字符编码及其应用
字符编码
字符编码简介
字符编码的主要对象是文本文件提前我们需要了解文本编辑器读取文件的流程以及python解释器执行文件的流程
- 文本编辑器读取文件的基本流程
- 第一阶段:启动一个文本编辑器
- 第二阶段:文本编辑器会将硬盘里的内容读取到内存里
- 第三阶段:文本编辑器将内存里的内容显示到屏幕上

- python解释器执行文件的基本流程
- 第一阶段:启动python解释器
- 第二阶段:python解释器将硬盘里的内容读取到内存里
- 第三阶段:python解释器开始执行文件里的内容,自动识别python语法
字符编码发展史
字符编码就是内部存储了数字与人类字符的对应关系
- 一家独大时期(ASCII)
由于计算机的起源是美国,所以刚开始的时候让计算机认识美国语言的重要性就凸显出来了。之后就诞生了美国的ASCII码,定义了数字与英文字符的对应关系
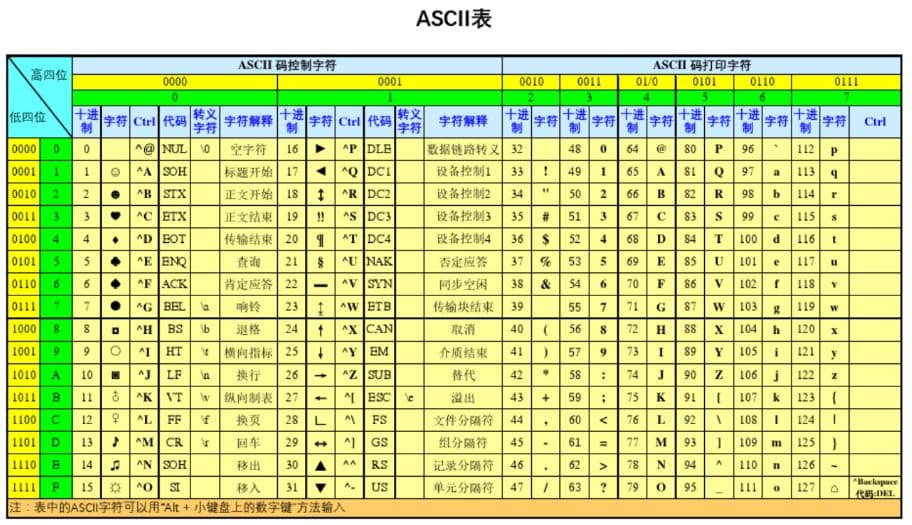
2.群雄割据时期(GBK、Euc_kr、shift_JIS)
随着计算机技术的发展,其他国家相继也拥有资本去使用计算机,然后就发现计算机只认识英文,怎么让计算机识别自己国家的语言就成了当时的问题,之后中国、韩国、日本相继制定了GBK、Euc_kr、shift_JIS码,分别增加了计算机对本土语言的识别问题。此时出现了一种现象,就是不同编码的计算机之间的文件传输会出现乱码现象。
3.天下一统时期(unicode:又称万国码)
unicode根据翻译过来的中文名字可以理解,就是该编码包含了多个国家的字符对数字的对应关系。不过这里需要注意的是万国码对于任何字符最想都要用两个字节进行存储,对于某些字符可能不需要两个字节进行对应,这就造成了存储空间的浪费以及读写时间的延长。所以后来就又开发了另一款编码:utf_8。utf_8编码优化了万国码的存储数据浪费空间的问题,英文字符用1字节存储。

注:内存里用的是unicode,硬盘里用的utf_8
字符编码的实际应用
编码与解码
编码:就是指将人类能够读懂的字符编码为计算机能够直接读懂的字符。
解码:就是指将计算机能够直接读懂的字符解码为人类能够读懂的字符。
编码与解码示例:
str1 = '中国牛批'
print(str1.encode('gbk')) # 将'中国牛批'编码成gbk形式
code1 = b'\xd6\xd0\xb9\xfa\xc5\xa3\xc5\xfa'
print(code1.decode('gbk')) # 将b'\xd6\xd0\xb9\xfa\xc5\xa3\xc5\xfa'解码成认了可识别的字符
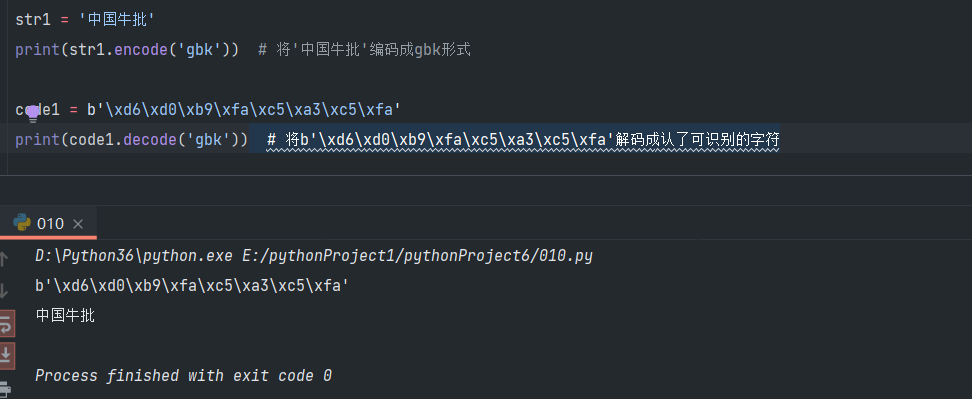
注:编码时输出结果加b,表示输出的结果是bytes类型,类似于二进制。并且网络传输的数据都是二进制格式,所以在进行数据传输时必定涉及到编码与解码
乱码问题
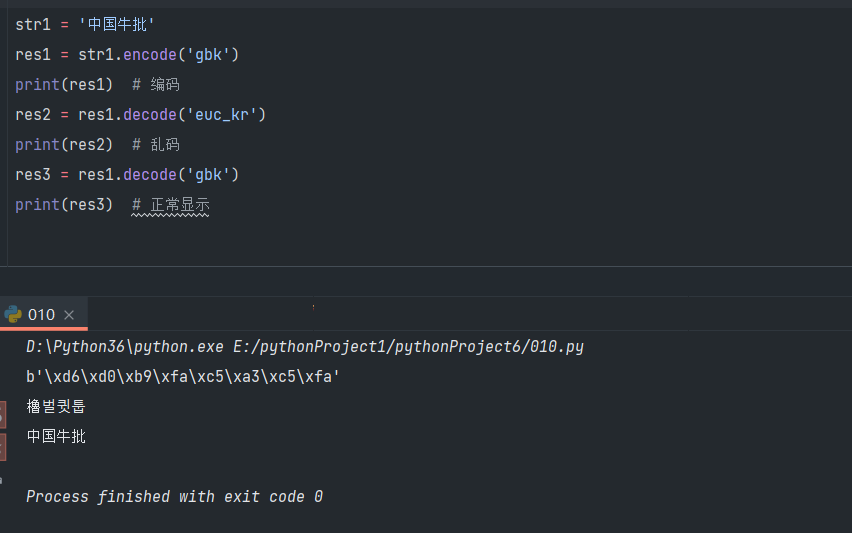
只需要记住用什么码编码,就用什么码解码,否则就会产生乱码
str1 = '中国牛批'
res1 = str1.encode('gbk')
print(res1) # 编码
res2 = res1.decode('euc_kr')
print(res2) # 乱码
res3 = res1.decode('gbk')
print(res3) # 正常显示
python解释器问题
 这里主要需要注意的是python2与python3的区别
1.python2解释器磨人的编码是ASCII码,原因就是python2的出现时间较早,当时并没有统一的编码。在遇到其他编码的文件用python2进行操作时,需要注意的是需要加文件头或者是字符前缀。
- 文件头:在文件最上方,告诉解释器文件使用的编码类型
coding:utf8 - 字符前缀:在使用python2时定义字符串习惯性在前面加 u ,作用就是规定字符串的编码类型
name = u'中国牛批'
文件操作
文件就是操作系统暴露给用户的可以直接操作硬盘的快捷方式
使用代码操作文件的流程
- 第一步:打开文件、创建文件
- 第二步:编辑文件内容
- 第三步:保存文件内容
- 第四步:关闭文件
基本的语法结构
结构一(了解不常用):
f1 = open(文件路径(在该项目里,可以用相对路径;不在的话用绝对路径))
fi.close()
结构二(推荐使用):
with open() as f:
pass
使用关键字打开
- 文件打开
open(r'文件路径'(相对路径或者绝对路径))
file1 = open(r'文件路径',文件操作模式, 文件的编码类型)
注:1、这里在文件路径前加的r主要作用是为了防止特殊符号。2、文件的操作模式和文件的编码有时不用写
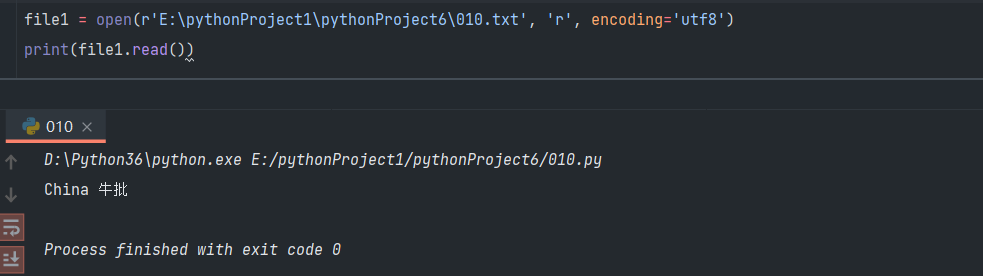
2.文件读取
print(file1.read()) # 读取文件
file1.close() # 关闭文件
- with上下文管理
在平时我们写代码的时候最后关闭文件的代码容易被遗忘,with可以帮我们避免这一问题,with在代码运行完毕后会自动关闭已经打开的文件。如果我们将读取的文件内容赋值给另外的变量名的话,关闭文件并不影响该变量的调用和访问。
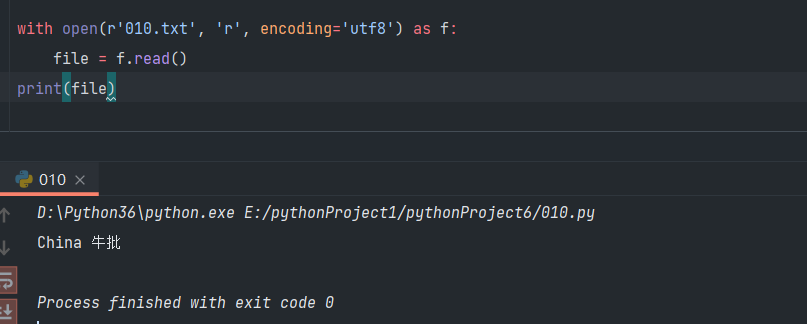
with open() as f:
file = f.read()
print(file)
文件的读写模式
文件的读写分为三种模式:只读、只写和追加模式(只能在文章末尾添加内容)
- 只读 r (read) 只能读取,不能写入
- 只写 w (write) 只能写入,不能读取
- 尾部追加 a (append) 只能在文本的末尾追加内容
只读‘r’模式
只读模式下,如果路径不存在时会直接报错,而且只读模式的默认字符编码是计算机默认的编码类型。
with open(r'文件路径', 'r', encoding = 'utf8') as f: # 打开文件为f
print(f.read()) # 读取内容
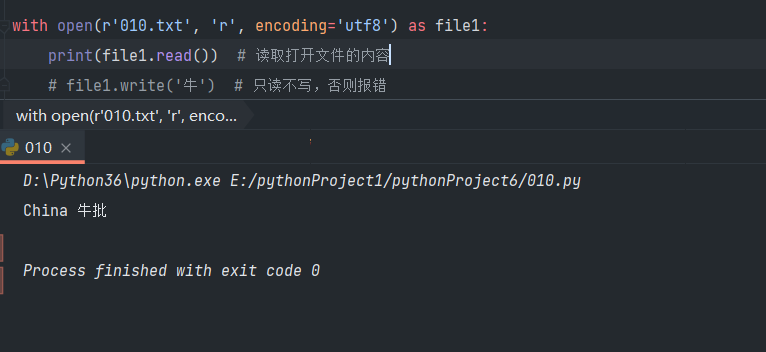
注:只读模式不能写入信息,否则会报错
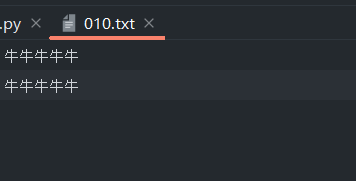
只写‘w’模式
只写模式下,如果路径不存在时,会直接创建新文件,并将信息写入新创键的文件;如果路径存在,会先将该文件清空然后再进行写入操作。
with open(r'文件路径', 'w', encoding = 'utf8') as f: # 打开文件为f
f.write('牛牛牛牛牛\n牛牛牛牛牛') # 写入文件的内容
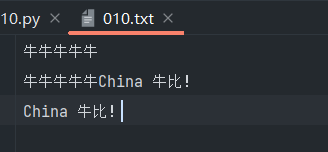
尾部追加(append)
追加模式下,路径不存在的时候直接创建新文件;路径存在时不像只写模式会删除原有数据,a模式不删除原有数据,并且会将要添加的数据添加到该文件里。
with open(r'文件路径', 'a', encoding = 'utf8') as f: # 打开文件为f
f.write('China牛比 ! \nChina牛比 !') # 写入文件的内容
print(f.read()) # 读取内容
附:中间提到了补全语法结构但是没有任何意义的两个关键字:pass和...作用相同,都是补全语法结构,没有其他意义
文件的操作模式
文件的操作模式有两个大的模式:t模式和b模式
- t 模式:指的是文本模式,文件操作的默认模式就是文本模式。需要注意的有三点:
- 只能操作文本文件
- 必须指定encoding参数
- 读写的最小参数都是字符串
- b (bytes)模式:二进制模式,可操作任意类型文件。需要注意的有四点:
- 这里的读、写和追加操作为'rb', 'wb', 'ab'且此处的 b 不可省略
- 可操作任意类型的文件
- 不需要指定encoding参数,默认为计算机默认编码类型
- 读写都是以bytes类型为最小单位
文件的内置方法
- 一次性读取文件内容:read() 不会再次读取
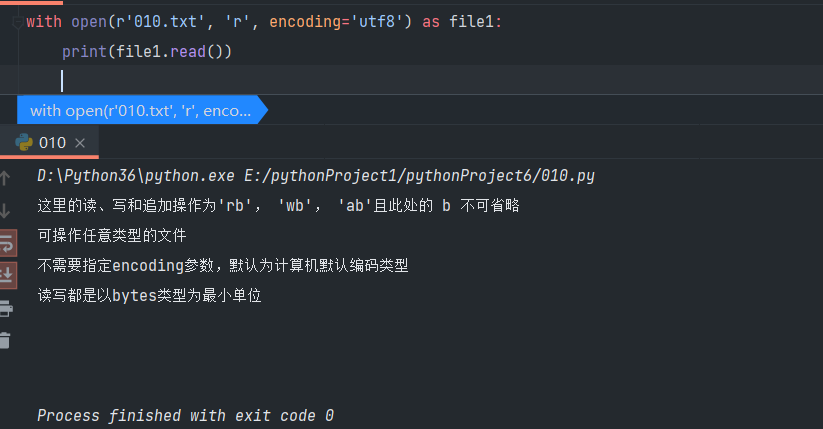
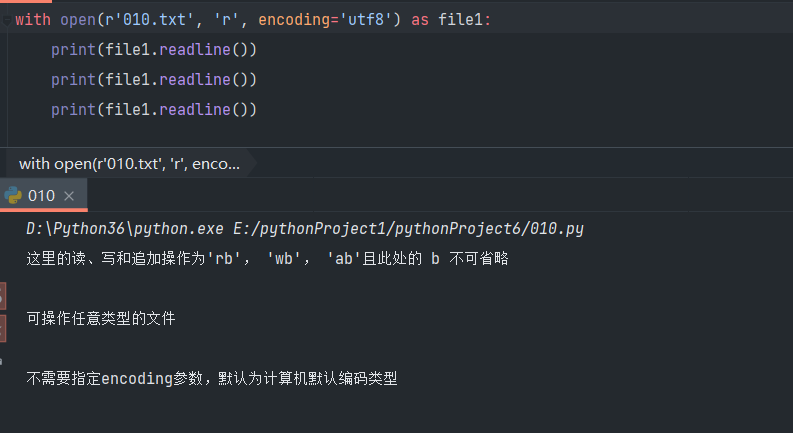
- 一次只读一行文件内容:readline()
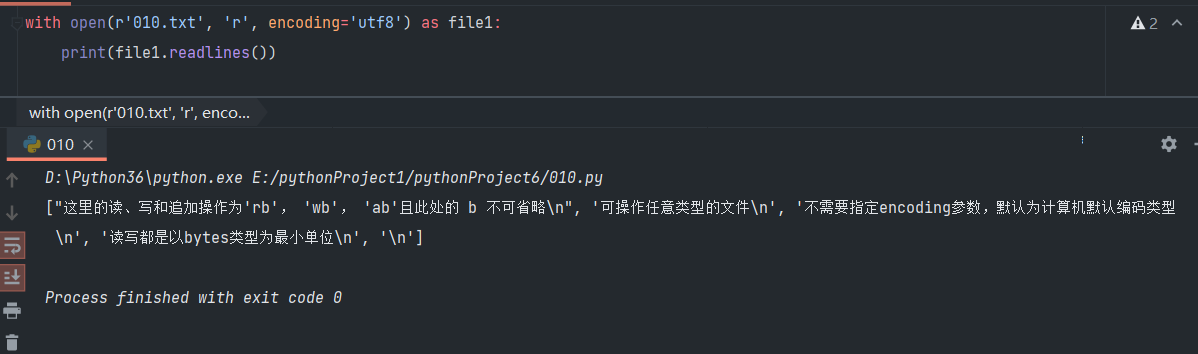
- 一次读取所有内容,每一行数据成为一个字符串,所有字符串生成一个列表:readlines()
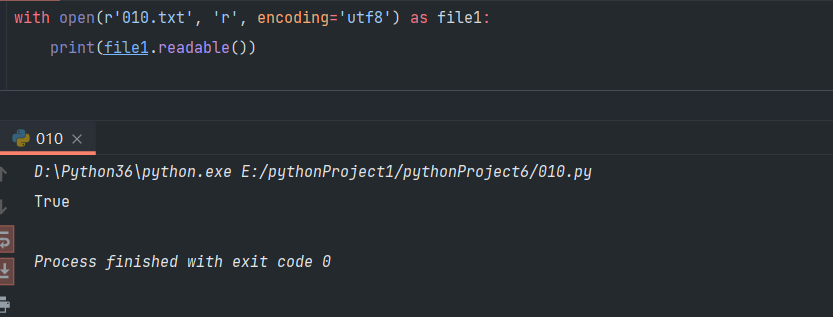
- 判断文件是否可读取:readable()
-
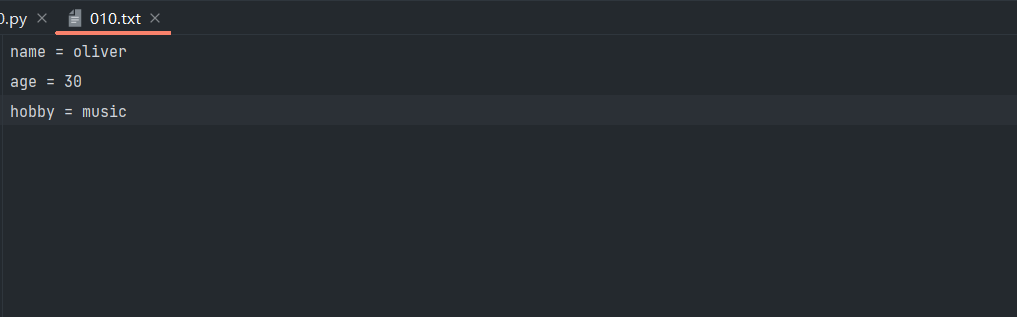
写入文件内容:write()
with open(r'010.txt', 'w', encoding='utf8') as file1: file1.write('name = oliver\nage = 30\nhobby = music')
-
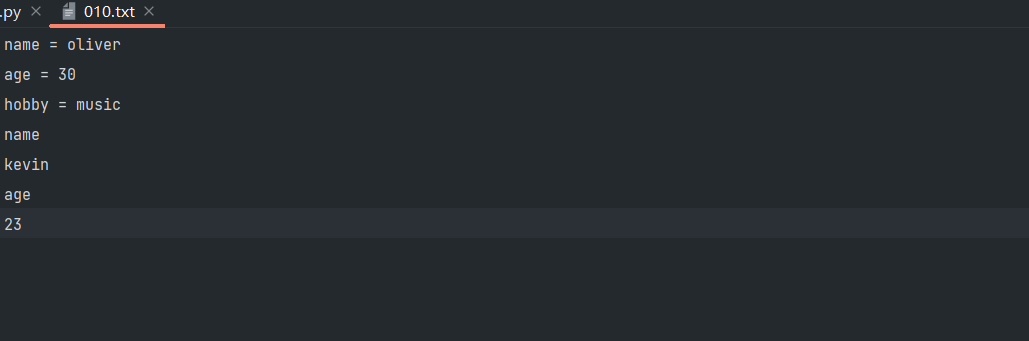
写入列表里的每个元素:writelines()
with open(r'010.txt', 'w', encoding='utf8') as file1:
file1.write('name = oliver\nage = 30\nhobby = music')
file1.writelines(['\nname\n', 'kevin\n', 'age\n', '23'])
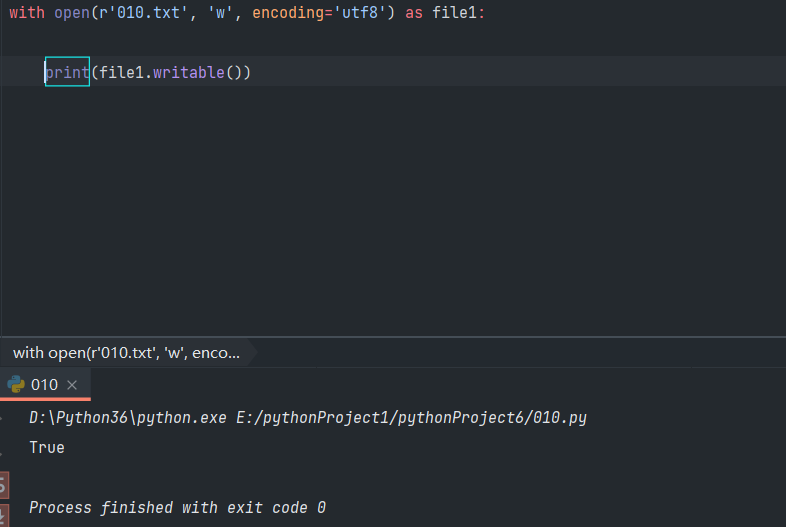
- 判断文件是否可写:writable()
- 保存文件(相当于ctrl + s):flush()
就这么没了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号