
《算法图解》第五章笔记与课后练习_散列函数与散列表
软件环境:Python 3.7.0b4
一、散列函数
无论你给它什么数据,它都还你一个数字。它必须满足一些要求:
- 它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都必须为4。
- 它应将不同的输入映射到不同的数字。例如,如果一个散列函数不管输入是什么都返回1,那它就不是好的散列函数。最理想的情况是 将不同的输入映射到不同的数字。
使用函数dict来创建散列表
>>> book = dict() >>> book["apple"] = 0.67 # 一个苹果的价格是67美分 >>> book["milk"] = 1.49 >>> book["avocado"] = 1.60 >>> print(book) {'apple': 0.67, 'milk': 1.49, 'avocado': 1.6} >>> print(book["milk"]) 1.49 # 牛奶的价格
散列表由键和值组成。在前面的散列表book中,键为商品名,值为商品价格。散列表将键映射到值。

二、应用案例
1,将散列表用于查找
假设你要创建一个电话簿,将姓名映射到电话号码。该电话簿需要提供如下功能:
- 添加联系人及其电话号码。
- 通过输入联系人来获悉其电话号码。
下面我们来使用散列表进行对电话簿的创建映射和查找。

2,防止重复
假如你负责管理一个投票站,每个人只能投一票,如何避免重复投票呢?
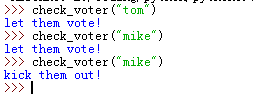
voted = {} # 创建一个散列表
def check_voter(name):
if voted.get(name): # 检查他是否在散列表中
print("kick them out!")
else:
voted[name] = True
print("let them vote!")
3,将散列表用作缓存
缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中。
缓存的优点:
- 用户能够更快地看到网页。
- 服务器需要做的工作很少。
cache = {} def get_page(url): if cache.get(url): return cache[url] # 返回缓存的数据 else: data = get_data_from_server(url) cache[url] = data # 先将数据保存到缓存中 return data
说明:仅当URL不在缓存中时,让服务器做这些处理,并将处理生成的数据存储到缓存中,再返回它。这样,当下次有人请求该URL时,你就可以直接发送缓存中的数据,而不用再让服务器进行处理,耗费资源。
三、小结
- 可以结合散列函数和数组来创建散列表。
- 散列表的查找、插入和删除的操作速度都非常快。
- 散列表适合用于模拟映射的关系。
- 散列表可用于缓存数据(例如在Web服务器上)。
- 散列表非常适合用于防止重复。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号