
05-Collection
Collection
1、复习数组和集合的区别
1.1、数组特点
-
- 长度不能变化
- 可以存放基本数据类型也可以存放引用数据类型
1.2、集合的特点
-
- 长度可以变化
- 只能存储引用数据类型
2、Collection集合
2.1、介绍
Collection是单列集合的顶层接口,Collection种定义单列集合种的共性内容

2.2、List体系特点
-
- 有索引
- 元素可以重复
- 存储和取出有顺序
2.3、Set体系特点
-
- 没有索引
- 元素不可以重复
- 存储和取出没有顺序
2.4、Collection常用功能
2.4.1、添加元素
- boolean add(E e) 添加元素
2.4.2、清空集合
- void clear() 清空集合,删除集合中的所有元素2.4.3、是否包含指定的元素
2.4.3、判断是否包含指定元素
- boolean contains(Object o) 是否包含指定的元素,如果包含返回true
2.4.4、判断集合是否为空
- boolean isEmpty() 判断集合是否为空,如果为空返回true
2.4.5、删除元素
- boolean remove(Object o) 根据内容删除元素
2.4.6、获取集合的长度
- int size() 获取集合的长度
2.4.7、集合转化成数组
- public Object[] toArray() 把集合中的元素,存储到数组中
2.5、示例代码
public class Demo02 { public static void main(String[] args) { // 我们现在要学习Collection接口中的方法 Collection<String> coll = new ArrayList<>(); // boolean add(E e) 添加元素 coll.add("王宝强"); coll.add("谢霆锋"); coll.add("贾乃亮"); coll.add("陈羽凡"); // void clear() 清空集合,删除集合中的所有元素 // coll.clear(); // boolean contains(Object o) 是否包含指定的元素,如果包含返回true System.out.println(coll.contains("王宝强")); // true System.out.println(coll.contains("王力宏")); // false // boolean isEmpty() 判断集合是否为空,如果为空返回true // System.out.println(coll.isEmpty()); // boolean remove(Object o) 根据内容删除元素 coll.remove("王宝强"); // int size() 获取集合的长度 System.out.println("长度: " + coll.size()); // public Object[] toArray() 把集合中的元素,存储到数组中 Object[] arr = coll.toArray(); for (int i = 0; i < arr.length; i++) { Object obj = arr[i]; System.out.println(obj); } System.out.println(coll); } }
2、迭代器
2.1、为什么要迭代器
- List接口有索引,我们可以通过for循环+get方法来获取数据,但是Set接口这边没有索引,不能通过for循环+get方法来获取数据。
- 解决办法:Collection接口设计了一种通用的方式方便所有的集合来获取数据,就是迭代器(Iterator)
2.2、迭代器的常用方法
2.2.1、判断是否有元素,如果有返回true
- boolean hashNext()判断是否有元素,如果有返回true
2.2.2、获取一个元素
- E next()获取一个元素
2.3、如何获取迭代器
- 集合.iterator()获取迭代器
- 所有的集合都可以调用iterator()方法获取迭代器
2.4、迭代器的使用步骤
-
- 获取迭代器
- 循环判断是否有元素
- 获取元素
2.5、示例代码
public class Demo03 { public static void main(String[] args) { // 创建集合 Collection<String> coll = new ArrayList<>(); coll.add("贾乃亮"); coll.add("陈羽凡"); coll.add("王宝强"); coll.add("武大郎"); // 使用迭代器遍历数据 // 1.获取迭代器 Iterator<String> itr = coll.iterator(); // 2.循环判断是否有下一个元素 while (itr.hasNext()) { // 3.有元素,获取一个元素 String next = itr.next(); System.out.println(next); } }}
3、增强for循环
3.1、概念
是JDK1.5推出的新特性,一般也称为加强for循环,foreach循环
3.2、格式
- for(数据类型 变量名 : 数组或集合){}
3.3、好处
- 简化代码
3.4、缺点
- 无法操作索引
3.5、遍历集合的原理
- 增强for遍历集合的底层利用的是迭代器
3.6、遍历数组的原理
- 增强for遍历数组底层利用的是普通for循环
3.7、示例代码
public class Demo05 { public static void main(String[] args) { Collection<String> coll = new ArrayList<>(); coll.add("李小璐"); coll.add("白百何"); coll.add("张柏芝"); coll.add("马蓉"); // 增强for遍历集合,底层是迭代器 for (String str: coll) { System.out.println(str); } // 判断存在才删除 while (coll.contains("白百何")) { coll.remove("白百何"); } System.out.println("--------------------------------------"); // 增强for遍历数组,底层是普通for循环 int[] arr = new int[] {11, 22, 33}; for (int number: arr) { System.out.println(number); } } }
4、常用数据结构
4.1、栈
- 先进后出
4.2、队列
- 先进先出
4.3、数组
- 查询快,增删慢
4.4、链表
- 查询慢,增删相对快
4.5、二叉树
- 二叉树每个节点最多只有2个子节点
4.6、二叉查找树
- 要求
- 每一个节点上最多有两个子节点
- 左子树上所有节点的值都小于根节点的值
- 右子树上所有节点的值都大于根节点的值
- 好处
- 提高查询数据的性能
- 弊端
- 二叉查找树倾斜,退化成链表,查询速度变慢
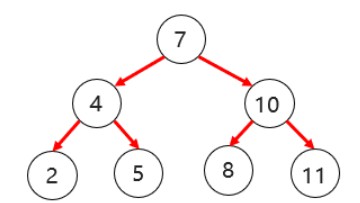
4.7、平衡二叉树
- 要求
- 任意节点的左右两个子树的高度相差不超过1
- 任意节点的左右两个子树都是一棵平衡二叉树
- 好处
- 提高查询数据的性能
- 弊端
- 平衡二叉树的子树高度相差不超过1,要求很严格,每次添加或删除数据的时候都可能导致树不平衡,需要进行旋转,查询效率高,增删效率低
4.8、红黑树
4.8.1、规则
- 每一个节点是红色或者黑色,根节点必须是黑色
- 如果一个节点没有子节点或者父节点,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
- demo:
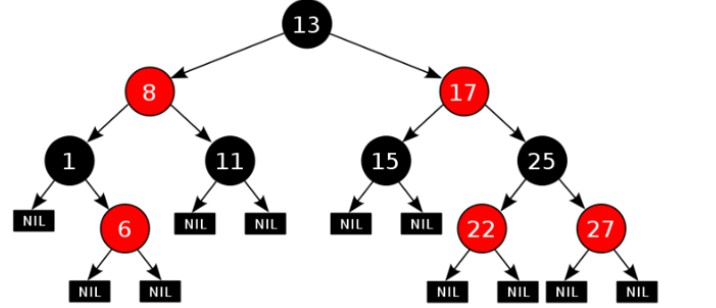
- 红黑树的要求比平衡二叉树更加宽松,保证最短路径到最长路径的数量不超过两倍
- demo:
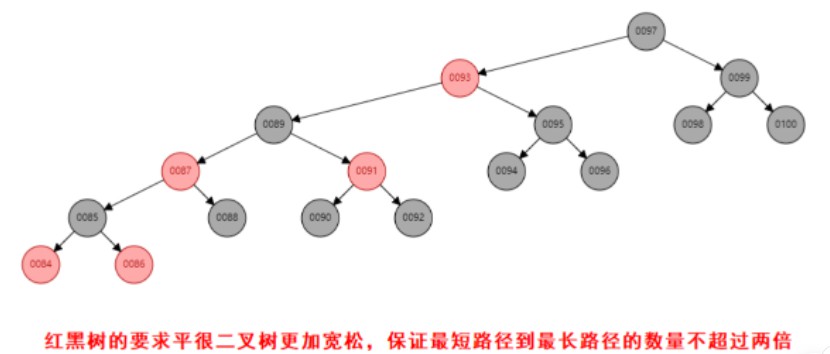
-
4.8.2、好处
- 红黑树的要求比平衡二叉树更加宽松,保证最短路径到最长路径的数量不超过两倍,添加或删除元素时进行旋转的概率更低,增高了增删效率
- 查询效率较高,增删效率高
5、List体系
5.1、特点
-
- 有索引
- 元素可以重复
- 存储和取出有顺序
- demo:
5.2、List集合特有方法
5.2.1、往指定索引位置添加元素
- void add(int index, E element) 往指定索引位置添加元素5.2.2、获取指定索引的元素
5.2.2、获取指定索引的元素
- E get(int index) 获取指定索引的元素
5.2.3、修改指定索引位置的元素
- E set(int index, E element) 修改指定索引位置的元素
5.2.4、通过索引删除元素
- E remove(int index) 通过索引删除元素
5.3、ArrayList原理
-
-
ArrayList集合底层是数组,查询快,增删慢
-
ArrayList内部使用Object[] elementData;来存储数据
-
刚创建ArrayList,elementData数组为0
-
第一次添加数据时elementData长度为10
-
当数据超过10个,扩容,容量是以前的1.5倍
eg:10, 15, 22, 33
-
5.4、LinkedList
5.4.1、LinkedList特有方法
5.4.1.1、在最前面添加一个数据
- void addFirst(E e) 在最前面添加一个数据
5.4.1.2、在最后面添加一个数据
- void addLast(E e) 在最后面添加一个数据5.4.1.3、获取第一个元素
5.4.1.3、
- E getFirst() 获取第一个元素
5.4.1.4、获取最后一个元素
- E getLast() 获取最后一个元素
5.4.1.5、删除第一个元素
- E removeFirst() 删除第一个元素
5.4.1.6、删除最后一个元素
- E removeLast() 删除最后一个元素
5.4.2、LinkedList原理
- LinkedList底层是双向链表,具有查询慢,增删快
6、Set体系
6.1、特点
-
- 没有索引
- 元素不可以重复
- 存储和取出没有顺序
- demo
6.2、Set体系特有方法
- Set体系没有特殊方法,都是使用来自Collection中的方法
6.3、HashSet
6.3.1、HashSet 基本使用
-
demo:
-
public class Demo11 { public static void main(String[] args) { // 创建HashSet Set<String> set = new HashSet<>(); // 添加数据 set.add("郭富城"); set.add("刘德华"); set.add("张学友"); System.out.println(set.add("黎明")); System.out.println(set.add("黎明")); System.out.println(set.add("黎明")); // 遍历集合 for (String s : set) { System.out.println(s); } } }
-
6.3.2、HashSet存储Student
- 放在HashSet中的元素如果要去除重复,需要重写hashCode()和equals()方法hashCode相同,equals为true的就认为是重复.不存储
6.3.3、哈希表结构
- JDK1.8之前
- JDK1.8Z之后
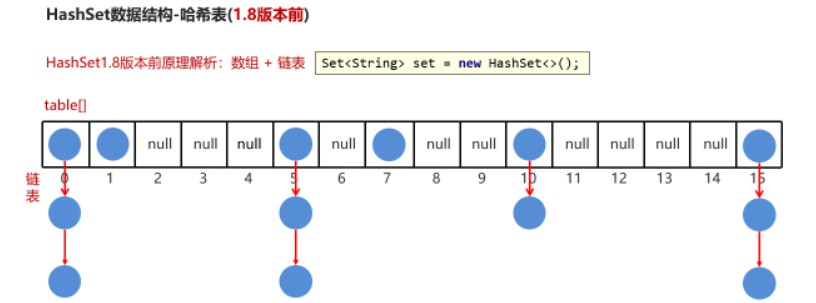
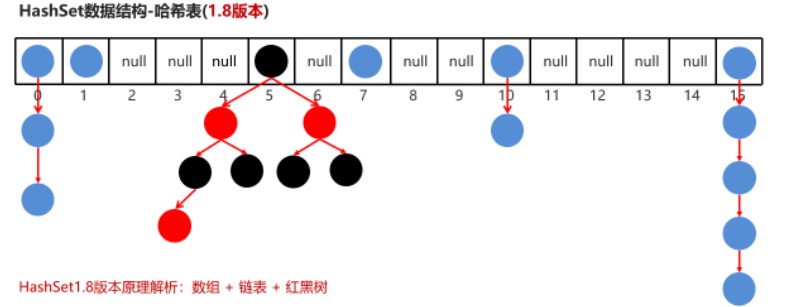
6.3.4、哈希表存储元素过程
-
- 根据hashCode值计算元素存放的位置
- 如果这个位置没有元素,直接存储
- 如果这个位置有元素,调用equals比较
- equals()为false,存储
- equals()为true,不存储(认为是相同的元素)
6.4、LinkedHashSet
6.4.1、特点
- 有序
- 不重复
- 无索引
6.4.2、底层原理
- 底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
- demo

6.5、TreeSet
6.5.1、特点
- 不重复
- 无索引
- 会排序
6.5.2、底层原理
- TreeSet集合底层是基于红黑树的数据实现排序的,增删改查性能都较好
- TreeSet集合是一定要排序的
-
- 元素自然排序(默认的规则排序)
- 比较器排序
-
6.5.3、TreeSet的构造器
6.5.3.1、根据元素的自然顺序排序
- public TreeSet()根据元素的自然顺序排序
6.5.3.2、根据比较器的规则给元素排序
- public TreeSet(Comparator comparator)根据比较器的规则给元素排序
6.5.4、TreeSet存储自定义类型
-
自定义类型放入TreeSet中,其是不知道怎么排序的,会出现异常
-
自然排序Comparable(自定义类实现Comparable接口)
-
// 类实现了Comparable接口就有自然排序的能力 public class Student implements Comparable<Student> { private String name; private int age; @Override public int compareTo(Student o) { // this: 当前对象 // o: 另一个对象 // return this.age - o.age; // 升序 return o.age - this.age; // 降序 } // 类中省略其他}
-
-
比较器排序Comparator(使用匿名内部类创建Comparator对象,并重写compara方法)
-
// 创建TreeSet集合对象(使用比较器排序) // 比较器的优先级高于,元素的自然顺序 TreeSet<Student> treeSet = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { // return o1.getAge() - o2.getAge(); // 升序 return o2.getAge() - o1.getAge(); // 升序 } });
-
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?