【Oracle11g】优化器基础知识之表连接
当优化器解析含表连接的目标SQL时,它除了会根据目标SQL的SQL文本的写法来决定表连接的类型之外,还必须决定如下三件事情才能得到最终的执行计划。
(1)表连接顺序
不管目标SQL中有多少表进行连接,Oracle在实际执行该SQL时都只能先两两表做表连接,在依次执行这样的两两表连接过程,直到目标SQL中所有的表都已经连接完毕。比如:现在有A,B,C三表,是先让A与B进行连接,然后再用其结果集与C连接。
(2)表连接方法
在Oracle中,表连接的方法有以下四种:
- 排序合并连接
- 嵌套循环连接
- 哈希连接
- 笛卡尔连接
(3)访问单表的方法
对于优化器而言,仅决定表连接顺序和表连接方法是远远不够的,这还不足以得到目标SQL的最终执行计划,优化器还要决定访问单表的方法,比如在访问单表的时候,是采取全表扫描还是走索引,走索引的话又使用什么索引访问等
1.表连接的类型
1.1 内连接(inner join)
内连接是指表连接的连接结果只包含那些完全满足连接条件的记录。
-- 表连接案例
create table t1(id number,name varchar2(10),cityNo number);
create table t2(cityNo number,cityName varchar2(10));
-- 插入数据
insert into t1 values(1,'Jack',10);
insert into t1 values(2,'Lucy',20);
insert into t1 values(3,'Tom',30);
insert into t2 values(10,'昆明');
insert into t2 values(20,'曲靖');
insert into t2 values(30,'红河');
insert into t2 values(40,'昭通');
commit;
以下是t1表与t2内连接的结果
-- 连接
SQL> select t1.id,t1.name,t1.cityNo,t2.cityName from t1,t2 where t1.cityNo = t2.cityNo;
ID NAME CITYNO CITYNAME
---------- ---------- ---------- ----------
1 Jack 10 昆明
2 Lucy 20 曲靖
3 Tom 30 红河
上述内连接写法是Oracle自己的写法,标准SQL中内连接的写法是JOIN ON或者JOIN USING
语法:
-- join on语法
目标表1 join 目标表2 on (连接条件)
-- join using语法
目标表1 join 目标表2 using (连接列集合)
-- 如果有多个连接列,则其语法中的"(连接列集合)"里边的各个连接列之间使用逗号来分隔
上述SQL可以等价改写为:
-- join on等价改写
select t1.id,t1.name,t1.cityNo,t2.cityName from t1 join t2 on (t1.cityNo = t2.cityNo);
-- join using等价改写
select t1.id,t1.name,cityNo,t2.cityName from t1 join t2 using(cityNo);
/*
注意:上述SQL中cityNo是不能添加别名的,如果添加别名则会报错:
ORA-25154: column part of USING clause cannot have qualifier
**/
还有一种更特殊的写法,就是NATURAL JOIN,它是一种特殊的JOIN USING,其含义是两个表的所有同名列进行连接,等价SQL为:
select t1.id,t1.name,cityNo,t2.cityName from t1 natural join t2
上述SQL不推荐使用,因为两个表的同名列不一定表示同一个意思,使用这种语法会增加目标SQL出错的风险。
1.2 外连接(outer join)
外连接是对内连接的一种扩展,它是指表连接的连接结果出了包含那些完全满足连接条件的记录之外还会包含驱动表中所有不满足该连接条件的记录。
外连接包含:左连接(left outer join )、右连接(right outer join )、全连接(full outer join )
这三种语法都可以跟JOIN ON或者JOIN USING连用
以下语法中的目标表1是驱动表,目标表2是被驱动表
左连接的语法:
-- join on语法
目标表1 left outer join 目标表2 on (连接条件)
-- join using语法
目标表1 left outer join 目标表2 using (连接列集合)
右语法的语法:
-- join on语法
目标表1 right outer join 目标表2 on (连接条件)
-- join using语法
目标表1 right outer join 目标表2 using (连接列集合)
全连接的语法:
-- join on语法
目标表1 full outer join 目标表2 on (连接条件)
-- join using语法
目标表1 full outer join 目标表2 using (连接列集合)
Oracle还有一种语法,使用关键字"(+)",例如:
select t1.id,t1.name,t1.cityNo,t2.cityName from t1 left outer join t2 on (t1.cityNo = t2.cityNo);
等价于
select t1.id,t1.name,t1.cityNo,t2.cityName from t1,t2 where t1.cityNo = t2.cityNo(+);
-- 加号跟谁谁是被驱动表,加号在等号右边是左连接,在等号左边是右连接
那么如果是存在过滤条件,这种语法又都得怎么写呢?
select t1.id,t1.name,t1.cityNo,t2.cityName from t1 right outer join t2 on (t1.cityNo = t2.cityNo and t1.cityNo=20);
等价于
select t1.id,t1.name,t1.cityNo,t2.cityName from t1,t2 where t1.cityNo(+) = t2.cityNo and t1.cityNo(+)=20;
需要注意一点,有些带了限制条件的外连接,看似外连接,但是实际执行的时候是选择使用的等价内连接
SQL> set autotrace traceonly
SQL> select t1.id,t1.name,t1.cityNo,t2.cityName from t1,t2 where t1.cityNo(+) = t2.cityNo and t1.cityNo=30;
Execution Plan
----------------------------------------------------------
Plan hash value: 1838229974
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 53 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 53 | 7 (15)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| T1 | 1 | 33 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| T2 | 1 | 20 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."CITYNO"="T2"."CITYNO")
2 - filter("T1"."CITYNO"=30)
3 - filter("T2"."CITYNO"=30)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
8 recursive calls
0 db block gets
31 consistent gets
0 physical reads
0 redo size
736 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
从上述结果可以看到,Id=1的执行步骤使用了HASH JOIN,表示使用的内连接。为什么会使用内连接呢?
对于上述SQL而言,其外连接条件t1.cityNo(+) = t2.cityNo中的关键字(+)出现在表t1的列cityNo后面。这意味着表t1中那些不满足外条件并位于表t1中的查询列都会以null来填充,同时该SQL的额外限制条件t1.cityNo=30中并没有关键字(+)
,这表示该限制条件会在表t1和表t2连接后才被应用到其结果集上。这个限制条件会把表t1中那些已经做完外连接且以NULL值填充的的所有记录都给过滤了。这样一来,就可以使用等价的内连接来执行了(因为执行结果中根本就不会出现外连接所特有的以NULL值来填充的记录)。
2.表连接的方法
2.1 排序合并连接(Sort Merge Join)
排序合并连接是两个表在做连接时用排序操作和合并操作来得到连接结果集的表连接方法。
如果两个表t1和t2在做表连接时使用排序合并连接,则Oracle会执行以下步骤:
(1) 首先以目标SQL中指定的谓词条件去访问表t1,然后对访问结果按照t1表中的连接列排序,排序后的结果此处记为结果集A。
(2)接着以目标SQL中指定的谓词条件去访问表t2,然后对访问结果按照t2表中的连接列排序,排序后的结果此处记为结果集B。
(3)合并结果集A和结果集B,从中取出匹配记录来作为排序连接的最终执行结果。
排序合并连接的优缺点和使用场景:
- 通常情况下,排序合并连接的执行效率会远不如哈希连接,但前者的使用范围广,因为哈希连接通常只能用于等值连接条件,而排序合并连接还能用于其他连接条件(例如:<、<=、>、>=)
- 通常情况下,排序连接合并并不适用于OLTP,因为排序代价太大,如果能避免排序,则可以使用。例如两个表在各自的连接列上都存在索引,虽然做的排序合并连接,但是实际上并不需要排序。
2.2 嵌套循环连接(Nested Loops Join)
嵌套循环连接是一种两个表在做表连接时依靠两层嵌套循环(分别为外层循环和内层循环)来得到连接结果集的表连接方法。
如果两个表t1和t2在做表连接时使用嵌套连接,则Oracle会执行以下步骤:
(1)首先,优化器会按照一定规则来决定谁是驱动表,谁是被驱动表。驱动表用于外层循环,被驱动表用于内层循环。这里假设t1是驱动表,t2是被驱动表。
(2)接着以目标SQL中指定的谓词条件去访问驱动表t1,访问驱动表t1得到的结果集我们记为驱动结果集A。
(3)然后遍历驱动结果集A并同时遍历被驱动表t2,先从结果集A中取出第1条记录,然后拿着这条记录去遍历t2表,并按照连接条件去判断t2中是否存在匹配的记录,然后再取出结果集A中的第2条记录,继续类似匹配,直到遍历完结果集A中所有记录。显然,t1表就是外层循环,t2表就是内层循环了。
嵌套循环连接的优缺点和使用场景:
- 驱动表数据量小,被驱动表的连接列上存在唯一性索引(或者是选择性很好的非唯一性索引),嵌套循环连接效率会很高。如果驱动表数据量大,那么就算有索引,效率也是很低的。
- 驱动表的数据量指的是:指定谓词条件后的数据量(也就是过滤条件执行后的数据量),所以大表如果指定谓词条件后,数据量下来了,也是可以使用的
- 独有的优点:嵌套循环可以实现快速响应。即它可以第一时间先返回已经连接过并且满足连接条件的记录,不必等到所有的记录全部完成后再返回结果。排序合并连接虽然也不必等待所有结果做完,但是它也不是第一时间返回记录,因为排序合并必须得等到合并操作时才开始返回数据。而哈希则要等到驱动结果集对应的Hash Table全部建完后才开始返回数据。
如果Oracle使用的是嵌套循环连接,且在被驱动表的连接列上存在索引,那么Oracle在访问索引的时候通常会使用单块读,这就意味着嵌套循环连接的驱动结果集有多少记录,就得访问该索引多少次。另外,如果数据不能从索引中直接获得,那么Oracle还需要回表操作,回表也是单块读,这就意味着做完嵌套循环连接后的连接结果集有多少条记录,就要回表多少次。
对于这种单块读,如果待访问的索引块或数据块不在Buffer Cache中,Oracle就需要耗费I/O去相应的数据文件中获取。显然,在单块读的数量不能降低的情况下,如果能减少这种单块读所需要耗费的物理I/O数量,那么嵌套循环连接的效率也会随之提高。
为了提高嵌套循环的连接效率,在Oracle11g中,Oracle引入了向量I/O。引入向量I/O后,Oracle可以将原先一批单块读所需要耗费的物理I/O组合起来,然后用一个向量I/O去批量处理他们,这样就实现了在单块读的数量不降低的情况下减少这些单块读所需要耗费的物理I/O数量,也就提高了嵌套循环连接的执行效率。
向量I/O的引入反映在嵌套循环连接所对应的执行计划上。在Oracle11g中,会发现一个问题,明明一次嵌套循环连接就可以处理完毕的SQL,但其执行计划的显示内容中嵌套循环连接的数量却由之前的一个变为现在的两个。
针对1.1中的测试表t1与t2,我们做个测试验证一下:
create index idx_t2 on t2(cityNo);
-- 查看版本
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
PL/SQL Release 11.2.0.1.0 - Production
CORE 11.2.0.1.0 Production
TNS for 64-bit Windows: Version 11.2.0.1.0 - Production
NLSRTL Version 11.2.0.1.0 - Production
SQL> set autotrace traceonly
SQL> set lines 120
SQL> select /*+ ordered use_nl(t2) */t1.id,t1.name,t1.cityNo,t2.cityName from t1,t2 where t1.cityNo = t2.cityNo;
执行计划如下:
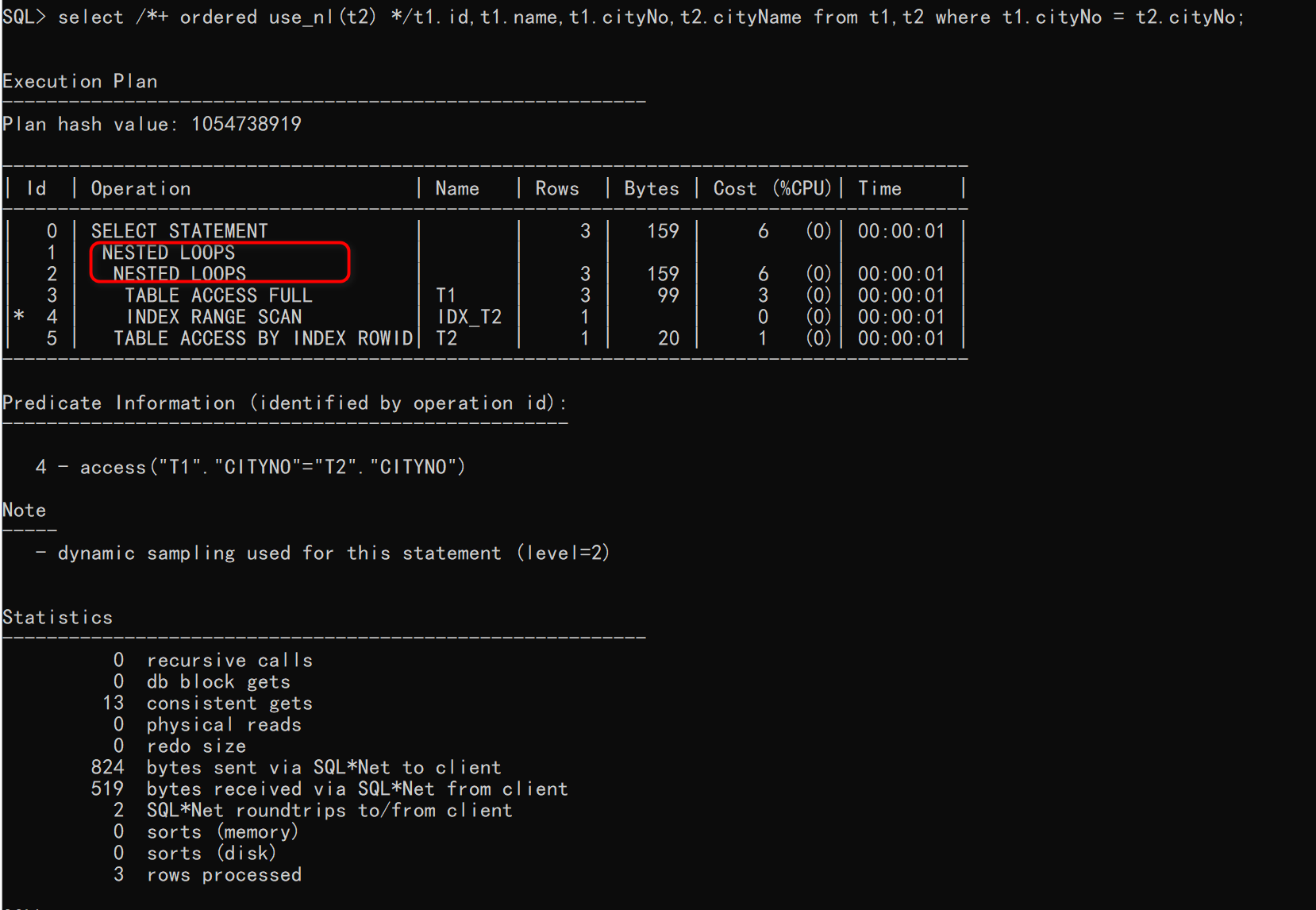
从上图可以看到,执行SQL时候用了两次嵌套循环。
2.3 哈希连接(Hash join)
哈希连接是一种两个表在做表连接的时主要依靠哈希运算来得到连接结果集的表连接方法。
如果两个表t1和t2在做表连接时使用哈希连接,则Oracle会执行以下步骤:
(1)首先Oracle会根据参数HASH_AREA_SIZE、DB_BLOCK_SIZE、HASH_MULTIBLOCK_IO_COUNT的值来决定Hash Partition的数量(Hash Partition是一个逻辑概念,它实际上是一组Hash Bucket的集合,所有Hash Partition的集合就称为Hash Table,即一个Hash Table由多个Hash Partition所组成,而一个Hash Partition又由多个Hash Bucket组成)
(2)对表t1跟t2施加目标SQL谓词条件后,得到的结果集中数据量较少的那个结果集会被Oracle选为哈希连接的驱动结果集,这里假设t1所对应的结果集数量较少,记为A,t2的结果集相对较多,记为B,那么A是驱动结果集,B是被驱动结果集。
(3)接着Oracle会遍历A,读取A中的每一条记录,并对每一条记录按照该记录在表t1中的连接列做哈希运算。这个哈希运算会使用两个内置哈希函数。这两个哈希函数会同时对该连接列计算哈希值,我们把这两个哈希函数分别记为hash_func_1和hash_func_2,他们所计算的哈希值分别记为hash_value_1和hash_value_2
(4)然后Oracle会按照Hash_value_1的值把相应的A中的对应记录存储在不同Hash Partition的不同Hash Bucket里边,同时和该记录存储在一起的还有该记录用hash_func_2计算出来的hash_value_2。此处需要注意:存储在Hash Bucket里的记录并不是目标表的完整行记录,只需要存储位于目标SQL中与目标表相关的查询列和连接列就足够了。我们把A所对应的每一个Hash Partition记为Ai。
(5)在构建Ai的同时,Oracle会构建一个位图(BITMAP),这个位图用来标记Ai所包含的每一个Hash Bucket是否有记录(即记录数是否大于0)
(6)如果A的数据量很大,那么在构建A所对应的Hash Table时,就可能会出现PGA的工作区被填满的情况。这时候Oracle会把工作区包含记录数最多的Hash Partition写到磁盘上(TEMP表空间)。接着Oracle会继续构建A所对应的Hash Table,在构建的过程中,如果工作区又满了,则Oracle会重复上述动作,即挑选包含记录最多的Hash Partition并写到磁盘上。如果要构建的记录所对应的Hash Partition已经事先被Oracle写回磁盘,则此时Oracle就会去更新该Hash Partition,即把该条记录和hash_value_2直接加到这个已经位于磁盘上的Hash Partition的相应Hash Bucket中。注意,极端情况下可能会出现只有某个Hash Partition的部分记录还在内存中,该Hash Partition的剩余部分和余下的所有Hash Partition都已经被写回到磁盘上。
(7)上述构建A所对应的Hash Table的过程会一直持续下去,直到遍历完S中所有的记录为止。
(8)接着Oracle会对所有的Ai按照他们所包含的记录数来排序,然后把这些已经排序好的Hash Partition按顺序依次且尽可能全部放到内存中(PGA工作区),当然,如果实在放不下,放不下的那部分Hash Partition还会位于磁盘上。
(9)至此,A处理完毕,现在可以开始处理B了
(10)Oracle会遍历B,读取B中的每一条记录,并按照该记录在表t2中的连接列做哈希运算。这个哈希运算和步骤3中的哈希运算是一模一样的。接着Oracle会按照该记录对应的哈希值Hash_value_1去Ai里去找匹配的Hash Bucket;如果能找到匹配的Hash Bucket,则Oracle还会遍历Hash Bucket中的每一条记录,并校验存储于该Hash Bucket中每一条记录的连接列,看是否真的匹配(即这里要校验A和B中的匹配记录所对应的连接列是否真的相等,因为对于哈希运算而言,不同的值经过哈希运算后得到的结果可能是相等的)。如果是真的匹配,则上述Hash_value_1所对应B中记录的位于目标SQL中的查询列和该Hash Bucket中的匹配记录便会组合起来,一起作为满足目标SQL条件的记录返回。如果找不到匹配的Hash Bucket,则Oracle就会去访问步骤5中构建的位图。如果位图显示该Hash Bucket在Ai中对应的记录数大于0,则说明该Hash Bucket虽然不在内存中,但它已经被写回磁盘,则此时Oracle会按照hash_value_1的值把相应B中的对应记录也以Hash Partition的方式写回到磁盘上,同时和该记录存储在一起的还有该记录用hash_func_2计算出来的hash_value_2的值。如果位图显示该Hash Bucket在Ai中对应的记录数等于0,则Oracle无须把上述hash_value_1所对应B中的记录写回磁盘了,因为这条记录必然不满足目标SQL的连接条件。这个根据位图来决定是否将hash_value_1所对应B中的记录写回到磁盘的动作就是所谓的"位图过滤"(Oracle不一定会启用位图过滤,因为如果所有的Ai本来就都在内存中,也没发生过将Ai写回磁盘的操作,那么这里就不需要启用位图过滤了),我们把B所对应的每一个Hash Partition记为Bj。
(11)上述去Ai中查找匹配Hash Bucket和构建Bj的过程会一直持续下去,直到遍历完B中所有记录为止。
(12)至此Oracle已经处理完所有位于内存中的Ai和对应的Bj,现在只剩下位于磁盘上的Ai和Bj未处理。
(13)因为构建Ai和Bj时用的是同样的哈希函数hash_func_1和hash_func_2,所以Oracle在处理位于磁盘上的Ai和Bj的时候可以放心地配对处理,即只有对应Hash Partition Number值相同的Ai和Bj才可能会产生满足连接条件的记录。这里我们用An和Bn来表示位于磁盘上且对应Hash Partition Number值相同的Ai和Bj
(14)对于每一对An和Bn,它们之中记录数较少的会被当做驱动结果集,然后Oracle会用这个驱动结果集Hash Bucket里记录的hash_value_2来构建新的Hash_Table,另外一个记录数较多的会被当做被驱动结果集,然后Oracle会用这个被驱动结果集Hash Bucket里记录hash_value_2去上述构建新的Hash_Table中找匹配记录。注意,对每一对An和Bn而言,Oracle始终会选择他们中记录较少的作为驱动结果集,所以每一对An和Bn的驱动结果集都可能会发生变化,这就是所谓的“动态角色互换”。
(15)如果存在匹配记录,则匹配记录会作为满足目标SQL连接条件的记录返回。
(16)上述处理An和Bn的过程会一直持续下去,直到遍历完所有的An和Bn为止。
哈希连接的优缺点和使用场景:
- 哈希连接不一定会排序,或者说大多数情况下都不需要排序
- 哈希连接的驱动表所对应的连接列的可选择性尽可能好,因为这个可选择性会影响对应Hash Bucket中的记录数,而Hash Bucket中的记录数又会直接影响从该Hash Bucket中查找匹配记录的效率。如果一个Hash Bucket所包含的记录数过多,则可能会严重降低所对应哈希连接的执行效率,此时典型的表现就是该哈希连接执行了很长时间都没有结束,数据库所在数据库服务器上的CPU占用率很高,但目标SQL消耗的逻辑读却很低,因为此时大部分时间都耗费在了遍历上述Hash Bucket里的所有记录上,而遍历Hash Bucket里的记录这个动作发生在PGA工作区,所以不耗费逻辑读。
- 哈希连接只适用于CBO,它只能用于等值连接条件。
- 哈希连接很适合小表与大表连接,并且连接的结果集的记录数较多的情形,特别是小表的连接列的可选择性非常好的情况下,这时候哈希连接的执行时间可以近似看作是和全表扫描那个大表所耗费的时间相当。
- 当两个表做哈希连接时,如果在施加了目标SQL中指定的谓词条件(如果有的话)后得到的数据量较小的那个结果集所对应的Hash Table能够完全容纳在内存中(PGA的工作区),则此时的哈希连接的执行效率会非常高。
2.4 笛卡尔连接(Cross Join)
笛卡尔连接又称为笛卡儿乘积,它是一种两个表在做表连接时没有任何连接条件的表连接方法。
如果两个表t1和t2在做表连接时使用笛卡尔连接,则Oracle会执行以下步骤:
(1)首先以目标SQL中指定的谓词条件(如果有的话)访问表t1,此时得到的结果集我们记为结果集1,这里假设结果集1的记录数为m;
(2)接着以目标SQL中指定的谓词条件(如果有的话)访问表t2,此时得到的结果集我们记为结果集2,这里假设结果集1的记录数为n;
(3)最后对结果集1和结果集2执行合并操作,从中取出匹配记录来作为笛卡尔连接的最终执行结果。结果集的记录数为m * n;
3.反连接(Anti Join)
反连接是一种与特殊的连接类型,与内连接和外连接不同,Oracle数据库里并没有相关的关键字可以在文本中专门表示反连接。
当做子查询展开时,Oracle经常会把那些外部where条件为NOT EXISTS、NOT IN 或<> ALL 等子查询转换为反连接。
-- NOT IN
select * from t1 where cityNo not in (select cityNo from t2);
-- <> ALL
select * from t1 where cityNo <> all (select cityNo from t2);
-- NOT EXISTS
select * from t1 where not exists (select 1 from t2 where cityNo=t1.cityNo);
此处以NOT IN 为例:
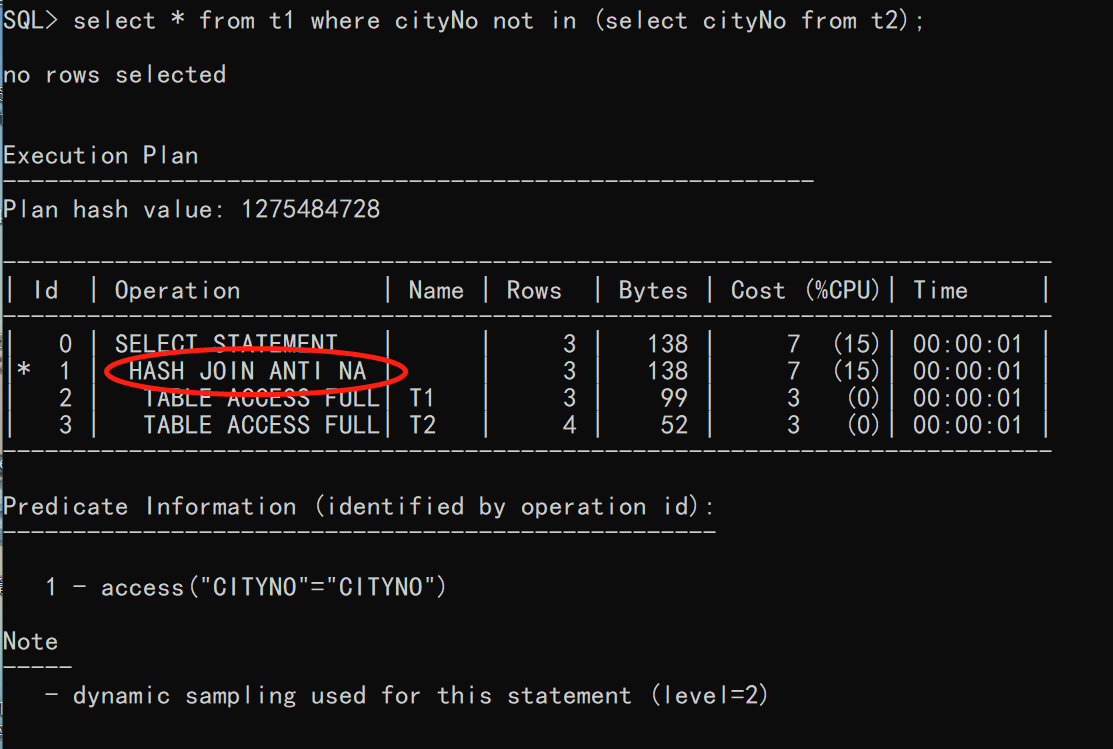
从上图可以看出,确实是使用了反连接;
3.2 可怕的NULL值
现在t1表与t2表没有null值,上述三个SQL是等价的,但是一旦有了NULL值呢?
insert into t1 values(99,'Mark',100);
insert into t1 values(4,'Logan',null);
commit;
-- 查询t1的数据
SQL> select * from t1;
ID NAME CITYNO
---------- ---------- ----------
1 Jack 10
2 Lucy 20
3 Tom 30
99 Mark 100
4 Logan
-- NOT IN
SQL> select * from t1 where cityNo not in (select cityNo from t2);
ID NAME CITYNO
---------- ---------- ----------
99 Mark 100
-- <> ALL
SQL> select * from t1 where cityNo <> all (select cityNo from t2);
ID NAME CITYNO
---------- ---------- ----------
99 Mark 100
-- NOT EXISTS
SQL> select * from t1 where not exists (select 1 from t2 where cityNo=t1.cityNo);
ID NAME CITYNO
---------- ---------- ----------
4 Logan
99 Mark 100
此时们可以看到NOT EXISTS的结果变了,现在我们将刚才的语句删除
delete from t1 where id=4;
commit;
然后往t2表插入一条null值记录
insert into t2 values(null,'上海');
commit;
查看t2表中的结果与上述三个SQL的结果
SQL> select * from t1 where cityNo not in (select cityNo from t2);
no rows selected
SQL> select * from t1 where cityNo <> all (select cityNo from t2);
no rows selected
SQL> select * from t1 where not exists (select 1 from t2 where cityNo=t1.cityNo);
ID NAME CITYNO
---------- ---------- ----------
99 Mark 100
从上述测试结果我们可以得到结论:
- 表t1、t2在各自的连接列cityNo上一旦有了NULL值,则NOT IN、<> ALL、NOT EXISTS就不完全等价了。
2)NO IN 和<> ALL对NULL值敏感,这就意味着NOT IN 后面的子查询或者常量集合一旦有NULL值出现,则整个SQL的结果就会变成NULL,此时的执行结果不包含任何记录。
3)NOT EXISTS对NULL值不敏感,这就意味着NULL值对NOT EXISTS的执行结果不会有影响
4.半连接(Semi Join)
半连接是一种与特殊的连接类型,与反连接一样,Oracle数据库里并没有相关的关键字可以在文本中专门表示半连接。
当做子查询展开时,Oracle经常会把那些外部where条件为 EXISTS、IN 或= ANY等子查询转换为半连接。
-- IN
select * from t1 where cityNo in (select cityNo from t2);
-- = ALL
select * from t1 where cityNo = any (select cityNo from t2);
-- EXISTS
select * from t1 where exists (select 1 from t2 where cityNo=t1.cityNo);
上述三个SQL是等价的,我们以IN 为例子,并查看执行计划
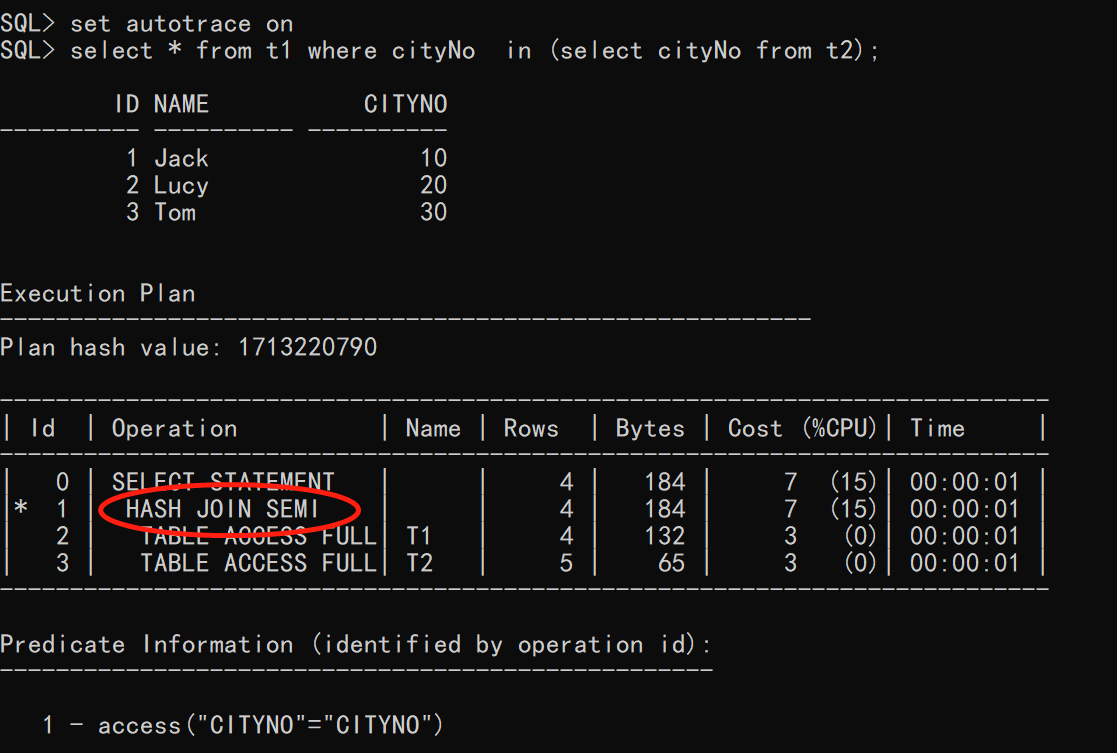
从上图我们可以看出,确实转换为了半连接进行查询。
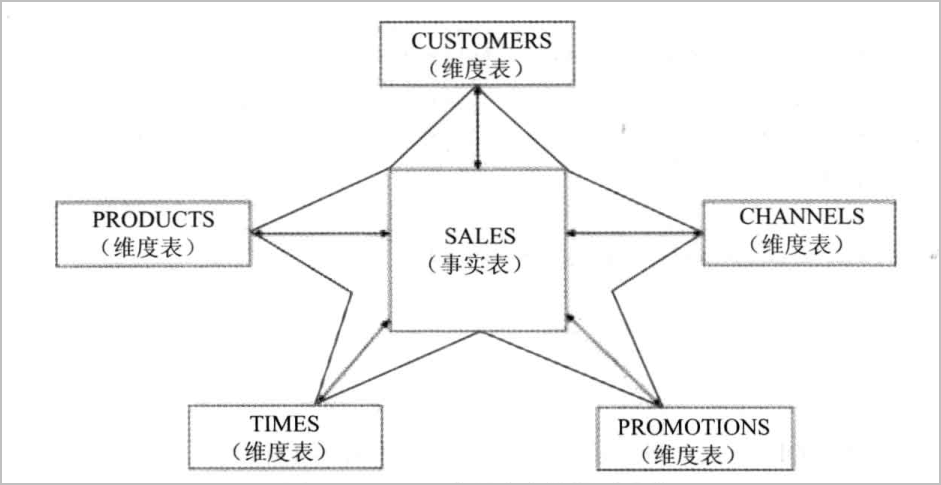
4.星型连接(Star Join)
星型连接通常用于数据仓库类型的应用,它是一种单个事实表(Fact Table)和多个维度表(Dimension Table)之间的连接。从严格意义上来讲,星型连接不是一种额外的连接方法,也不是一种额外的连接类型。
以下是示意图:
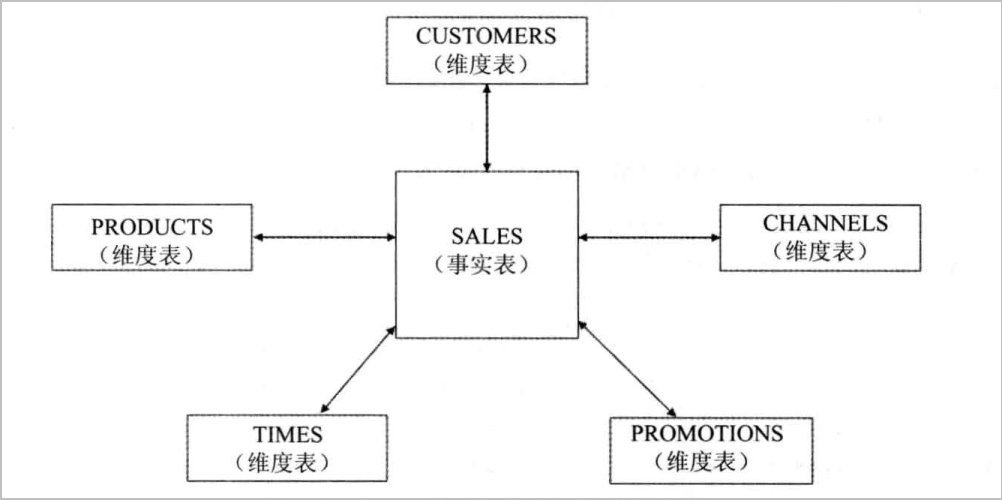
为什么叫做星型连接呢?因为事实表与个维度表之间的表连接看起来像是一颗五角星,如下图:
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

