【Python3 爬虫】U04_cookie的使用
1.什么是cookie?
在网站中,http的请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。cookie的出现就是为了解决这个问题,第一次登陆服务器返回一些数据(cookie)给浏览器,然后浏览器保存到本地,当该用户第二次请求的时候,就会自动把上次请求存储的cookie数据自动的携带给服务器。服务器通过浏览器携带的数据就能判断当前用户是哪个了。cookie存储的数据量有限,不同浏览器有不同的存储大小,但一般不超过4kb。因此使用cookie只能存储一些小量的数据。
cookie的格式:
Set-cookie: NAME=VALUE Expires/Max-age=DATE Path=PATH Domain=DOMAIN_NAME SECURE
参数解释:
- NAME:cookie的名字
- VALUE:cookie的值
- Expires: cookie的过期时间。
- Path: cookie作用的路径。
- Domain: cookie作用的域名。
- SECURE:是否只在htps协议下起作用
2.使用cookielib库和HTTPCookieProcessor模拟登陆
2.1 手工复制cookie
Cookie是指网站服务器为了辨别身份和session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登陆信息到用户下次与服务器的会话。
实战演练:
- 不使用cookie,直接访问
from urllib import request
# 不使用cookie去登录主页
tmp_url = 'http://www.renren.com/238656222/profile'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
req = request.Request(url=tmp_url,headers=headers)
resp = request.urlopen(req)
# print(resp.read().decode())
# 将返回的网站源码写入到文件中
with open('renren.html','w',encoding='utf-8') as f:
f.write(resp.read().decode('utf-8'))
运行后,在浏览器打开下载的renren.html,如下:

- 使用cookie
打开谷歌浏览器的检查 -->> Network ,然后刷新页面:http://www.renren.com/238656222/profile 【前提是已经成功登录了】,找到下图中所示,即可得到cookie信息
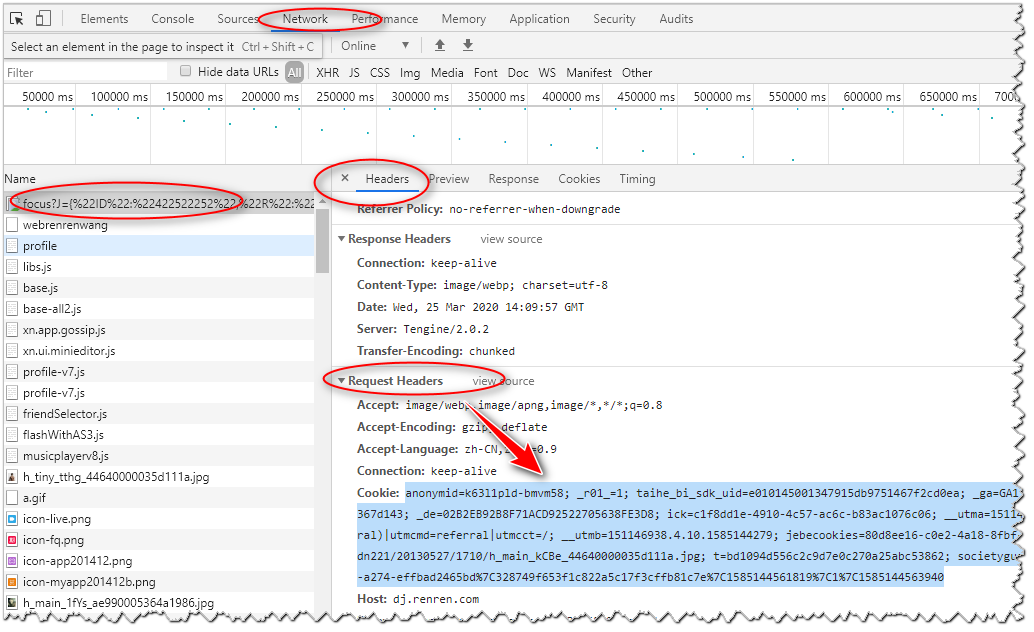
from urllib import request
tmp_url = 'http://www.renren.com/238656222/profile'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Cookie':'anonymid=k63l1pld-bmvm58; _r01_=1; taihe_bi_sdk_uid=e010145001347915db9751467f2cd0ea; _ga=GA1.2.1477590665.1580561077; depovince=GW; ick_login=b0a0dff4-179b-4cda-ae35-fbf3e97f9912; taihe_bi_sdk_session=602eb6642e983c664e81de65e367d143; _de=02B2EB92B8F71ACD92522705638FE3D8; ick=c1f8dd1e-4910-4c57-ac6c-b83ac1076c06; __utma=151146938.1477590665.1580561077.1580561077.1585144279.2; __utmc=151146938; __utmz=151146938.1585144279.2.2.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmb=151146938.4.10.1585144279; jebecookies=80d8ee16-c0e2-4a18-8fbf-7a53f40793e2|||||; p=7619396d7fce293085bc7b12b502a2da2; first_login_flag=1; ln_uact=18298377941; ln_hurl=http://hdn.xnimg.cn/photos/hdn221/20130527/1710/h_main_kCBe_44640000035d111a.jpg; t=bd1094d556c2c9d7e0c270a25abc53862; societyguester=bd1094d556c2c9d7e0c270a25abc53862; id=422522252; xnsid=ee08367c; ver=7.0; loginfrom=null; wp_fold=0; jebe_key=03183a84-908b-4464-a274-effbad2465bd%7C328749f653f1c822a5c17f3cffb81c7e%7C1585144561819%7C1%7C1585144563940'
}
req = request.Request(url=tmp_url,headers=headers)
resp = request.urlopen(req)
# print(resp.read().decode())
# 将返回的网站源码写入到文件中
with open('renren2.html','w',encoding='utf-8') as f:
f.write(resp.read().decode('utf-8'))
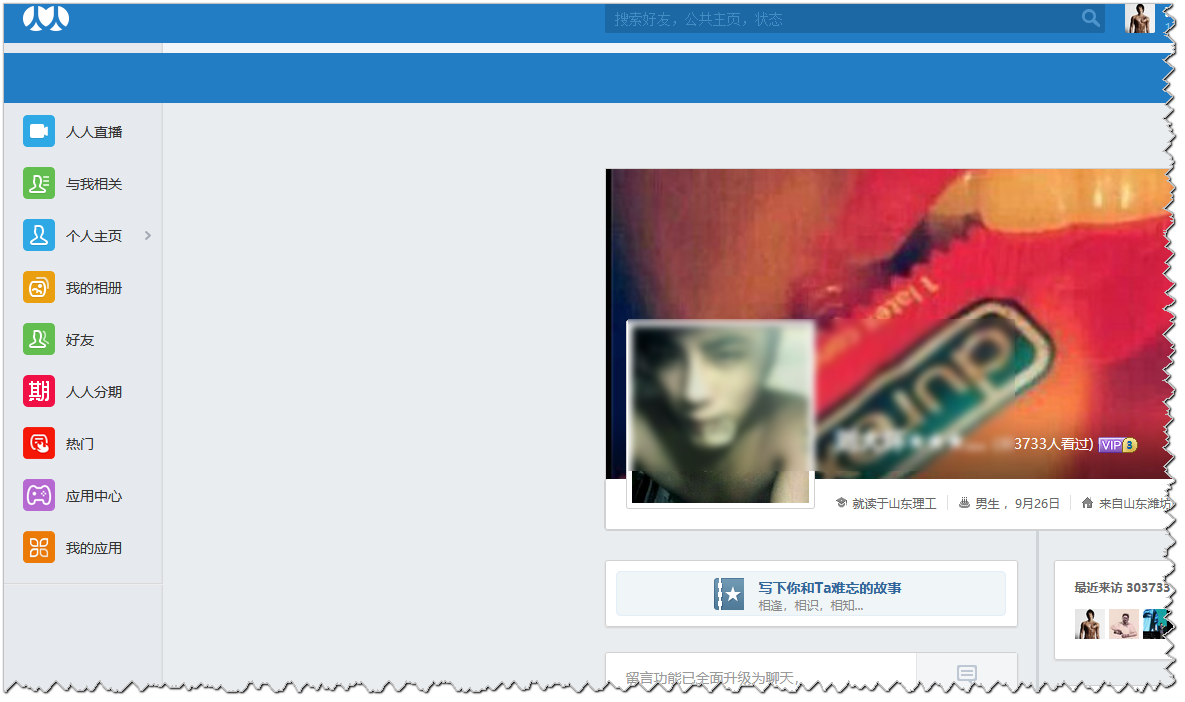
此时已经成功的登录到主页了
2.2 自动登录并授权访问
在【2.1 手工复制cookie】中,我们每次都需要手工去浏览器复制cookie比较麻烦,在Python处理cookie,一般是通过http.cookiejar模块和urllib模块的HttpCookieProcessor处理类一起使用。http.cookiejar模块主要作用是存储cookie对象。而HttpCookieProcessor处理类主要是处理这些cookie对象,并构建Handler对象。
- http.cookiejar模块
该模块主要的类有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。这四个类的作用分别如下:-
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
-
FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
-
MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。
-
LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
-
实战演练:利用http.cookiejar和HttpCookieProcessor登录人人网,并授权访问
from urllib import request
from urllib import parse
from http.cookiejar import CookieJar
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
def get_opener():
# 1.登录
# 1.1创建一个cookiesjar对象
cookiejar = CookieJar()
# 1.2使用cookiejar创建一个HTTPCookieProcessor对象
handler = request.HTTPCookieProcessor(cookiejar)
# 1.3使用上一步创建的handler创建一个opener
opener = request.build_opener(handler)
return opener
def login_renren(opener):
# 1.4使用opener发送登录的请求(人人网的邮箱和密码)
data = {
'email': '182xxxx',
'icode':'',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '1',
'captcha_type': 'web_login',
'password': '4b58ca16c38851fd1b6ca6be866e95d7dbce492e32c659be27a9403732b86b06',
'rkey': 'cb15f985754fd884a44506ff5db1256e',
'f': 'http%3A%2F%2Fwww.renren.com%2F422522252'
}
login_url = "http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2020232216437"
req = request.Request(login_url, data=parse.urlencode(data).encode('utf-8'), headers=headers)
opener.open(req)
print(request.urlopen(req).read().decode())
def visit_profile(opener):
# 2.访问主页
tmp_url = "http://www.renren.com/238656222/profile"
# 获取个人主页的页面的时候,不要新建一个opener
# 而是应该使用之前的那个opener,因为之前的那个opener已经包含了
# 登录所需要的cookie信息
req = request.Request(tmp_url, headers=headers)
resp = opener.open(req)
with open('renren3.html', 'w', encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
opener = get_opener()
login_renren = login_renren(opener)
visit_profile = visit_profile(opener)
上述代码中data中的信息来自浏览器,在Network下可以查看
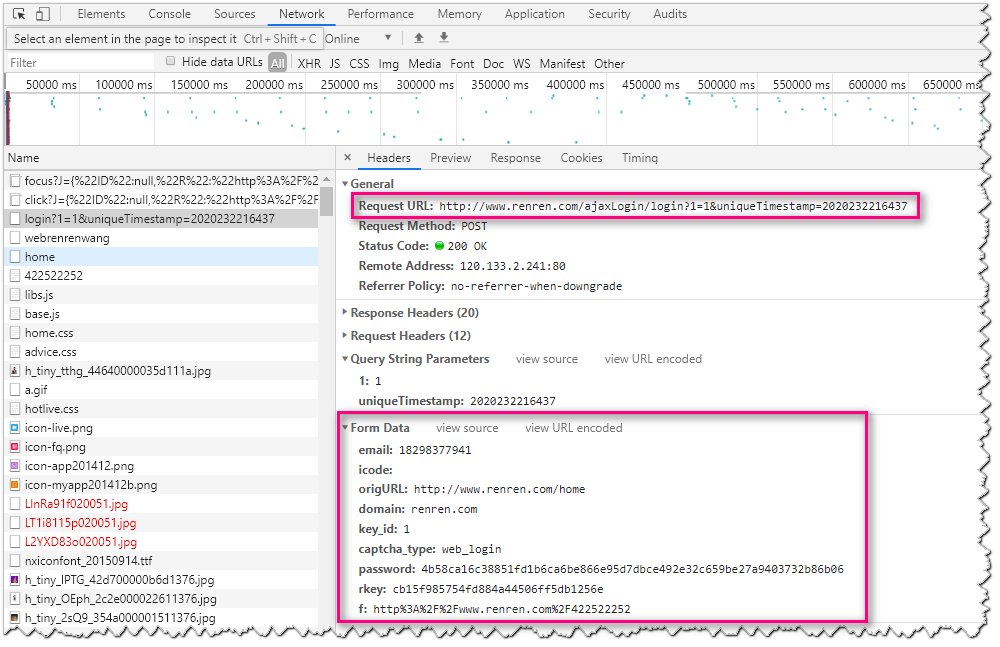
3.cookie信息的保存和加载
3.1 cookie信息的保存
保存cookie到本地,可以使用cookiejar的save方法,并且需要指定一个文件名
# Author:Logan
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookie.txt')
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
req = request.Request('http://httpbin.org/cookies/set?man=tom',headers=headers)
resp = opener.open(req)
print(resp.read())
cookiejar.save()
运行程序后,我们可以看到生成了一个cookie.txt文件,但是打开文件发现,并没有保存cookie,如下图:
接着打开浏览器观察,如下图:
接着查看目前在使用的Cookie如下图:
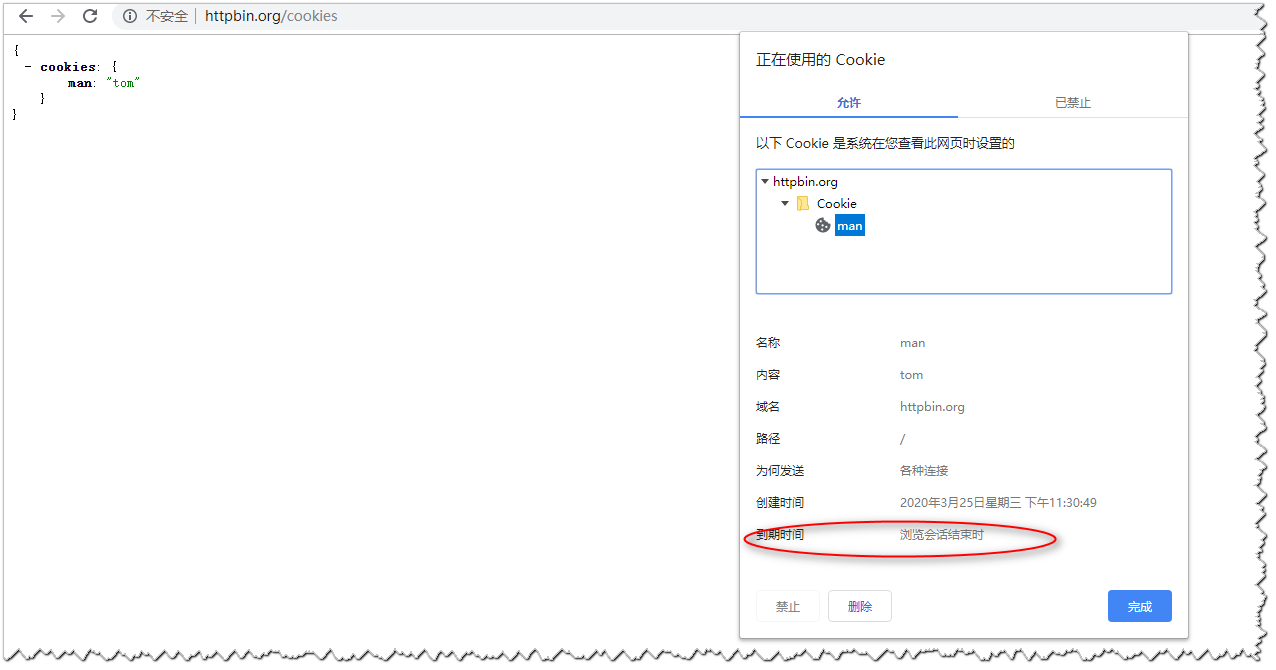
通过上图我们可以发现Cookie是在浏览器会话结束的时候cookie就到期了,所以我们的cookie中没有保存cookie
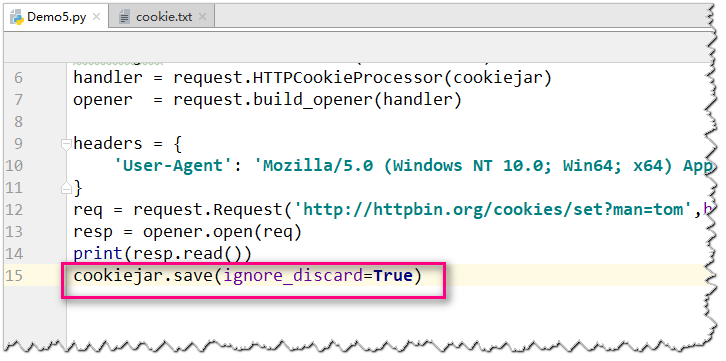
此时我们需要添加参数ignore_discard=True,修改点如下图标记部分
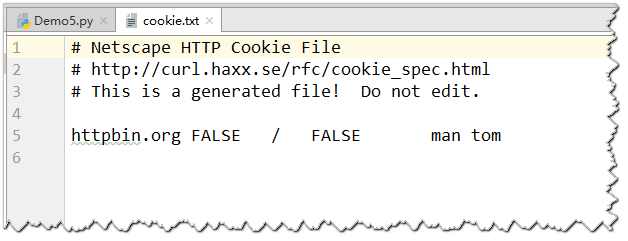
再次查看,可以看到cookie已经被保存了
3.2 cookie信息的加载
# Author:Logan
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookie.txt')
cookiejar.load(ignore_discard=True)
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
req = request.Request('http://httpbin.org/cookies',headers=headers)
resp = opener.open(req)
for cookie in cookiejar:
print(cookie)
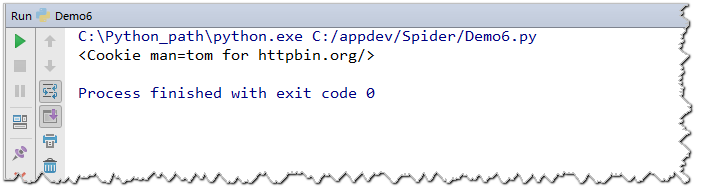
打印结果:
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

