
01-分布式事务概念与解决思路
一、分布式事务概念与解决思路
1.1、本地事务与分布式事务
1.1.1、本地事务
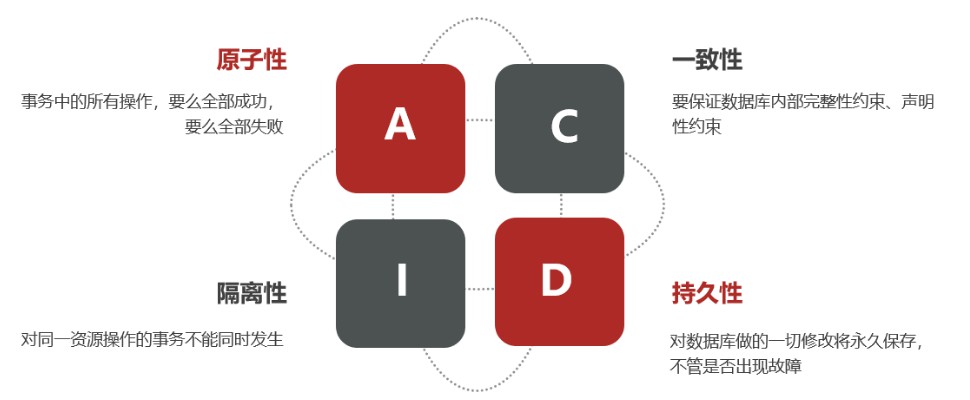
- 不管是本地事务还是分布式事务,都必须满足以下四个原则
- JDBC事务控制
Connection.setAutoCommit(false):取消事务自动提交Connection.commit():提交事务Connection.rollback:回滚事务
- Spring的声明式事务
@Transtional
1.1.2、分布式事务
- 分布式事务,就是指不是在单个服务或者单个数据库架构下,产生的事务,例如:
- ①、在一个业务方法中跨数据源的分布式事务
- ②、在一个业务方法中跨服务的分布式事务
- ...
- 一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为
- ①、创建新订单
- ②、扣减商品库存
- ③、从用户账户余额扣除金额
- 完成上面的操作需要访问三个不同的微服务和三个不同的数据库,如下所示
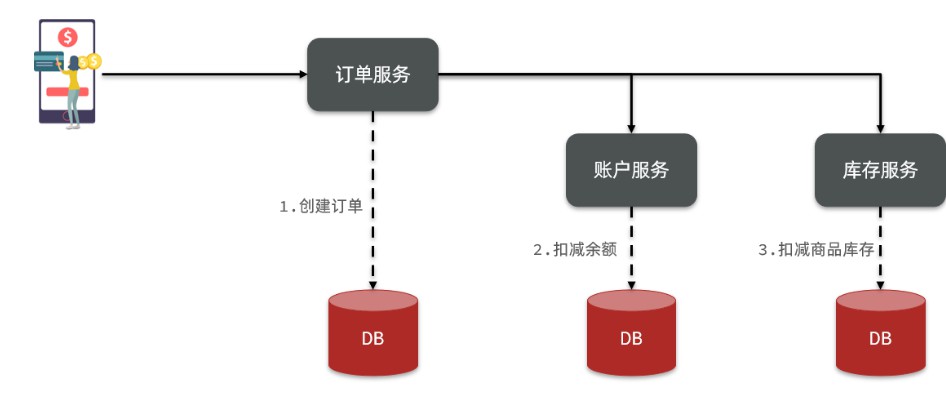
- 订单的创建、库存的扣除、账户扣款在每一个服务和数据内是一个本地事务,可以保证ACID原则
- 但是当我们把三件事情看作一个"业务",要满足保证"业务"的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务
- 此时ACID难以满足,分布式事务的解决方案即是解决该问题
1.2、分布式事务问题的演示
通过一个案例来演示分布式事务的问题
①、创建一个数据库seata_demo,导入数据
-
/* Navicat Premium Data Transfer Source Server : local Source Server Type : MySQL Source Server Version : 50622 Source Host : localhost:3306 Source Schema : seata_demo Target Server Type : MySQL Target Server Version : 50622 File Encoding : 65001 Date: 24/06/2021 19:55:35 */ SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for account_tbl -- ---------------------------- DROP TABLE IF EXISTS `account_tbl`; CREATE TABLE `account_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `money` int(11) UNSIGNED NULL DEFAULT 0, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT; -- ---------------------------- -- Records of account_tbl -- ---------------------------- INSERT INTO `account_tbl` VALUES (1, 'user202103032042012', 1000); -- ---------------------------- -- Table structure for order_tbl -- ---------------------------- DROP TABLE IF EXISTS `order_tbl`; CREATE TABLE `order_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `commodity_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `count` int(11) NULL DEFAULT 0, `money` int(11) NULL DEFAULT 0, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT; -- ---------------------------- -- Records of order_tbl -- ---------------------------- -- ---------------------------- -- Table structure for storage_tbl -- ---------------------------- DROP TABLE IF EXISTS `storage_tbl`; CREATE TABLE `storage_tbl` ( `id` int(11) NOT NULL AUTO_INCREMENT, `commodity_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `count` int(11) UNSIGNED NULL DEFAULT 0, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `commodity_code`(`commodity_code`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT; -- ---------------------------- -- Records of storage_tbl -- ---------------------------- INSERT INTO `storage_tbl` VALUES (1, '100202003032041', 10); SET FOREIGN_KEY_CHECKS = 1; -
account_tbl表

- 记录某个用户的账户余额
-
order_tbl表

- 记录订单,关联账单表和库存表
-
storage_tbl表
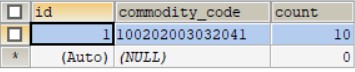
- 库存表,记录某个商品的库存数量
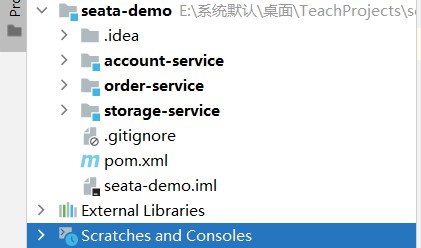
②、创建微服务工程
有需要可联系本人
- 如下图所示
- seata-demo:父工程,负责管理项目依赖
- account-service:账户服务,负责管理用户的资金账户。提供扣减余额的接口
- storage-service:库存服务,负责管理商品库存。提供扣减库存的接口
- order-service:订单服务,负责管理订单。创建订单的时候,需要调用account-service和storage-service服务
③、启动nacos、所有微服务
- 启动Nacos
- 启动所有微服务
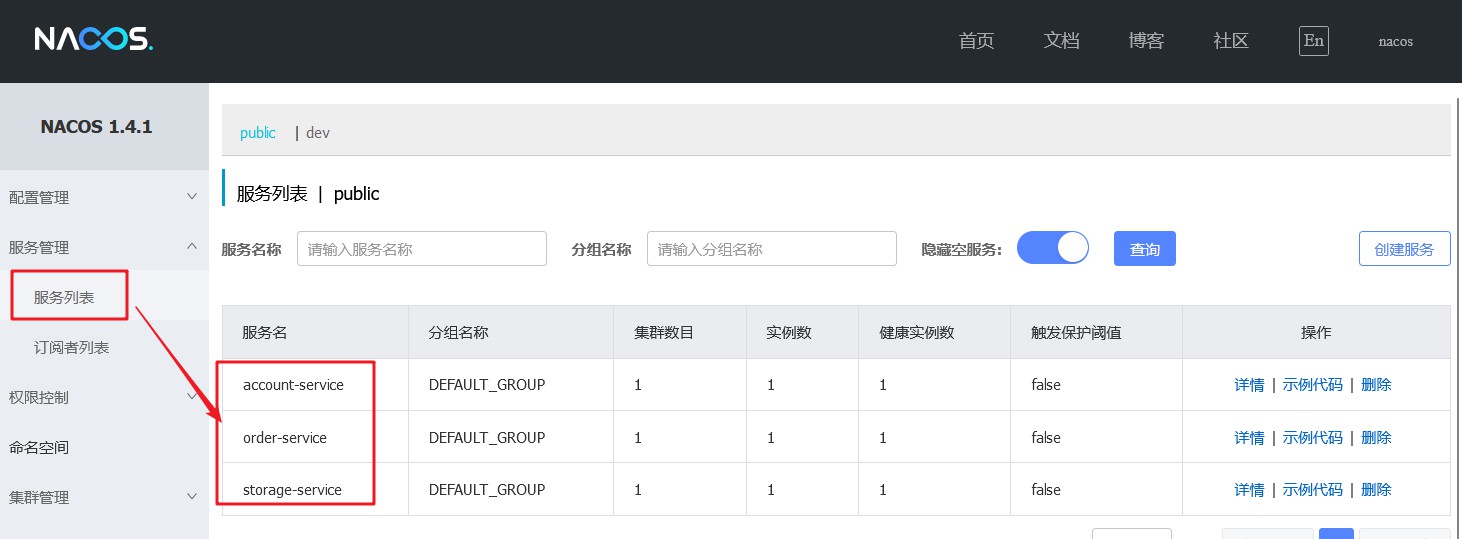
- 登录nacos首页,查看微服务是否注册成功
④、测试下单功能,发出POST请求
-
请求如下所示
-
curl --location --request POST 'http://localhost:8082/order?userId=user202103032042012&commodityCode=100202003032041&count=20&money=200' - 该请求的含义是,向userId为
user202103032042012的用户要购买20件商品,该商品code为100202003032041,要生成该订单,需要插入新数据到订单表,同时修改账户表,减少200(原1000),修改库存表,减少20(原本10)
- 该请求的含义是,向userId为
-
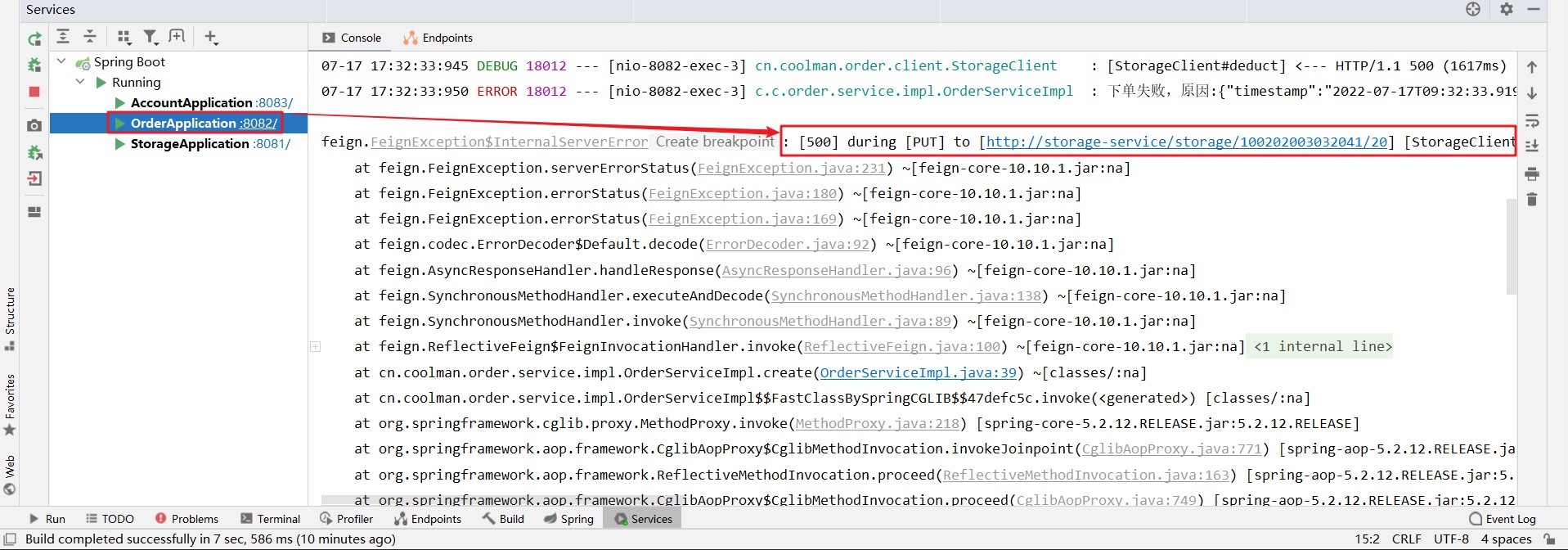
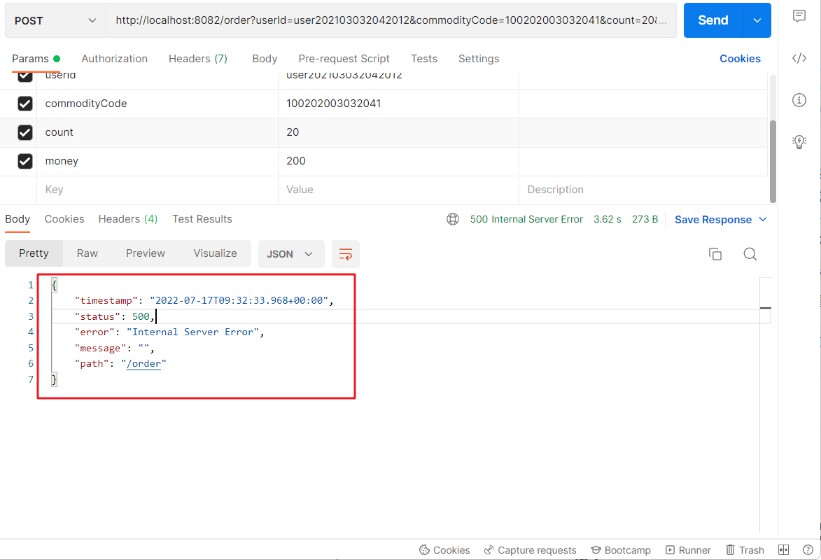
此时Postman请求页面报错状态码为500
-
后端报错信息如下
-
PS:如果没出现这个错误,那就是其他地方有错误,比如如果有
feign.····:Read time out,那就是当前网络存在波动,可以在yml配置文件中添加feign.client的超时时间(默认的时间较短,可以配置长一点)feign: client: config: default: connectTimeout: 60000 readTimeout: 60000 loggerLevel: basic -
-
feign.FeignException$InternalServerError: [500] during [PUT] to [http://storage-service/storage/100202003032041/20] [StorageClient#deduct(String,Integer)]: [{"timestamp":"2022-07-17T09:32:33.919+00:00","status":500,"error":"Internal Server Error","message":"","path":"/storage/100202003032041/20"}] -
报错信息为在更新(修改)stroage_tbl表的时候,出现了500的错误信息
-
-
-
这时候,我们查看一下创建订单的代码

- 报错信息显示在
storageClient.decut方法,这属于Feign远程调用其他服务 - 因为在
create方法上添加了@Transactional注解,我们本意是当sql语句执行错误的时候,让事务回滚 - 我们可以查看一下数据库此时的变化
- order_tbl表
- storage_tbl表
- account_tbl表
- order_tbl表
- 可以发现,此时其他两张表没有变化,而用户余额的记录表发生了变化,显然此时的
@Transactional并没有起到所有事务回滚的效果



1.3、分布式事务问题出现的原因
- 很显然,错误原因是账户表中的count字段为10,请求要减去20,源于count字段不能为负数,所以会直接报错
- 同时
@Transactional只能解决本地事务,如果有微服务远程调用时是没办法控制- 此时创建订单的代码,对账户表和库存表的业务都是远程调用,所以这里
@Transactional对这两张表是不起作用的,而因为此时的操作是在order-service中,对于order表来说是属于本地调用,所以事务回滚成功,订单没有创建
- 此时创建订单的代码,对账户表和库存表的业务都是远程调用,所以这里
- 显然,要解决这个问题,就要思考如何让分布式的微服务实现事务回滚?
1.4、CAP定理
1.4.1、CAP定理的概念
- 1988年,加州大学计算机科学家 Eric Brewer 提出,分布式系统有三个指标
- ①、Consistency(一致性)
- ②、Availability(可用性)
- ③、Partition tolerance(分区容错性)
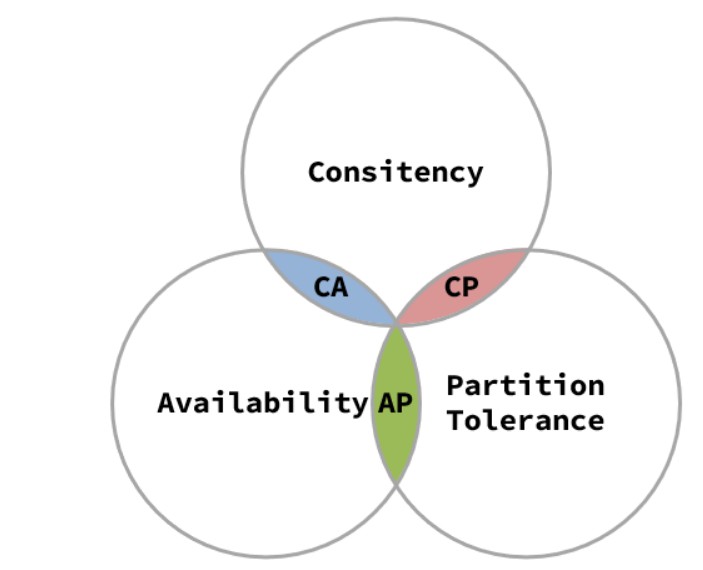
- 作者指出,这三个指标不可能通知做到,这个结论就叫做 CAP 定理
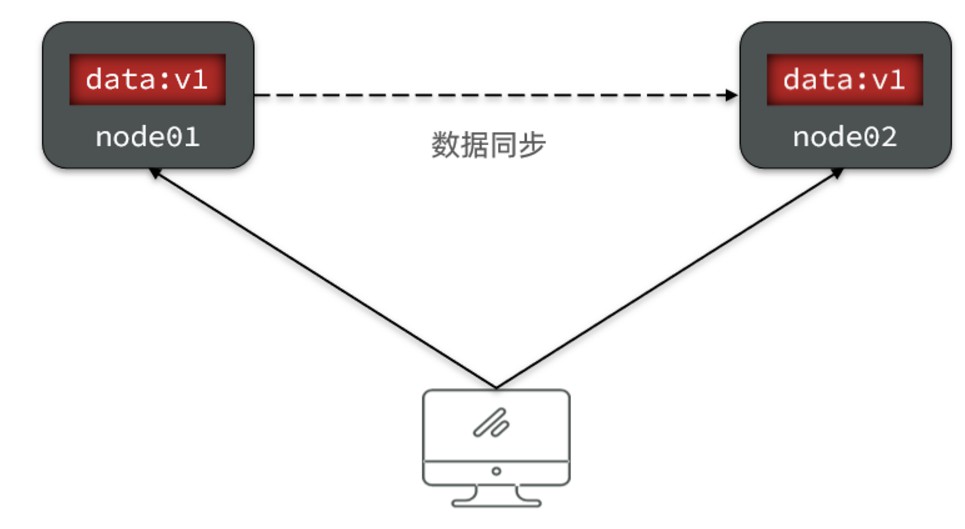
①、一致性
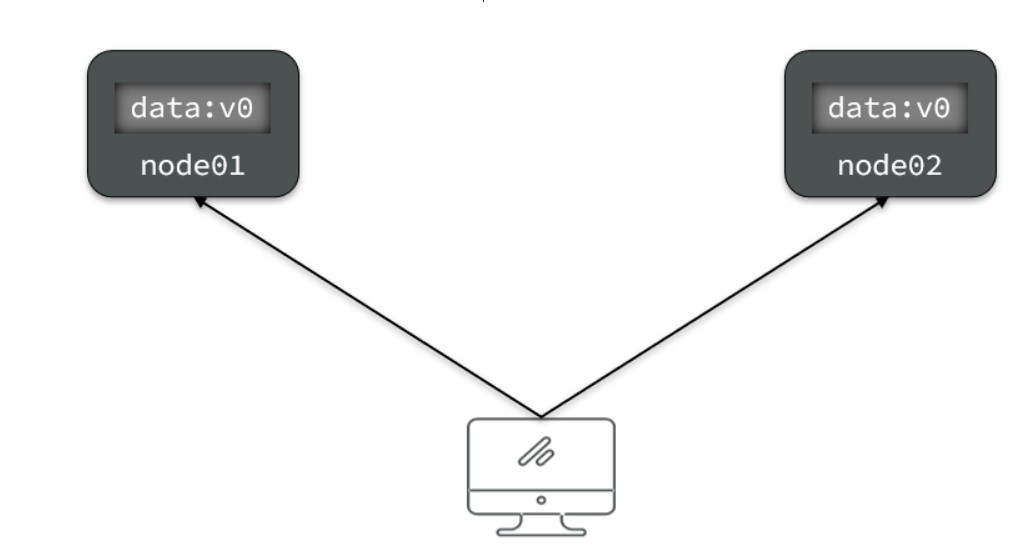
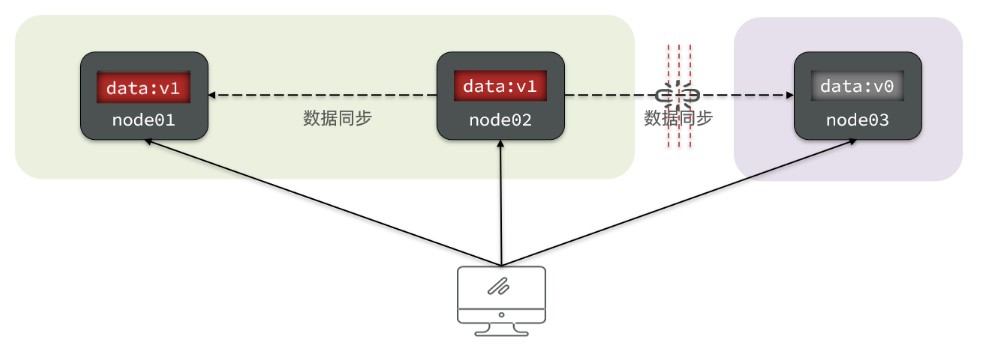
- Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
- 比如现在包含两个节点,其中的初始数据是一致的
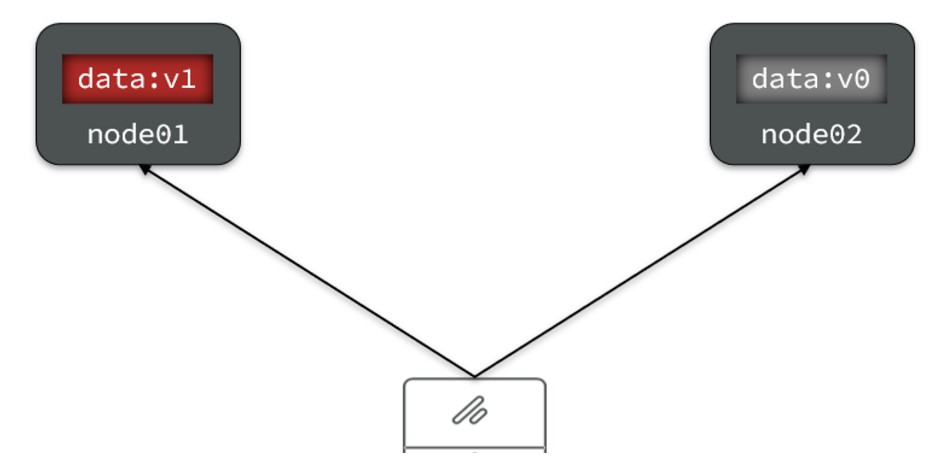
- 当我们修改其中一个节点的数据的时候,两者的数据产生了差异
- 要想保证一致性,就必须实现 node1 到 node2 的数据同步
②、可用性
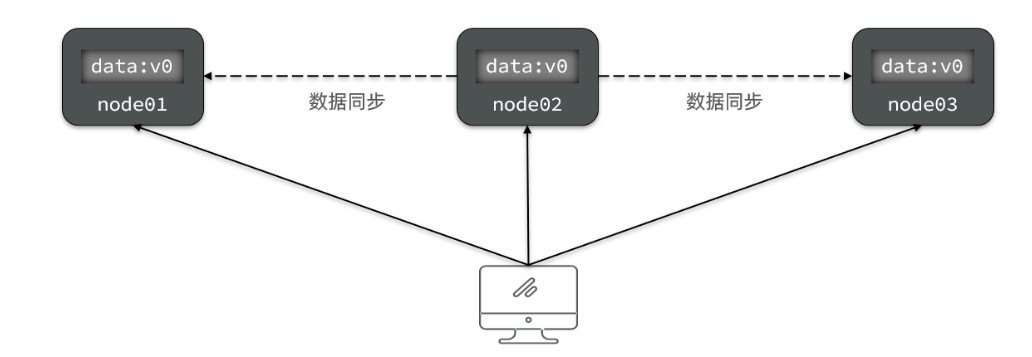
- Availability(可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝
- 如图,有三个节点的集群,访问任何一个都可以及时得到响应
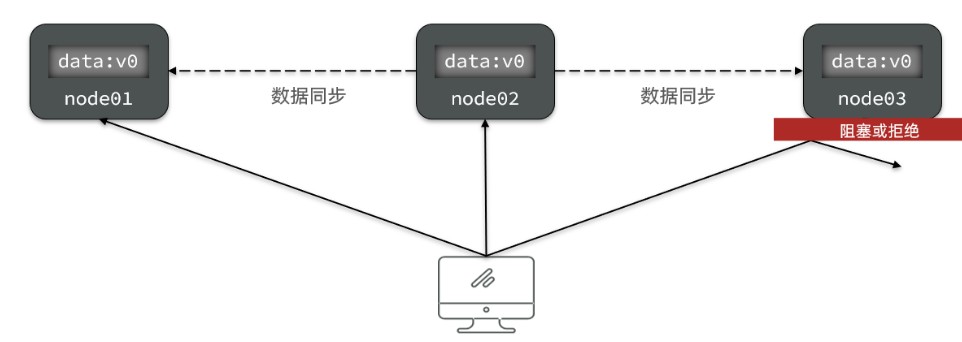
- 当有部分节点因为网络故障或其他原因无法访问时候,代表节点不可用
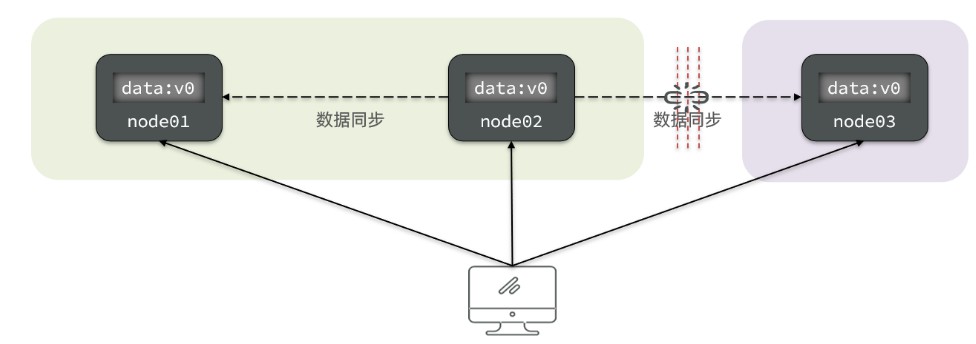
③、分区容错性
- Partition(分区):因为网络故障或其他原因导致分布式系统中的部分节点与其他节点失去连接,形成独立分区
1.4.2、CAP定理矛盾点
- 在分布式系统中,系统之间的网络不能100%保证健康,一定会有故障的时候,而服务由必须对外保证服务,因此Partition Tolerance(分区容错性)不可避免
- 当节点接收到新的数据变更的时候, 就会出现问题了
- 如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用(CP:一致性和分区容错性)
- 如果此时要保证可用性,就不能等待网络恢复,那node01,node02与node03之间就会出现数据不一致(AP:可用性和分区容错性)
- 也就是说,在P一定会出现的情况下,A和C之间只能实现一个
1.5、BASE理论与解决分布式事务思路
- BASE理论是由eBay架构师提出的,是对CAP的一种解决思路,包含三个思想:
- Basically Available(基本可用):分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致
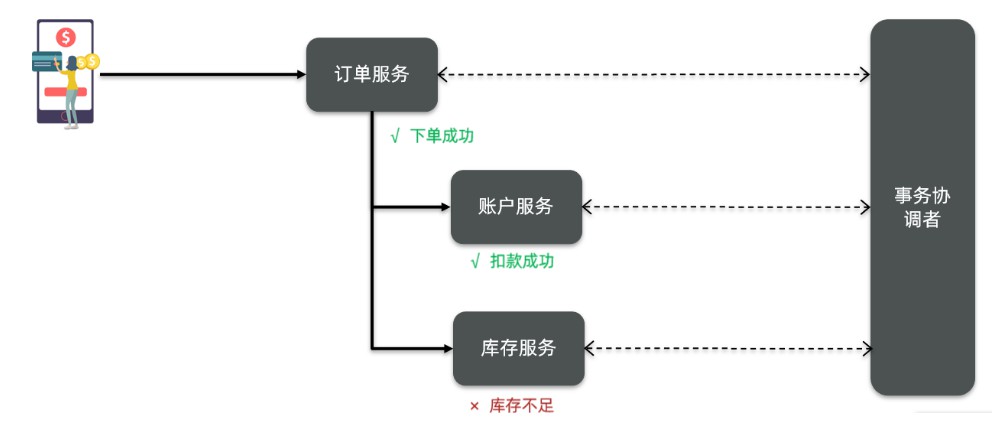
- 分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路
- ①、AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致(强可用,弱一致)
- ②、CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但是事务回滚等待过程中,处于弱可用状态(弱可用,强一致)
- 但是不管哪一种模式,都需要在子系统事务之间互相通讯,协调事务状态,也就是需要一个事务协调者(TC)
- 这里的子系统事务,称为分支事务;有关联的各个分支事务在一起称为全局事务


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?