【Oracle11g】10_表
1.表的类型
- 普通表
- 分区表
- 索引组织表IOT
- 簇表
- 临时表
- 嵌套表、对象表等
2.术语
2.1 高水位线
高水位线(high-water mark,HWM)
高水位线是一个很有趣的概念,但是也是一个非常重要的概念。顾名思义,高水位线有点类型于水文监测站里测水深度的标杆一样,当水涨的时候,水位线随之上升,并在标杆留下一个水印痕,这个水印痕就是高水位线。在数据库中,上述比喻很恰当。如果把表想象成一个平面结构,或者想象成从左到右依次排开的一系列块,高水位线就是包含了数据的最右边的块。如下图所示。
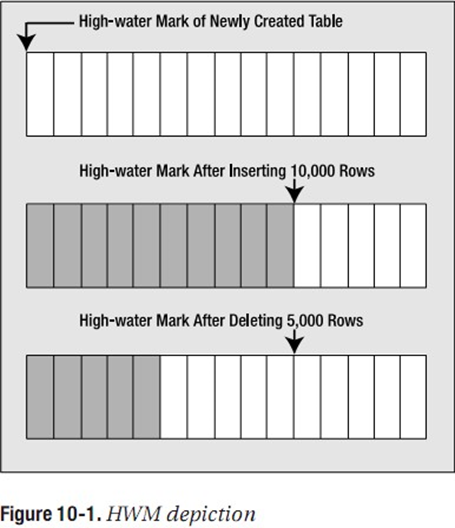
当表刚创建时,HWM位于表的第一个块中。过一段时间后,随着在这个表中放入数据,而且使用了越来越多的块,HWM会升高。但当我们删除了表中的一些(甚至全部)行,可能就会出现许多块不再包含数据,但仍然处于HWM之下,而且会一直保持在HWM之下。记住:HWM永远不会下降,除非使用rebuild、truncated或shrunk这个对象(shrinking是10g的一个新特性,仅ASSM支持)。
HWM很重要,因为Oracle在全表扫描时会扫描HWM之下的所有块,即使其中不包括任何数据。这会影响full scan的性能,特别是当HWM之下的绝大多数块都为空时。下面来看一个例子,创建一个有1000000行的表,然后对其执行select count()。接着delete所有行,再执行select count()统计出0行,比较两次执行的时间。
SQL> create table tb1 as select * from emp;
表已创建。
SQL> insert into tb1 select * from tb1; -- 执行19次生成
SQL> select count(*) from tb1;
COUNT(*)
----------
14680064
已用时间: 00: 00: 00.42
SQL> delete from tb1;
已删除14680064行。
已用时间: 00: 07: 10.92
SQL> select count(1) from tb1;
COUNT(1)
----------
0
已用时间: 00: 00: 00.42
SQL> truncate table tb1;
表被截断。
已用时间: 00: 00: 10.90
SQL> select count(1) from tb1;
COUNT(1)
----------
0
已用时间: 00: 00: 00.02
SQL>
从上述结果可以很清楚的发现上述结论成立。
2.2 PCTFREE
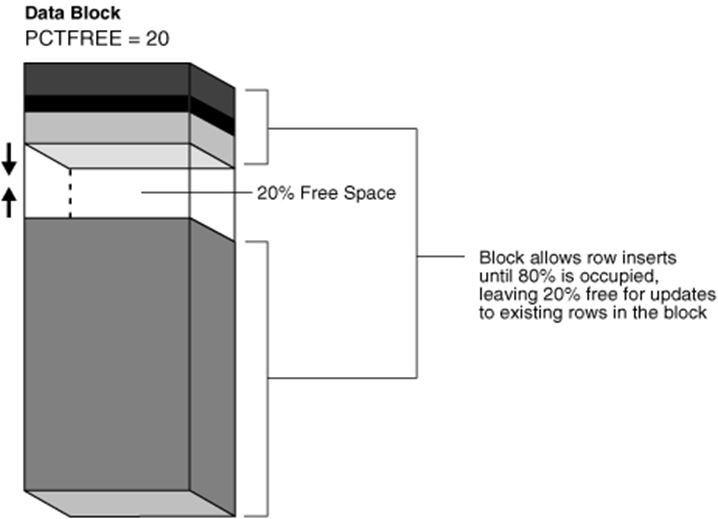
PCTFREE:为一个块保留的空间百分比,表示数据块在什么情况下可以被insert,默认是10,表示当数据块的可用空间低于10%后,就不可以被insert了,只能被用于update;即:当使用一个block时,在达到pctfree之前,该block是一直可以被插入的,这个时候处在上升期。
2.3 PCTUSED
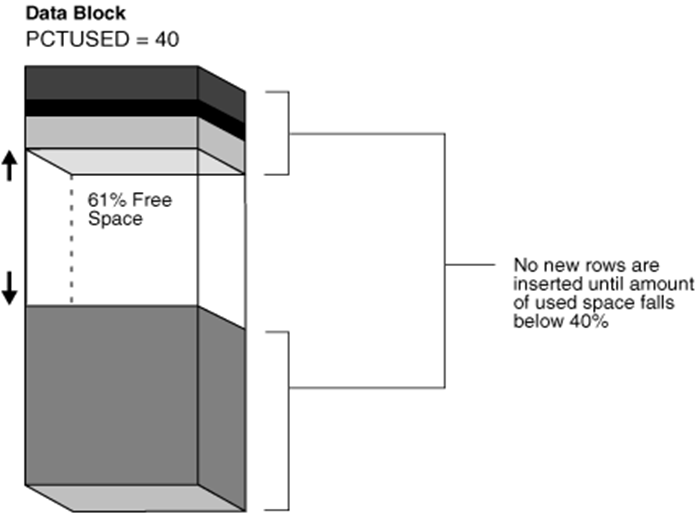
PCTUSED:是指当块里的数据低于多少百分比时,又可以重新被insert,一般默认是40,即40%,即:当数据低于40%时,又可以写入新的数据,这个时候处在下降期。
假设你一个块可以存放100个数据,而且PCTFREE 是10, PCTUSED是40,则:不断的向块中插入数据,如果当存放到90个时,就不能存放新的数据,这是受pctfree来控制,预留的空间是给UPDATE用的。
当你删除一个数据后,再想插入个新数据行不行?不行,必须是删除41个,即低于40个以后才能插入新的数据的,这是受 pctused来控制的。
注意:如果表空间上启用了ASSM,在建立表的时候,只能指定PCTFREE,否则可用指定PCTFREE和PCTUSED。
以下是一个小实验,用于说明上面这条结论
我们登陆到em控制台:https://localhost:1158/em
ASSM:自动段存储管理(自动段管理)
进入到【服务器】--> 【表空间】

我们可以看到USER表空间是ASSM
我们在USER表空间上建立一张表,进入到【方案】-->> 【表】
然后我们查看【存储】,可以看到他只支持PCTFREE参数
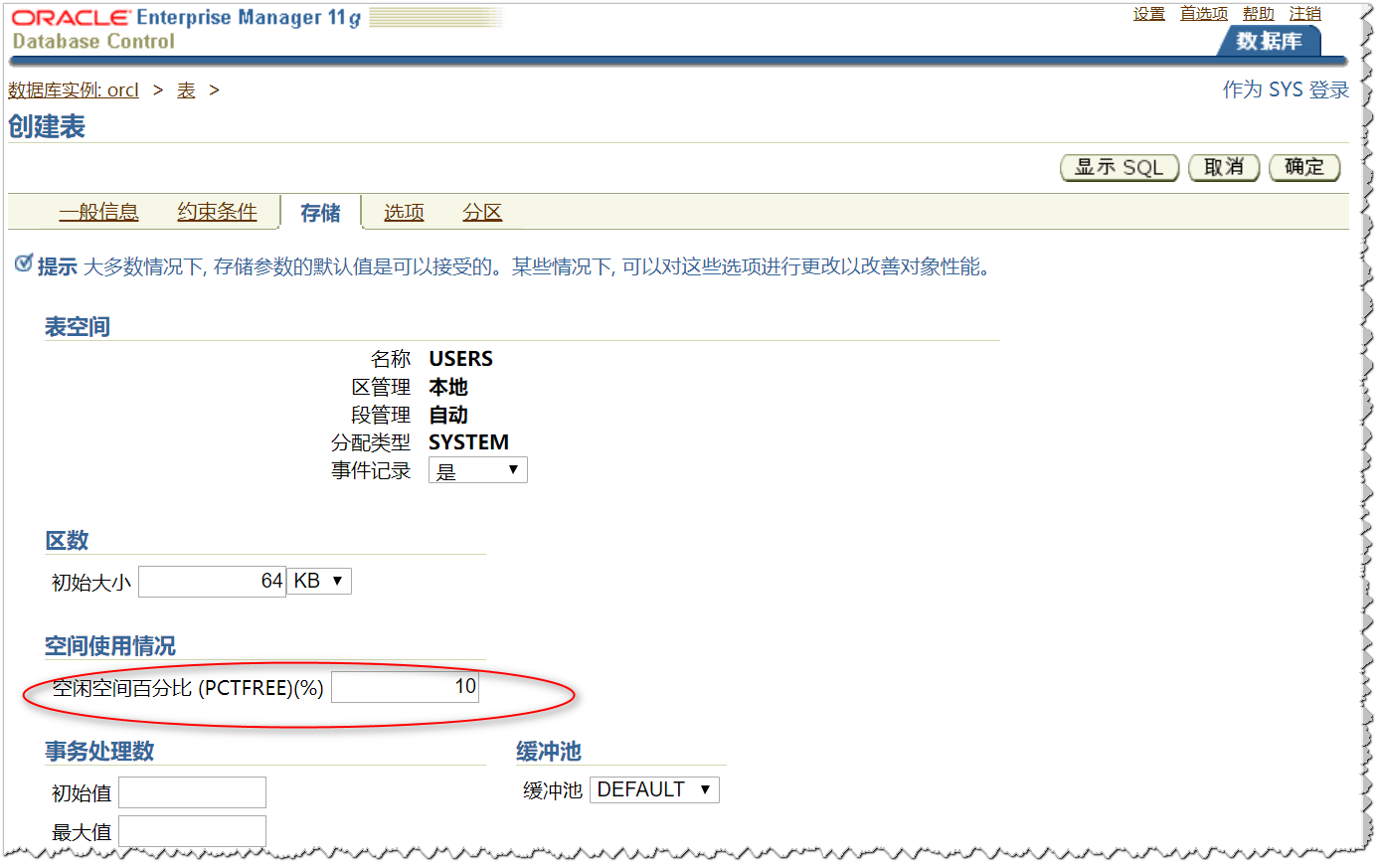
如果表空间未启用ASSM,则PCTFREE与PCTUSED都可以指定。
3.普通表
实验前准备环境:
create tablespace testtbs datafile 'C:\app\QIN\oradata\orcl\testtbs.dbf' size 20m autoextend on; -- 创建表空间
create table tb3(id number,name varchar(100)) tablespace testtbs; --在scott下创建表
insert into tb3 values(1,'Jack');
commit;
查询表dba_extents,可以看到BYTES列的值为65536
SELECT * FROM dba_extents d where d.owner='SCOTT';
3.1 给表分配空间
作用:主动扩展一个表所占的空间
alter table scott.tb3 allocate extent( datafile 'C:\app\QIN\oradata\orcl\testtbs.DBF' size 1m);
查询表dba_extents,可以看到存在多行记录了。说明表空间已经扩大了。
3.2 移动表move
作用:从一个表空间移动到另一个表空间,可以清楚表里的碎片。
alter table t1 move [tablespace users];
优点:清除数据块中的碎片,降低HWM
缺点:move过程中,表上不能有应用。
move之后,表上的索引需要重建。
3.3 收缩表shrink
收缩表shrink,将数据行从一个数据块移动到另一个数据块,分为2个阶段:收缩、降低HWM;在收缩阶段,可以对表进行DML操作,在降低HWM阶段,不能对表进行DML操作。
alter table t2 shrink space [cascade];
前提:表所在的表空间使用了ASSM。
表上启用了 row movement
3.4 截断表
截断表truncate,将表中的记录全部删除,保留表的结构。释放表所占用的全部数据块,并把HWM调整到最低,而且不能回滚
3.5 删除表
drop table t2 [cascade constraints] [purge];
3.6 删除列
alter table t2 set unused column tele;
alter table t2 drop unused columns;
4.分区表
详细内容见https://www.cnblogs.com/OliverQin/p/12663659.html
5.索引组织表IOT
1.区别于普通表的无序组织方式,IOT(Index Organized Table)表必须有主键,是有序的表,其中的数据按照主键进行存储和排序。
2.使用堆组织表时,我们必须为表和表主键上的索引分别留出空间。而IOT不存在主键的空间开销,因为IOT的数据存储在与其关联的索引中,索引就是数据,数据就是索引,二者已经合二为一。
3.IOT表中,表的数据存放在索引块中,所以如果通过主键索引访问表时,只需要读取一个块即可。而如果通过主键索引访问普通表,至少需要读取两个块,一个是索引块、一个是数据块。
4.对于经常通过主键访问数据的表来说,适合使用IOT表。
创建语句:
create table iot_student(
sno int,
sname varchar2(100),
sage int, constraint pk_student primary key(sno))
organization index
[ pctthreshold 30 overflow tablespace users ];
因为所有数据都放入索引,所以当表的数据量很大时,会降低索引组织表的查询性能。此时设置溢出段将主键和溢出数据分开来存储以提高效率。
说明: pctthreshold制定一个数据块的百分比,当行数据占用大小超出时,该行的其他列数据放入溢出段,即overflow指定存储空间中去, 所以pctthreshold是保留在索引块里的数据量占整个索引块的大小百分比,从0到50%。默认的 pctthreshold的值是50,即50%。
6.簇表
两个相互关联的表的数据,同时放到一个簇数据块中,当以后进行关联读取时,只需要扫描一个数据块就可以了,极大的提高了效率。
分为索引簇表和哈希簇表两类。
索引簇表的创建步骤:
1,建立簇段cluster segment
2,基于簇,创建两个相关表,每个表都关联到cluster segment上。
3,为簇创建索引。
创建语句:
create cluster scott.cluster1(code_key number);
create table scott.student (sno1 number, sname varchar2(10)) cluster scott.cluster1(sno1);
create table scott.address (sno2 number, zz varchar2(10)) cluster scott.cluster1(sno2);
create index index1 on cluster scott.cluster1; --为簇创建索引
7.临时表
存放临时数据,可以使用临时表;临时表被每个session单独使用,即:不同session看到的临时表中的数据可能不一样。如果在退出session时删除临时表中的数据,可以使用on commit preserve rows;如果在用户commit或rollback时删除临时表中的数据,可以使用on commit delete rows;从v$sort_usage中查看正在使用临时表空间的session信息和SQL语句的ID号,从v$sort_segmen中查看临时表空间中的段的使用情况。
临时表在临时表空间中保存。
创建语法
create global temporary table tmp_student(sno int, name varchar(100)) on commit preserve rows;
···
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

