【Python3 爬虫】U11_BeautifulSoup4库提取数据详解
目录
在下面的内容中引用了前程无忧网的部分源码进行案例演示,以下全部都是以实战案例来对BeautifulSoup4库提取数据进行解析。
前程无忧网部分源码:(在下述代码中将使用
"前程无忧"代表以下代码)
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="120207510" jt="0" style="display:none" />
<span>
<a target="_blank" title="python教师" href="https://jobs.51job.com/kunming-whq/120207510.html?s=01&t=0" onmousedown="">
python教师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南通识教育信息咨询有限公司" href="https://jobs.51job.com/all/co5751385.html">云南通识教育信息咨询有限公司</a></span>
<span class="t3">昆明-五华区</span>
<span class="t4">4.5-6千/月</span>
<span class="t5">03-29</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="118417429" jt="0" style="display:none" />
<span>
<a target="_blank" title="Python工程师" href="https://jobs.51job.com/kunming-whq/118417429.html?s=01&t=0" onmousedown="">
Python工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南蓝典科技股份有限公司" href="https://jobs.51job.com/all/co4646964.html">云南蓝典科技股份有限公司</a></span>
<span class="t3">昆明-五华区</span>
<span class="t4">4-6千/月</span>
<span class="t5">03-27</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="120703493" jt="0" style="display:none" />
<span>
<a target="_blank" title="YX00-Python开发工程师" href="https://jobs.51job.com/kunming-gdq/120703493.html?s=01&t=0" onmousedown="">
YX00-Python开发工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南远信科技有限公司" href="https://jobs.51job.com/all/co2256249.html">云南远信科技有限公司</a></span>
<span class="t3">昆明-官渡区</span>
<span class="t4">4-8千/月</span>
<span class="t5">03-27</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="117230454" jt="0" style="display:none" />
<span>
<a target="_blank" title="Python开发工程师" href="https://jobs.51job.com/kunming/117230454.html?s=01&t=0" onmousedown="">
Python开发工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南紫米科技有限公司" href="https://jobs.51job.com/all/co4672988.html">云南紫米科技有限公司</a></span>
<span class="t3">昆明</span>
<span class="t4">0.8-1万/月</span>
<span class="t5">03-27</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="117148016" jt="0" style="display:none" />
<span>
<a target="_blank" title="Python高级开发工程师" href="https://jobs.51job.com/kunming-plq/117148016.html?s=01&t=0" onmousedown="">
Python高级开发工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="微加普惠金融服务(深圳)有限公司" href="https://jobs.51job.com/all/co5633133.html">微加普惠金融服务(深圳)有限公司...</a></span>
<span class="t3">昆明-盘龙区</span>
<span class="t4">1-2万/月</span>
<span class="t5">03-27</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="118740280" jt="0" style="display:none" />
<span>
<a target="_blank" title="Java/大数据/python 讲师" href="https://jobs.51job.com/kunming/118740280.html?s=01&t=0" onmousedown="">
Java/大数据/python 讲师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南新华计算机中等专业学校" href="https://jobs.51job.com/all/co3757091.html">云南新华计算机中等专业学校</a></span>
<span class="t3">昆明</span>
<span class="t4">0.5-1万/月</span>
<span class="t5">03-27</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="104297888" jt="0" style="display:none" />
<span>
<a target="_blank" title="Python开发工程师" href="https://jobs.51job.com/kunming-whq/104297888.html?s=01&t=0" onmousedown="">
Python开发工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云南创至互达网络科技有限公司" href="https://jobs.51job.com/all/co4670824.html">云南创至互达网络科技有限公司</a></span>
<span class="t3">昆明-五华区</span>
<span class="t4">0.6-1万/月</span>
<span class="t5">03-19</span>
</div>
<div class="el">
<p class="t1 ">
<em class="check" name="delivery_em" onclick="checkboxClick(this)"></em>
<input class="checkbox" type="checkbox" name="delivery_jobid" value="120456484" jt="0" style="display:none" />
<span>
<a target="_blank" title="Python开发工程师" href="https://jobs.51job.com/kunming/120456484.html?s=01&t=0" onmousedown="">
Python开发工程师 </a>
</span>
</p>
<span class="t2"><a target="_blank" title="云思华盛(北京)科技有限公司" href="https://jobs.51job.com/all/co2898169.html">云思华盛(北京)科技有限公司</a></span>
<span class="t3">昆明</span>
<span class="t4">10-15万/年</span>
<span class="t5">03-14</span>
</div>
1.获取所有的p标签
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
ps = soup.find_all('p')
for p in ps:
print(p)
print("=" * 40)
上述代码中输出的p是一个tag类型,但是from bs4.element import Tag,进入到Tag这个类下,我们可以找到以下方法:
__repr__,从下图可以看到,该方法能将元素以字符串形式打印出来。

输出结果如下图:

2.获取第2个p标签
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
p = soup.find_all('p',limit=2)[1] # limit=2:最多提取2个标签
print(p)
输出结果如下图:
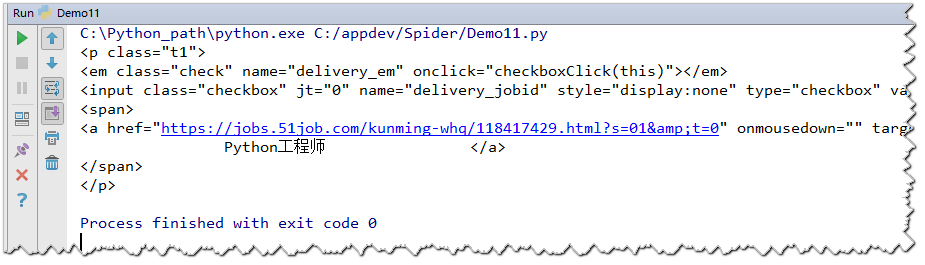
3.获取所有class等于t3的span标签
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
spans = soup.find_all('span',class_='t3') # 此处使用class_,由于class是关键字
# 上述语句也可以使用attrs替换:spans = soup.find_all('span',attrs=({'class':"t3"}))
for span in spans:
print(span)
print("=" * 40)
4.获取class等于check,name等于delivery_em的em标签
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
# 错误的语法:emList = soup.find_all('em', class_="check" ,name="delivery_em" )
emList = soup.find_all('em', attrs = {'class':"check" ,'name':"delivery_em"} )
for em in emList:
print(em)
print("=" * 40)
此处如果使用
emList = soup.find_all('em', class_="check" ,name="delivery_em" ),则会报错如下图,是由于:findall()中不能直接使用name作为参数

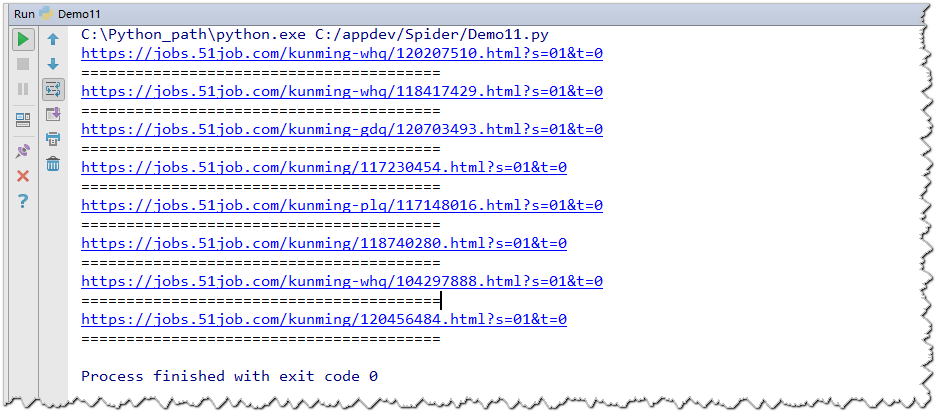
5.获取class为t1的p标签下的所有a标签的href属性
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
pList = soup.find_all('p',class_='t1')
for p in pList:
aList = p.find_all('a')
for a in aList:
# 1)通过下标操作(推荐使用,语法简洁明了)
href = a['href']
print(href)
print("=" * 40)
# 2)通过attrs属性
# href = a.attrs['href']
# print(href)
# print("=" * 40)
输出结果:
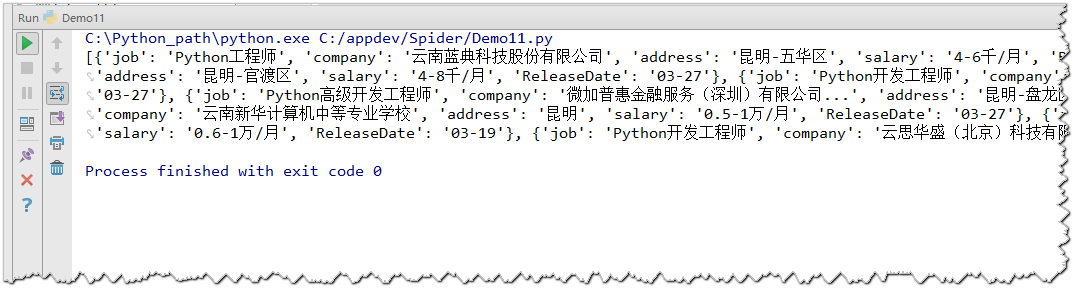
6.获取所有的职位信息(文本)
html = "前程无忧"
soup = BeautifulSoup(html,'lxml')
divs = soup.find_all('div')[1:]
infoSet = list()
for div in divs:
info = {}
infos = list(div.stripped_strings) # div.stripped_strings返回的是一个生成器
info['job'] = infos[0]
info['company'] = infos[1]
info['address'] = infos[2]
info['salary'] = infos[3]
info['ReleaseDate'] = infos[4]
infoSet.append(info)
print(infoSet)
输出结果:
7.总结
7.1 find_all的使用
- 1.在提取标签的时候,第一个是标签的名字。如果在提取标签的时候想要使用标签属性进行过滤,那么可以在方法中通过关键字参数的形式,将属性的名字及对应的值传进去,或者使用
attrs属性,将所有的属性以及对应的值放在一个字典中传给attrs - 2.
limit属性可以限制提取标签的数量
7.2 find与find_all的区别
- find:找到第一个满足条件的标签返回
- find_all:将所有满足条件的标签都返回
7.3 find与find_all的过滤条件
- 关键字参数:将属性的名字作为关键字的参数,以及属性的值作为关键字的值进行过滤,如:soup.find_all('p',class_='t1')
- attrs参数:将属性条件放到一个字典中,传给attrs参数。如:soup.find_all('p',attrs={'class':'t1'})
7.4 获取标签的属性
- 通过下标获取
href = a['href']
- 通过attrs属性获取
href = a.attrs['href']
7.5 strings和stripped_strings、string属性以及get_text方法
- string:获取某个标签下的非标签字符串,返回的是个字符串。
- strings:获取某个标签下的子孙非标签字符串,返回的是个生成器。
- stripped_strings:获取某个标签下的子孙非标签字符串,会去掉空白字符,返回的是个生成器。
- get_text:获取某个标签下的子孙非标签字符串,不是以生成器的形式返回。
作者:奔跑的金鱼
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
