【Python数据分析】pandas去重和替换
1.去重复:duplicated
import pandas as pd
s = pd.Series([1,1,1,1,2,2,2,3,3,4,4,5,6])
# 通过duplicated判断是否重复
print(s.duplicated())
# 通过布尔判断,得到不重复的值
print(s[s.duplicated() == False])
# 移除重复drop_duplicates
s_re = s.drop_duplicates()
print(s_re)
# Dataframe中使用duplicated
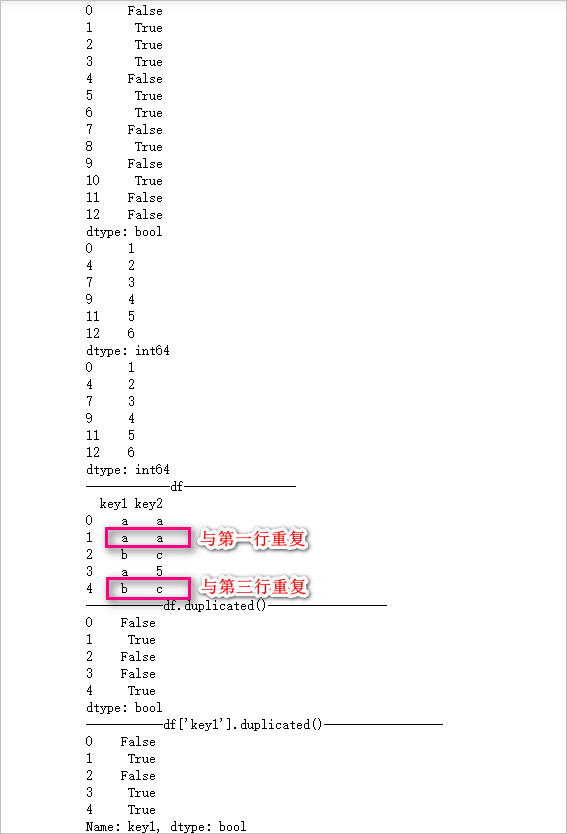
df = pd.DataFrame({'key1':['a','a','b','a','b'],
'key2':['a','a','c',5,'c']
})
print('------------df----------------')
print(df)
print('-----------df.duplicated()-----------------') # 第2行与第1行重复了,所以为True,第5行与第3行重复,所以为True
print(df.duplicated())
print('-----------df[\'key1\'].duplicated()-----------------')
print(df['key1'].duplicated())
输出结果:
2.替换:replace
import pandas as pd
import numpy as np
s = pd.Series(list('aseaasasx'))
print(s.replace('a', np.nan)) # 替换a为np.nan
print(s.replace(['a','s'], np.nan)) # a替换为s,然后再将s替换为np.nan
print(s.replace({'a':'@@@','s':'***'})) # 一次性替换为多个值
输出结果:

作者:奔跑的金鱼
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号