【Python3 爬虫】U01_爬虫简介
1.什么是网络爬虫?
通俗理解:爬虫就是一个模拟人类请求网站行为的程序。可以自动请求网页,并将数据抓取下来,然后使用一定的规则提取有价值的数据。
2.爬虫的分类
- 通用网络爬虫
百度 谷歌 雅虎...搜索引擎
特点:关键字获取既定的目标,覆盖率很大
- 聚焦网络爬虫
特点:到互联网上有选择有目的去抓取特定的目标和相关的主题内容。
- 增量式网络爬虫
特点:只采取增量式的更新或者是只爬取新产生或者是已经发生变化的网页。
- 深层网络爬虫
- 表层
- 深层 大部分内容是不可以通过静态链接获取到的,隐藏在搜索表单之后的一些数据,有可能需要用户提交一些关键词才可以获得的WEB页面
3.为什么用Python写爬虫
- PHP:PHP是世界上最好的语言,但是它天生不是做这个的,而且对于多线程、异步支持也不是很好,并法处理能力弱。爬虫是工具性程序,对速度和效率要求比较高。
- Java:生态圈很完善,是Python爬虫最大的竞争对手。但是Java语言本身很笨重,代码量很大。重构成本比较高,任何修改都会导致代码大量改动。爬虫经常需要修改采集代码。
- c/c++:运行效率是最高的。但学习和开发成本高,需要自己造轮子。写个小爬虫程序可能需要大半天的时间。
- Python:语法优美、代码简洁、开发效率高、支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富,还有Scrapy框架让我们开发爬虫变得异常简单。
4.HTTP协议
4.1 什么是HTTP和HTTPS协议?
| 简称 | 全称 | 描述 | 端口 |
|---|---|---|---|
| HTTP | HyperText Transfer Protocol | 超文本传输协议 | 80 |
| HTTPS | Hyper Text Transfer Protocol over SecureSocket Layer | HTTP下加入了SSL层 | 443 |
4.2 HTTP请求过程
我们在浏览器的地址中输入一个URL地址并按回车之后,浏览器会向HTTP服务器发送HTTP请求。网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等,浏览器再对其进行解析,并将网页呈现了出现。HTTP请求主要分为get和post两种方法。
4.3 url详解
URL是Uniform Resource Locator的简写,统一资源定位符。
一个URL有以下几部分组成:
schema://host:port/path/?query-string=xxx#anchor
- scheme:代表的是访问的协议,一般是http或者https
- host:主机名,域名,比如:www.baidu.com
- port:端口号
- path:查找的路径
- query-string:查询字符串,比如:
www.baidu.com/s?wd=python,后面的wd=python就是查询字符串 - anchor:锚点,后台一般不用管,前端用来做页面定位的。
4.3 常见的请求头
在http协议中,定义了8种请求方法,此处只是介绍常用的请求方法,分别是get和post。
-
get请求
一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求 -
post请求
向服务器发送数据(登录)、上传文件等。会对服务器资源产生影响的时候回使用post请求。
以上是在网站开发中常用的两种方法。并且一般情况下都会遵守使用的原则。但是由的网站和服务器为了做反爬虫机制,也经常会不安常理出牌。
4.4 请求头常见参数
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个是把数据放在body中(在post请求中),第三个就是把数据放在head中。此处只介绍常见的请求头:
- User-Agent
浏览器名称。这个在网络爬虫中经常被用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的。如果我们不设置User-Agent,那么我们在爬取网站的时候,User-Agent就是Python,这样很容易就被识别为爬虫了。 - Referer
表明当前这个请求时从哪个url过来的。这个一般也可以用来做反爬虫技术,如果不是从指定页面过来的,那么就不做相关的响应。 - Cookie
http协议是无状态的。也就是同一个人发送了2次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候用cookie来做识别。一般如果想要做登陆后才能访问的网站,那么就需要发送cookie信息了。
4.5 常见的响应状态码
| 状态码 | 说明 | 详情 |
|---|---|---|
| 200 | 成功 | 服务器已经成功处理了请求 |
| 301 | 永久重定向 | 比如在访问了www.jingdong.com,被重定向到了www.jd.com |
| 302 | 临时重定向 | 比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录页面 |
| 400 | 请求的url在服务器上找不到 | url请求错误 |
| 403 | 拒绝访问 | 服务器拒绝此请求 |
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求 |
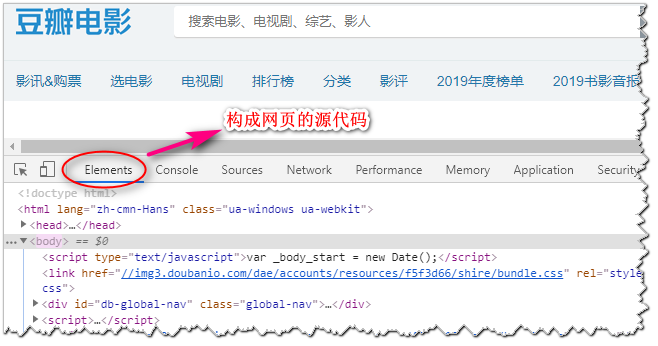
5.Chrome抓包工具
通过右键-->>检查 或者F12都可以打开谷歌浏览器的开发者工具。下图说明:


声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

