Elasticsearch基本概念
-
Elasticsearch自顶向下的架构体系
-
文档,索引
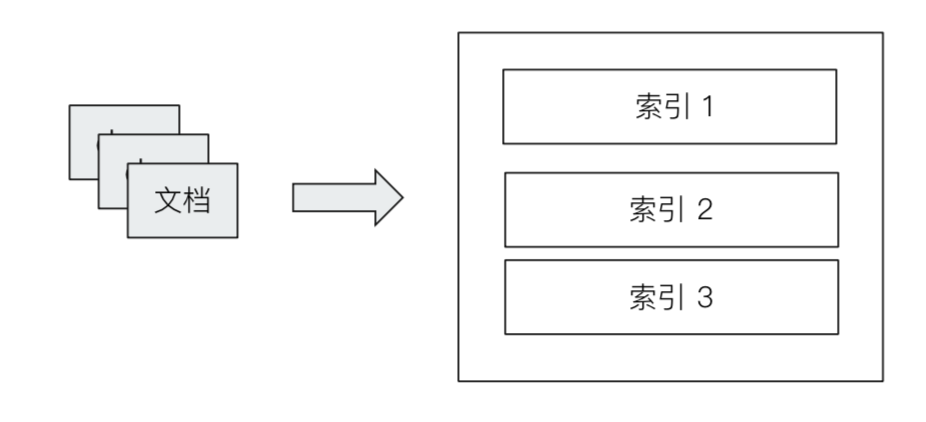
文档(Document)
-
- Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
- 文档会被序列化成JSON格式,保持在Elasticsearch中
- 每一个文档都有一个UniqueID
文档的元数据
-
- 元数据,用于标注稳定的相关信息
- _index -文档所属的索引名
- _type -文档所属的类型名
- _source-文档的原始Json数据
- _version-文档的版本信息
- _score-相关性打分
索引(Index)
Index- 索引是文档的容器,是一类文档的结合
-
- Index体现了逻辑空间的概念:每一个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型
- Shard体现了物理空间的概念:索引中的数据分散在Shard上
索引的Mapping与Settings
-
- Mapping定义文档字段的类型
- Setting定义不同的数据分布
Type
-
- 在7.0之前,一个index可以设置多个Types
- 6.0开始,Type已经被Deprecated。7.0开始一个索引只能创建一个Type -"_doc"
-
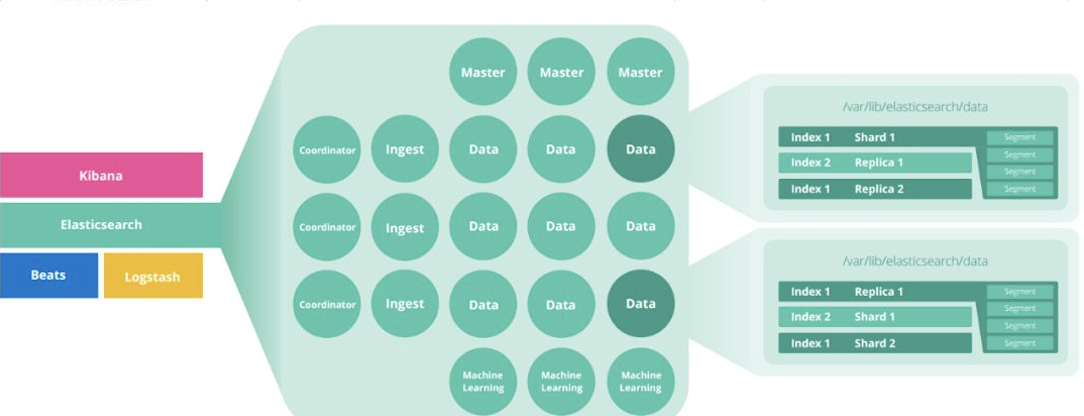
集群/节点/分片/副本
- 分布式系统的可用性与扩展性
- 高可用
- 服务可用性-允许有节点停止服务
- 数据可用性-部分节点丢失,不会丢失数据
- 可扩展性
- 存储的水平扩容 请求量提升/数据的不断增长(将数据分布到所用节点上)
- 高可用
- 集群
- 多台Es服务器的结合的统称叫ES集群
- 集群的健康状态
- Green-主分片与副本都正常分配
- Yellow-主分片全部正常分配,有副本分片未能正常分配
- Red-有主分片未能分配(例如 当服务器的磁盘容量超过85%时,去创建了一个新的索引)
- 节点
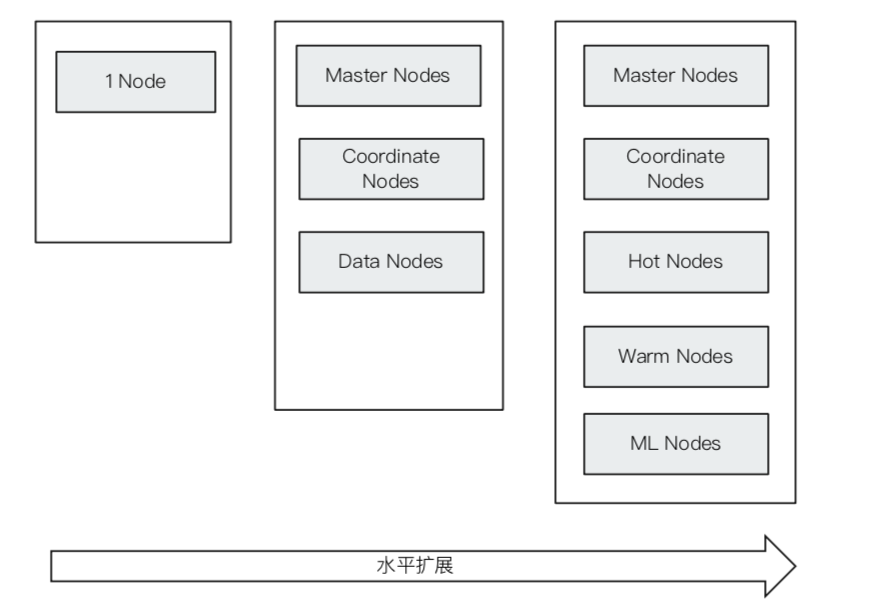
- 节点是一个Elasticsearch的实例,本质上就是一个JAVA进程
- 每一个节点都有名字,通过配置文件配置,或者启动时候指定
- 每一个节点在启动之后,会分配一个UID,保存在data目录下
- Master-eligible nodes 和Master Node(主节点)
- 每个节点启动后,默认就是一个Master eligible节点(可以设置node.master:false禁止)
- Master-eligible节点可以参加选主流出,成为Master节点
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息
- 集群状态(cluster state)维护了一个集群中必要的信息所有节点的信息/所有的索引和其相关的Mapping与Setting信息/分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性
- DataNode(数据节点)
-
可以保存数据的节点。负责保存分片数据。在数据扩展上起到了至关重要的作用
-
- Coordination Node(协调节点)
-
负责接收Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordination Node的职责
-
- Hot&Warm Node
-
不同硬件配置的Data Node,用来实现Hot&Warm架构,降低集群部署的成本
-
- Machine Learning Node
- 负责跑机器学习的Job,用来做异常检测
- Ingest Node
-
Ingest Node 可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用。
-
- Tribe Node
-
5.3开始使用Cross Cluster Search)TribeNode 连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理
-
节点角色划分及资源使用情况
|
角色
|
描述
|
存储
|
内存
|
计算
|
网络
|
|
数据节点
|
存储和检索数据
|
极高
|
高
|
高
|
中
|
|
主节点
|
管理集群状态
|
低
|
低
|
低
|
低
|
|
Ingest 节点
|
转换输入数据
|
低
|
中
|
高
|
中
|
|
机器学习节点
|
机器学习
|
低
|
极高
|
极高
|
中
|
|
协调节点
|
请求转发和合并检索结果
|
低
|
中
|
中
|
中
|
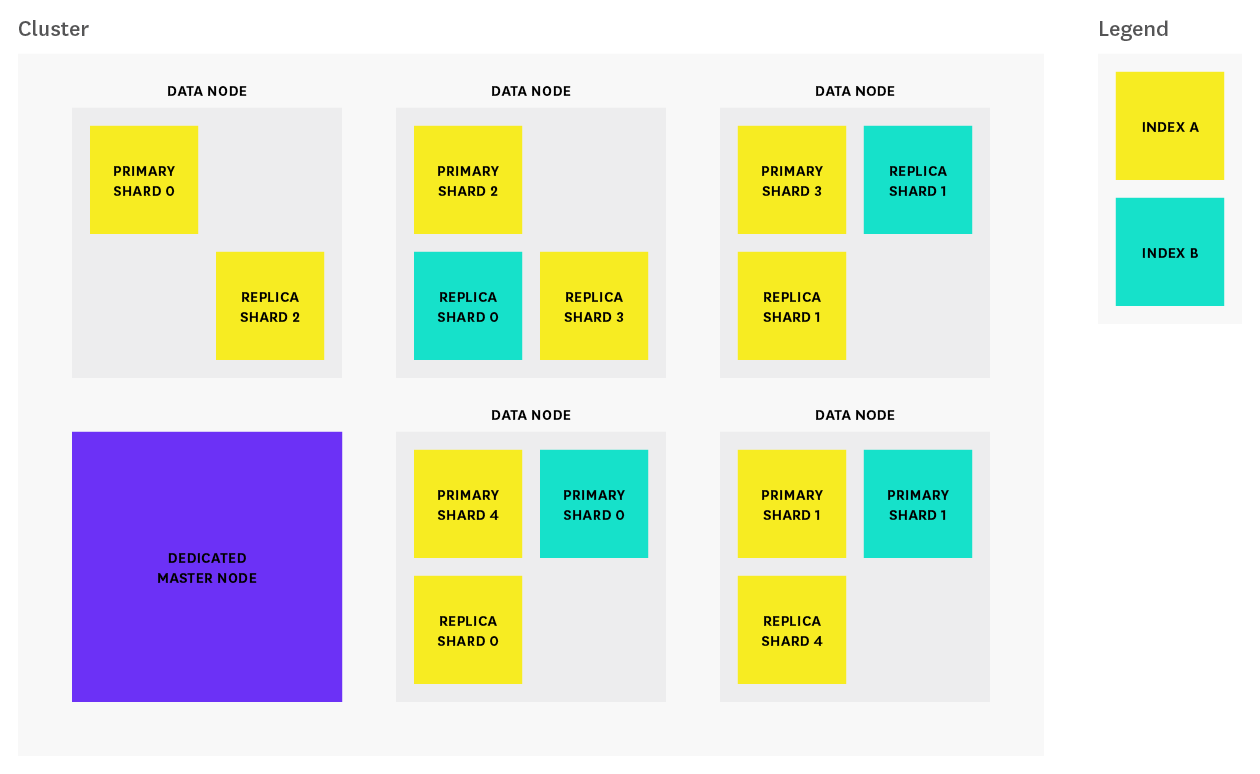
- 分片(Primary Shard & Replica Shard)
-
- 将数据切分放在每个分片中,分片又被放到集群中的节点上。
- 每个分片都是独立的lucene实例
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大
- 影响搜索结构的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
- 分片为主分片和备份分片
- 副本分片数提高了数据冗余量
- 主分片挂掉以后能够自动由副本分片升为主分片
- 备份分片还能够降低主分片的查询压力(会消耗更多的系统性能)
-
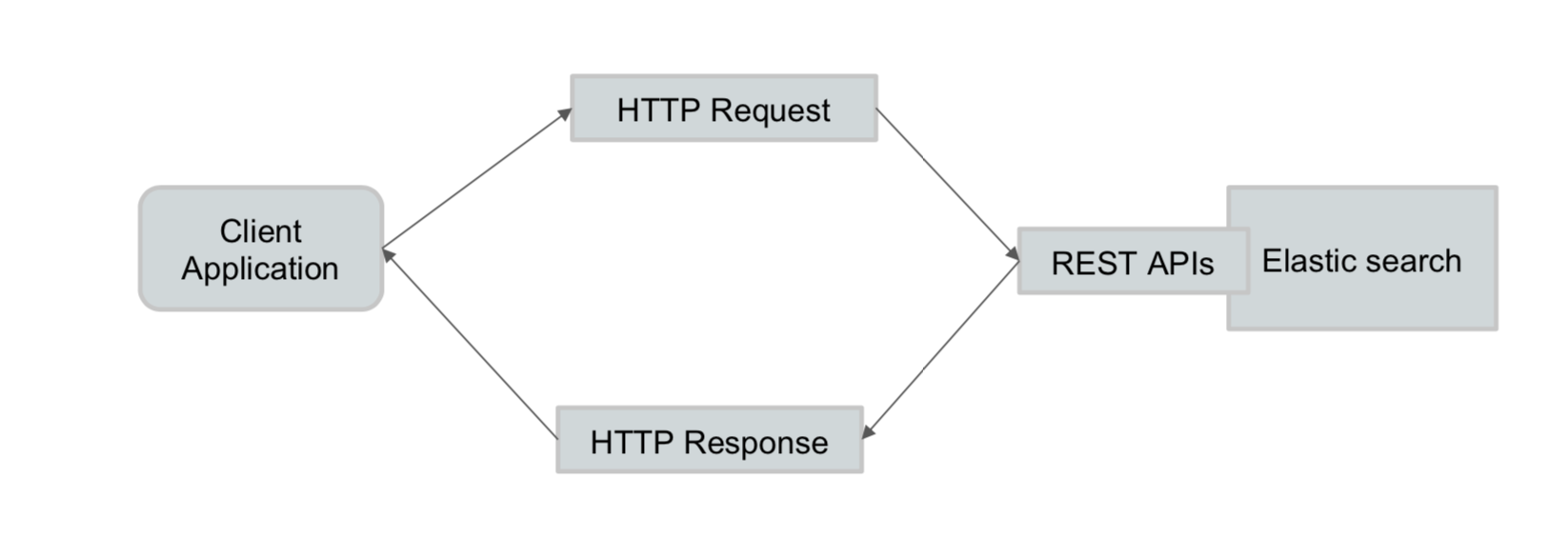
REST API
Elasticsearch提供了一个非常全面和强大的REST API,使用它与集群进行交互
- 检查群集,节点和索引运行状况,状态和统计信息
- 管理您的群集,节点和索引数据和元数据
- 对索引执行CRUD(创建,读取,更新和删除)和搜索操作
- 执行高级搜索操作,例如分页,排序,过滤,脚本编写,聚合等