【Oracle】优化器基础知识之访问数据的方法
对于优化器而言,他在解析目标SQL,得到执行计划时至关重要的一点是决定访问数据的方法。
Oracle访问表中数据有两种方法:
- 直接访问表
- 先访问索引,再回表
如果目标SQL通过访问索引就能得到所需要的数据,那么就不需要再回表了。
1、直接访问表
Oracle数据库直接访问表中数据的方法有2种:
- 全表扫描
- ROWID扫描
1.1 全表扫描(TABLE ACCESS FULL)
全表扫描是指Oracle在访问目标表里的数据时,会从该表所占的第一个区(EXTENT)的第一个块(BLOCK)开始扫描,一直扫描到该表的高水位线(HWM,High Water Mark),这段范围内所有的数据块Oracle都必须读到。当然,Oracle会对这期间所读到的数据施加目标SQL的WHERE条件中指定的过滤条件,最后返回满足过滤条件的数据。
数据量小的时候,全表扫描效率是很高的。但是全表扫最大的问题在于走全表扫描的目标SQL的执行时间会不稳定,不可控,这个执行时间一定会随着目标表数据量的递增而递增。
随着目标表的数据量的递增,他的HWM也会一直不断往上涨,所以全表扫描所需要读取的数据块的数量也会不断增加,这就意味着全表扫描该表时所需要耗费的I/O资源也会不断的增加,当然完成全表扫描操作所需要的时间也在增加。进而,针对CBO而言,I/O资源增加,就意味着成本值的增加。
Oracle的高水位线类似水库的水位,水涨则水位上移,水库放水,水位并不会下移,插入数据类似水涨,delete数据类似放水
1.2 ROWID扫描
ROWID扫描是指Oracle在访问目标表里的数据时,通过ROWID去定位并访问数据。ROWID表示的是Oracle中的数据行就所在的物理存储地址,也就是说ROWID与数据块中的记录一一对应。
严格意义上讲,Oracle中的ROWID扫描有以下2层含义:
(1)根据用户输入的ROWID去直接访问对应的数据行记录
(2)先去访问索引,根据索引得到的ROWID再回表访问数据行记录
1.2.1 直接通过ROWID查询(TABLE ACCESS BY USER ROWID)
对于Oracle中的堆表,我们可以通过Oracle内置的伪列得到对应行记录所在的ROWID的值(ROWID是伪列,在实际的数据块中不存在该列),DBMS_ROWID包中相关的方法有:dbms_rowid.rowid_relative_fno,dbms_rowid.rowid_block_number,dbms_rowid.rowid_row_number
以下是一个ROWID伪列和DBMS_ROWID包的实例。
select empno,ename,rowid,dbms_rowid.rowid_relative_fno(rowid) || '_' || dbms_rowid.rowid_block_number(rowid) || '_' || dbms_rowid.rowid_row_number(rowid) location from emp;
执行结果如下:
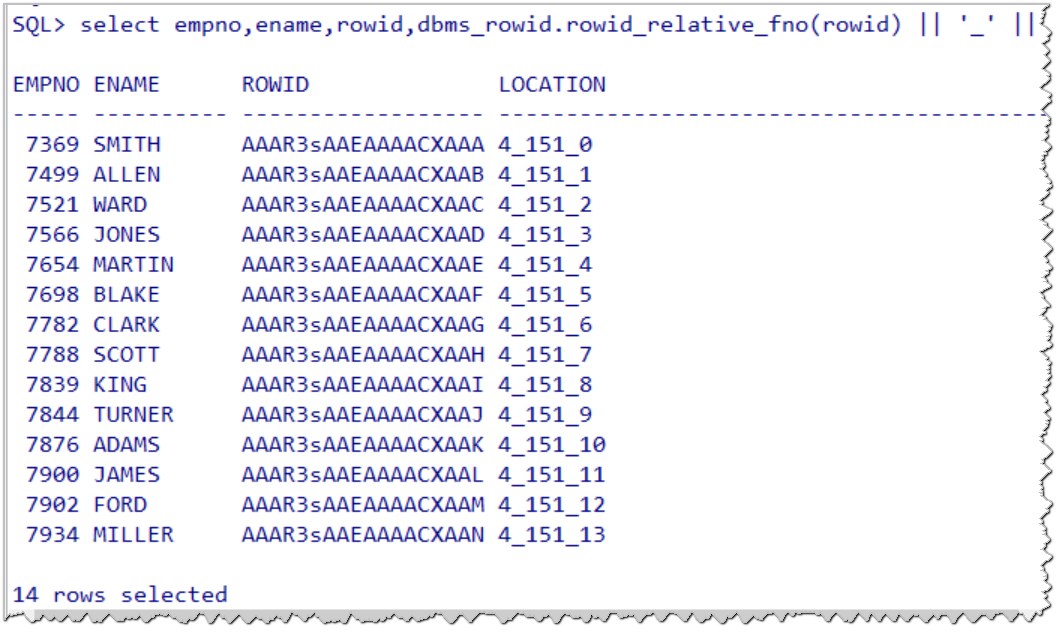
从上图可以看出,EMPNO=7396对应的ROWID为 AAAR3sAAEAAAACXAAA,使用DBMS_ROWID包翻译后的值为4_151_0,这表示EMPNO为7396的行记录实际的物理存储位置为4号文件的第151个数据块的第0行记录(数据块里边的行记录是从0开始的)
于是我们需要查询EMPNO=7396的记录就可以这么查询
select * from emp where rowid='AAAR3sAAEAAAACXAAA';
1.2.2 先访问索引后根据ROWDID查表
下边是B数索引的结构图:

B树索引就是长得像棵树,它包含两种类型的数据块:(1)索引分支块 (2)索引叶子块
索引分支块包含指向相应索引分支块/叶子块的指针和索引键值列(这里的指针是指相关分支块/叶子块的块地址RDBA。每个索引分支块都会有两种类型的指针,一种是lmc,另一种是索引分支块的索引行记录所记录的指针。lmc是Left Most Child的缩写,每个索引分支块都只有一个lmc,这个lmc指向的是分支块/叶子块中所有索引键值列中的最大值一定小于该lmc所在索引分支块的所有索引键值列中的最小值;而索引分支块的索引行记录所记录的指针所指向的分支块/叶子块的所有索引键值列中的最小值一定大于或等于该行记录的索引键值列的值)。这个索引键值列不一定就是完整的的被索引键值,它可能只是被索引键值的前缀,只要Oracle能通过这些前缀区分相应的索引分支块/叶子块就行。这样Oracle既能节省索引分支块的存储空间,又可以快速定位其下层的索引分支块/叶子块。索引分支块最上层的那个块就是所谓的索引根节点,也就是上图中包含"B C"的那个分支块。
索引叶子块包含被索引键值和用于定位该索引键值所在的数据行在表中实际物理存储位置的ROWID。
针对唯一性B树索引,ROWID是存储在索引行的行头,Oracle不需要额外存储该ROWID的长度。
针对非唯一B树索引,ROWID被当做额外的列与被索引的键值列存储在一起,所以Oracle此时既要存储ROWID,又要存储其长度。在同等条件下,相对于唯一性B树索引来说,占用空间较大。
正是由于上述结构特点,Oracle数据库中的B树索引才具有如下优势。
(1)所有的索引叶子块都在同一层,即它们距离索引根节点的深度是相同的。这也就意味着访问索引叶子块的任何一个索引键值所花费的时间几乎相同。
(2)Oracle会保证所有的B树索引都是自平衡的,即不可能出现不同的索引叶子块不处于同一层的现象。
(3)通过B树索引访问表里行记录的效率并不会随着相关表的数据量的递增而显著降低,即通过走索引访问数据的时间是可控的、基本稳定的,这也是走索引和全表扫描最大的区别。
B树索引的上述结构就决定了Oracle里通过B树索引访问数据的过程是先访问相关的B树索引,然后根据访问该索引后得到的ROWID再回表去访问相应的数据行记录。Oracle中走索引的成本有2部分:一部分是访问相关B树索引的成本,另一部分是回表的成本。
1.2.1.1 索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里是等值查询的目标SQL。因为扫描的对象是唯一性索引,所以索引唯一性扫描的结果至多只会返回一条记录。
1.2.1.2 索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围查询(谓词条件为:BETWEEN、>、<等);当扫描的对象是非唯一性索引时,对目标SQL的where条件没有限制(可以是等值查询,也可以是范围查询)。
针对同等条件下的相同SQL,当目标索引的索引行的数量大于1时,索引范围扫描所耗费的逻辑读会多于索引唯一性扫描所耗费的逻辑读。因为索引唯一性扫描结果至多只会返回1条记录,所以Oracle明确知道,只需要访问相关的叶子块一次即可直接返回,但是对于索引范围扫描而言,因为扫描结果可能返回多条记录,同时又因为目标索引的索引行数量大于1,目标SQL为了确定索引范围扫描的扫描终点,就不得不去多次访问相关的叶子块。所以,在同等条件下,当目标索引的索引行数量大于1时,索引范围扫描所耗费的逻辑读至少会比索引唯一性扫描的逻辑读多1
案例验证:
-- 创建表
SQL> create table emp_temp as select * from emp;
Table created.
-- 在表emp_temp上建立一个单键值唯一性B树索引IDX_EMP_TEMP
SQL> create unique index idx_emp_temp on emp_temp(empno);
Index created.
-- 收集统计信息
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'EMP_TEMP', estimate_percent => 100, cascade => true, method_opt => 'for all columns size 1');
PL/SQL procedure successfully completed.
-- 清除Buffer Cache和数据字典缓存
/**
为了避免Buffer Cache和数据字典缓存(Data Dictionary Cache)对逻辑读统计结果的影响,此处清空Buffer Cache和数据字典缓存。生产环境慎用!!!
此处我已经将dba权限授予用户scott用户:grant dba to scott;
**/
SQL> alter system flush shared_pool;
System altered.
SQL> alter system flush buffer_cache;
System altered.
-- 开启执行计划
SQL> set autotrace traceonly
SQL> set lines 120
SQL> select * from scott.emp_temp where empno=7369;
-- 执行计划如下图
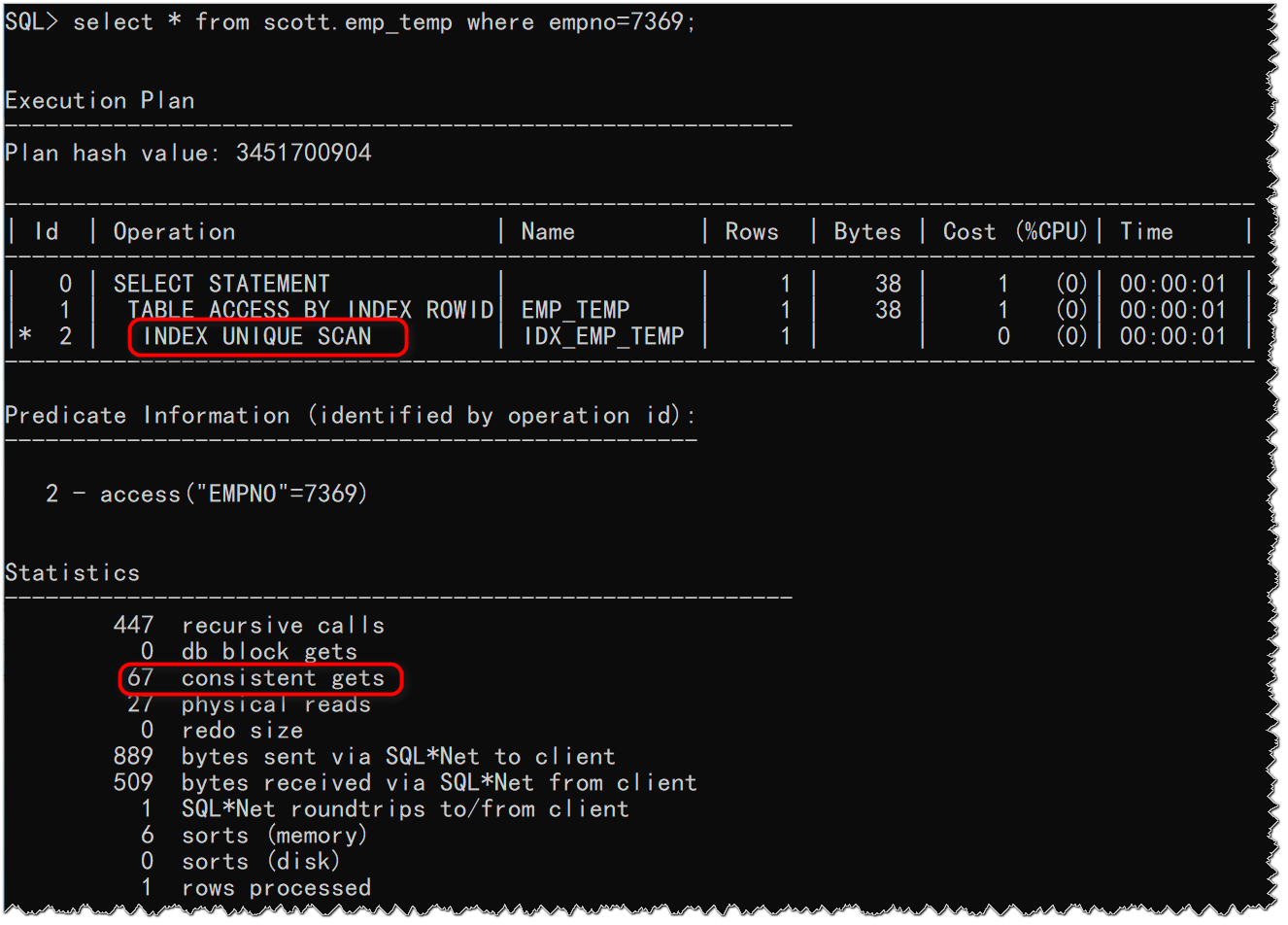
从上述执行计划可以看到执行计划走的索引唯一性扫描,并且耗费的逻辑读是67;
那么,我们删除索引,建立非唯一性索引试试
SQL> drop index idx_emp_temp;
Index dropped.
SQL> create index idx_emp_temp on emp_temp(empno);
Index created.
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'EMP_TEMP', estimate_percent => 100, cascade => true, method_opt => 'for all columns size 1');
PL/SQL procedure successfully completed.
SQL> alter system flush shared_pool;
System altered.
SQL> alter system flush buffer_cache;
System altered.
SQL> select * from scott.emp_temp where empno=7369;
执行计划如下图:

我们可以看到,现在是索引范围扫描了,并且在同等条件下,逻辑读的次数为68,比之前多1,说明索引范围扫描所耗费的逻辑读确实至少会比相应的索引唯一性扫描多1;
1.2.1.3 索引全扫描(INDEX FULL SCAN)
索引全扫描(INDEX FULL SCAN)适用于所有类型的B树索引。“全扫描”就表示扫描目标索引所有叶子块的所有索引行。这里需要注意的是,索引全扫描需要扫描目标索引所有的所有叶子块,但这并不意味着需要扫描该索引所有分支块。在默认情况下,Oracle在做索引全扫描时只需要通过访问必要的分支块定位到位于该索引最左边的叶子块的第一行索引行,就可以利用该索引叶子块之间的双向指针链表,从左至右依次顺序扫描该索引所有叶子块的所有索引行。
在默认情况下,索引全扫描需要从左至右依次顺序扫描目标索引所有叶子块的所有索引行,而索引是有序的,所以索引全扫描的执行结果也是有序的,并且是按照该索引的索引键值列来排序,这也就意味着走索引全扫描能够达到排序的效果,又同时避免了对该索引的索引键值列的真正排序操作。
create table student(stuNo number,stuName varchar2(10), addr varchar2(10),age number);
insert into student values(1,'Jack','China',18);
insert into student values(2,'Jack1','America',20);
insert into student values(3,'Jack2','Japan',17);
insert into student values(4,'Jack3','Canada',16);
insert into student values(5,'Jack4','China',33);
commit;
---
SQL> alter table student modify stuno not null;
Table altered.
SQL> create index idx_student on student(stuno);
Index created.
SQL> set autotrace on
SQL> select stuno from student;
执行计划如下:
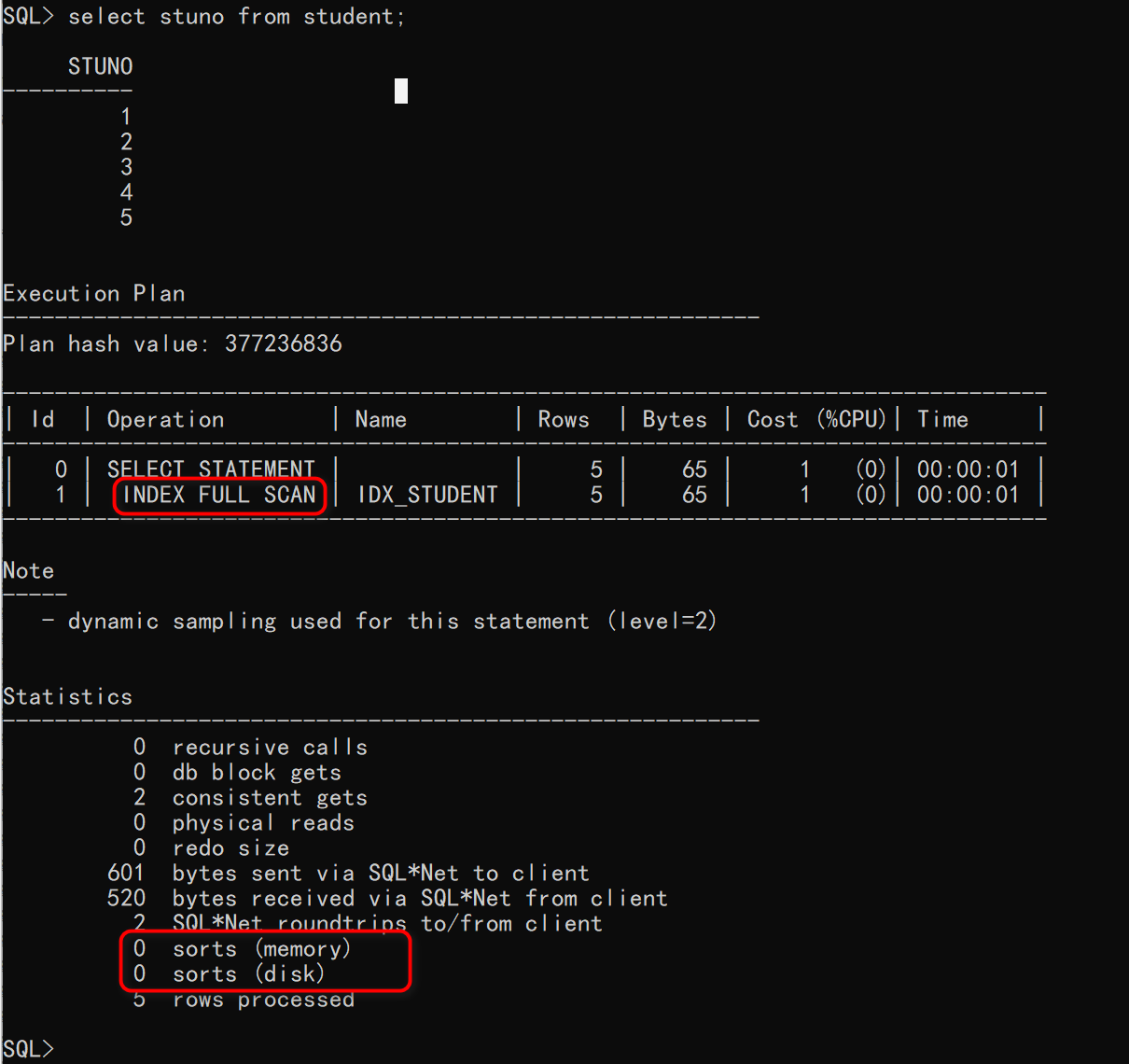
针对上述SQL而言,表EMP的列STUNO行存在一个单键值B树索引IDX_STUDENT,索引列STUNO的属性一定是NOT NULL,而该SQL的查询又只有列STUNO,索引Oracle此时就走的索引全扫描。
从结果可以看出,已经排序了,但是统计信息部分的sorts(memory)与sorts(disk)值均为0,这说明虽然结果排序了,但是这里没有任何排序操作。
通常情况下,索引全扫描是不需要回表的,所以索引全扫描适用于目标SQL的查询列全部是目标索引键值的情形。对于B树索引而言,当所有索引键值列全为NULL值时不入索引(当所有的索引键值列全为NULL值时,这些NULL值不会在B树索引中存在),这就意味着Oracle中能做索引全扫描的前提条件是目标索引列至少有一个索引键值列的属性是NOT NULL。显然,如果目标索引列的所有索引键值列的属性均为允许NULL值,此时如果还走索引,那么就会漏掉索引键值列均为NULL的记录。
1.2.1.4 索引快速扫描(INDEX FAST FULL SCAN)
索引快速全扫描(INDEX FAST FULL SCAN )和索引全扫描类似。但是有以下三点区别:
- 索引快速全扫描只适用于CBO
- 索引快速全扫描可以使用多块读,也可以并行执行
- 索引快速全扫描的执行结果不一定是有序的。
所以快速全扫描时Oracle是根据索引行所在磁盘的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果不一定有序(对于单个索引叶子块中的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序不一定在逻辑上有序)
案例:
-- 给表添加主键
alter table student add constraint p_student primary key(stuno);
-- 插入数据
begin
for i in 100..2000 loop
insert into student values(i,'Jack','China',99);
end loop;
end;
/
-- 收集索引信息后再次查询
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'STUDENT', estimate_percent => 100, cascade => true, method_opt => 'for all columns size 1');
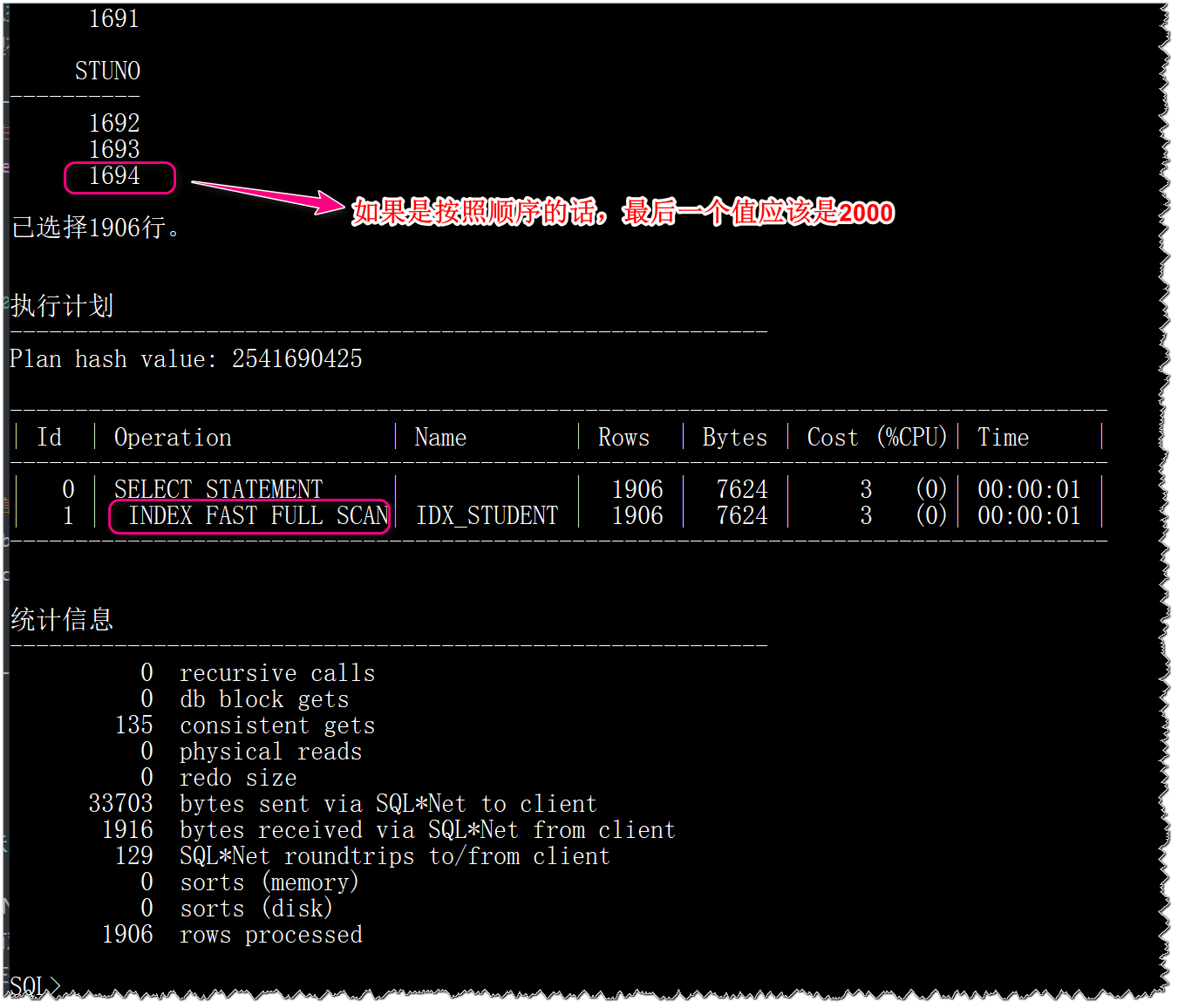
SQL> select stuno from student;
执行计划如下图:
1.2.1.5 索引跳跃式扫描(INDEX SKIP SCAN )
索引跳跃式扫描(INDEX SKIP SCAN )适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),它使那些在where条件中没有对目标索引的前导列指定查询条件但又对该索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样(实际的执行过程并非如此),这也是索引跳跃式扫描中"跳跃(SKIP)"一词的含义。
以下是实例:
-- 创建表
create table employee(gender varchar(1),employee_id number);
alter table employee modify(employee_id not null);
-- 创建一个复合B树索引,其中GENDER为该索引的前导列,列EMPLOYEE_ID为该索引的第二列
create index idx_employee on employee(gender, employee_id);
-- 插入数据
begin
for i in 1..5000 loop
insert into employee values('F',i);
end loop;
commit;
end;
/
--------------------
begin
for i in 1..5000 loop
insert into employee values('N',i);
end loop;
commit;
end;
/
-- 收集统计信息
SQL> exec dbms_stats.gather_table_stats(ownname => 'SCOTT', tabname => 'EMPLOYEE', estimate_percent => 100, cascade => true, method_opt => 'for all columns size 1');
-- 查询语句
SQL> set autotrace traceonly;
SQL> select * from employee where employee_id=100;
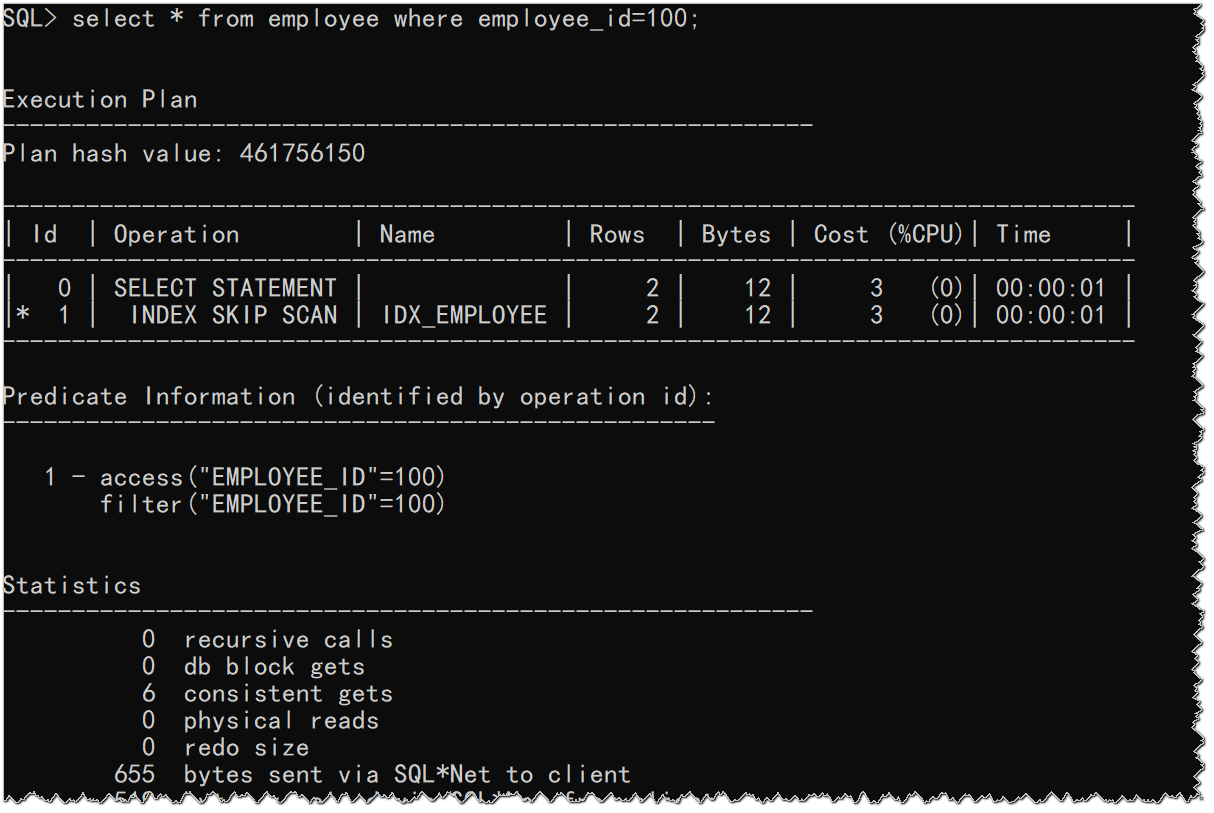
从上述显示内容可以看出,Oracle在执行时用上了索引IDX_EMPOLYEE,并且其执行计划走的就是对该索引的索引跳跃式扫描。
这里在没有指定前导列的情况下还能用上述索引,就是因为Oracle帮我们对该索引的前导列的所有distinct值做了遍历。
所谓的对目标索引的所有distinct值做遍历,其实际含义相当于对原目标SQL做等价改写(即把要用的目标索引的所有前导列的distinct 值都加进来)。索引IDX_EMPOLYEE的前导列GENDER的distinct值只有"F"和"M"两个值,所以这里能使用索引 IDX_EMPOLYEE的原因可以简单地理解成是Oracle将上述SQL改写为:
select * from employee where gender = 'F' and employee_id = 100
union all
select * from employee where gender = 'M' and employee_id = 100;
Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导列的distinct值数量较少、后续非前导列的可选择性又非常好的情形,因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减。
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号