【Python3 爬虫】U02_urllib库
1.urllib库简介
urllib库是Python中一个最基本的网络请求库,可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。
2.urlopen函数
在Python3的urllib库中,所有和网络请求相关的方法,都被集成到urllib.request模块下了,下面是urlopen函数的基本使用:
from urllib import request
resp = request.urlopen('http://sh.ganji.com/')
print(resp.getcode()) # 获取状态码
print(resp.read())
上述代码中使用resp.read()得到的源码与在浏览器中右键查看源代码得到的结果一致。
以下对urlopen函数进行详细介绍:
- url:请求的url
- data:请求的data,如果设置了这个值,那么将变成post请求
- 返回值,返回值是一个http.client.HTTPResponse对象,这个对象是一个类文件句柄对象。有
read(size),readline,readlines和getcode等方法;
3.urlretrieve函数
这个函数可以方便的将网页上的一个文件保存到本地,以下代码可以方便的将必应的首页下载到本地
from urllib import request
request.urlretrieve('https://cn.bing.com/','bing.html') # 只会下载源码到本地,图片等信息不下载
以下是根据一张图片的地址下载保存图片
from urllib import request
request.urlretrieve('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1585112393443&di=d6bbee92689405bc16dd4c6e3f001498&imgtype=0&src=http%3A%2F%2Fa3.att.hudong.com%2F68%2F61%2F300000839764127060614318218_950.jpg','download.jpg')
4.参数编码和解码
4.1 编码urlencode函数
用浏览器发送请求的时候,如果url中包含了中文或者其他特殊字符,那么浏览器会自动给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就使用urlencode函数来实现。urlencode可以将字典数据转化为URL编码数据
实战演练:
from urllib import parse
data = {'name':'张三','age':'18'}
trans = parse.urlencode(data)
print(trans)
运行结果:name=%E5%BC%A0%E4%B8%89&age=18
4.2 解码parse_qs函数
可以通过parse_qs对上述结果进行解码操作
from urllib import parse
data = 'name=%E5%BC%A0%E4%B8%89&age=18'
trans = parse.parse_qs(data)
print(trans)
运行结果:{'name': ['张三'], 'age': ['18']}
5.urlparse和urlsplit
有时候拿到一个url,想要对每个url的组成部分进行分割,那么此时就可以使用urlparse和urlsplit来操作。
实例代码:
from urllib import parse
url = 'https://cn.bing.com/search?q=python3'
result1 = parse.urlsplit(url)
result2 = parse.urlparse(url)
print(result1)
print(result2)
# 得到分割后的信息
print(result1.scheme)
print(result1.netloc)
print(result1.path)
print(result1.query)
print(result1.fragment)
运行结果:
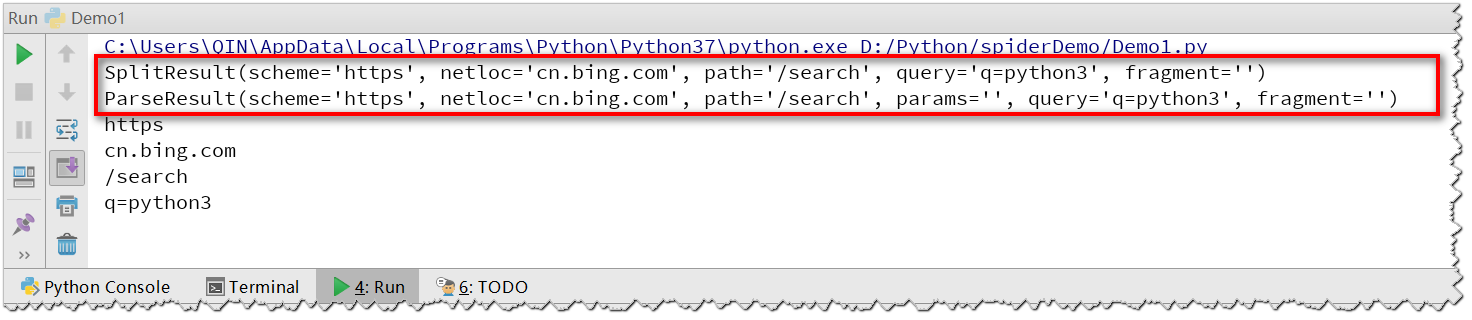
urlsplit和urlparse基本是一模一样的,唯一不同的就是urlparse多了一个params属性。
6.request.Request类
如果想要在请求的时候增加一些请求头,那么就必须使用request.Request类来实现,例如:在爬虫中增加User-Agent
- 直接使用urlopen爬取
# 直接使用urlopen爬取拉勾网,由于拉勾网做了反爬虫机制,所以无法直接爬取
from urllib import request
url = 'https://www.lagou.com/zhaopin/Python/?labelWords=label'
resp = request.urlopen(url)
print(resp.read())
- 添加User-Agent头信息
from urllib import request
url = 'https://www.lagou.com/zhaopin/Python/?labelWords=label'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
req = request.Request(url,headers=headers)
resp = request.urlopen(req)
print(resp.read().decode())
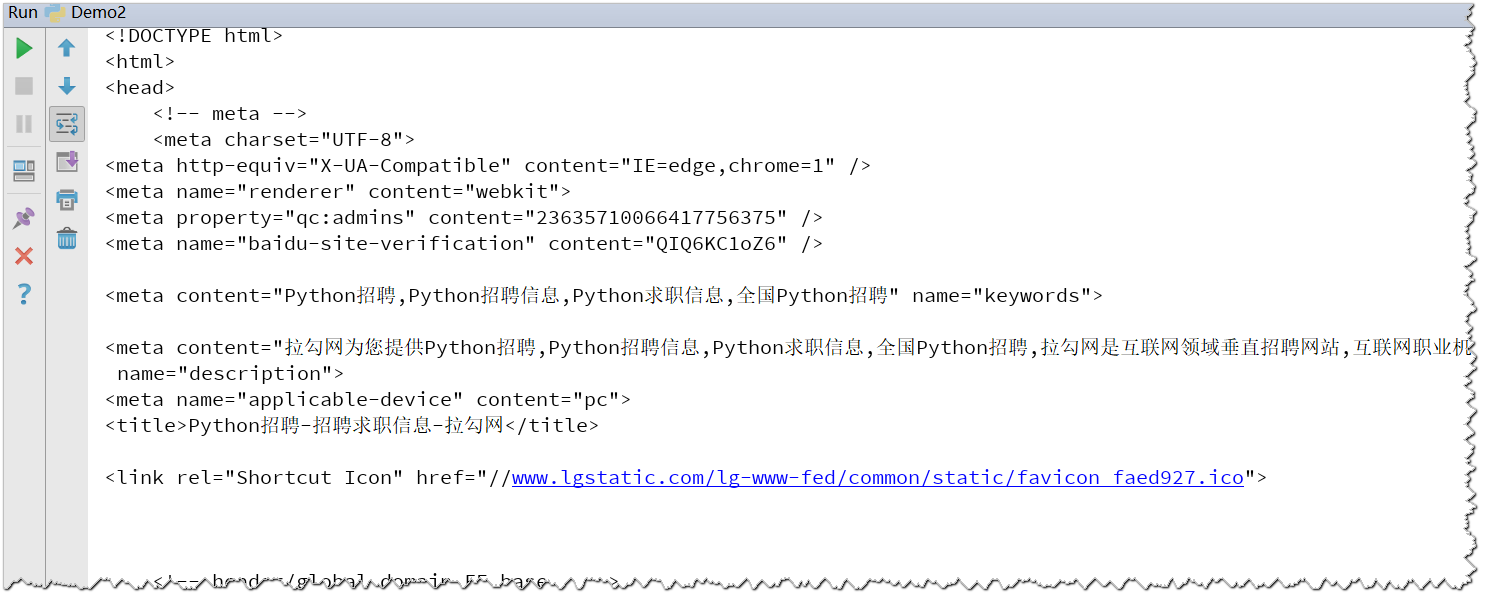
运行结果:
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!


