SRPCore Material classification与优化Screen Space Reflection
 在写Visibility Buffer流程之前,还得给自己的管线添加延迟渲染的流程。
于是乎在参考HDRP的Deferred Lighting的时候看到了Indirect Dispatch的优化手法,然后也意识到这样的优化手法也能够作用到之前写的SSR之中。
在写Visibility Buffer流程之前,还得给自己的管线添加延迟渲染的流程。
于是乎在参考HDRP的Deferred Lighting的时候看到了Indirect Dispatch的优化手法,然后也意识到这样的优化手法也能够作用到之前写的SSR之中。
序言
在写这篇之前,原本是打算写一篇RenderGraph的简易使用指南的,潜意识的我觉得写这个的意义不是特别大,因为感觉并不能在写的过程中让自己学到点什么新的知识(特别是看到DebugView的GC之后),除非把整个Render Graph(资源管理,Pass Compile流程)理一遍,这样的话就不算是简易指南了。
所以,还是更倾向于搞一点对我而言比较新的东西,比如在岗时就想做的Visibility Buffer。
而在写Visibility Buffer流程之前,还得给自己的管线添加延迟渲染的流程。
于是乎在参考HDRP的Deferred Lighting的时候看到了Indirect Dispatch的优化手法,然后也意识到这样的优化手法也能够作用到之前写的SSR之中。
(其实这样的优化手法在14年SIGGRAPH COD的Advances in Real-Time Rendering就有提及。https://advances.realtimerendering.com/s2014/index.html)
一下子就觉得写这个比写RenderGraph更值得记录下来,于是决定还是先写这个,RenderGraph还是往后延一下。
Material classification
延迟渲染的时候,很多时候的消耗是在于,为了支持多种光照模型,Deferred输出的shader需要计算当前像素的光照模型(动态分支),以及会让Shader变得过于臃肿(带来更多的渲染资源的绑定)。
为了解决这个动态分支,需要提前将画面上的材质进行分类,把动态分支变成静态分支。
HDRP对于这个材质分类的做法是跟神海4的2016 SIGGRAPH的类似。https://zhuanlan.zhihu.com/p/77542272
也是在GBuffer Pass阶段输出材质类型的ID,
然后通过Compute Shader通过线程原子操作计算16*16像素的Tile内的材质类型,并且进行分类,
并把对应的Variant InterlockAdd Indirect Buffer得到对应Feature Variant要Dispatch的线程组数量(Deferred Shader Indirect Dispatch用)中。
在材质类型分类的基础上,HDRP在做FPTL的时候顺便对不同的光照情况进行了更近一步的分类。
FeatureFlag
FeatureFlag的种类
这里依旧是用GenerateHLSL Tag控制管线代码与Shader代码的同步
https://www.cnblogs.com/OneStargazer/p/18131227
从LightDefinitions.s_LightFeatureMaskFlags可以看出Light Feature Flag占32位uint的后面16位,Material Flag占前面的16位。
其中SSRefraction与SSReflection并没有对Tile进行分类,只是在FeatureFlag上占了位
[GenerateHLSL]
internal enum LightFeatureFlags
{
// Light bit mask must match LightDefinitions.s_LightFeatureMaskFlags value
Punctual = 1 << 12,
Area = 1 << 13,
Directional = 1 << 14,
Env = 1 << 15,
Sky = 1 << 16,
SSRefraction = 1 << 17,
SSReflection = 1 << 18,
// If adding more light be sure to not overflow LightDefinitions.s_LightFeatureMaskFlags
}
[GenerateHLSL]
class LightDefinitions
{
...
// Following define the maximum number of bits use in each feature category.
public static uint s_LightFeatureMaskFlags = 0xFFF000;
public static uint s_LightFeatureMaskFlagsOpaque = 0xFFF000 & ~((uint) LightFeatureFlags.SSRefraction); // Opaque don't support screen space refraction
public static uint s_LightFeatureMaskFlagsTransparent = 0xFFF000 & ~((uint) LightFeatureFlags.SSReflection); // Transparent don't support screen space reflection
public static uint s_MaterialFeatureMaskFlags = 0x000FFF; // don't use all bits just to be safe from signed and/or float conversions :/
}
Tile内的Light Feature Flag计算
在之前的FPTL的流程解析之中,FeatureFlag的计算由于对Forward的计算光照的流程没有影响,于是就略过了。
这里就只把FTPL计算每个Tile的FeatureFlag的代码拉出来,FPTL的具体流程可以看我之前写的文章这里就不再赘述了。
https://www.cnblogs.com/OneStargazer/p/18105322
计算Tile内的LightFeatureFlag存放到RWStructuredBuffer的g_TileFeatureFlags
(tileIDX.y * nrTilesX + tileIDX.x把屏幕上的Tile转换成一维)
#define NR_THREADS PLATFORM_LANE_COUNT
#else
#define NR_THREADS 64 // default to 64 threads per group on other platforms..
#endif
#ifdef USE_FEATURE_FLAGS
groupshared uint ldsFeatureFlags;
RWStructuredBuffer<uint> g_TileFeatureFlags;
#endif
#define TILE_SIZE_FPTL (16)
//lightlistbuild.compute
[numthreads(NR_THREADS, 1, 1)]
void TileLightListGen(uint3 dispatchThreadId : SV_DispatchThreadID, uint threadID : SV_GroupIndex, uint3 u3GroupID : SV_GroupID)
{
...(SphericalIntersectionTests)
...(FinePruneLights)
if (t < CATEGORY_LIST_SIZE)
ldsCategoryListCount[t] = 0;
#ifdef USE_FEATURE_FLAGS
if(t==0)
ldsFeatureFlags=0;
#endif
#if NR_THREADS > PLATFORM_LANE_COUNT
GroupMemoryBarrierWithGroupSync();
#endif
#define LIGHT_LIST_MAX_COARSE_ENTRIES (64)
//遍历经过SphericalIntersectionTests以及FinePruneLights剔除计算之后的Tile内灯光列表
int nrLightsCombinedList = min(ldsNrLightsFinal,LIGHT_LIST_MAX_COARSE_ENTRIES);
for (int i = t; i < nrLightsCombinedList; i += NR_THREADS)
{
const int lightBoundIndex = GenerateLightCullDataIndex(prunedList[i], g_iNrVisibLights, unity_StereoEyeIndex);
InterlockedAdd(ldsCategoryListCount[_LightVolumeData[lightBoundIndex].lightCategory], 1);
//原子操作计算当前Tile的FeatureFlag(一个线程组计算一个Tile)
//LightVolumeData的featureFlags为当前Volume Data的Light Feature Flag
//Light Feature Flag有(Punctal,Area,Direction,Environment,Sky,ScreenSpaceReflection,ScreenSpaceRefraction)
#ifdef USE_FEATURE_FLAGS
InterlockedOr(ldsFeatureFlags, _LightVolumeData[lightBoundIndex].featureFlags);
#endif
}
#ifdef USE_FEATURE_FLAGS
if(t == 0)
{
//g_BaseFeatureFlags = LightFeatureFlags.Directional(Direction Light Count>0)|LightFeatureFlags.Sky(skyEnabled);
uint featureFlags = ldsFeatureFlags | g_BaseFeatureFlags;
//整个Tile所有像素都是用作渲染天空盒
// In case of back
if(ldsZMax < ldsZMin) // is background pixel
{
// There is no stencil usage with compute path, featureFlags set to 0 is use to have fast rejection of tile in this case. It will still execute but will do nothing
featureFlags = 0;
}
g_TileFeatureFlags[tileIDX.y * nrTilesX + tileIDX.x + unity_StereoEyeIndex * nrTilesX * nrTilesY] = featureFlags;
}
#endif
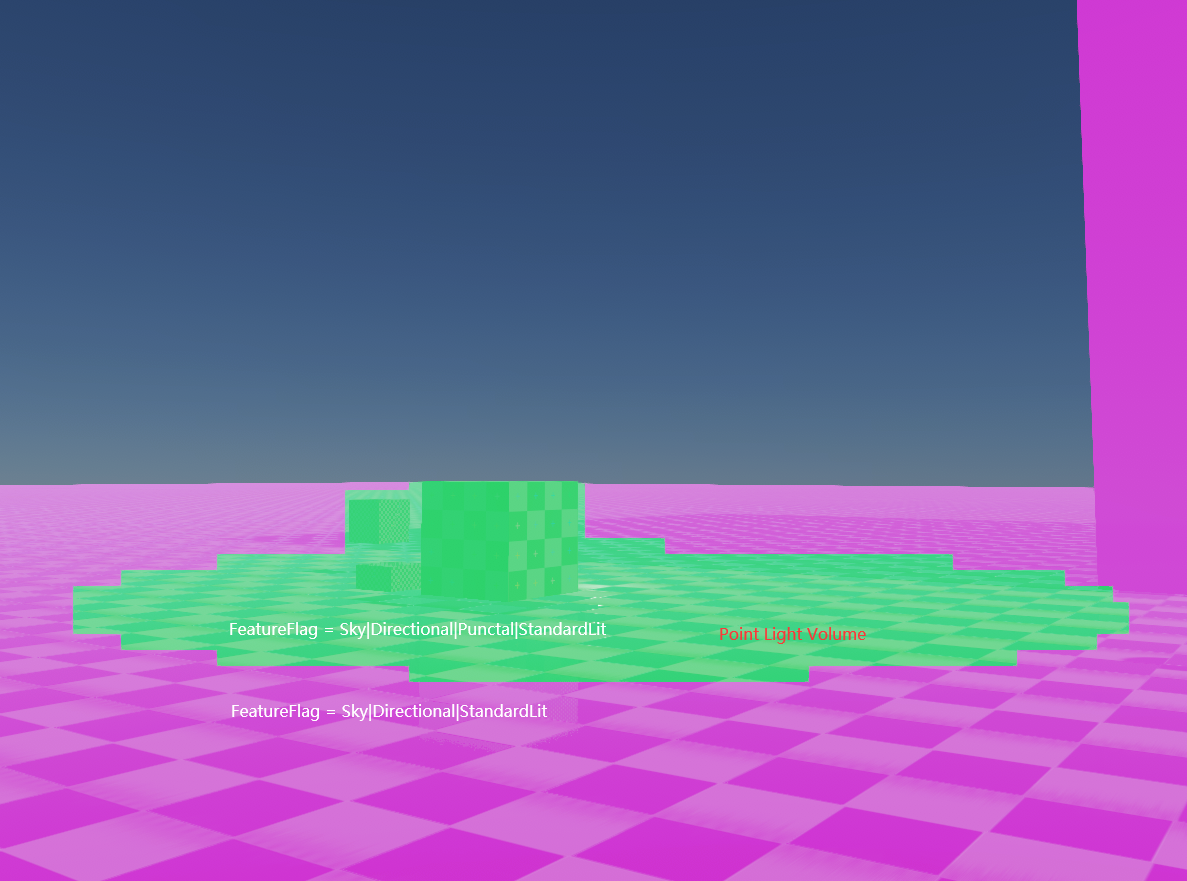
g_BaseFeatureFlags的设置
平行光数量大于0时,g_BaseFeatureFlags开启LightFeatureFlags.Directional Flag
天空盒渲染开启时,g_BaseFeatureFlags开启LightFeatureFlags.Sky Flag
//HDRenderPipeline.LightLoop.cs
static void BuildPerTileLightList(BuildGPULightListPassData data, ref bool tileFlagsWritten, CommandBuffer cmd)
{
// optimized for opaques only
if (data.runLightList && data.runFPTL)
{
...
var localLightListCB = data.lightListCB;
if (data.enableFeatureVariants)
{
uint baseFeatureFlags = 0;
if (data.directionalLightCount > 0)
{
baseFeatureFlags |= (uint)LightFeatureFlags.Directional;
}
if (data.skyEnabled)
{
baseFeatureFlags |= (uint)LightFeatureFlags.Sky;
}
if (!data.computeMaterialVariants)
{
baseFeatureFlags |= LightDefinitions.s_MaterialFeatureMaskFlags;
}
localLightListCB.g_BaseFeatureFlags = baseFeatureFlags;
cmd.SetComputeBufferParam(data.buildPerTileLightListShader, data.buildPerTileLightListKernel, HDShaderIDs.g_TileFeatureFlags, data.output.tileFeatureFlags);
tileFlagsWritten = true;
}
ConstantBuffer.Push(cmd, localLightListCB, data.buildPerTileLightListShader, HDShaderIDs._ShaderVariablesLightList);
...
}
}
MaterialFlag
对于MaterialFlag,HDRP只是对Lit的
LitSubsurfaceScattering
LitTransmission
LitStandard
LitAnisotropy
LitIridescence
LitClearCoat
做了Tile的分类。
LitSpecularColor在DeferredShader着色还是用的是动态分支。
//Packages/com.unity.render-pipelines.high-definition@12.1.6/Runtime/Material/Lit/Lit.cs
partial class Lit : RenderPipelineMaterial
{
// Currently we have only one materialId (Standard GGX), so it is not store in the GBuffer and we don't test for it
// If change, be sure it match what is done in Lit.hlsl: MaterialFeatureFlagsFromGBuffer
// Material bit mask must match the size define LightDefinitions.s_MaterialFeatureMaskFlags value
[GenerateHLSL(PackingRules.Exact)]
public enum MaterialFeatureFlags
{
LitStandard = 1 << 0, // For material classification we need to identify that we are indeed use as standard material, else we are consider as sky/background element
LitSpecularColor = 1 << 1, // LitSpecularColor is not use statically but only dynamically
LitSubsurfaceScattering = 1 << 2,
LitTransmission = 1 << 3,
LitAnisotropy = 1 << 4,
LitIridescence = 1 << 5,
LitClearCoat = 1 << 6
};
...
}
BuildMaterialFlag
在FPTL对屏幕上16*16的Tile计算好Light Feature Flag之后,就轮到读取GBuffer上的Material Flag,对整个Tile内所有像素的MaterialFlag规约计算出当前Tile最终的FeatureFlag
(HDRP通过MATERIAL_FEATURE_FLAGS_FROM_GBUFFER读取GBuffer2即可获取MaterialFeatureFlag)
#pragma kernel MaterialFlagsGen
//USE_OR启用Light Feature Flag计算开启,即前面的buildlightlist.compute计算
#pragma multi_compile _ USE_OR
...
#define USE_MATERIAL_FEATURE_FLAGS
#ifdef PLATFORM_LANE_COUNT // We can infer the size of a wave. This is currently not possible on non-consoles, so we have to fallback to a sensible default in those cases.
#define NR_THREADS PLATFORM_LANE_COUNT
#else
#define NR_THREADS 64 // default to 64 threads per group on other platforms..
#endif
groupshared uint ldsFeatureFlags;
RWStructuredBuffer<uint> g_TileFeatureFlags;
TEXTURE2D_X_UINT2(_StencilTexture);
[numthreads(NR_THREADS, 1, 1)]
void MaterialFlagsGen(uint3 dispatchThreadId : SV_DispatchThreadID, uint threadID : SV_GroupIndex, uint3 u3GroupID : SV_GroupID)
{
UNITY_XR_ASSIGN_VIEW_INDEX(dispatchThreadId.z);
uint2 tileIDX = u3GroupID.xy;
uint iWidth = g_viDimensions.x;
uint iHeight = g_viDimensions.y;
uint nrTilesX = (iWidth + (TILE_SIZE_FPTL - 1)) / TILE_SIZE_FPTL;
uint nrTilesY = (iHeight + (TILE_SIZE_FPTL - 1)) / TILE_SIZE_FPTL;
// 16 * 4 = 64. We process data by group of 4 pixel
uint2 viTilLL = 16 * tileIDX;
float2 invScreenSize = float2(1.0 / iWidth, 1.0 / iHeight);
if (threadID == 0)
{
ldsFeatureFlags = 0;
}
GroupMemoryBarrierWithGroupSync();
uint materialFeatureFlags = g_BaseFeatureFlags; // Contain all lightFeatures or 0 (depends if we enable light classification or not)
UNITY_UNROLL
for (int i = 0; i < 4; i++)
{
int idx = i * NR_THREADS + threadID;
uint2 uCrd = min(uint2(viTilLL.x + (idx & 0xf), viTilLL.y + (idx >> 4)), uint2(iWidth - 1, iHeight - 1));
// Unlit object, sky/background and forward opaque tag don't tag the StencilUsage.RequiresDeferredLighting bit
uint stencilVal = GetStencilValue(LOAD_TEXTURE2D_X(_StencilTexture, uCrd));
if ((stencilVal & STENCILUSAGE_REQUIRES_DEFERRED_LIGHTING) > 0)
{
PositionInputs posInput = GetPositionInput(uCrd, invScreenSize);
materialFeatureFlags |= MATERIAL_FEATURE_FLAGS_FROM_GBUFFER(posInput.positionSS);
}
}
InterlockedOr(ldsFeatureFlags, materialFeatureFlags); //TODO: driver might optimize this or we might have to do a manual reduction
GroupMemoryBarrierWithGroupSync();
if (threadID == 0)
{
uint tileIndex = tileIDX.y * nrTilesX + tileIDX.x;
// TODO: shouldn't this always enabled?
#if defined(UNITY_STEREO_INSTANCING_ENABLED)
tileIndex += unity_StereoEyeIndex * nrTilesX * nrTilesY;
#endif
#ifdef USE_OR
g_TileFeatureFlags[tileIndex] |= ldsFeatureFlags;
#else // Use in case we have disabled light classification
g_TileFeatureFlags[tileIndex] = ldsFeatureFlags;
#endif
}
}
计算 Variant Index并Build Indirect Buffer
Variant Index
上面计算出LightFeatureFlag以及MaterialFeatureFlag合并成最终的FeatureFlag之后,
就需要计算Tile归属于的Variant Index。(遍历静态的kFeatureVariantFlags里面所有可能的组合)
说到kFeatureVariantFlags Table,
除了之前提到的其中SSRefraction与SSReflection并没有逐Tile进行分类之外,
值得留意的是次表面散射以及透射材质的MaterialFeature被合并成一种Variant处理
(MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING,MATERIALFEATUREFLAGS_LIT_TRANSMISSION)
kFeatureVariantFlags Table
//Packages/com.unity.render-pipelines.high-definition@12.1.6/Runtime/Material/Lit/Lit.hlsl
// Combination need to be define in increasing "comlexity" order as define by FeatureFlagsToTileVariant
static const uint kFeatureVariantFlags[NUM_FEATURE_VARIANTS] =
{
// Precomputed illumination (no dynamic lights) with standard
/* 0 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_STANDARD,
// Precomputed illumination (no dynamic lights) with standard, SSS and transmission
/* 1 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING | MATERIALFEATUREFLAGS_LIT_TRANSMISSION |
MATERIALFEATUREFLAGS_LIT_STANDARD,
// Precomputed illumination (no dynamic lights) for all material types
/* 2 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIAL_FEATURE_MASK_FLAGS,
/* 3 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 4 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_AREA | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 5 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 6 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 7 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIALFEATUREFLAGS_LIT_STANDARD,
// Standard with SSS and Transmission
/* 8 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING | MATERIALFEATUREFLAGS_LIT_TRANSMISSION |
MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 9 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_AREA | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING | MATERIALFEATUREFLAGS_LIT_TRANSMISSION |
MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 10 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING |
MATERIALFEATUREFLAGS_LIT_TRANSMISSION | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 11 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING |
MATERIALFEATUREFLAGS_LIT_TRANSMISSION | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 12 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIALFEATUREFLAGS_LIT_SUBSURFACE_SCATTERING | MATERIALFEATUREFLAGS_LIT_TRANSMISSION | MATERIALFEATUREFLAGS_LIT_STANDARD,
// Anisotropy
/* 13 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | MATERIALFEATUREFLAGS_LIT_ANISOTROPY | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 14 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_AREA | MATERIALFEATUREFLAGS_LIT_ANISOTROPY | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 15 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_ANISOTROPY | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 16 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_ANISOTROPY |
MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 17 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIALFEATUREFLAGS_LIT_ANISOTROPY | MATERIALFEATUREFLAGS_LIT_STANDARD,
// Standard with clear coat
/* 18 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | MATERIALFEATUREFLAGS_LIT_CLEAR_COAT | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 19 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_AREA | MATERIALFEATUREFLAGS_LIT_CLEAR_COAT | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 20 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_CLEAR_COAT | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 21 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_CLEAR_COAT |
MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 22 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIALFEATUREFLAGS_LIT_CLEAR_COAT | MATERIALFEATUREFLAGS_LIT_STANDARD,
// Standard with Iridescence
/* 23 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | MATERIALFEATUREFLAGS_LIT_IRIDESCENCE | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 24 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_AREA | MATERIALFEATUREFLAGS_LIT_IRIDESCENCE | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 25 */ LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_IRIDESCENCE | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 26 */
LIGHTFEATUREFLAGS_SKY | LIGHTFEATUREFLAGS_DIRECTIONAL | LIGHTFEATUREFLAGS_PUNCTUAL | LIGHTFEATUREFLAGS_ENV | LIGHTFEATUREFLAGS_SSREFLECTION | MATERIALFEATUREFLAGS_LIT_IRIDESCENCE |
MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 27 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIALFEATUREFLAGS_LIT_IRIDESCENCE | MATERIALFEATUREFLAGS_LIT_STANDARD,
/* 28 */ LIGHT_FEATURE_MASK_FLAGS_OPAQUE | MATERIAL_FEATURE_MASK_FLAGS, // Catch all case with MATERIAL_FEATURE_MASK_FLAGS is needed in case we disable material classification
};
uint FeatureFlagsToTileVariant(uint featureFlags)
{
for (int i = 0; i < NUM_FEATURE_VARIANTS; i++)
{
if ((featureFlags & kFeatureVariantFlags[i]) == featureFlags)
return i;
}
return NUM_FEATURE_VARIANTS - 1;
}
//Packages/com.unity.render-pipelines.high-definition@12.1.6/Runtime/Lighting/LightLoop/builddispatchindirect.compute
#ifdef PLATFORM_LANE_COUNT // We can infer the size of a wave. This is currently not possible on non-consoles, so we have to fallback to a sensible default in those cases.
#define NR_THREADS PLATFORM_LANE_COUNT
#else
#define NR_THREADS 64 // default to 64 threads per group on other platforms..
#endif
RWBuffer<uint> g_DispatchIndirectBuffer : register( u0 ); // Indirect arguments have to be in a _buffer_, not a structured buffer
RWStructuredBuffer<uint> g_TileList;
StructuredBuffer<uint> g_TileFeatureFlags;
uniform uint g_NumTiles;
uniform uint g_NumTilesX;
[numthreads(NR_THREADS, 1, 1)]
void BuildIndirect(uint3 dispatchThreadId : SV_DispatchThreadID)
{
if (dispatchThreadId.x >= g_NumTiles)
return;
UNITY_XR_ASSIGN_VIEW_INDEX(dispatchThreadId.z);
uint featureFlags = g_TileFeatureFlags[dispatchThreadId.x + unity_StereoEyeIndex * g_NumTiles];
uint tileY = (dispatchThreadId.x + 0.5f) / (float)g_NumTilesX; // Integer division is extremely expensive, so we better avoid it
uint tileX = dispatchThreadId.x - tileY * g_NumTilesX;
// Check if there is no material (means it is a sky/background pixel).
// Note that we can have no lights, yet we still need to render geometry with precomputed illumination.
if ((featureFlags & MATERIAL_FEATURE_MASK_FLAGS) != 0)
{
uint variant = FeatureFlagsToTileVariant(featureFlags);
uint tileOffset;
...
}

Build Indirect Buffer
需要留意的是Deferred着色的Tile的大小是8*8,而上面FPTL计算的Tile大小是16*16,所以给Variant Indirect Buffer需要InterlockAdd 4个Tile(4*8*8=16*16)
//Packages/com.unity.render-pipelines.high-definition@12.1.6/Runtime/Lighting/LightLoop/builddispatchindirect.compute
#ifdef PLATFORM_LANE_COUNT // We can infer the size of a wave. This is currently not possible on non-consoles, so we have to fallback to a sensible default in those cases.
#define NR_THREADS PLATFORM_LANE_COUNT
#else
#define NR_THREADS 64 // default to 64 threads per group on other platforms..
#endif
RWBuffer<uint> g_DispatchIndirectBuffer : register( u0 ); // Indirect arguments have to be in a _buffer_, not a structured buffer
RWStructuredBuffer<uint> g_TileList;
StructuredBuffer<uint> g_TileFeatureFlags;
uniform uint g_NumTiles;
uniform uint g_NumTilesX;
[numthreads(NR_THREADS, 1, 1)]
void BuildIndirect(uint3 dispatchThreadId : SV_DispatchThreadID)
{
...
uint variant = FeatureFlagsToTileVariant(featureFlags);
uint tileOffset;
#ifdef IS_DRAWPROCEDURALINDIRECT
// We are filling up an indirect argument buffer for DrawProceduralIndirect.
// The buffer contains {vertex count per instance, instance count, start vertex location, and start instance location} = {0, instance count, 0, 0, 0}
InterlockedAdd(g_DispatchIndirectBuffer[variant * 4 + 1], 1, tileOffset);
#else
uint prevGroupCnt;
// We are filling up an indirect argument buffer for DispatchIndirect.
// The buffer contains {groupCntX, groupCntY, groupCntZ} = {groupCnt, 0, 0}.
InterlockedAdd(g_DispatchIndirectBuffer[variant * 3 + 0], 4, prevGroupCnt);
tileOffset = prevGroupCnt / 4; // 4x 8x8 groups per a 16x16 tile
#endif
// See LightDefinitions class in LightLoop.cs
uint tileIndex = (unity_StereoEyeIndex << TILE_INDEX_SHIFT_EYE) | (tileY << TILE_INDEX_SHIFT_Y) | (tileX << TILE_INDEX_SHIFT_X);
// For g_TileList each VR eye is interlaced instead of one eye and then the other. Thus why we use _XRViewCount here
g_TileList[variant * g_NumTiles * _XRViewCount + tileOffset] = tileIndex;
}
}
Deferred Compute Shader
计算完不同Variant的Indirect Buffer,之后就可以Deferred通过固定的ArgsOffset对不同的Variant渲染路径进行Indirect Dispatch
(CommandBuffer.DispatchCompute(ComputeShader cs,int kernelIndex,ComputeBuffer indirectBuffer,uint argsOffset))
static void RenderComputeDeferredLighting(DeferredLightingPassData data, RenderTargetIdentifier[] colorBuffers, CommandBuffer cmd)
{
using (new ProfilingScope(cmd, ProfilingSampler.Get(HDProfileId.RenderDeferredLightingCompute)))
{
...
//遍历所有的可能variant
for (int variant = 0; variant < data.numVariants; variant++)
{
int kernel;
if (data.enableFeatureVariants)
{
kernel = s_shadeOpaqueIndirectFptlKernels[variant];
}
else
{
kernel = data.debugDisplaySettings.IsDebugDisplayEnabled() ? s_shadeOpaqueDirectFptlDebugDisplayKernel : s_shadeOpaqueDirectFptlKernel;
}
cmd.SetComputeTextureParam(data.deferredComputeShader, kernel, HDShaderIDs._CameraDepthTexture, data.depthTexture);
// TODO: Is it possible to setup this outside the loop ? Can figure out how, get this: Property (specularLightingUAV) at kernel index (21) is not set
cmd.SetComputeTextureParam(data.deferredComputeShader, kernel, HDShaderIDs.specularLightingUAV, colorBuffers[0]);
cmd.SetComputeTextureParam(data.deferredComputeShader, kernel, HDShaderIDs.diffuseLightingUAV, colorBuffers[1]);
cmd.SetComputeBufferParam(data.deferredComputeShader, kernel, HDShaderIDs.g_vLightListTile, data.lightListBuffer);
cmd.SetComputeTextureParam(data.deferredComputeShader, kernel, HDShaderIDs._StencilTexture, data.depthBuffer, 0, RenderTextureSubElement.Stencil);
// always do deferred lighting in blocks of 16x16 (not same as tiled light size)
if (data.enableFeatureVariants)
{
cmd.SetComputeBufferParam(data.deferredComputeShader, kernel, HDShaderIDs.g_TileFeatureFlags, data.tileFeatureFlagsBuffer);
cmd.SetComputeIntParam(data.deferredComputeShader, HDShaderIDs.g_TileListOffset, variant * data.numTiles * data.viewCount);
cmd.SetComputeBufferParam(data.deferredComputeShader, kernel, HDShaderIDs.g_TileList, data.tileListBuffer);
cmd.DispatchCompute(data.deferredComputeShader, kernel, data.dispatchIndirectBuffer, (uint)variant * 3 * sizeof(uint));
}
else
{
// 4x 8x8 groups per a 16x16 tile.
cmd.DispatchCompute(data.deferredComputeShader, kernel, data.numTilesX * 2, data.numTilesY * 2, data.viewCount);
}
}
}
}
值得留意的一点是在上面的kFeatureVariantFlags是静态的uint数组。
DeferredShader通过定义不同的Variant Index配合上是否含有对应渲染特性的判断
(Ex:if (featureFlags & LIGHTFEATUREFLAGS_DIRECTIONAL)、HasFlag(surfaceData.materialFeatures, MATERIALFEATUREFLAGS_LIT_TRANSMISSION)),
就可以在编译阶段对动态分支进行移除。
#pragma kernel Deferred_Direct_Fptl SHADE_OPAQUE_ENTRY=Deferred_Direct_Fptl
#pragma kernel Deferred_Direct_Fptl_DebugDisplay SHADE_OPAQUE_ENTRY=Deferred_Direct_Fptl_DebugDisplay DEBUG_DISPLAY
// Variant with and without shadowmask
#pragma kernel Deferred_Indirect_Fptl_Variant0 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant0 USE_INDIRECT VARIANT=0
#pragma kernel Deferred_Indirect_Fptl_Variant1 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant1 USE_INDIRECT VARIANT=1
#pragma kernel Deferred_Indirect_Fptl_Variant2 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant2 USE_INDIRECT VARIANT=2
#pragma kernel Deferred_Indirect_Fptl_Variant3 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant3 USE_INDIRECT VARIANT=3
#pragma kernel Deferred_Indirect_Fptl_Variant4 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant4 USE_INDIRECT VARIANT=4
#pragma kernel Deferred_Indirect_Fptl_Variant5 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant5 USE_INDIRECT VARIANT=5
#pragma kernel Deferred_Indirect_Fptl_Variant6 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant6 USE_INDIRECT VARIANT=6
#pragma kernel Deferred_Indirect_Fptl_Variant7 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant7 USE_INDIRECT VARIANT=7
#pragma kernel Deferred_Indirect_Fptl_Variant8 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant8 USE_INDIRECT VARIANT=8
#pragma kernel Deferred_Indirect_Fptl_Variant9 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant9 USE_INDIRECT VARIANT=9
#pragma kernel Deferred_Indirect_Fptl_Variant10 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant10 USE_INDIRECT VARIANT=10
#pragma kernel Deferred_Indirect_Fptl_Variant11 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant11 USE_INDIRECT VARIANT=11
#pragma kernel Deferred_Indirect_Fptl_Variant12 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant12 USE_INDIRECT VARIANT=12
#pragma kernel Deferred_Indirect_Fptl_Variant13 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant13 USE_INDIRECT VARIANT=13
#pragma kernel Deferred_Indirect_Fptl_Variant14 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant14 USE_INDIRECT VARIANT=14
#pragma kernel Deferred_Indirect_Fptl_Variant15 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant15 USE_INDIRECT VARIANT=15
#pragma kernel Deferred_Indirect_Fptl_Variant16 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant16 USE_INDIRECT VARIANT=16
#pragma kernel Deferred_Indirect_Fptl_Variant17 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant17 USE_INDIRECT VARIANT=17
#pragma kernel Deferred_Indirect_Fptl_Variant18 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant18 USE_INDIRECT VARIANT=18
#pragma kernel Deferred_Indirect_Fptl_Variant19 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant19 USE_INDIRECT VARIANT=19
#pragma kernel Deferred_Indirect_Fptl_Variant20 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant20 USE_INDIRECT VARIANT=20
#pragma kernel Deferred_Indirect_Fptl_Variant21 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant21 USE_INDIRECT VARIANT=21
#pragma kernel Deferred_Indirect_Fptl_Variant22 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant22 USE_INDIRECT VARIANT=22
#pragma kernel Deferred_Indirect_Fptl_Variant23 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant23 USE_INDIRECT VARIANT=23
#pragma kernel Deferred_Indirect_Fptl_Variant24 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant24 USE_INDIRECT VARIANT=24
#pragma kernel Deferred_Indirect_Fptl_Variant25 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant25 USE_INDIRECT VARIANT=25
#pragma kernel Deferred_Indirect_Fptl_Variant26 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant26 USE_INDIRECT VARIANT=26
#pragma kernel Deferred_Indirect_Fptl_Variant27 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant27 USE_INDIRECT VARIANT=27
#pragma kernel Deferred_Indirect_Fptl_Variant28 SHADE_OPAQUE_ENTRY=Deferred_Indirect_Fptl_Variant28 USE_INDIRECT VARIANT=28
...
#ifdef USE_INDIRECT
StructuredBuffer<uint> g_TileList;
// Indirect
[numthreads(GROUP_SIZE, GROUP_SIZE, 1)]
void SHADE_OPAQUE_ENTRY(uint2 groupThreadId : SV_GroupThreadID, uint groupId : SV_GroupID)
{
...
}
Screen Space Reflection
上面提到了HDRP的SSRefraction与SSReflection并没有对Tile进行Variant分类,
可能是出于对SSReflection分类容易把Tile弄得过于零散,
但是这也启发了我,在BuildMaterialFlag的时候可以得到SSReflection的Indirect Buffer,
同时在这里说一下SSR其他优化加速的技巧。
Hiz加速求交
首先肯定是最常见的Hiz加速,Hiz加速这部分HDRP已经做了。(可以抄)
这里简单地说一下这个过程。
Depth Pyramid
Hiz首先需要生成相机深度图的Depth Pyramid,作为Ray Trace判断是否往下一级Mip进行步进的依据。
不同级别(Hierarchical)的UVoffset的确定跟Color Pyramid是保持一致的。
(MipGenerator:https://www.cnblogs.com/OneStargazer/p/18150428)
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl"
#pragma only_renderers d3d11 playstation xboxone xboxseries vulkan metal switch
#pragma kernel KDepthDownsample8DualUav KERNEL_SIZE=8 KERNEL_NAME=KDepthDownsample8DualUav
RW_TEXTURE2D(float, _DepthMipChain);
CBUFFER_START(cb)
uint4 _SrcOffsetAndLimit; // {x, y, w - 1, h - 1}
uint4 _DstOffset; // {x, y, 0, 0}
CBUFFER_END
#if UNITY_REVERSED_Z
# define MIN_DEPTH(l, r) max(l, r)
#else
# define MIN_DEPTH(l, r) min(l, r)
#endif
// Downsample a depth texture by taking the min value of sampled pixels
// The size of the dispatch is (DstMipSize / KernelSize).
[numthreads(KERNEL_SIZE, KERNEL_SIZE, 1)]
void KERNEL_NAME(uint3 dispatchThreadId : SV_DispatchThreadID)
{
uint2 srcOffset = _SrcOffsetAndLimit.xy;
uint2 srcLimit = _SrcOffsetAndLimit.zw;
uint2 dstOffset = _DstOffset.xy;
// Upper-left pixel coordinate of quad that this thread will read
uint2 srcPixelUL = srcOffset + (dispatchThreadId.xy << 1);
float p00 = _DepthMipChain[(min(srcPixelUL + uint2(0u, 0u), srcLimit))];
float p10 = _DepthMipChain[(min(srcPixelUL + uint2(1u, 0u), srcLimit))];
float p01 = _DepthMipChain[(min(srcPixelUL + uint2(0u, 1u), srcLimit))];
float p11 = _DepthMipChain[(min(srcPixelUL + uint2(1u, 1u), srcLimit))];
float4 depths = float4(p00, p10, p01, p11);
// Select the closest sample
float minDepth = MIN_DEPTH(MIN_DEPTH(depths.x, depths.y), MIN_DEPTH(depths.z, depths.w));
_DepthMipChain[(dstOffset + dispatchThreadId.xy)] = minDepth;
}

Screen Space Reflections Tracing
在Tracing开始之前需要先干掉不需要计算的Ray。
Texture2D<uint2> _StencilTexture;
#define NR_THREADS 8
[numthreads(NR_THREADS,NR_THREADS,1)]
void ScreenSpaceReflectionsTracing(uint3 dispatchThreadId : SV_DispatchThreadID, uint2 groupThreadId : SV_GroupThreadID, uint groupId : SV_GroupID)
{
uint2 positionSS = dispatchThreadId;
//模板值判断
uint stencilValue = GetStencilValue(LOAD_TEXTURE2D(_StencilTexture, positionSS));
_SsrStencilBit = (1 << 3);
bool noReceiveSSR = (stencilValue & 32) == 0;
if (noReceiveSSR)
return;
float deviceDepth = LOAD_TEXTURE2D(_CameraDepthTexture, positionSS).r;
if (deviceDepth < FLT_EPS)
return;
}
判断Ray是否值得后续做Tracing计算
计算第一次反射光线屏幕空间坐标是否在NDC内
计算当前反射点对应的NDotV以及Roughness是否在阈值内
[numthreads(NR_THREADS,NR_THREADS,1)]
void ScreenSpaceReflectionsTracing(uint3 dispatchThreadId : SV_DispatchThreadID, uint2 groupThreadId : SV_GroupThreadID, uint groupId : SV_GroupID)
{
...
NormalData normalData;
ZERO_INITIALIZE(NormalData, normalData);
GetNormalData(positionSS, normalData);
float2 positionNDC = positionSS * _ScreenSize.zw + (0.5 * _ScreenSize.zw); // Should we precompute the half-texel bias? We seem to use it a lot.
float3 positionWS = ComputeWorldSpacePosition(positionNDC, deviceDepth, UNITY_MATRIX_I_VP); // Jittered
float3 V = GetWorldSpaceNormalizeViewDir(positionWS);
//从DepthNormalBuffer读取Normal,perceptualRoughness计算NdotV,判断perceptualRoughness是否在阈值内
float3 N = normalData.normalWS;
float perceptualRoughness = normalData.perceptualRoughness;
float3 R = reflect(-V, N);
float3 cameraPositionWS = GetCurrentViewPosition();
float bias = (1.0f - 0.001f * rcp(max(dot(N, V), FLT_EPS)));
positionWS = cameraPositionWS + (positionWS - cameraPositionWS) * bias;
deviceDepth = ComputeNormalizedDeviceCoordinatesWithZ(positionWS, UNITY_MATRIX_VP).z;
float3 rayOrigin = float3(positionSS + 0.5, deviceDepth);
//计算第一次反射光线屏幕空间坐标是否在NDC内
float3 reflPosWS = positionWS + R;
float3 reflPosNDC = ComputeNormalizedDeviceCoordinatesWithZ(reflPosWS,UNITY_MATRIX_VP);
float3 reflPosSS = float3(reflPosNDC.xy * _ScreenSize.xy, reflPosNDC.z);
float3 rayDir = reflPosSS - rayOrigin;
float3 rcpRayDir = rcp(rayDir);
int2 rayStep = int2(rcpRayDir.x >= 0 ? 1 : 0,
rcpRayDir.y >= 0 ? 1 : 0);
float3 raySign = float3(rcpRayDir.x >= 0 ? 1 : -1,
rcpRayDir.y >= 0 ? 1 : -1,
rcpRayDir.z >= 0 ? 1 : -1);
bool killRay = (reflPosSS.z <= 0);
killRay = killRay || (dot(N, V) <= 0);
killRay = killRay || (perceptualRoughness > _SsrRoughnessFadeEnd);
if (killRay)
{
return;
}
...
}
Tracing
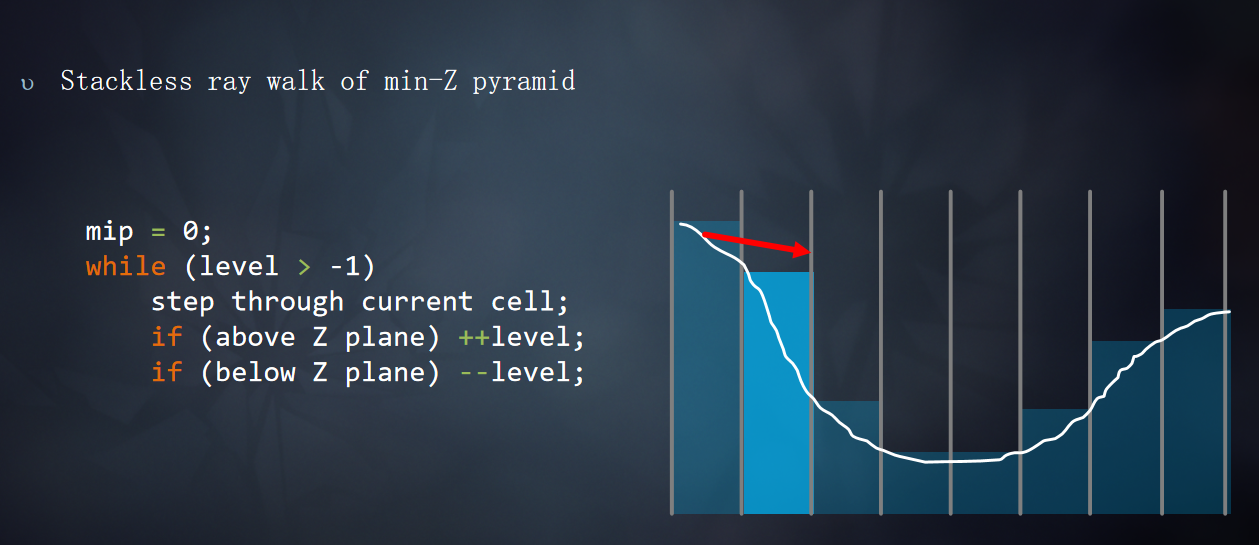
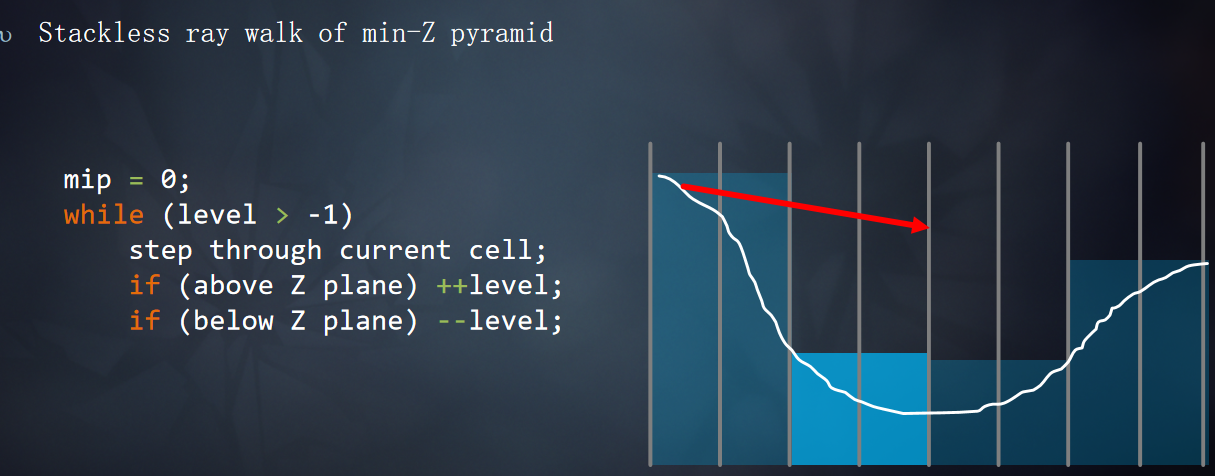
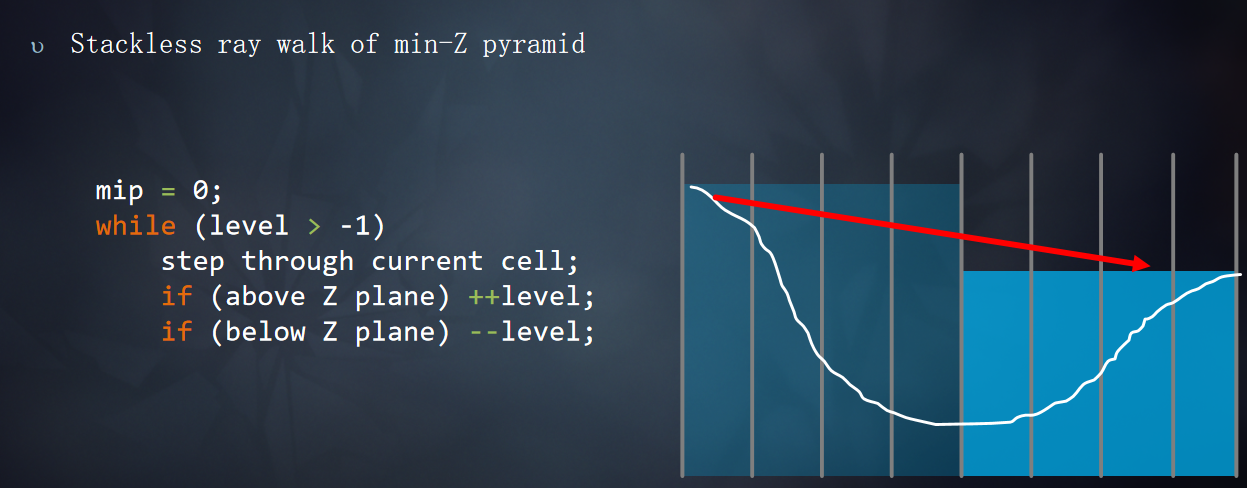
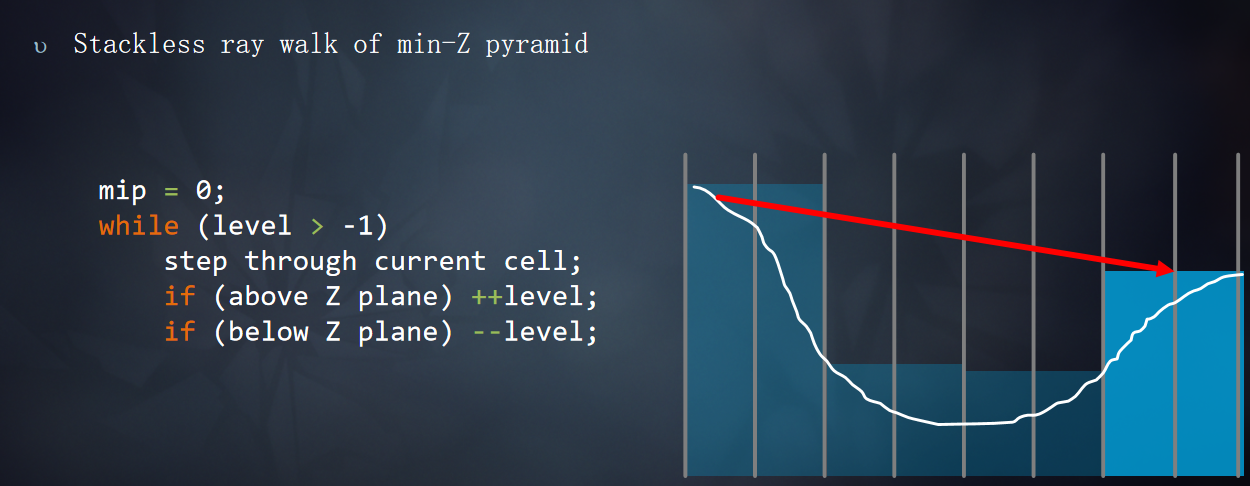
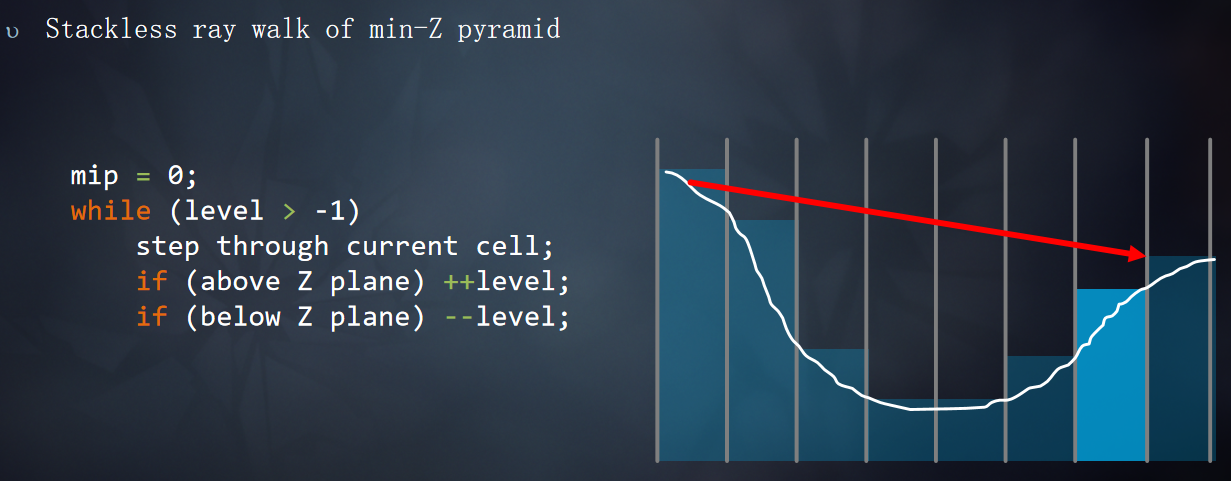
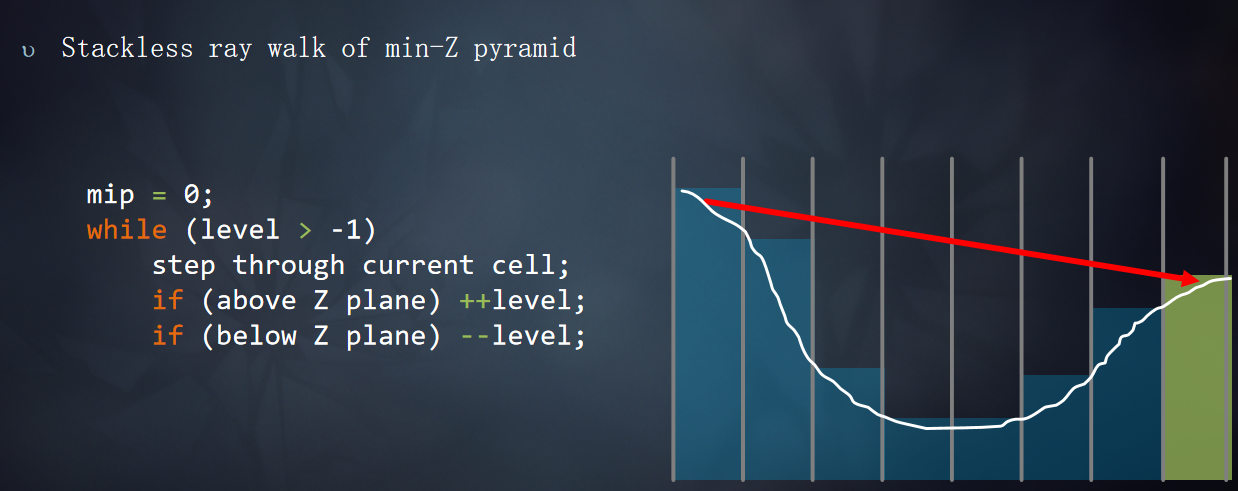
在正式Tracing开始之前需要对光线步进的范围进行限制(tMax),限制t的范围,使得t的范围不会超出屏幕,根据是否反射SkyBox上的像素调整Bounds.z的范围。
如果最近的交叉点是单元格的墙壁,切换到更粗粒度的MIP,并推进射线。mip++
如果最近的交叉点位于Z plane之下,切换到更细粒度的MIP,并推进射线。mip--
如果最近的交叉点位于Z plane之上,切换到更细粒度的MIP,不推进射线。mip--
光线步进的过程:
[numthreads(NR_THREADS,NR_THREADS,1)]
void ScreenSpaceReflectionsTracing(uint3 dispatchThreadId : SV_DispatchThreadID, uint2 groupThreadId : SV_GroupThreadID, uint groupId : SV_GroupID)
{
...
float bias = (1.0f - 0.001f * rcp(max(dot(N, V), FLT_EPS)));
positionWS = cameraPositionWS + (positionWS - cameraPositionWS) * bias;
deviceDepth = ComputeNormalizedDeviceCoordinatesWithZ(positionWS, UNITY_MATRIX_VP).z;
float3 rayOrigin = float3(positionSS + 0.5, deviceDepth);
float3 reflPosWS = positionWS + R;
float3 reflPosNDC = ComputeNormalizedDeviceCoordinatesWithZ(reflPosWS,UNITY_MATRIX_VP);
float3 reflPosSS = float3(reflPosNDC.xy * _ScreenSize.xy, reflPosNDC.z);
float3 rayDir = reflPosSS - rayOrigin;
float3 rcpRayDir = rcp(rayDir);
int2 rayStep = int2(rcpRayDir.x >= 0 ? 1 : 0,
rcpRayDir.y >= 0 ? 1 : 0);
float3 raySign = float3(rcpRayDir.x >= 0 ? 1 : -1,
rcpRayDir.y >= 0 ? 1 : -1,
rcpRayDir.z >= 0 ? 1 : -1);
...
//计算光线步进的范围tMax
float tMax;
{
const float halfTexel = 0.5f;
float3 bounds;
bounds.x = (rcpRayDir.x >= 0) ? _ScreenSize.x - halfTexel : halfTexel;
bounds.y = (rcpRayDir.y >= 0) ? _ScreenSize.y - halfTexel : halfTexel;
float maxDepth = (_SsrReflectsSky != 0) ? -0.00000024 : 0.00000024;
bounds.z = (rcpRayDir.z >= 0) ? 1 : maxDepth;
float3 dist = bounds * rcpRayDir - (rayOrigin * rcpRayDir);
tMax = Min3(dist.x, dist.y, dist.z);
}
const int maxMipLevel = min(_SsrDepthPyramidMaxMip, 14);
//
//Still has question at starting ray marching from the next texel
//
// Start ray marching from the next texel to avoid self-intersections.
float t;
{
//dist.x=1/(2*(reflpos.x-positionss.x)-1)
//dist.y=1/(2*(reflpos.y-positionss.y)-1)
// -1即为从下一个Texel开始RayTracing?
// 'rayOrigin' is the exact texel center.
float2 dist = abs(0.5 * rcpRayDir.xy);
t = min(dist.x, dist.y);
}
float3 rayPos;
int mipLevel = 0;
int iterCount = 0;
bool hit = false;
bool miss = false;
bool belowMip0 = false; // This value is set prior to entering the cell
//尚未Hit也尚未Miss时才继续循环
//t在tMax范围内(一定迭代次数)进行循环
while (!(hit || miss) && (t <= tMax) && (iterCount < _SsrIterLimit))
{
rayPos = rayOrigin + t * rayDir;
#define SSR_TRACE_EPS 0.000488281f // 2^-11, should be good up to 4K
// Ray position often ends up on the edge. To determine (and look up) the right cell,
// we need to bias the position by a small epsilon in the direction of the ray.
float2 sgnEdgeDist = round(rayPos.xy) - rayPos.xy;
float2 satEdgeDist = clamp(raySign.xy * sgnEdgeDist + SSR_TRACE_EPS, 0, SSR_TRACE_EPS);
rayPos.xy += raySign.xy * satEdgeDist;
int2 mipCoord = (int2)rayPos.xy >> mipLevel;
int2 mipOffset = _DepthPyramidMipLevelOffsets[mipLevel];
// Bounds define 4 faces of a cube:
// 2 walls in front of the ray, and a floor and a base below it.
float4 bounds;
bounds.xy = (mipCoord + rayStep) << mipLevel;
bounds.z = LOAD_TEXTURE2D(_CameraDepthTexture, mipOffset + mipCoord).r;
// 拉大当前Ray所在的Hierarchical Depth Bound.z,让部分Tracing结果原本是Miss的Ray变成Hit
// We define the depth of the base as the depth value as:
// b = DeviceDepth((1 + thickness) * LinearDepth(d))
// b = ((f - n) * d + n * (1 - (1 + thickness))) / ((f - n) * (1 + thickness))
// b = ((f - n) * d - n * thickness) / ((f - n) * (1 + thickness))
// b = d / (1 + thickness) - n / (f - n) * (thickness / (1 + thickness))
// b = d * k_s + k_b
bounds.w = bounds.z * _SsrThicknessScale + _SsrThicknessBias;
float4 dist = bounds * rcpRayDir.xyzz - (rayOrigin.xyzz * rcpRayDir.xyzz);
float distWall = min(dist.x, dist.y);
float distFloor = dist.z;
float distBase = dist.w;
// Note: 'rayPos' given by 't' can correspond to one of several depth values:
// - above or exactly on the floor
// - inside the floor (between the floor and the base)
// - below the base
// #if 0
// bool belowFloor = (raySign.z * (t - distFloor)) < 0;
// bool aboveBase = (raySign.z * (t - distBase )) >= 0;
// #else
bool belowFloor = rayPos.z < bounds.z;
bool aboveBase = rayPos.z >= bounds.w;
// #endif
bool insideFloor = belowFloor && aboveBase;
bool hitFloor = (t <= distFloor) && (distFloor <= distWall);
// Game rules:
// *如果最近的交叉点是单元格的壁,切换到更粗的MIP,并推进射线。mip++
// *如果最近的交叉点与下面的高度相交,切换到更精细的MIP,并推进射线。mip--
// *如果最近的交叉点与上面的高度相交,切换到更精细的MIP,不推进射线。mip--
// Victory conditions:
// * See below. Do NOT reorder the statements!
//#ifdef SSR_TRACE_BEHIND_OBJECTS
miss = belowMip0 && insideFloor;
//#else
//miss = belowMip0;
//#endif
hit = (mipLevel == 0) && (hitFloor || insideFloor); //Mip=0时最精细的时候,与Floor相交才判定是Hit
belowMip0 = (mipLevel == 0) && belowFloor;
// 'distFloor' can be smaller than the current distance 't'.
// We can also safely ignore 'distBase'.
// If we hit the floor, it's always safe to jump there.
// If we are at (mipLevel != 0) and we are below the floor, we should not move.
t = hitFloor ? distFloor : (((mipLevel != 0) && belowFloor) ? t : distWall);
rayPos.z = bounds.z; // Retain the depth of the potential intersection
// Warning: both rays towards the eye, and tracing behind objects has linear
// rather than logarithmic complexity! This is due to the fact that we only store
// the maximum value of depth, and not the min-max.
mipLevel += (hitFloor || belowFloor || rayTowardsEye) ? -1 : 1;
mipLevel = clamp(mipLevel, 0, maxMipLevel);
iterCount++;
}
miss = miss || ((_SsrReflectsSky == 0) && (rayPos.z == 0));
hit = hit && !miss;
if (hit)
{
// Note that we are using 'rayPos' from the penultimate iteration, rather than
// recompute it using the last value of 't', which would result in an overshoot.
// It also needs to be precisely at the center of the pixel to avoid artifacts.
float2 hitPositionNDC = floor(rayPos.xy) * _ScreenSize.zw + (0.5 * _ScreenSize.zw); // Should we precompute the half-texel bias? We seem to use it a lot.
_SsrHitPointTexture[(positionSS)] = hitPositionNDC.xy;
}
}
分帧Accumulate
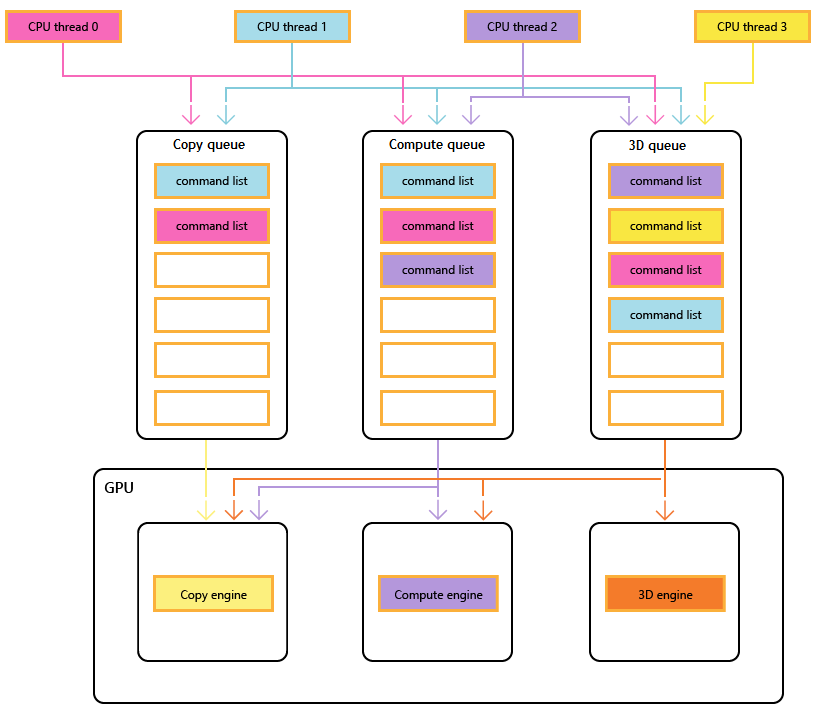
由于全屏RayTracing消耗还是挺大的,所以我第一时间想到直接试着将大表哥渲染体积云的的棋盘格分帧优化思路拿来试试看,把RayMarch的计算压力分散到四帧中。
Reprojection
Reprojection这一步主要是用MotionVector重投影得到hitPositionNDC对应的像素在上一帧的位置(prevFrameNDC),
然后就能利用上一帧的_ColorPyramidTexture得到当前帧的反射结果。
这样最大好处就是,能够让SSR的计算能够跟加入到AsyncCompute当中,提高GPU的利用率。https://zhuanlan.zhihu.com/p/425830762
有关于MotionVector的生成可以看我上一篇文章:https://www.cnblogs.com/OneStargazer/p/18139671
// Tweak parameters.
// #define DEBUG
#define SSR_TRACE_BEHIND_OBJECTS
#define SSR_TRACE_TOWARDS_EYE
#ifndef SSR_APPROX
#define SAMPLES_VNDF
#endif
#define SSR_TRACE_EPS 0.000488281f // 2^-11, should be good up to 4K
#define MIN_GGX_ROUGHNESS 0.00001f
#define MAX_GGX_ROUGHNESS 0.99999f
Texture2D<uint2> _StencilTexture;
RW_TEXTURE2D(float2, _SsrHitPointTexture);
RW_TEXTURE2D(float4, _SsrAccumPrev);
RW_TEXTURE2D(float4, _SsrLightingTextureRW);
RW_TEXTURE2D(float4, _SSRAccumTexture);
StructuredBuffer<int2> _DepthPyramidMipLevelOffsets;
StructuredBuffer<uint> _CoarseStencilBuffer;
uint2 GetPositionSS(uint2 dispatchThreadId, uint2 groupThreadId)
{
const uint2 offset[4] = {uint2(0, 1), uint2(1, 1), uint2(1, 0), uint2(0, 0)};
uint indexOffset = groupThreadId.x % 2 == 1 || groupThreadId.y % 2 == 1 ? 1 : 0;
if (groupThreadId.x % 2 == 1 && groupThreadId.y % 2 == 1)
indexOffset = 0;
indexOffset = (ssrFrameIndex + indexOffset) % 4;
return dispatchThreadId.xy * 2 + offset[indexOffset];
}
[numthreads(8,8,1)]
void ScreenSpaceReflectionsReprojection(uint3 dispatchThreadId : SV_DispatchThreadID, uint2 groupThreadId : SV_GroupThreadID, uint groupId : SV_GroupID)
{
const uint2 positionSS = GetPositionSS(dispatchThreadId.xy, groupThreadId);
float3 N;
float perceptualRoughness;
GetNormalAndPerceptualRoughness(positionSS, N, perceptualRoughness);
float2 hitPositionNDC = LOAD_TEXTURE2D(_SsrHitPointTexture, positionSS).xy;
if (max(hitPositionNDC.x, hitPositionNDC.y) == 0)
return;
// TODO: this texture is sparse (mostly black). Can we avoid reading every texel? How about using Hi-S?
float2 motionVectorNDC;
float4 motionVectorBufferValue = SAMPLE_TEXTURE2D_LOD(_CameraMotionVectorsTexture, s_linear_clamp_sampler, min(hitPositionNDC, 1.0f - 0.5f * _ScreenSize.zw) * _RTHandleScale.xy, 0);
DecodeMotionVector(motionVectorBufferValue, motionVectorNDC);
float2 prevFrameNDC = hitPositionNDC - motionVectorNDC;
float2 prevFrameUV = prevFrameNDC * _ColorPyramidUvScaleAndLimitPrevFrame.xy;
// TODO: optimize with max().
// if ((prevFrameUV.x < 0) || (prevFrameUV.x > _ColorPyramidUvScaleAndLimitPrevFrame.z) ||
// (prevFrameUV.y < 0) || (prevFrameUV.y > _ColorPyramidUvScaleAndLimitPrevFrame.w))
if (max(prevFrameUV.x, prevFrameUV.y) < 0 ||
(prevFrameUV.x > _ColorPyramidUvScaleAndLimitPrevFrame.z) ||
(prevFrameUV.y > _ColorPyramidUvScaleAndLimitPrevFrame.w)
)
{
// Off-Screen.
return;
}
float opacity = EdgeOfScreenFade(prevFrameNDC, _SsrEdgeFadeRcpLength)
* PerceptualRoughnessFade(perceptualRoughness, _SsrRoughnessFadeRcpLength, _SsrRoughnessFadeEndTimesRcpLength);
// TODO: filtering is quite awful. Needs to be non-Gaussian, bilateral and anisotropic.
float mipLevel = lerp(0, _SsrColorPyramidMaxMip, perceptualRoughness);
// Note that the color pyramid uses it's own viewport scale, since it lives on the camera.
float3 color = SAMPLE_TEXTURE2D_LOD(_ColorPyramidTexture, s_trilinear_clamp_sampler, prevFrameUV, mipLevel).rgb;
// Disable SSR for negative, infinite and NaN history values.
uint3 intCol = asuint(color);
bool isPosFin = Max3(intCol.r, intCol.g, intCol.b) < 0x7F800000;
color = isPosFin ? color : 0;
opacity = isPosFin ? opacity : 0;
_SSRAccumTexture[positionSS] = float4(color, 1.0f) * opacity;
}
Accumulate
在上面通过Reprojection得到了当前帧的SSR的1/4结果(_SSRAccumTexture),自然需要另外的3/4将其补齐。
另外的3/4就从历史帧(_SsrAccumPrev)当中去读取获得。
最终把累积的结果输出到_SsrLightingTextureRW之中。
为了消除移动过大产生的伪影,读取MotionVector,如果当前像素的MotionVector过大,就直接将其截断。
[numthreads(8,8,1)]
void ScreenSpaceReflectionsAccumulate(uint3 dispatchThreadId : SV_DispatchThreadID)
{
uint2 positionSS = dispatchThreadId.xy;
float2 hitPositionNDC = LOAD_TEXTURE2D(_SsrHitPointTexture, positionSS).xy;
//(x,y) current frame (z,w) last frame (this is only used for buffered RTHandle Systems)
float2 prevHistoryScale = _RTHandleScaleHistory.zw / _RTHandleScaleHistory.xy;
float4 original = _SSRAccumTexture[(positionSS)];
float4 previous = _SsrAccumPrev[(positionSS * prevHistoryScale + 0.5f / prevHistoryScale)];
float2 motionVectorNDC;
float4 motionVectorBufferValue = SAMPLE_TEXTURE2D_LOD(_CameraMotionVectorsTexture, s_linear_clamp_sampler, min(hitPositionNDC, 1.0f - 0.5f * _ScreenSize.zw) * _RTHandleScale.xy, 0);
DecodeMotionVector(motionVectorBufferValue, motionVectorNDC);
float speedDst = length(motionVectorNDC);
float2 motionVectorCenterNDC;
float2 positionNDC = positionSS * _ScreenSize.zw + (0.5 * _ScreenSize.zw);
float4 motionVectorCenterBufferValue = SAMPLE_TEXTURE2D_LOD(_CameraMotionVectorsTexture, s_linear_clamp_sampler, min(positionNDC, 1.0f - 0.5f * _ScreenSize.zw) * _RTHandleScale.xy, 0);
DecodeMotionVector(motionVectorCenterBufferValue, motionVectorCenterNDC);
float speedSrc = length(motionVectorCenterNDC);
float speed = saturate((speedDst + speedSrc) * 128.0f);
float coefExpAvg = lerp(_SsrAccumulationAmount, 1.0f, speed);
float4 result = lerp(previous, original, coefExpAvg);
uint3 intCol = asuint(result.rgb);
bool isPosFin = Max3(intCol.r, intCol.g, intCol.b) < 0x7F800000;
result.rgb = isPosFin ? result.rgb : 0;
result.w = isPosFin ? result.w : 0;
_SsrLightingTextureRW[positionSS] = result;
_SSRAccumTexture[positionSS] = result;
}
Indirect Buffer
仿造之前提到Material Feature Flag的流程,可以通过提前计算Tile内的所有像素是否适合发射射线(NeedKillRay评估当前像素位置的粗糙度以及NdotV)就能够得到Dispatch SSR的Indirect Buffer.
需要留意的是,由于分帧SSR减少了1/4线程的关系,使得原本一个16*16的Tile需要添加的线程组数量4*8*8的变成1*8*8
RWBuffer<uint> g_SSRDispatchIndirectBuffer : register( u0 );
RWStructuredBuffer<uint> g_SSRTileList;
float _SsrRoughnessFadeEnd;
groupshared uint ldsNeedSSR;
bool killRay(uint2 positionSS, float deviceDepth)
{
float4 inGBuffer1 = LOAD_TEXTURE2D(_GBufferTexture1, positionSS);
NormalData normalData;
ZERO_INITIALIZE(NormalData, normalData);
DecodeFromNormalBuffer(inGBuffer1, normalData);
float2 positionNDC = positionSS * _ScreenSize.zw + (0.5 * _ScreenSize.zw); // Should we precompute the half-texel bias? We seem to use it a lot.
float3 positionWS = ComputeWorldSpacePosition(positionNDC, deviceDepth, UNITY_MATRIX_I_VP); // Jittered
float3 V = GetWorldSpaceNormalizeViewDir(positionWS);
float3 N = normalData.normalWS;
if (normalData.perceptualRoughness > _SsrRoughnessFadeEnd || dot(N, V) <= 0)
return false;
return true;
}
[numthreads(NR_THREADS, 1, 1)]
void BuildMaterialFlag(uint3 dispatchThreadId : SV_DispatchThreadID, uint threadID : SV_GroupIndex, uint3 u3GroupID : SV_GroupID)
{
uint2 tileIDX = u3GroupID.xy;
uint iWidth = g_viDimensions.x;
uint iHeight = g_viDimensions.y;
uint nrTilesX = (iWidth + (TILE_SIZE_FPTL - 1)) / TILE_SIZE_FPTL;
uint nrTilesY = (iHeight + (TILE_SIZE_FPTL - 1)) / TILE_SIZE_FPTL;
// 16 * 4 = 64. We process data by group of 4 pixel
uint2 viTilLL = 16 * tileIDX;
float2 invScreenSize = float2(1.0 / iWidth, 1.0 / iHeight);
if (threadID == 0)
{
ldsFeatureFlags = 0;
ldsNeedSSR = false;
}
GroupMemoryBarrierWithGroupSync();
uint materialFeatureFlags = g_BaseFeatureFlags; // Contain all lightFeatures or 0 (depends if we enable light classification or not)
bool tileNeedSSR = false;
UNITY_UNROLL
for (int i = 0; i < 4; i++)
{
int idx = i * NR_THREADS + threadID;
uint2 positionSS = min(uint2(viTilLL.x + (idx & 0xf), viTilLL.y + (idx >> 4)), uint2(iWidth - 1, iHeight - 1));
float depth = FetchDepth(positionSS);
if (depth < VIEWPORT_SCALE_Z)
materialFeatureFlags |= MaterialFeatureFlagsFromGBuffer(positionSS);
tileNeedSSR = tileNeedSSR || killRay(positionSS, depth);
}
InterlockedOr(ldsFeatureFlags, materialFeatureFlags); //TODO: driver might optimize this or we might have to do a manual reduction
InterlockedOr(ldsNeedSSR, tileNeedSSR);
GroupMemoryBarrierWithGroupSync();
if (threadID == 0)
{
uint tileIndex = tileIDX.y * nrTilesX + tileIDX.x;
// TODO: shouldn't this always enabled?
#if defined(UNITY_STEREO_INSTANCING_ENABLED)
tileIndex += unity_StereoEyeIndex * nrTilesX * nrTilesY;
#endif
g_TileFeatureFlags[tileIndex] |= ldsFeatureFlags;
if (materialFeatureFlags != g_BaseFeatureFlags && ldsNeedSSR)
{
const uint unity_StereoEyeIndex = 0;
const uint _XRViewCount = 1;
uint tileOffset;
uint prevGroupCnt;
InterlockedAdd(g_SSRDispatchIndirectBuffer[0], 1, prevGroupCnt);
tileOffset = prevGroupCnt; // 1x 8x8 groups per a 16x16 tile
// uint tileY = (dispatchThreadId.x + 0.5f) / (float)g_NumTilesX; // Integer division is extremely expensive, so we better avoid it
// uint tileX = dispatchThreadId.x - tileY * g_NumTilesX;
//
//
uint tileY = tileIDX.y;
uint tileX = tileIDX.x;
// See LightDefinitions class in LightLoop.cs
uint tileIndex = (unity_StereoEyeIndex << TILE_INDEX_SHIFT_EYE) | (tileY << TILE_INDEX_SHIFT_Y) | (tileX << TILE_INDEX_SHIFT_X);
// For g_TileList each VR eye is interlaced instead of one eye and then the other. Thus why we use _XRViewCount here
g_SSRTileList[tileOffset] = tileIndex;
}
}
}
Pipeline Code参考
SSR计算//SSR
TextureHandle RenderSSR(RenderGraph renderGraph,
HQCamera hqCamera,
ref PrepassOutput prepassOutput,
ref BuildGPULightListOutput buildGPULightListOutput,
Texture skyTexture,
bool transparent = false)
{
void UpdateSSRConstantBuffer(HQCamera camera, ScreenSpaceReflection settings, ref ShaderVariablesScreenSpaceReflection cb)
{
float n = camera.camera.nearClipPlane;
float f = camera.camera.farClipPlane;
float thickness = settings.depthBufferThickness.value;
cb._SsrThicknessScale = 1.0f / (1.0f + thickness);
cb._SsrThicknessBias = -n / (f - n) * (thickness * cb._SsrThicknessScale);
cb._SsrIterLimit = settings.RayMaxIterations;
cb._SsrReflectsSky = 1;
cb._SsrStencilBit = 1 << 3; //(int)StencilUsage.TraceReflectionRay;
float roughnessFadeStart = 1 - settings.smoothnessFadeStart;
cb._SsrRoughnessFadeEnd = 1 - settings.m_MinSmoothness.value;
float roughnessFadeLength = cb._SsrRoughnessFadeEnd - roughnessFadeStart;
cb._SsrRoughnessFadeEndTimesRcpLength = (roughnessFadeLength != 0) ? (cb._SsrRoughnessFadeEnd * (1.0f / roughnessFadeLength)) : 1;
cb._SsrRoughnessFadeRcpLength = (roughnessFadeLength != 0) ? (1.0f / roughnessFadeLength) : 0;
cb._SsrEdgeFadeRcpLength = Mathf.Min(1.0f / settings.screenFadeDistance.value, float.MaxValue);
cb._ColorPyramidUvScaleAndLimitPrevFrame =
HQUtils.ComputeViewportScaleAndLimit(camera.historyRTHandleProperties.previousViewportSize, camera.historyRTHandleProperties.previousRenderTargetSize);
cb._SsrColorPyramidMaxMip = camera.colorPyramidHistoryMipCount - 1;
cb._SsrDepthPyramidMaxMip = camera.DepthBufferMipChainInfo.mipLevelCount - 1;
if (camera.isFirstFrame || camera.cameraFrameIndex <= 3)
cb._SsrAccumulationAmount = 1.0f;
else
cb._SsrAccumulationAmount = Mathf.Pow(2, Mathf.Lerp(0.0f, -7.0f, settings.accumulationFactor.value));
cb.ssrFrameIndex = camera.cameraFrameIndex % 4;
}
if (hqCamera.camera.cameraType == CameraType.Preview)
return renderGraph.defaultResources.blackTextureXR;
RTHandle colorPyramidRT = hqCamera.GetPreviousFrameHistoryRT((int) HQCameraHistoryRTType.ColorBufferMipChain);
if (colorPyramidRT == null)
return renderGraph.defaultResources.blackTextureXR;
RTHandle depthPyramidRT = hqCamera.GetCurrentFrameHistoryRT((int) HQCameraHistoryRTType.DepthPyramid);
using (var builder = renderGraph.AddRenderPass<RenderSSRPassData>("Render SSR", out var passData))
{
passData.screenSpaceReflectionsCS = m_ScreenSpaceReflectionsCS;
passData.tracingKernel = m_SsrTracingKernel;
passData.reprojectionKernel = m_SsrReprojectionKernel;
passData.accumulateKernel = m_SsrAccumulateKernel;
passData.width = hqCamera.actualWidth;
passData.height = hqCamera.actualHeight;
passData.viewCount = hqCamera.viewCount;
int w = hqCamera.actualWidth;
int h = hqCamera.actualHeight;
int numTilesX = (w + 15) / 16;
int numTilesY = (h + 15) / 16;
int numTiles = numTilesX * numTilesY;
UpdateSSRConstantBuffer(hqCamera, screenSpaceReflection, ref passData.cb);
hqCamera.DepthBufferMipChainInfo.GetOffsetBufferData(m_DepthPyramidMipLevelOffsetsBuffer);
passData.offsetBufferData = builder.ReadComputeBuffer(renderGraph.ImportComputeBuffer(m_DepthPyramidMipLevelOffsetsBuffer));
passData.ssrIndirectBuffer = builder.ReadComputeBuffer(buildGPULightListOutput.SSRDispatchIndirectBuffer);
passData.ssrTileIndexBuffer = builder.ReadComputeBuffer(buildGPULightListOutput.SSRTileList);
passData.colorPyramid = builder.ReadTexture(renderGraph.ImportTexture(colorPyramidRT));
passData.depthPyramid = builder.ReadTexture(renderGraph.ImportTexture(depthPyramidRT));
passData.normalBuffer = builder.ReadTexture(prepassOutput.normalBuffer);
passData.stencilBuffer = builder.ReadTexture(prepassOutput.depthBuffer);
passData.motionVectorsBuffer = builder.ReadTexture(prepassOutput.motionVectorsBuffer);
passData.hitPointsTexture = builder.CreateTransientTexture(new TextureDesc(Vector2.one, true, false)
{
colorFormat = GraphicsFormat.R16G16_UNorm, clearBuffer = true, clearColor = Color.clear, enableRandomWrite = true,
name = transparent ? "SSR_Hit_Point_Texture_Trans" : "SSR_Hit_Point_Texture"
});
passData.lightingTexture = builder.WriteTexture(renderGraph.CreateTexture(new TextureDesc(Vector2.one, false, false)
{colorFormat = GraphicsFormat.R16G16B16A16_SFloat, clearBuffer = true, clearColor = Color.clear, enableRandomWrite = true, name = "SSR_Lighting_Texture"}));
passData.ssrAccum = builder.WriteTexture(renderGraph.ImportTexture(hqCamera.GetCurrentFrameHistoryRT((int) HQCameraHistoryRTType.ScreenSpaceReflectionAccumulation)));
passData.ssrAccumPrev = builder.WriteTexture(renderGraph.ImportTexture(hqCamera.GetPreviousFrameHistoryRT((int) HQCameraHistoryRTType.ScreenSpaceReflectionAccumulation)));
passData.validColorPyramid = hqCamera.cameraFrameIndex > 1;
passData.ssrUseIndirect = pipelineQualitySetting.renderPathSetting.indirectSSR;
passData.tileListOffset = 0 * numTiles;
CoreUtils.SetKeyword(m_ScreenSpaceReflectionsCS, "USE_INDIRECT", passData.ssrUseIndirect);
builder.AllowPassCulling(false);
builder.SetRenderFunc((RenderSSRPassData data, RenderGraphContext context) =>
{
CommandBuffer cmd = context.cmd;
ComputeShader cs = data.screenSpaceReflectionsCS;
//
using (new ProfilingScope(cmd, ProfilingSampler.Get(ProfileIDList.SSRTraing)))
{
ConstantBuffer.Push(cmd, data.cb, cs, ShaderIDs._ShaderVariablesScreenSpaceReflection);
cmd.SetComputeTextureParam(cs, data.tracingKernel, ShaderIDs._CameraDepthTexture, data.depthPyramid);
cmd.SetComputeTextureParam(cs, data.tracingKernel, ShaderIDs._NormalBufferTexture, data.normalBuffer);
cmd.SetComputeTextureParam(cs, data.tracingKernel, ShaderIDs._SsrHitPointTexture, data.hitPointsTexture);
//uint GetStencilValue(uint2 stencilBufferVal)=>stencilBufferVal.y
cmd.SetComputeTextureParam(cs, data.tracingKernel, ShaderIDs._StencilTexture, data.stencilBuffer, 0, RenderTextureSubElement.Stencil);
cmd.SetComputeBufferParam(cs, data.tracingKernel, ShaderIDs._DepthPyramidMipLevelOffsets, data.offsetBufferData);
if (data.ssrUseIndirect)
{
cmd.SetComputeBufferParam(cs, data.tracingKernel, ShaderIDs.g_TileList, data.ssrTileIndexBuffer);
cmd.DispatchCompute(cs, data.tracingKernel, data.ssrIndirectBuffer, 0);
// cmd.RequestAsyncReadback(data.ssrIndirectBuffer, (request =>
// {
// var data = request.GetData<uint>();
// foreach (var tileCount in data)
// {
// Debug.Log(tileCount);
// }
// }));
}
else
{
cmd.DispatchCompute(cs, data.tracingKernel, HQUtils.DivRoundUp(data.width / 2, 8), HQUtils.DivRoundUp(data.height / 2, 8), data.viewCount);
}
}
using (new ProfilingScope(cmd, ProfilingSampler.Get(ProfileIDList.SSRReprojection)))
{
CoreUtils.SetRenderTarget(cmd, data.ssrAccum, ClearFlag.Color, Color.clear);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._CameraDepthTexture, data.depthPyramid);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._NormalBufferTexture, data.normalBuffer);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._SsrHitPointTexture, data.hitPointsTexture);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._CameraMotionVectorsTexture, data.motionVectorsBuffer);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._ColorPyramidTexture, data.colorPyramid);
//uint GetStencilValue(uint2 stencilBufferVal)=>stencilBufferVal.y
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._StencilTexture, data.stencilBuffer, 0, RenderTextureSubElement.Stencil);
cmd.SetComputeBufferParam(cs, data.reprojectionKernel, ShaderIDs._DepthPyramidMipLevelOffsets, data.offsetBufferData);
cmd.SetComputeTextureParam(cs, data.reprojectionKernel, ShaderIDs._SSRAccumTexture, data.ssrAccum);
cmd.DispatchCompute(cs, data.reprojectionKernel, HQUtils.DivRoundUp(data.width / 2, 8), HQUtils.DivRoundUp(data.height / 2, 8), data.viewCount);
}
if (!data.validColorPyramid)
{
CoreUtils.SetRenderTarget(cmd, data.ssrAccum, ClearFlag.Color, Color.clear);
CoreUtils.SetRenderTarget(cmd, data.ssrAccumPrev, ClearFlag.Color, Color.clear);
}
using (new ProfilingScope(cmd, ProfilingSampler.Get(ProfileIDList.SSRAccumulate)))
{
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._CameraDepthTexture, data.depthPyramid);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._NormalBufferTexture, data.normalBuffer);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._ColorPyramidTexture, data.colorPyramid);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._SsrHitPointTexture, data.hitPointsTexture);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._SSRAccumTexture, data.ssrAccum);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._SsrLightingTextureRW, data.lightingTexture);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._SsrAccumPrev, data.ssrAccumPrev);
cmd.SetComputeTextureParam(cs, data.accumulateKernel, ShaderIDs._CameraMotionVectorsTexture, data.motionVectorsBuffer);
cmd.DispatchCompute(cs, data.accumulateKernel, HQUtils.DivRoundUp(data.width, 8), HQUtils.DivRoundUp(data.height, 8), data.viewCount);
}
});
return passData.lightingTexture;
}
}
Indirect Buffer
static void BuildDispatchIndirectArguments(BuildGPULightListPassData data, bool tileFlagsWritten, CommandBuffer cmd)
{
using (new ProfilingScope(cmd, ProfilingSampler.Get(ProfileIDList.BuildDispatchIndirectArguments)))
{
if (!data.useIndirectDeferred)
return;
ConstantBuffer.Push(cmd, data.lightListCB, data.clearDispatchIndirectShader, ShaderIDs.ShaderVariablesLightList);
cmd.SetComputeBufferParam(data.clearDispatchIndirectShader, s_ClearDispatchIndirectKernel, ShaderIDs.g_DispatchIndirectBuffer, data.output.dispatchIndirectBuffer);
cmd.SetComputeBufferParam(data.clearDispatchIndirectShader, s_ClearDispatchIndirectKernel, ShaderIDs.g_SSRDispatchIndirectBuffer, data.output.SSRDispatchIndirectBuffer);
cmd.DispatchCompute(data.clearDispatchIndirectShader, s_ClearDispatchIndirectKernel, 1, 1, 1);
if (data.computeMaterialFlag)
{
ComputeShader buildMaterialFlagsShader = data.buildMaterialFlagsShader;
ConstantBuffer.Push(cmd, data.lightListCB, buildMaterialFlagsShader, ShaderIDs.ShaderVariablesLightList);
cmd.SetComputeBufferParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs.g_TileFeatureFlags, data.output.tileFeatureFlags);
cmd.SetComputeBufferParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs.g_SSRDispatchIndirectBuffer, data.output.SSRDispatchIndirectBuffer);
cmd.SetComputeBufferParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs.g_SSRTileList, data.output.SSRTileList);
cmd.SetComputeFloatParam(buildMaterialFlagsShader, "_SsrRoughnessFadeEnd", data.ssrRoughnessFadeEnd);
cmd.SetComputeTextureParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs._GBufferTexture[2], data.gBufferMaterialFlagTexture);
cmd.SetComputeTextureParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs._GBufferTexture[1], data.gBufferNormalDataTexture);
cmd.SetComputeTextureParam(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, ShaderIDs.g_depth_tex, data.depthBuffer);
cmd.DispatchCompute(buildMaterialFlagsShader, s_BuildMaterialFlagKernel, data.numTilesFPTLX, data.numTilesFPTLY, data.viewCount);
}
const int k_ThreadGroupOptimalSize = 64;
// add tiles to indirect buffer
cmd.SetComputeBufferParam(data.buildDispatchIndirectShader, s_BuildIndirectKernel, ShaderIDs.g_DispatchIndirectBuffer, data.output.dispatchIndirectBuffer);
cmd.SetComputeBufferParam(data.buildDispatchIndirectShader, s_BuildIndirectKernel, ShaderIDs.g_TileList, data.output.tileList);
cmd.SetComputeBufferParam(data.buildDispatchIndirectShader, s_BuildIndirectKernel, ShaderIDs.g_TileFeatureFlags, data.output.tileFeatureFlags);
cmd.SetComputeIntParam(data.buildDispatchIndirectShader, ShaderIDs.g_NumTiles, data.numTilesFPTL);
cmd.SetComputeIntParam(data.buildDispatchIndirectShader, ShaderIDs.g_NumTilesX, data.numTilesFPTLX);
// Round on k_ThreadGroupOptimalSize so we have optimal thread for buildDispatchIndirectShader kernel
cmd.DispatchCompute(data.buildDispatchIndirectShader, s_BuildIndirectKernel, (data.numTilesFPTL + k_ThreadGroupOptimalSize - 1) / k_ThreadGroupOptimalSize, 1, data.viewCount);
}
}
private BuildGPULightListOutput BuildGPULightList(RenderGraph renderGraph, HQCamera hqCamera, TileAndClusterData tileAndClusterData,
int directionalLightCount, int totalLightCount,
ref ShaderVariablesLightList constantBuffer,
TextureHandle depthStencilBuffer,
TextureHandle stencilBufferCopy,
ref PrepassOutput prepassOutput
)
{
using (var builder = renderGraph.AddRenderPass<BuildGPULightListPassData>("Build Light List", out var passData, ProfilingSampler.Get(ProfileIDList.BuildLightList)))
{
{
PrepareBuildGPULightListPassData(renderGraph, builder, hqCamera,
tileAndClusterData, ref constantBuffer,
directionalLightCount, totalLightCount,
depthStencilBuffer, stencilBufferCopy, ref prepassOutput,
passData);
builder.SetRenderFunc(
(BuildGPULightListPassData data, RenderGraphContext context) =>
{
bool tileFlagsWritten = false;
{
ClearLightLists(data, context.cmd);
GenerateLightsScreenSpaceAABBs(data, context.cmd);
BigTilePrepass(data, context.cmd);
BuildPerTileLightList(data, ref tileFlagsWritten, context.cmd);
// VoxelLightListGeneration(data, context.cmd);
BuildDispatchIndirectArguments(data, tileFlagsWritten, context.cmd);
}
});
}
return passData.output;
}
}
性能对比

测试的显卡是RTX3080,左边的是Indirect Dispatch的耗时,右边是不用Indirect Dispatch的耗时,快了0.02ms。
如果评估Tile内所有像是否合适发射射线的不加入Roughness以及NdotV的判断,实际上耗时的差距并不会拉得特别大,但是用了Indirect Dispatch之后,耗时会平稳很多(提高了GPU的利用率)。
另外BuildLightList还好也并没有因为新增加的计算(InterlockAdd)而加大了计算的耗时。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号