正则表达式
示例:京东注册页面的手机号格式验证
要求:限制字符串为纯数字,并且位数为11,且开始只能是13,15,16,17,18,19
方式一:python代码实现
phone_num = input('手机号:').strip() # 获取用户输入的手机号
if phone_num.startswith('12') or
phone_num.startswith('13') or
phone_num.startswith('15') or
phone_num.startswith('16') or
phone_num.startswith('17') or
phone_num.startswith('18') or
phone_num.startswith('19'): # 判断手机号的起始两位
if len(phone_num) == 11: # 判断手机号的位数
if phone_num.isdigit(): # 判断是否是纯数字
print('right')
else:
print('手机号码纯数字')
else:
print('位数不对')
else:
print('格式不对')
方式二:正则表达式实现
import re # 正则需要导入re模块才能在python代码内使用
phone_num = input('手机号:').strip() # 获取用户输入的手机号
print('right') if re.match('^(13|15|16|17|18|19)[0-9]{9}$', phone_num) else print('wrong')
很明显,正则表达式的代码相比于直接用if语句代码验证简介很多
正则表达式
正则表达式是独立的用来匹配、检验数据的一门语言,编程语言可用,在python中使用正则表达式需要导入re模块
1. 正则表达式的形式
是用特殊字符组成的一系列具有不同作用的字符组合所构成的句式 **
2. 学习方法**
学习特殊字符组合的作用
正则表达式之字符组
1. 形式:[……]
**2. 作用:逐一匹配中括号内部出现的字符, **
'''
表达式 作用
[0-9] 匹配0-9内的所有数字
[a-z] 匹配a-z内的所有小写字母
[A-Z] 匹配A-Z内的所有大写字母
[0-9a-zA-Z] 匹配0-9内的所有数字和a-z内的所有小写字母和A-Z内的所有大写字母
'''
正则表达式之特殊符号
由字符组成的具有不同作用的符号组合
'''
字符 作用
. 匹配换行符之外的所有字符
\w 匹配单个数字、字母、下划线
\d 匹配单个任意数字
\t 匹配单个制表符
^ 匹配必须在开头位置的指定字符
$ 匹配必须在末尾位置的指定字符
\W 匹配非(数字、字母、下划线)
\D 匹配非数字
a|b 匹配a或者b | 是或者的意思
() 给表达式分组
[] 字符组的概念符号
[^] 在中括号里出现^的时候表示取反,即不取^后的字符
'''
正则表达式之量词
量词是需要跟在表达式后面的字符,不能单独使用,默认是贪婪匹配
'''
* 重复零次或多次 默认尽可能多次
+ 重复依次或多次 默认尽可能多次
? 重复零次或一次 默认一次
{n} 重复n次
{n,} 重复至少n次 默认尽可能多次
{n,m} 重复n-m次 默认尽可能多,但不多于m次,不少于n次
'''
课堂练习内容
'''
表达式 文本 结果
海. 海燕海娇海东 3条
^海. 海燕海娇海东 1条
海.$ 海燕海娇海东 1条
李.? 李杰和李莲英和李二棍子 3条
李.* 李杰和李莲英和李二棍子 1条
李.+ 李杰和李莲英和李二棍子 1条
李.{1,2} 李杰和李莲英和李二棍子 3条
李[杰莲英二棍子]* 李杰和李莲英和李二棍子 3条
李[^和]* 李杰和李莲英和李二棍子 3条
\d+ 456bdha3 2条
'''
复杂正则表达式
复杂正则表达式只需要在能看懂的基础上去网络上查找别人写好的表达式即可
取消转义
'''
\n \n False
\\n \n True
\\\\n \\n True
在python中还可以在字符串的前面加r取消转义 更加方便
'''
在每个\的前面都需要加一个\来取消\与其他字母组合的作用
贪婪匹配与非贪婪匹配
在正则表达式之量词中我们提到量词默认都是贪婪匹配,即尽可能多的匹配指定内容;只需要在量词后面加?便可以将贪婪匹配改为非贪婪匹配。贪婪与非贪婪匹配都是以两边的特殊字符作为起始依据
'''
表达式 匹配内容 结果
<.*> <start>nate666<end> 1条 <start>nate666<end> 最后的>作为结束
<.*?> <start>nate666<end> 2条 <start> <end> 出现>就是结束标志
'''
re模块
python中是无法直接使用正则表达式的,需要借助内置的re模块才能使用
re模块的内置放法
findall
import re # 导入re模块
res = re.findall('e', 'oliver kevin jerry') # 匹配文本里的所有指定字符,并将找到的组成列表返回
print(res)

search
import re # 导入re模块
res1 = re.search('e', 'oliver kevin jerry') # 匹配一个文本里的指定字符并返回,找不到的时候返回None
print(res1)
print(res1.group()) # 通过调用group查看返回的数据,返回值为None时调用group的话会报错

match
import re # 导入re模块
res2 = re.match('e', 'oliver kevin jerry') # 从字符串开始匹配,开头不是直接返回None(类似于^),开头是也只匹配这一个
print(res2.group()) # 通过调用group查看返回的数据,返回值为None时调用group的话会报错

import re # 导入re模块
res3 = re.match('o', 'oliver kevin jerry')
print(res3.group()) # 通过调用group查看返回的数据

finditer
import re # 导入re模块
res4 = re.finditer('e', 'oliver kevin jerry') # 匹配所有的指定字符,返回值是迭代器对象
print(res4) # <callable_iterator object at 0x000001B0583FB4E0>
print([[index.group()] for index in res4]) # [['e'], ['e'], ['e']]

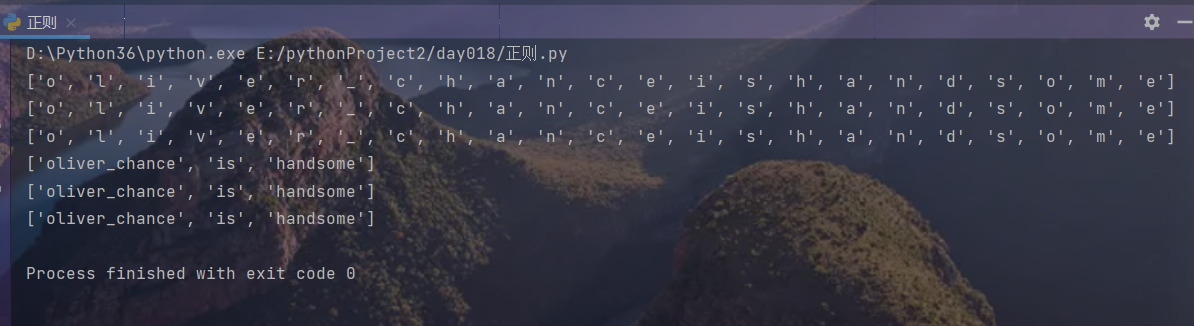
compile
import re # 导入re模块
obj = re.compile('\w') # 逐一地匹配所有的数字,字母,下划线
print(re.findall(obj, 'oliver_chance is handsome')) # 迭代器多次调用
print(re.findall(obj, 'oliver_chance is handsome'))
print(re.findall(obj, 'oliver_chance is handsome'))
obj1 = re.compile('\w+') # 尽可能多地匹配所有的数字,字母,下划线
print(re.findall(obj1, 'oliver_chance is handsome')) # 因为空格不在\w的匹配范围,所以空格处断开
print(re.findall(obj1, 'oliver_chance is handsome'))
print(re.findall(obj1, 'oliver_chance is handsome'))
正则表达式结束


