1 4 6 7 8 7 10 7 10
样例输出
4
考场思路
简单的 DFS。
直接模拟即可。
代码(100 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; vector<int> g[400001]; int vis[400001]; int n,sz[400001]; int ans; void dfs(int u) { sz[u] = 1; for(int v:g[u]) { dfs(v); sz[u] += sz[v]; } return; } signed main() { // freopen("ex_authority4.in","r",stdin); ios_base::sync_with_stdio(0); cin.tie(0); cin>>n; int i; for(i=2;i<=n;i++) { int fa; cin>>fa; if(fa==i) continue; g[fa].push_back(i); } dfs(1); for(i=1;i<=n;i++) if(2*sz[i]-1>n) ans++; cout<<ans<<endl; return 0; }
正解
同思路。
B 病毒(virus)
题意
W 国决定攻略 Y 国的网络系统。
Y 国的网络系统由 n 台编号依次为 1,2,…,n 的服务器组成。为了防止被入侵,Y 国每天都会更改网络结构,具体的,初始时服务器之间都没有边,然后 ∀2≤i≤n,第 i 台服务器会从编号在 [1,i−1] 内的服务器中等概率选出一个服务器,向其连一条有向边。显然,最后 Y 国的网络系统会呈现出一个以 1 为根的内向树结构。
W 国早就在 Y 国的若干台服务器中种下病毒,假如有一天,存在某个点到 1 的路径上出现了所有带病毒的服务器,那么 Y 国的网络系统就会崩溃。现在,Y 国请求你帮他们计算,每次更改完网络结构后,网络系统崩溃的概率。
由于 Y 国并不知道哪些服务器被种了病毒,所以他们只能对 W 国的行为进行猜测后来询问你。具体的,Y 国会询问你 q 次,每次给定一个点集 Si,你需要求出,假如只有 Si 内的服务器中了病毒,那每次更改完网络结构后,网络系统崩溃的概率是多少。
输入格式
第一行两个正整数 n,q。
接下来 q 行:每行开头为一个正整数 ki,接下来有 ki 个互不相同的在 [1,n] 内的整数表示 Si。
输出格式
输出共 q 行,第 i 行你需要输出当只有 Si 内的服务器中了病毒,那每天网络系统崩溃的概率,对 998244353 取模。
样例输入
3 2
2 1 2
2 2 3
样例输出
1
499122177
考场思路
以为是概率 DP,写了 1h,样例死活不过,不放代码了。
正解
诈骗题。
设 S 为网络子集。
假如 S 中的点从小到大依次为 x1,x2,…,xm,可以发现“xi 是 xi 的祖先”这些事件之间是相互独立的。
然后通过计算,发现 xi 是 xi+1 的祖先的概率和 xi+1 具体是什么无关:我们令 xi+1 一直跳父亲,直到编号小于等于 xi 的那一次。因为父亲是等概率选取的,所以概率就是 1xi。
同时,对于 ∏m−1i=11xi。
总复杂度 O(n+∑ki)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long const int mod = 998244353; int n,q; int ksm(int x,int k) { int ans = 1; while(k) { if(k&1) ans = ans*x%mod; x = x*x%mod; k>>=1; } return ans%mod; } main() { cin>>n>>q; while(q--) { int t,cnt; int ans = 1; int ma = INT_MIN; cin>>cnt; while(cnt--) { cin>>t; ma = max(ma,t); ans = (ans*t)%mod; } cout<<(ksm(ans,mod-2)*ma)%mod<<endl; } return 0; }
C 合作(cooperate)
题意
给定一个 n 个点 m 条边的无向简单图,两条边可以匹配当且仅当它们有共用的端点,求是否有完美匹配,报告无解或构造。
数据范围:1≤n,m≤3×105,1≤ui,vi≤n。
输入格式
第一行两个整数 n,m。
接下来 m 行每行两个整数表示 ui,vi。
输出格式
假如无解,输出一行NO。
否则输出一行YES,接下来输出 m 行每行一个 ui,vi 之中的整数,表示第 i 条隧道的士兵被安排到哪个阵地。你需要保证每个数都出现偶数次。(请不要输出多余的空格和换行,否则可能被判定为格式错误)
考场思路
考试的时候想了好久,嗑了差不多 2h,会判断是否有解了,但不会输出。不得不吐槽一下毒瘤出题人,判断正确竟然不得分,太坑了(讲个笑话,讲题的时候发 std,std 也没有输出方案 xD)!!
判断有没有解就用欧拉回路,简单 DFS 一下即可。
代码(0 分):
点击查看代码
#include <iostream> #include <vector> using namespace std; vector<int> adj[200001]; int ans[200001], vis[200001]; void dfs(int u) { vis[u] = 1; int cnt = 0; for (int v : adj[u]) { if (!vis[v]) { dfs(v); cnt++; if (cnt % 2 == 1) { ans[u] = v; ans[v] = u; } } } } int main() { int n, m; // freopen("ex_cooperate4.in","r",stdin); cin >> n >> m; for (int i = 0; i < m; i++) { int u, v; cin >> u >> v; adj[u].push_back(v); adj[v].push_back(u); } if (m % 2 == 1) { cout << "NO" << endl; } else { dfs(1); cout << "YES" << endl; for (int i = 1; i <= n; i++) { cout << ans[i] << endl; } } return 0; }
正解
显然可得出:有解的情况当且仅当每个连通块边数都是偶数,下面构造进行证明。
对于部分分的特殊结构(20% 的数据保证图为树),树可以从叶子开始构造,仙人掌可以建圆方树然后和树类似的构造,海胆图找到中心后就很容易构造了。
对于一般的图而言,我们建立 DFS 树,这样非树树边只有返租边。从深到浅考察每个点,考虑这个点和儿子的连边及其连出的非树边中还没有匹配的边的数量,如果是偶数则直接两两匹配,否则再加入这个点和父亲的连边然后两两匹配。由于除了根节点之外的每个点都能用和父亲连边调整奇偶性,且连通块一共有偶数条边,所以一定能完美匹配。
复杂度 O(n+m)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; struct node { int to,w,nxt; }e[600001]; int head[300001],cnt; void add(int u,int v,int w) { cnt++; e[cnt].to = v; e[cnt].w = w; e[cnt].nxt = head[u]; head[u] = cnt; } int n,m; int vis[300001],path[300001],used[300001]; void dfs(int u,int id) { vis[u] = 1; int i,j; for(i=head[u];i;i=e[i].nxt) { int v = e[i].to; int w = e[i].w; if(!vis[v]) dfs(v,w); } vector<int> ve; for(i=head[u];i;i=e[i].nxt) { int v = e[i].to; int w = e[i].w; if(!used[w]&&w!=id) { ve.push_back(w); used[w] = 1; } } if(ve.size()&1) { if(id==0) { puts("NO"); exit(0); } used[id] = 1; ve.push_back(id); } for(auto p:ve) path[p] = u; } signed main() { cin>>n>>m; int i; for(i=1;i<=m;i++) { int u,v; cin>>u>>v; add(u,v,i); add(v,u,i); } for(i=1;i<=n;i++) if(!vis[i]) dfs(i,0); puts("YES"); for(i=1;i<=m;i++) cout<<path[i]<<endl; return 0; }
D 激光炮(jgp)
题意
Y 国有 n 个实验设备从左到右摆成一排,编号依次为 1 到 n,第 i 个设备价值为 ai。
W 国希望破坏 Y 国的实验设备,所以准备了 m 轮激光炮轰击,第 i 轮激光炮会从第 ri 个设备开始,从右到左依次轰击到第 li 个设备,并把这些设备全部破坏。
Y 国提前知道了 W 国的计划。为了防止损失过多,Y 国准备给至多 k 个设备安装能量吸收保护罩。当激光炮接触到保护罩,那个激光炮就会失效,不再继续轰击,而且被安装了保护罩的设备也不会被破坏(但是在激光炮失效之前已经轰击的设备还是会被破坏)。所以,假如一轮激光炮的轰击范围为 [l,r],并在第 x(x∈[l,r]) 个设备上安装了能量吸收保护罩,那么激光炮的轰击范围就变成了 [x+1,r]。
现在你需要帮 Y 国安排在哪些设备安装保护罩,使得被破坏的设备的价值之和最小。
输入格式
第一行三个整数 n,m,k。
第二行 n 个正整数依次表示 a1,…,n。
接下来 m 行每行两个整数表示 li,ri。
输出格式
输出一个整数,表示被破坏的设备的价值之和最小值。
样例输入
5 3 1
3 2 3 2 1
1 5
2 3
3 3
样例输出
3
考场思路
暴力,但看了一下部分分,不值得,没写。
讲个笑话,全场没人有分((
无代码。
正解
记 Ri=mini∈[lj,rj]{rj},那么 i 可以贡献当且仅当 [i,Ri] 中至少存在一个点被标记。直接暴力 dp 可以做到 O(n2k)。
注意到如果 j∈[i,Ri],那么 Rj≤Ri,所以 [i,Ri] 这些区间之间要么无交,那么互相包含。根据区间关系建树,那么我们每次标记可以保证一条到根的链不被破坏。
在树上 dp 的话,使用树上背包的技巧可以做到 O(nk)。
但是并不需要那么麻烦,我们考虑树长剖,那么其实我们的答案就是前 k 条长链的带权长度和,复杂度 O(n+m)。
代码:
点击查看代码
#include<bits/stdc++.h> #define N 600005 #define int long long using namespace std; int n,m,k,a[N],L[N],R[N],st[N],top,cnt,ans,len[N],c[N],head[N],to[N],nedge,Next[N]; void add(int a,int b){ Next[++nedge]=head[a]; head[a]=nedge; to[nedge]=b; } void dfs(int u){ int son=0; for(int i=head[u];i;i=Next[i]){ dfs(to[i]); if(len[to[i]]>len[son])son=to[i]; } len[u]=len[son]+a[u]; for(int i=head[u];i;i=Next[i])if(son^to[i])c[cnt++]=len[to[i]]; } signed main(){ cin>>n>>m>>k; for(int i=1;i<=n;i++)cin>>a[i],L[i]=i+1,ans+=a[i]; for(int i=1;i<=m;i++){ int u,v; cin>>u>>v; L[v]=min(L[v],u); } for(int i=n;i;i--){ while(top&&L[i]<=L[st[top]])top--; if(L[i]<=i)st[++top]=i; if(top&&L[st[top]]<=i)R[i]=st[top]; else ans-=a[i],R[i]=i-1; } st[top=1]=0,R[0]=n; for(int i=1;i<=n;i++){ while(top&&R[st[top]]<i)top--; if(R[i]>=i)add(st[top],i),st[++top]=i; } dfs(0),c[cnt++]=len[0]; if(cnt>=k)nth_element(c,c+cnt-k,c+cnt); for(int i=max(cnt-k,0ll);i<cnt;i++)ans-=c[i]; cout<<ans; return 0; }
Day 5
DP 专题。
100+50+60+0=210 pts。Rank 18/58。
A 网络行走
题意
有一个 n×m 的矩阵 a,第 i 行第 j 列有价值为 ai,j 的宝石。现在要从 (1,1) 走到 (n,m),每一步只能向下或向右走,到一个点必须捡起这个点上的宝石。走到终点后会随机丢弃 n+m−1 个宝石中的一个宝石,剩下来宝石价值的异或和就是得分。
现在问所有可能情况的得分之和模 998244353 的结果。
数据范围:1≤n,m≤301,0≤ai,j<128。
输入格式
输入第一行两个数 n,m。
接下来 n 行,每行 m 个数表示 ai,j。
输出格式
输出一行一个数表示得分和模 998244353 的结果。
样例输入:
2 2
1 2
0 1
样例输出:
8
考场思路
设 dpi,j,k,0/1 表示从 (1,1) 走到 (i,j),异或和为 k,且没有扔掉/扔掉一个宝石的方案数。
然后每次直接枚举 (i,j,k) 是否向下还是向右走就行。
时间复杂度 O(127nm)。
代码(100 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; typedef long long ll; const int mod = 998244353; int n,m; int a[501][501]; ll dp[301][301][129][3]; main() { cin>>n>>m; int i,j,k; for(i=1;i<=n;i++) for(j=1;j<=m;j++) cin>>a[i][j]; dp[1][1][0][0] = 1; dp[1][1][a[1][1]][1] = 1; for(i=1;i<=n;i++) { for(j=1;j<=m;j++) { for(k=0;k<=127;k++) { if(i==1&&j==1) continue; else { dp[i][j][k][0] = ((dp[i-1][j][a[i][j]^k][0] + dp[i][j-1][a[i][j]^k][0])%mod+ dp[i-1][j][k][1] + dp[i][j-1][k][1])%mod; dp[i][j][k][1] = (dp[i-1][j][a[i][j]^k][1]+ dp[i][j-1][a[i][j]^k][1])%mod; } } } } ll ans = 0; for(int i=0;i<=127;i++) ans += i*dp[n][m][i][0],ans %= mod; cout<<ans<<endl; return 0; }
正解
同思路。
B 树
题意
有一棵 n 个点的树,求有多少序列 a1<a2<⋯<ak(k≥2),且树上从 a1 到 ak 的路径依次经过 a1,a2,…,ak。
答案对 109+7 取模。
输入格式
输入第一行一个整数 n。
接下来 n−1 行,每行两个整数 u,v,表示树上的一条边。
输出格式
输出一行一个整数,表示可能序列的个数模 109+7 的结果。
样例输入:
5
5 3
5 4
3 1
1 2
样例输出:
14
考场思路
写两个 DFS。
代码(50 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long vector<int> g[5001]; const int mod = 1e9+7; void add(int u,int v) { g[u].push_back(v); g[v].push_back(u); } int ans1,ok,a[5001],b[5001],n,cnt,ans[5001]; int nw = 1,vis[5001]; void dfs1(int u,int fa) { vis[u] = 1; if(u==ans[nw]) ++nw; int i; for(i=0;i<g[u].size();i++) if(!vis[g[u][i]]) dfs1(g[u][i],fa); if(nw==fa+1) ok = 1; if(u==ans[nw-1]) nw--; } void dfs(int u,int fa) { if(u==n+1) { if(cnt!=fa) return; ok = 0; memset(vis,0,sizeof(vis)); dfs1(ans[1],fa); if(ok==1) ans1++; ans1 %= mod; return; } ans[++cnt] = u; dfs(u+1,fa); cnt--; dfs(u+1,fa); } main() { cin>>n; int i; for(i=1;i<n;i++) { cin>>a[i]>>b[i]; add(a[i],b[i]); } for(i=2;i<=n;i++) { cnt = 0; dfs(1,i); } cout<<ans1<<endl; return 0; }
正解
考虑将一条合法的路径在 LCA 处计算进答案。可以设 fi,j 表示 i 子树内一条祖先-儿子链,且祖先 >儿子,最后一个点是 j 的方案数,gi,j 则是祖先 < 儿子,最后一个点是 j 的方案数。
当 u 合并一颗子树 v 的时候,答案会增加 ∑a<bfu,a×gv,b+fu,b×gv,a。
时间复杂度 O(n2)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; const int mod = 1e9+7; int n,f[5001][5001],g[5001][5001],ans; vector<int> G[5001]; int add(int x,int y) { return x+y<mod?x+y:x+y-mod; } void dfs(int u,int fa) { f[u][u] = g[u][u] = 1; int k; for(int v:G[u]) { if(v==fa) continue; dfs(v,u); int s1,s2; s1 = s2 = 0; for(k=1;k<=n;k++) { ans = (ans+s1*g[v][k]+s2*g[u][k])%mod; s1 = add(s1,f[u][k]); s2 = add(s2,f[v][k]); } for(k=1;k!=u;k++) f[u][u] = add(f[u][u],f[v][k]); for(k=n;k!=u;k--) g[u][u] = add(g[u][u],g[v][k]); for(k=1;k<=n;k++) { f[u][k] = add(f[u][k],f[v][k]); g[u][k] = add(g[u][k],g[v][k]); } } } int main() { cin>>n; int i; for(i=1;i<n;i++) { int u,v; cin>>u>>v; G[u].push_back(v); G[v].push_back(u); } dfs(1,0); cout<<ans<<endl; return 0; }
C 序列
题意
给定 n,m,求所有长为 n 的序列 a,满足 0≤ai≤m,n∑i=1ai=m 的序列 a 的价值之和,对 109+9 取模的结果。
这里一个序列的价值定义为它所有元素的异或和。
数据范围:2≤n≤103,0≤m≤109。
输入格式
输入一行两个整数 n,m。
输出格式
输出一行一个整数,表示价值和模 109+9 的结果。
样例输入:
2 5
样例输出:
22
考场思路
首先考虑爆搜,而爆搜可以用记忆化优化很大一部分,所以可以通过爆搜+记忆化搜索骗大量的分。
代码(60 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; const int mod = 1e9 + 9; int n, m; int dp[205][205][205]; int dfs(int nw, int sum, int xor_sum) { int i; if (nw == n + 1) { if (sum == m) return xor_sum; return 0; } if (dp[nw][sum][xor_sum] != -1) return dp[nw][sum][xor_sum]; int res = 0; for (i = 0; i <= m; i++) if (sum + i <= m) res = (res + dfs(nw + 1, sum + i, xor_sum ^ i)) % mod; return dp[nw][sum][xor_sum] = res; } int main() { cin >> n >> m; memset(dp, -1, sizeof(dp)); int ans = dfs(1, 0, 0); cout << ans << endl; return 0; }
正解
分别要记 fi,j 表示所有数确定完第 i 位,且第 i 位的和等于 n 的第 i 位的方案数,gi,j 表示所有合法方案中的异或和。
转移的话,fi,j 直接枚举第 i+1 位有几个 1,设为 x,然后只要 x+j 的奇偶性和 n 第 i+1 位一样就行。
gi,j 有两个部分的贡献:一个是低于 i+1 位的贡献,一个是第 i+1 位的贡献。分别算即可。即 gi,j×(nx)+2i+1×fi,j×(nx)。
时间复杂度 O(n2logm)。
其实考试的时候一开始就是用数学写的,但是样例一直不过(可能我太菜了),于是就没交,真的离正解很近了!
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; int n,m,c[1001][1001]; int f[1001],g[1001],tf[1001],tg[1001]; const int mod = 1e9+9; int add(int x,int y) { return x+y<mod?x+y:x+y-mod; } main() { cin>>n>>m; int i,j; for(i=0;i<=n;i++) { c[i][0] = c[i][i] = 1; for(j=1;j<i;j++) c[i][j] = add(c[i-1][j],c[i-1][j-1]); } f[0] = 1; int t; for(t=0;t<=__lg(m);t++) { bool o = m>>t&1; memset(tf,0,sizeof(tf)); memset(tg,0,sizeof(tg)); for(i=0;i<n;i++) { for(j=(i^o)&1;j<=n;j+=2) { int k = (i+j)>>1; tf[k] = (tf[k]+1ll*f[i]*c[n][j])%mod; tg[k] = (tg[k]+1ll*g[i]*c[n][j]+1ll*((j&1)<<t)*f[i]%mod*c[n][j])%mod; } } memcpy(f,tf,n<<2); memcpy(g,tg,n<<2); } cout<<tg[0]<<endl; return 0; }
番外
在赛后,我和 wzk 想把思路中的记忆化代码“优化”一下,从  变成了
变成了 
DFS 中的变化:

变成

(我才不会告诉你我下标搞反了好几次呢)
本来是 MLE 的(如果数组开满肯定会,但我这里只开了 200,所以 RE 了),变成了 TLE 的。

而且分数从 60 掉到了 48,负优化第一人 xDDDDD
D 酒馆
题意
你经营着 n 家酒馆,第 i 家酒馆可以花费 ci,j(0≤j≤k) 元将这家酒馆的档次设置为 j。
有 m 个人,每个人会在区间 [li,ri] 种选择一家档次最高的酒馆消费 j 元(j 是这家酒馆的档次),求合理设置最大每个酒馆的档次,使得收益最大化。
数据范围:2≤n≤300,1≤m≤105,1≤k≤104,1≤li≤ri≤n,1≤ci≤109。
输入格式
输入第一行三个整数 n,m,k。
接下来 n 行,每行 k 个整数,第 i 行第 j 个数表示将酒馆 i 档次设置为 j 的花费,特别地,有 ci,0=0,但不会在输入数据中。
接下来 m 行,第 i 行两个整数 li,ri,表示第 i 个人选择的酒馆区间。
输出格式
输出一行一个整数,表示最大收益。
样例输入
4 5 3
2 4 5
3 4 5
2 2 4
1 2 3
3 3
2 2
2 3
2 4
1 2
样例输出
7
考场思路
没时间了。
一眼看上去像是贪心,但没有往深处想。
无代码。
正解
其实也差不多是贪心。
首先,假设当我们已经选好了每个点的标准,那么每个人就一定会贪心地去他所能到达的店中标准最高的。
可以枚举这个区间的最大值是什么,即设 fi,j 表示只考虑区间 [i,j] 里的人的最大收益是什么,然后枚举标准最高的点 k,设能到达 k 的人有 t 个,那么就是 fi,k−1+fj,k+1+gk,t,其中 gk,t 表示有 t 个人到第 k 家店,合理选择标准能达到的最高收益是什么。
那么接下来就是求出所有 gk,t。由于每个人都求这个(过程一样),于是下面用 ci 代表标准为 i 的花费,fj 表示有 j 个人来,那么最高收益是什么。
显然 fj=maxi×j−ci。这个是一个标准的斜率优化式子,建出凸包来即可。
但是斜率优化是有限制的,比如这些都是能放在平面直角坐标系上面的直线(也就是说贡献都可以写成 kx+b)的形式。
下面给一种感觉通用性更高,且理解起来并不比斜率优化复杂的决策单调性优化方法(虽然写起来其实本质相同)。
对于一个 j,假设 i1<i2,且这个时候选 i2 比 i1 更加优秀,那么对于所有 k>j,i2 都会比 i1 优秀,那么 i1 在这之后就没有用了。
那么我们按 i 从小到大的顺序加入 i×j−ci 这条直线。假设已经处理完了之前的所有直线,那么对于所有可能成为最优选择的 i1<i2<⋯ik,一定有 ix 是 ix−1 后面一些点的最优解。
我们对每个 ix 记录 px 表示对于 j<px,ix 比 ix+1 优,之后则是 ix+1 优,那么显然 p1<p2<⋯pk−1。
否则若 px>px+1,那么在 ix+1 比 ix 优之前,ix+2 就已经比 ix+1 优了,所以 ix+1 就不可能成为最优选择了。
那么加入 i 的时候,先算出来 i 比 ik 什么时候优(因为 i>ik,所以一定有个时间更优),设为 y,那么如果 xk−1>y,那么根据上面 px 单调的解释,就需要删除 ik,那么这样做就能维护出对于所有 j,什么 i 最优。
做完这个之后直接枚举 j,然后双指针不断从前往后扫到最后一个 px<j 的 x,ix+1 就是最优的答案。
这样的时间复杂度是线性。于是,整个题时间复杂度 O(n3+nk)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n,m,k; int st[100005],c[100005],p[100005],top; int s[305][305]; int v[305][100005],f[305][305]; main() { cin>>n>>m>>k; int t; int i,j; for(t=1;t<=n;t++) { top = 0; st[1] = 0,c[1] = 0; for(i=1;i<=k;i++) { int tp; cin>>tp; while(top&&tp<=c[top]) top--; while(top>1&&p[top-1]>=(tp-c[top]-1)/(i-st[top])+1) top--; top++; st[top] = i; c[top] = tp; if(top>1) p[top-1] = (tp-c[top-1]-1)/(i-st[top-1])+1; } j = 1; for(i=1;i<=m;i++) { while(j!=top&&p[j]<=i) j++; v[t][i] = i*st[j]-c[j]; } } while(m--) { int l,r; cin>>l>>r; s[l][r]++; } for(i=n;i;i--) for(j=1;j<=n;j++) s[i][j] += s[i+1][j]; for(i=1;i<=n;i++) for(j=1;j<=n;j++) s[i][j] += s[i][j-1]; for(i=n;i;i--) for(j=i;j<=n;j++) for(k=i;k<=j;k++) f[i][j] = max(f[i][j],f[i][k-1]+f[k+1][j]+v[k][s[i][j]-s[i][k-1]-s[k+1][j]]); cout<<f[1][n]<<endl; return 0; }
Day 6
数学场。
100+70+0+25=195 pts。Rank 34/58。
本应该 100+100+70+25=295 的,但是不是这错就是那错,痛失 Rank 15-。
其实有 6 个 AK 的。
讲个笑话:今天是打表专题,因为 C 和 D 两题如果打表恰当,能取得 70+70 分的好成绩!
A 危机
题意
现在有 m 个质数是危险的。如果对于某个数 x,它包含了这 m 个质数中的任何一个作为约数,那么就称 x 也是危险的。现在给定 n 和 m 个质数 p1,p2,⋯,pm,问 [1,n] 中有多少数是危险的。
数据范围:1≤n≤2×107,1≤m≤105,1≤pi≤n。
输入格式
第一行输入两个整数 n,m。
第二行输入 m 个质数 pi,保证 pi 两两不同。
输出格式
输出一行一个整数,表示有多少个在 [1,n] 中的整数是危险的。
样例输入:
20 4
7 3 2 19
样例输出:
15
考场思路
看完题就有了思路,要不是写完了谨慎一下,测了大样例,不然可以冲一下一血。
思路类似埃式筛。
枚举每一个 pi 的倍数,一直到 n,他们一定是危险的。
那就开一个 vis 数组,把所有 pi 的倍数都设为 1,最后统计为 1 的数量即可。
代码(100 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; bitset<200000001> v; int n,m; void go(int x) { int i; for(i=x;i<=n;i+=x) v[i] = 1; } int cnt; int main() { cin>>n>>m; int i; for(i=1;i<=m;i++) { int p; cin>>p; go(p); } for(i=1;i<=n;i++) { if(v[i]) cnt++; } cout<<cnt<<endl; return 0; }
这里普及一下 bitset 的基本用法。
定义一个 bitset<length> a,其中 length 是 a 的长度,它完全等同于 bool a[length]。而 bitset 比 bool 快得多,空间消耗是 bool 的 18。
正解
同思路。
B 质树
题意
有一棵 n 个点的树,对于 i>1,i 和 if(i) 间有一条边相连,其中 f(i) 表示 i 的最大质因子。
现在有 q 次询问,每次询问给定 x,y,问树上 x 到 y 的路径长度(即要经过多少条边)。
数据范围:1≤x,y≤n≤107,1≤q≤2×105。
输入格式
输入第一行两个整数 n,q。
接下来 q 行,每行两个整数 x,y,表示询问 x 到 y 的路径长度。
输出格式
输出 q 行,每行一个整数,表示路径长度。
样例输入:
6 5
1 4
2 5
3 6
2 4
2 6
样例输出:
2
2
3
1
1
考场思路
先预处理出最大质因子,然后暴力模拟即可。
代码(70 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long #define endl "\n" int n,q; bitset<20000001> isprime; int prime[20000001]; void init1() { isprime[0] = isprime[1] = 1; int i,j; for(i=2;i*i<=n;i++) { if(!isprime[i]) { for(j=i*i;j<=n;j+=i) isprime[j] = 1; } } } void init2() { int i,j; for(i=2;i<=n;i++) { if(!isprime[i]) { for(j=i;j<=n;j+=i) prime[j] = i; } } } int find(int x,int y) { int len = 0; while(x!=y) { if(x>y) x /= prime[x]; else y /= prime[y]; len++; } return len; } main() { // freopen("ex.in","r",stdin); // freopen("oo.out","w",stdout); cin>>n>>q; init1(); init2(); while(q--) { int x,y; cin>>x>>y; int len = find(x,y); cout<<len<<endl; } return 0; }
每日花絮!!!
其实此代码有 3 个分数可以拿——50、70 和 100。
注意到 q 比较大,于是输入上会耗时。
当输出用 endl:50 分。考试的时候我一开始就交的输出带有 endl 的代码,但有了前车之鉴后,在 1min 后意识到出错,马上就 #define endl '\n'。
当用 '\n' 时,就可以拿到 70 分的好成绩。
但仔细观察代码,就会发现我 #define int long long 了!但是题中并没有说答案大,需要取模,所以 long long 完全不用开。档把这一行删掉后,就 100 了?!其实 long long 的空间是 int 的两倍,速度当然也会慢了。
当换成 scanf 和 printf 后,速度直接降了好多!!
这告诉我们,不要随意 #define int long long,也不要偷懒用 cin、cout 和 endl,scanf 和 printf 才是王道!printf 好闪,拜谢 printf。
图片区:
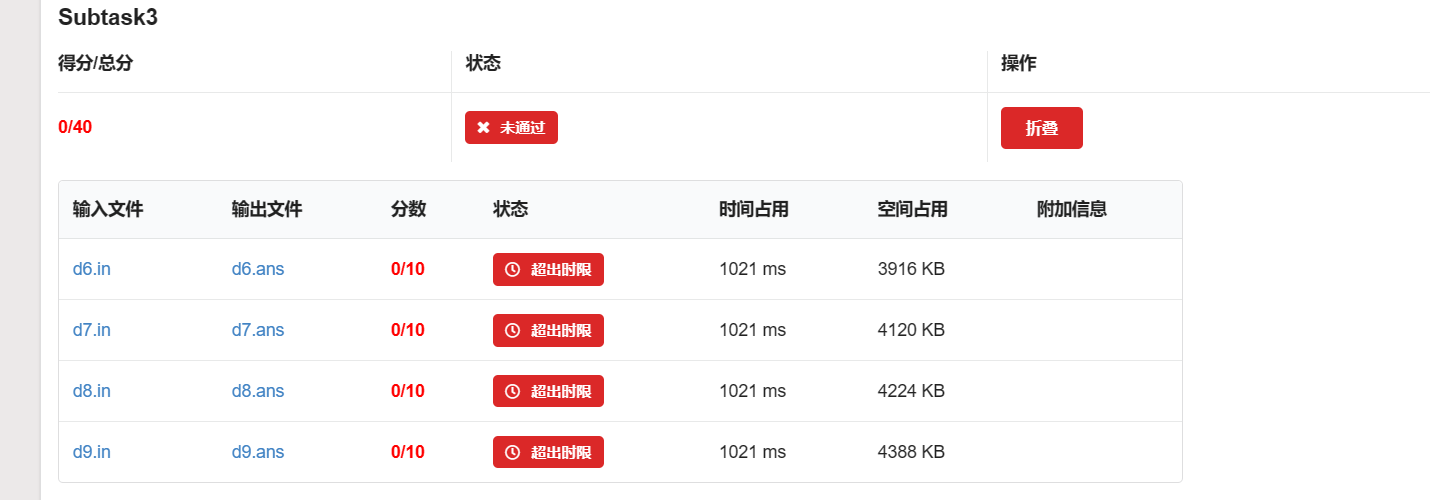
Subtask 3 时限均为 1500ms。
用 endl: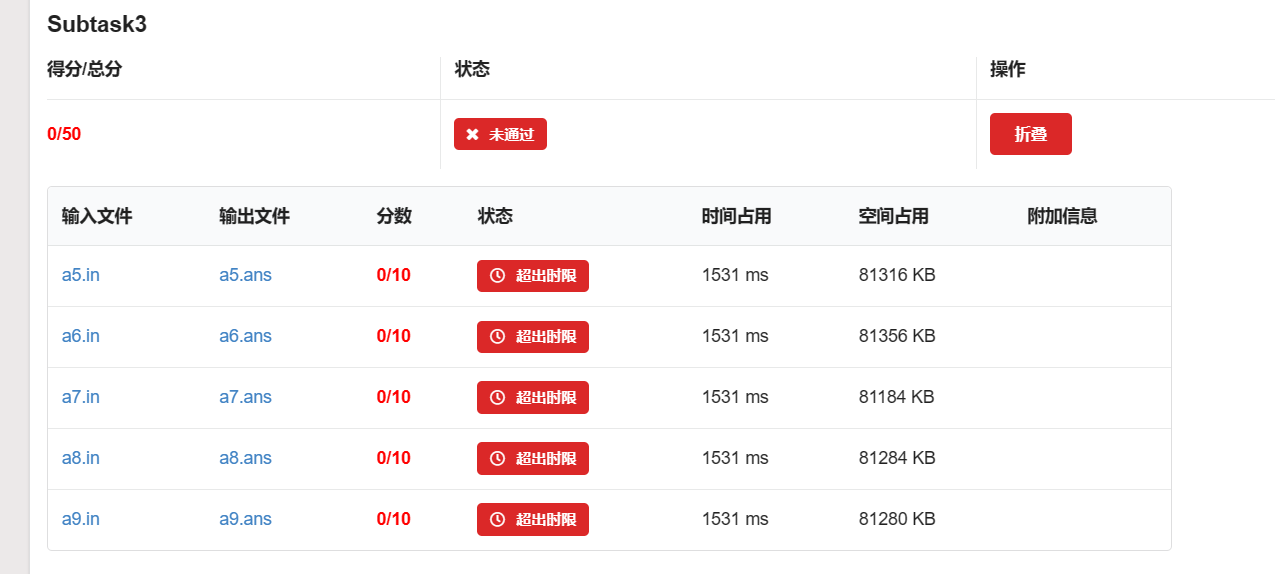
#define endl '\n':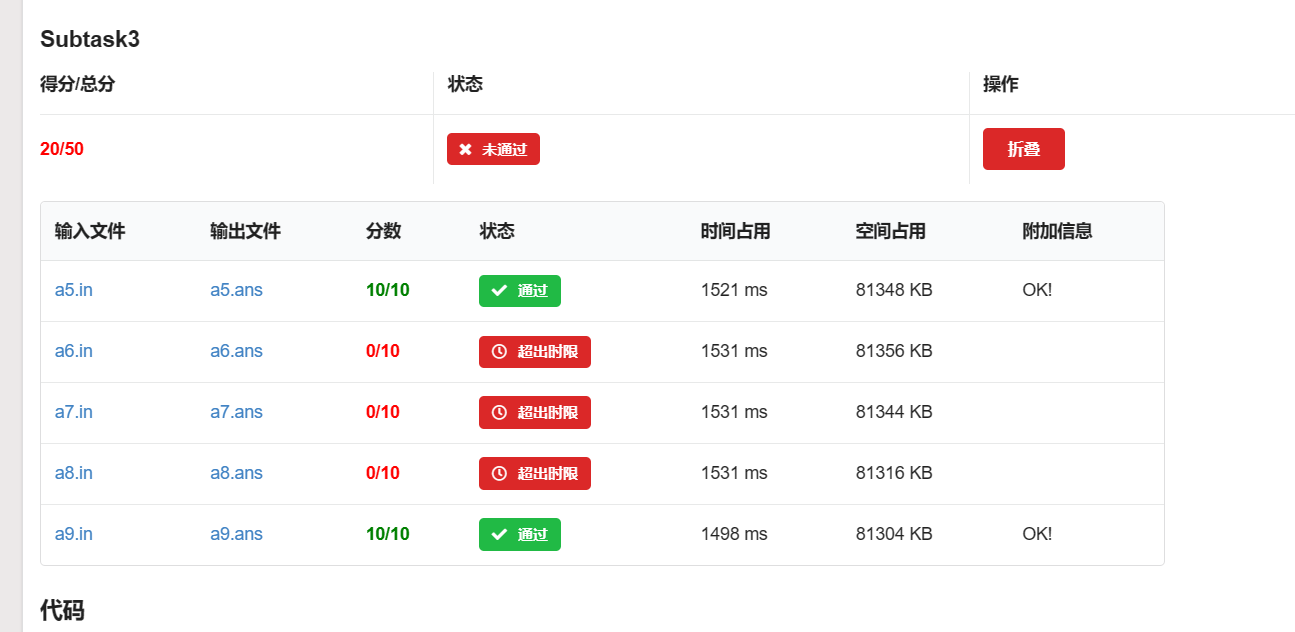
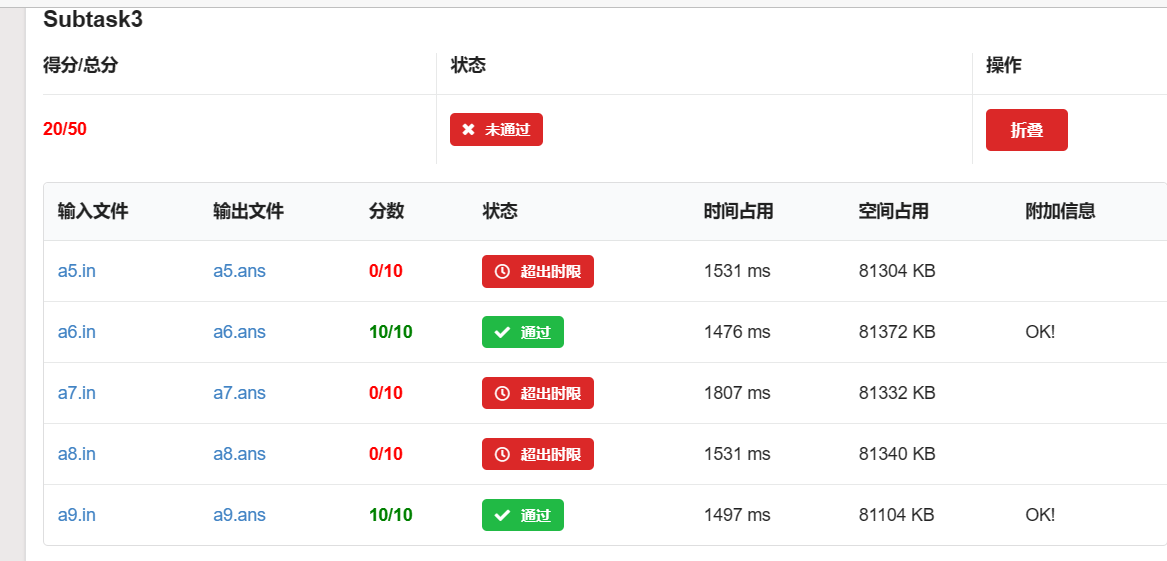
注意观察时间。随着提交次数的增多,此 Subtask 正确的点数也不同,玄学啊!
删掉 #define int long long 后: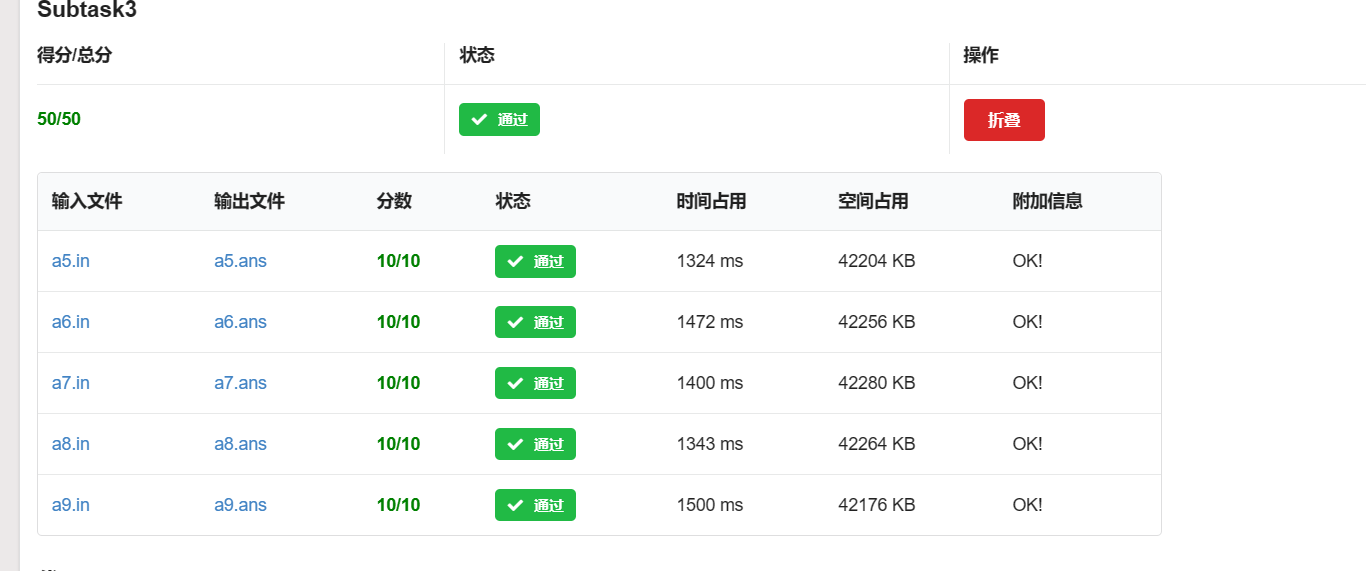
用 scanf 和 printf: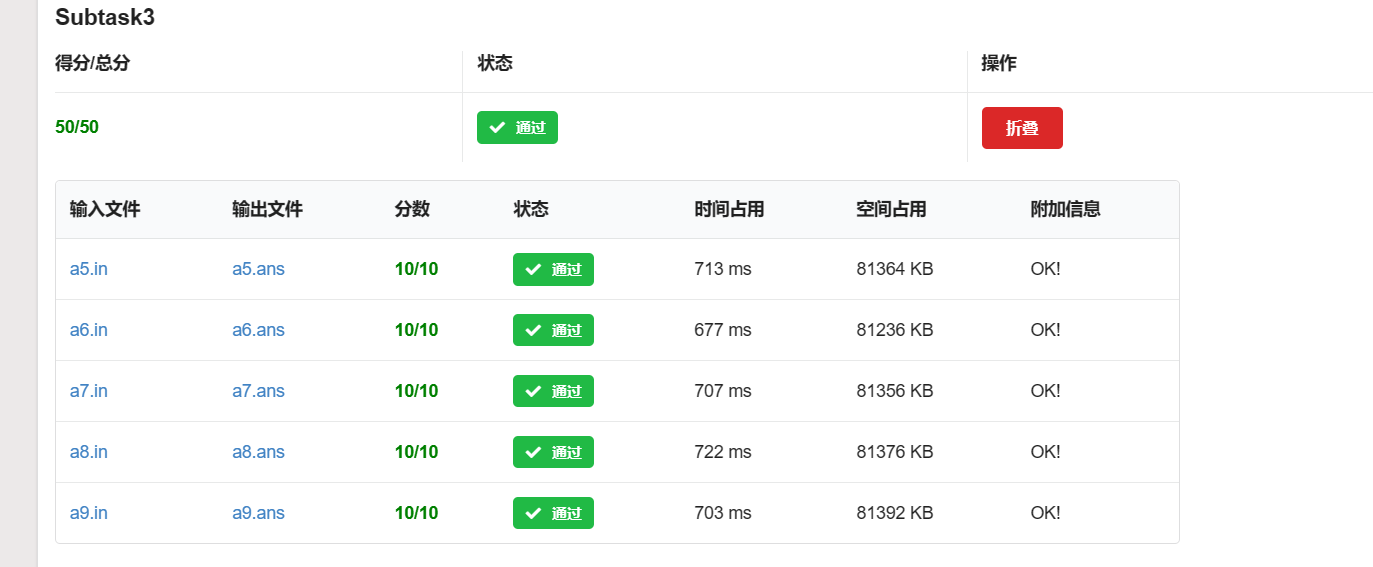
正解
其实思路已经是正解了。
给出另一种思路:
直接对每个点它的父亲,由于每个数质因子总数 ≤logn,所以每次询问可以暴力跳 LCA。
时间复杂度 O(n+qlogn)。
这里就不给代码了。
C 整除
题意
对于 y,定义 f(y) 表示有多少 x 满足 1≤x<y,且 y−x 是 y+x 的约数。
现在给定 n,求 n∑y=2f(y)。
数据范围:2≤n≤107。
输入格式
输入一行一个整数 n。
输出格式
输出一行一个整数,表示 n∑y=2f(y)。
样例输入
1000
样例输出
8948
考场思路
纯暴力。
但是输出 1 到 20 的答案后,感觉有些规律,就用oeis.org找了找规律,找到了,但看不懂通项公式。。。
在比赛最后 10min 后考虑打表,但是从 1 到 105 太长了,就从 5000 达到 10000。
大的要来力!
快速把暴力改成打表机,跑的还挺快!如果直接输出答案,n∑y=2f(y) 的话,太慢了。于是我的表就存的是 f(y)。
但是下标统计错了!普遍比答案大一些。但我测得只是样例和 5000、5001 之类的小数据,大的没看,后果可想而知。
最后 25 秒交代码了,然后零蛋。
本来还有 30 分的暴力(哭)
放一下暴力代码吧(30 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long int n; int ans; main() { cin>>n; int x,y; for(y=2;y<=n;y++) { int cnt = 0; for(x=1;x<y;x++) { if((x+y)%(x-y)==0) cnt++; } ans += cnt; } cout<<ans<<endl; return 0; }
其实如果打表打的好一点,能拿 70。
但需要求出所有的 n∑y=2f(y)。有个老哥就这么干的,喜提 70 pts。
正解
首先考虑另外一个问题:有多少对 (x,y) 满足 1≤x≤y≤n 且 y 是 x 的倍数?
可以枚举 x,那么 n 以内 x 的倍数就是 ⌊nx⌋,所以答案就是 n∑x=1⌊nx⌋。
回到原问题:设 a=y−x,b=y+x,那么 x=b−a2,y=b+a2。由于 y≤n,所以 a+b≤2n,且 a<b,a,b 奇偶性要相同。
所以枚举 a,如果 a 是偶数,那么 b≤2n−a 且 b 是 a 的倍数的话,b 也一定是偶数。b 的个数就是 ⌊2n−aa⌋−1,减一是因为 b 不能等于 a。
若 a 是奇数,那么刚刚那样算出来的 b 就有可能是偶数,即 b 是 2a 的倍数,那么减去 ⌊n−a2a⌋ 就行。
时间复杂度 O(n)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; int n,ans; int main() { cin>>n; int i; for(i=1;i<n;i++) { ans += (2*n-i)/i-1; if(i&1) ans -= (2*n-i)/(2*i); } cout<<ans<<endl; return 0; }
D 序列计数
题意
给定 n,k,现在对于每个 1≤i≤n 的 i,求有多少长为 k 的序列 b1,b2,⋯,bk 满足 bj≥1 且这个序列所有元素的最小公倍数是 i,对 998244353 取模。
数据范围:1≤n≤106,1≤k<998244353。
输入格式
输入第一行两个整数 n,k。
输出格式
输出一行 n 个整数,第 i 个整数表示长为 k,最小公倍数为 i 的序列的个数模 998244353 的结果。
样例输入:
6 3
样例输出:
1 7 7 19 7 49
考场思路
枚举所有可能的序列,十分暴力。
老样子,考虑打表。
注意到有一个 Subtask 的数据规模都很小,1≤n,k≤8。所以可以处理出所有 1≤n,k≤8 的情况,答案用 vector 存起来,一共 64 种答案。
先给出暴力代码(20 分):
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long const int mod = 998244353; int gcd(int a,int b) { return b?gcd(b,a%b):a; } int lcm(int a,int b) { return a/gcd(a,b)*b%mod; } int n,k; int a[1000001]; int ans[1000001]; main() { cin>>n>>k; int i,j; for(i=1;i<=n;i++) { int cnt = 0; fill(a+1,a+1+k,1); while(1) { int nw_lcm = 1; for(j=0;j<k;j++) nw_lcm = lcm(nw_lcm,a[j]); if(nw_lcm==i) cnt++; int pos = k-1; while(pos>=0&&a[pos]==i) { a[pos] = 1; pos--; } if(pos<0) break; a[pos]++; } ans[i] = cnt; } for(i=1;i<=n;i++) cout<<ans[i]<<' '; cout<<endl; return 0; }
发现当 n,k 都为 8 时跑了 3s 左右,所以可打表(特判也行)解决。
打表代码(25 分):
点击查看代码
//打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds //打表 yyds #include<bits/stdc++.h> using namespace std; vector<int> ans[11][11]; int main() { ans[1][1]={1}; ans[1][2]={1}; ans[1][3]={1}; ans[1][4]={1}; ans[1][5]={1}; ans[1][6]={1}; ans[1][7]={1}; ans[1][8]={1}; ans[2][1]={1,1}; ans[2][2]={1,3}; ans[2][3]={1,7}; ans[2][4]={1,15}; ans[2][5]={1,31}; ans[2][6]={1,63}; ans[2][7]={1,127}; ans[2][8]={1,255}; ans[3][1]={1,1,1}; ans[3][2]={1,3,3}; ans[3][3]={1,7,7}; ans[3][4]={1,15,15}; ans[3][5]={1,31,31}; ans[3][6]={1,63,63}; ans[3][7]={1,127,127}; ans[3][8]={1,255,255}; ans[4][1]={1,1,1,1}; ans[4][2]={1,3,3,5}; ans[4][3]={1,7,7,19}; ans[4][4]={1,15,15,65}; ans[4][5]={1,31,31,211}; ans[4][6]={1,63,63,665}; ans[4][7]={1,127,127,2059}; ans[4][8]={1,255,255,6305}; ans[5][1]={1,1,1,1,1}; ans[5][2]={1,3,3,5,3}; ans[5][3]={1,7,7,19,7}; ans[5][4]={1,15,15,65,15}; ans[5][5]={1,31,31,211,31}; ans[5][6]={1,63,63,665,63}; ans[5][7]={1,127,127,2059,127}; ans[5][8]={1,255,255,6305,255}; ans[6][1]={1,1,1,1,1,1}; ans[6][2]={1,3,3,5,3,9}; ans[6][3]={1,7,7,19,7,49}; ans[6][4]={1,15,15,65,15,225}; ans[6][5]={1,31,31,211,31,961}; ans[6][6]={1,63,63,665,63,3969}; ans[6][7]={1,127,127,2059,127,16129}; ans[6][8]={1,255,255,6305,255,65025}; ans[7][1]={1,1,1,1,1,1,1}; ans[7][2]={1,3,3,5,3,9,3}; ans[7][3]={1,7,7,19,7,49,7}; ans[7][4]={1,15,15,65,15,225,15}; ans[7][5]={1,31,31,211,31,961,31}; ans[7][6]={1,63,63,665,63,3969,63}; ans[7][7]={1,127,127,2059,127,16129,127}; ans[7][8]={1,255,255,6305,255,65025,255}; ans[8][1]={1,1,1,1,1,1,1,1}; ans[8][2]={1,3,3,5,3,9,3,7}; ans[8][3]={1,7,7,19,7,49,7,37}; ans[8][4]={1,15,15,65,15,225,15,175}; ans[8][5]={1,31,31,211,31,961,31,781}; ans[8][6]={1,63,63,665,63,3969,63,3367}; ans[8][7]={1,127,127,2059,127,16129,127,14197}; ans[8][8]={1,255,255,6305,255,65025,255,58975}; int n,m; cin>>n>>m; for(auto i:ans[n][m]) cout<<i<<' '; cout<<endl; return 0; }
比暴力多了 5 分。/cf/cf/cf
正解
首先,如果一个长为 k 的序列的最小公倍数是 i,那么这个序列的所有元素都是 i 的约数。设 i 的约数有 d(i) 个。
填 k 个 i 的约数的方案是 gi=d(i)k。但如果要求最小公倍数是 i,则这样任意填可能导致最小公倍数不是 i,如:i=4,k=3,填的序列是 (1,2,1),那么最小公倍数是 2,而不是 4。
设最小公倍数是 i 的序列个数是 fi,那么可以先求出 gi(任意填 i 的约数),再减去最终最小公倍数不是 i 的方案数,那么最小公倍数不是 i,就一定是 i 的某一个约数 j,且最小公倍数是 j 的数组所有元素一定是 i 的约数,也就是它一定会在 gi 中被算进去。
所以 fi=gi−∑j|i,j≠ifj。
这样暴力递推的复杂度是 O(nlogn) 的,总时间复杂度 O(nlogn+nlogk)。
代码:
点击查看代码
#include<bits/stdc++.h> using namespace std; #define int long long const int mod = 998244353; int n,k,f[1000001]; int jian(int x,int y) { return x<y?x+mod-y:x-y; } int ksm(int a,int b) { int ans = 1; while(b) { if(b&1) ans = 1ll*ans*a%mod; a = 1ll*a*a%mod; b>>=1; } return ans; } main() { cin>>n>>k; int i,j; for(i=1;i<=n;i++) for(j=i;j<=n;j+=i) f[j]++; for(i=1;i<=n;i++) f[i] = ksm(f[i],k); for(i=1;i<=n;i++) for(j=i+i;j<=n;j+=i) f[j] = jian(f[j],f[i]); for(i=1;i<=n;i++) cout<<f[i]<<' '; return 0; }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】