Unity的Forward+ FPTL光照剔除解析(五)
 这一章是把之前留的关于标量化LightLoop的坑给填了,会涉及到一些关于GPU的硬件知识,标量化变量的好处和途径。
这一章是把之前留的关于标量化LightLoop的坑给填了,会涉及到一些关于GPU的硬件知识,标量化变量的好处和途径。
序言
这一章是把之前留的关于标量化LightLoop的坑给填了,会涉及到一些关于GPU的硬件知识,标量化变量的好处和途径。
WaveFront,Warp,Lane?
首先明确一点Warp是NVIDIA的说法,WaveFront是AMD的说法。为了统一后续都用Wave
Wave是由lane构成,每个lane可以近似当做是thread。
不同硬件上,Wave包含的lane的数量也不一样,
N卡的一个Wave包含32个Lane。
A卡的一个Wave一般包含64个Lane,
RDNA1、2 架构则为可变的32、64,
Adreno 也是 64,
Apple GPU 则为 32,
Intel 则是可变的 8、16、32,实际大小由驱动启发式动态决定。
引用自:https://zhuanlan.zhihu.com/p/469436345
所以在ComputeShader里面,需要根据不同平台选择不同的线程组大小
//Switch.hlsl
#define PLATFORM_LANE_COUNT 32
#ifdef PLATFORM_LANE_COUNT // We can infer the size of a wave. This is currently not possible on non-consoles, so we have to fallback to a sensible default in those cases.
#define NR_THREADS PLATFORM_LANE_COUNT
#else
#define NR_THREADS 64 // default to 64 threads per group on other platforms..
#endif
[numthreads(NR_THREADS, 1, 1)]
void TileLightListGen(uint3 dispatchThreadId : SV_DispatchThreadID, uint threadID : SV_GroupIndex, uint3 u3GroupID : SV_GroupID)
{
...
#if NR_THREADS > PLATFORM_LANE_COUNT
GroupMemoryBarrierWithGroupSync();
#endif
Pixel Shader渲染的时候,Lane的组织的形式一般是2*2(用来计算ddx,ddy)像素构成一个Quad,一个Wave包含多个Quad。
由于这种组织的形式,就容易造成有的线程是对最终渲染是没有任何作用的。
线程组中参与当前指令的线程称为active Thread,而不参与当前指令的线程称为Inactive Thread。
线程处于Inactive状态的原因有很多种,
比如:
比线程组中的其他线程更早退出,选择了不同的分支路径(例如:AlphaTest),
线程数量不是线程组大小的倍数。
引用自:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architecture-notes

我们以为参与绘制的线程数

实际参与绘制的线程数(向往大佬博客园偷的图)
VGPR,SGPR
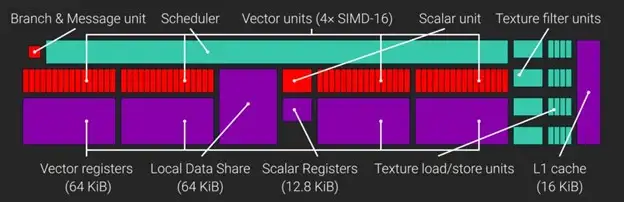
GCN CU的架构
AMD GCN中,一个GCN CU(compute uint)包含4个SIMD,每个SIMD具有32位的VGPR(向量通用寄存器)的64KiB Register File,还有32位SGPR(标量通用寄存器)的12.8KiB Register File。
而CU运行的调度最小的工作单元也被称作Wave。CU中的4个SIMDs中的每一个都可以最多调度10个并发的Wave.
CU可以暂停一个wave,转而执行另一个wave,同时等待内存操作完成。
AMD GPUs能够在单个CU上同时执行两组线程大小为1024的线程组。
为了最大化利用CU的占用,着色计算必需最小化寄存器(VGPR,SGPR)和LDS的使用。
如果shader着色计算中需要的VGPR多于可用的VGPR,会照成SIMD无法无法执行最优数量的wave,
例如一个Shader的线程组由1024个线程组成,每个线程用40个VGPR。40*1024*2=81920个VGPR(远超于CU上可用的65536个VGPR)。
导致1024个线程产生了16个wave,每个wave包含64线程。每个线程平均分布在SIMD中,每个SIMD中只有4个Wave。(4*4*64*40=40960VGPR即160kiB,每个CU有64*4KiB内存,浪费了96KiB[37.5%])
SIMD的最佳占用率的时候最多可以调用10个wave的,这将导致只有40%的占有率,降低了SIMD的利用率。
所以假如一个CU只用来计算一组线程组的运算的时候,CU的资源利用率将会大大降低。
因此,优化VGPR的占用是很有必要的。
引用自:机翻版本:https://zhuanlan.zhihu.com/p/432186478,
原文:https://gpuopen.com/learn/optimizing-gpu-occupancy-resource-usage-large-thread-groups/
Code?
代码呢?怎么判断一个变量是VGPR,还是SGRP的?
向量寄存器(VGPR):用于在wave中线程之间有差异的(diverging)的值。这样的局部变量大多数可能会被存放在VGPRS寄存器中.
标量寄存器(SGPR):保证在一个wave中的线程中具有相同值的值,都将放在SGPR寄存器中。例如:来自常量缓冲区constant Buffer的值。
ex:
cbuffer MyValues
{
float aValue;
};
Texture2D aTexture;
StructuredBuffer aStructuredBuffer;
float4 main(uint2 pixelCoord) : SV_Target
{
// This will be in a SGPR
float s_value = aValue;
// This will be put in VGPRs via a VMEM load as pixelCoord is in VGPRs
float4 v_textureSample = aTexture.Load(pixelCoord);
// This will be put in SGPRs via a SMEM load as 0 is constant.
SomeData s_someData = aStructuredBuffer.Load(0);
// This should be an SALU op (output in SGPR) since both operands are in SGPRs
// (Note, check note [0])
float s_someModifier = s_value + s_someData.someField;
// This will be a VALU (output in VGPR) since one operand is VGPR.
float4 v_finalResult = s_someModifier * v_textureSample;
return v_finalResult;
}
引用自:https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-1/
Scalarize Loop Fetch Light
在之前的LightingLoop里面我们是这么写的,可以看到v_lightIdx是由posInput里的TileIndex计算的。
所以会出现不同线程之间计算出不一样的TileIndex的情况,TileIndex就会被存到VGPR之中。
而后续的获取LightData也会有所差异,所以在一个Warp中,不同TileIndex越多,VGPR的压力也就越大。
//LightingLoop.hlsl
if (featureFlags & LIGHTFEATUREFLAGS_PUNCTUAL)
{
uint lightCount, lightStart;
GetCountAndStart(posInput, LIGHTCATEGORY_PUNCTUAL, lightStart, lightCount);
//先去除掉原本 Scalarize Loop的代码
uint v_lightListOffset = 0;
uint v_lightIdx = lightStart;
while (v_lightListOffset < lightCount)
{
uint v_lightIdx = FetchIndex(lightStart, v_lightListOffset);
//获取LightData
LightData v_lightData = FetchLight(v_lightIdx);
//Lighting
...
}
}

可以看到Scalarized后,这4个线程从总共占用80VGPR,减到了只有20VGPR。
Scalarize的方法
Scalarize需要我们让不同线程之中都读取固定的LightIndex(标量化),才能够让这些不同的Thread后续读取相同的LightData。
读取固定的LightIndex就需要用到Warp Intrinsics的相关指令了。
Warp Intrinsics指令
Warp Intrinsics指令分为几类:查询,投票,广播,规约,
这里就只说下面Scalarize用到的函数。
WaveGetLaneIndex,WaveActiveBallot,WaveActiveAnyTrue,WaveActiveAllTrue,WaveReadLaneFirst,WaveActiveMin
查询
WaveGetLaneCount,返回当前 Wave 中的 Lane 数量,即 Warp Size。
WaveGetLaneIndex,获取当前 Wave 中当前 Lane 的索引,即 LaneID。
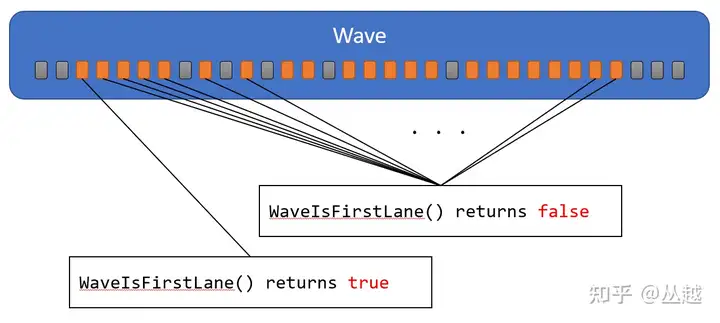
WaveIsFirstLane,判断当前 Lane 是否是索引最小的 Active Lane,如下图所示(橙色为 Avtive lane,灰色是 Inactive Lane):
投票
WaveActiveAnyTrue,表达式在当前 Wave 的任何一个 Active Lane 中为真,则返回真。
WaveActiveAllTrue,表达式在当前 Wave 的所有 Active Lane 中都为真,则返回真。
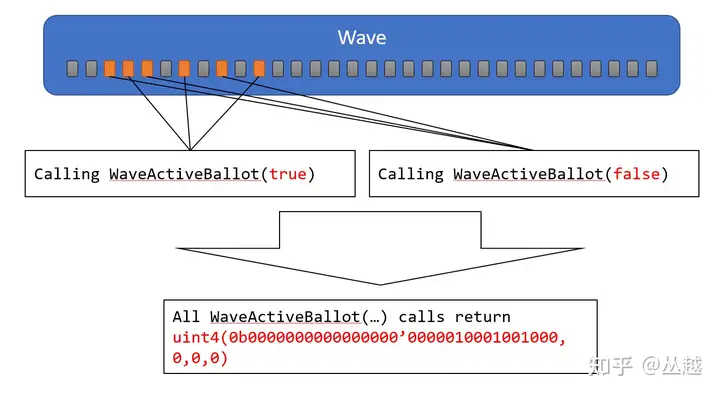
WaveActiveBallot,在当前 Wave 的所有 Active Lane 中评估表达式 bool 结果,并返回 mask。此函数返回 uint4,最多可以表达 128 个 Lane 的 mask bit,但由于不同的硬件 Wave Size 不同,因此大于或等于 WaveGetLaneCount 的 mask 中的 bit 设置为 0,另外要注意的是 Inactive Lane 对应的 mask 中的 bit 设置为 0。如下图所示:
广播
Wave 中所有 Active Lane 之间有效的数据通信,有以下几个指令:
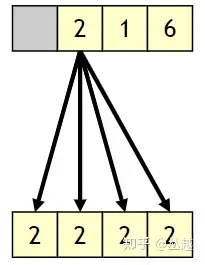
WaveReadLaneFirst,获取最小 Active Lane 索引对应的表达式的值,如下图所示:
规约
执行 Wave 中所有 Active Lane 的指定操作,并将操作结果返回给所有的 Active Lanes,因此这个结果值在整个 Wave 上是 Uniform 的。这种类型指令形式都是 WaveActive<op>(T value),包括 Equal、Add、Mul、Min、Max、And、Or、Xor,例如 WaveActiveAllEqual、WaveActiveMax 等等,在此就不逐一列出。举例如下图所示:
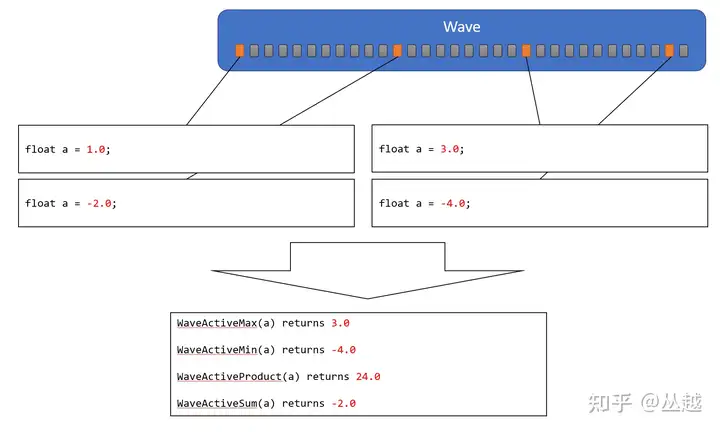
引用自:https://zhuanlan.zhihu.com/p/469436345
Scalarize Lighting
COD的做法
COD的做法主要是把Cell Index(跟Tile Index差不多一个意思)标量化,循环之中只处理与标量化的Cell Index相等的Lane
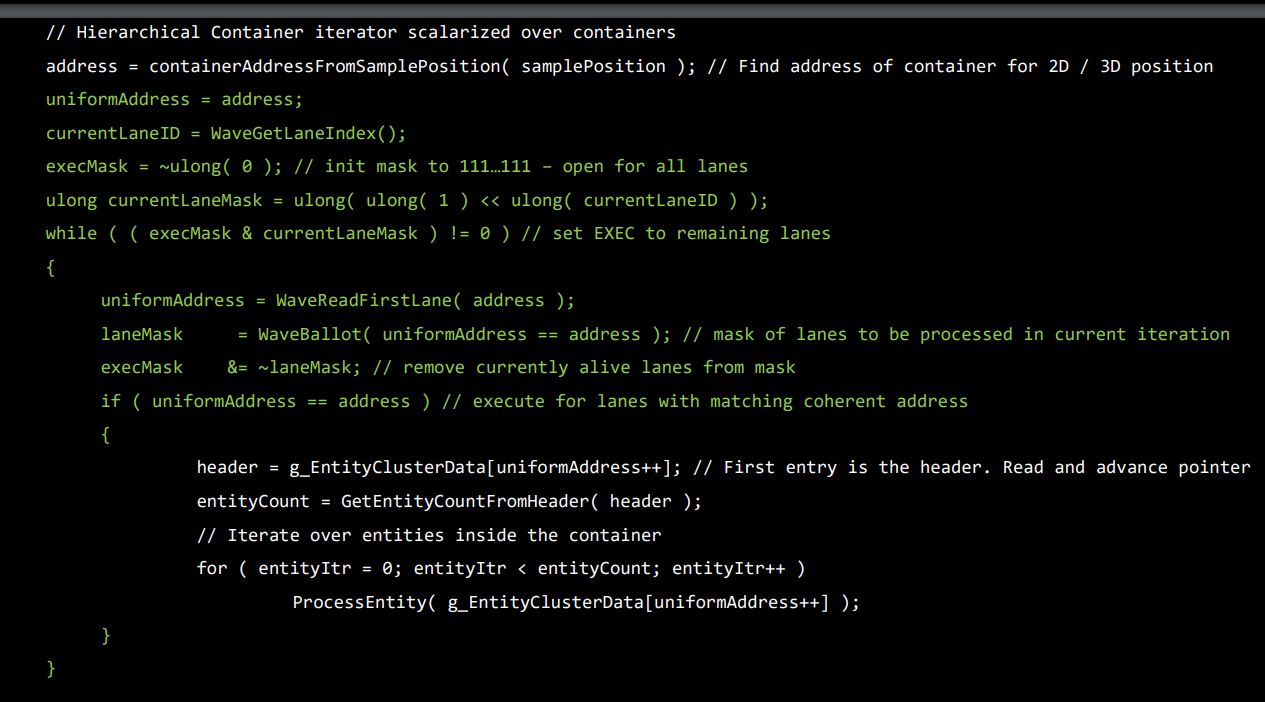
//获取当前片元的Tile
uint v_cellIdx = GetCellIdx();
//获取当前Lane的在Warp中的Index
uint v_laneID = WaveGetLaneIndex();
//先标记所有Lane为alive
ulong execMask = 0xffffffff;
//例如:v_laneID=3 curLaneMask=>00000...001000
ulong curLaneMask = ulong(1) << ulong(v_laneID);
//只要execMask中所有Lane对应的标识位都变成0就结束循环
while ( ( execMask & curLaneMask ) != 0 )
{
//标量的形式读取到对应最小Acive Lane Index对应的cellIdx
uint s_cellIdx = WaveReadLaneFirst(v_cellIdx);
//处理同一个cell Index的Lane,把处理了的Lane Index对应的flag标识为0
//后续就不会重复处理cell了
ulong laneMask = WaveActiveBallot( v_cellIdx == s_cellIdx );
execMask = execMask & ~laneMask;
//处理同一个cell Index的Lane
if (v_cellIdx == s_cellIdx )
{
ProcessLightsInCell(s_cellIdx);
}
}
void ProcessLightsInCell(uint s_cellIdx)
{
{s_lightStart, s_lightCount} = GetCellIndices(s_cellIdx);
for( i = 0; i < s_lightCount; ++i)
{
uint s_lightIdx = GetLightIdx(s_lightStart, i);
LightData s_light = Lights[s_lightIdx];
ProcessLight(s_light);
}
}
引用自:https://advances.realtimerendering.com/s2017/2017_Sig_Improved_Culling_final.pdf
DOOM的做法
扁平化LightList

首先需要明确一点的是,在每个Tile里面,LightIndex都是排序过了的,所以我们可以用WaveActiveMin对LightIndex进行Scalarize。
把所有的LightIndex扁平化成一维数组,然后就可以让每个Lane从小的Index进行着色计算。
uint v_cellIdx = GetCellIdx();
//获取当前Tile的灯光数量以及起始Index
{v_lightStart, v_lightCount} = GetCellIndices(v_cellIdx);
uint v_lightOffset = 0;
while(v_lightOffset < v_lightCount)
{
uint v_lightIdx = GetLightIdx(v_lightStart, v_lightOffset);
//读取到所有的Lane中最小的Idx
uint s_lightIdx = WaveActiveMin(v_lightIdx);
//优先处理Index小的
if(s_lightIdx >= v_lightIdx)
{
v_lightOffset++;
LightData s_light = Lights[s_lightIdx];
ProcessLight(s_light);
}
}
FastPath

大多数时候是Tile与Warp对齐的,也就是Opaque FPTL读取Light List时。
但是,当Transparent队列用Cluster读取时会因为depthZ映射的Cluster ID不一样才会导致一个warp中会出现LightList不一致的情况。
而且WaveActiveMin查询其实也是有消耗的,而且还在While内部。
所以又引入了FastPath解决这个问题。
下面就是HDRP的FastPath实现。
//ShaderVariablesFunctions.hlsl
// ----------------------------------------------------------------------------
// Scalarization helper functions.
// These assume a scalarization of a list of elements as described in https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-2-scalarize-all-the-lights/
//判断当前Warp是FastPath,LightList一致
bool IsFastPath(uint lightStart, out uint lightStartLane0)
{
// Fast path is when we all pixels in a wave are accessing same tile or cluster.
lightStartLane0 = WaveReadLaneFirst(lightStart);
return WaveActiveAllTrue(lightStart == lightStartLane0);
}
// This function scalarize an index accross all lanes. To be effecient it must be used in the context
// of the scalarization of a loop. It is to use with IsFastPath so it can optimize the number of
// element to load, which is optimal when all the lanes are contained into a tile.
// Please note that if PLATFORM_SUPPORTS_WAVE_INTRINSICS is not defined, this will *not* scalarize the index.
uint ScalarizeElementIndex(uint v_elementIdx, bool fastPath)
{
uint s_elementIdx = v_elementIdx;
//如果不是fastPath才查询其他Lane的v_elementIdx
if (!fastPath)
{
// If we are not in fast path, v_elementIdx is not scalar, so we need to query the Min value across the wave.
s_elementIdx = WaveActiveMin(v_elementIdx);
}
// If WaveActiveMin returns 0xffffffff it means that all lanes are actually dead, so we can safely ignore the loop and move forward.
// This could happen as an helper lane could reach this point, hence having a valid v_elementIdx, but their values will be ignored by the WaveActiveMin.
// If that's not the case we make sure the index is put into a scalar register.
//WaveActiveMin返回出-1,说明所有的Lane已经是Inactive(提前结束)
//提前结束大多数是因为当前的Lane是Helper Lane(没有写入像素仅参于计算Gradients[ddx/ddy]),
//对于这些Helper Lane就算是有有效的v_elementIdx,但它们的值都会被WaveActiveMin给忽略。
if (s_elementIdx != -1)
{
//如果是FastPath也需要化v_elementIdx成标量
s_elementIdx = WaveReadLaneFirst(s_elementIdx);
}
return s_elementIdx;
}
/////////////////////////End of ShaderVariablesFunctions.hlsl//////////////////////////////////
//LightLoop.hlsl
if (featureFlags & LIGHTFEATUREFLAGS_PUNCTUAL)
{
uint lightCount, lightStart;
GetCountAndStart(posInput, LIGHTCATEGORY_PUNCTUAL, lightStart, lightCount);
bool fastPath = false;
uint lightStartLane0;
fastPath = IsFastPath(lightStart, lightStartLane0);
if (fastPath)
{
lightStart = lightStartLane0;
}
// Scalarized loop. All lights that are in a tile/cluster touched by any pixel in the wave are loaded (scalar load), only the one relevant to current thread/pixel are processed.
// For clarity, the following code will follow the convention: variables starting with s_ are meant to be wave uniform (meant for scalar register),
// v_ are variables that might have different value for each thread in the wave (meant for vector registers).
// This will perform more loads than it is supposed to, however, the benefits should offset the downside, especially given that light data accessed should be largely coherent.
// Note that the above is valid only if wave intriniscs are supported.
uint v_lightListOffset = 0;
uint v_lightIdx = lightStart;
while (v_lightListOffset < lightCount)
{
v_lightIdx = FetchIndex(lightStart, v_lightListOffset);
uint s_lightIdx = ScalarizeElementIndex(v_lightIdx, fastPath);
//FallBack:防止s_lightIdx出现-1导致循环挂起
if (s_lightIdx == -1)
break;
LightData s_lightData = FetchLight(s_lightIdx);
// If current scalar and vector light index match, we process the light. The v_lightListOffset for current thread is increased.
// Note that the following should really be ==, however, since helper lanes are not considered by WaveActiveMin, such helper lanes could
// end up with a unique v_lightIdx value that is smaller than s_lightIdx hence being stuck in a loop. All the active lanes will not have this problem.
if (s_lightIdx >= v_lightIdx)
{
v_lightListOffset++;
if (IsMatchingLightLayer(s_lightData.lightLayers, builtinData.renderingLayers))
{
DirectLighting lighting = EvaluateBSDF_Punctual(context, V, posInput, preLightData, s_lightData, bsdfData, builtinData);
AccumulateDirectLighting(lighting, aggregateLighting);
}
}
}
}
结尾
写到这里HDRP的FPTL以及Cluster就基本写完了,感谢能一路看下来的读者,
其实比较遗憾的是,没有什么实质性的性能比对的实验,能够验证标量化的有效性,在Unity搞SM6.0还是不现实,先挖个坑吧。
如果读者这一章还是没太明白的话,我强烈推荐大家去看原文,原文还有动图以及ppt
https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-1/
https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-2-scalarize-all-the-lights/
如果说对于Warp和Lane相关的硬件知识还是不太了解的可以看这几篇:
https://anteru.net/blog/2018/intro-to-compute-shaders/
https://zhuanlan.zhihu.com/p/469436345
https://www.cnblogs.com/timlly/p/11471507.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号