quartz分布式搭建,把单机模式修改为分布式
quartz的分布式搭建也很多,但是由于每个项目的结构不同,采用的方式也不同。我们公司的项目原来采用的quartz的单机版。但是由于采用redis作为缓存,两个tomcat作为应用服务器。那么quartz理所应当的要进行分布式升级。
先看看原来采用的方式。
public class QuartzManager {undefined
private static SchedulerFactory gSchedulerFactory = new StdSchedulerFactory();
private static String JOB_GROUP_NAME = “EXTJWEB_JOBGROUP_NAME”;
private static String TRIGGER_GROUP_NAME = “EXTJWEB_TRIGGERGROUP_NAME”;
//QuartzTask 为自己建立的定时任务表表结构以及数据格式是这个样子的,我们的定时任务不是采用xml的定时器方式存储的,是放在了数据库里面

public static void addJob(String jobName, Class cls, String time,QuartzTask task) { try { Scheduler sched = gSchedulerFactory.getScheduler(); JobDetail jobDetail = new JobDetail(jobName, JOB_GROUP_NAME, cls);// 任务名,任务组,任务执行类 jobDetail.getJobDataMap().put("task", task); CronTrigger trigger = new CronTrigger(jobName, TRIGGER_GROUP_NAME);// 触发器名,触发器组 trigger.setCronExpression(time);// 触发器时间设定 sched.scheduleJob(jobDetail, trigger); // 启动 if (!sched.isShutdown()) { sched.start(); } } catch (Exception e) { throw new RuntimeException(e); } }
这种方式为单机模式,容器以及任务全部存在内存中,是不合适的。我这块想了一下,应该改动这一块就可以了。
第一:修改spring的配置文件,因为容器也就是Scheduler的对象不应该在对象里面创建,应该交给spring进行管理。
修改第一步:
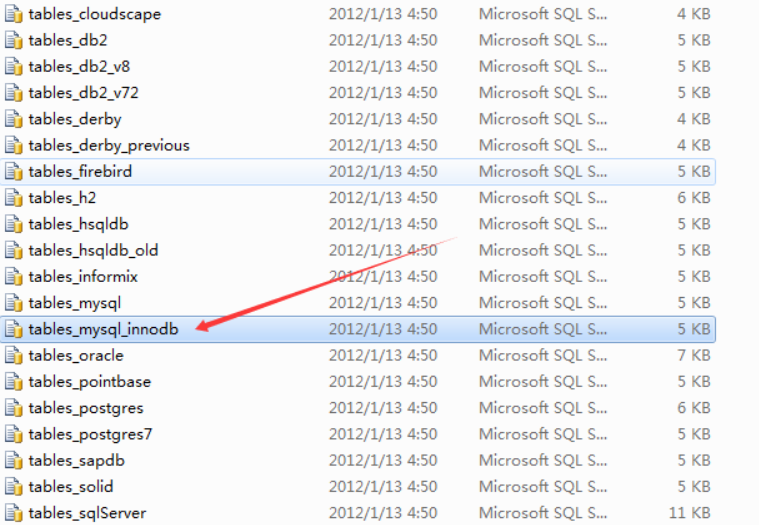
创建定时器表机构,这个在网上可以搜到,就是这个样子的,打开,然后执行,如果执行出错,表里面有一句话TYPE=InnoDB;
改成engine=InnoDB就可以了
第二步,创建quartz.properities文件,文件内容
调度器实例的名字,使用默认的DefaultQuartzScheduler就好
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
调度器实例的ID, 选择AUTO
org.quartz.scheduler.instanceId:AUTO
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
跳过更新检查
org.quartz.scheduler.skipUpdateCheck:true
配置线程池
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount: 10
org.quartz.threadPool.threadPriority: 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
quartz默认的是将job信息存储在内存中,quartz集群必须将job信息持久化到数据库中
org.quartz.jobStore.dataSource = dataSource
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.misfireThreshold:60000
############
以指示JDBCJobStore将JobDataMaps中的所有值都作为字符串,因此可以作为名称 - 值对存储而不是在BLOB列中以其序列化形式存储更多复杂的对象。从长远来看,这是更安全的,因为您避免了将非String类序列化为BLOB的类版本问题
org.quartz.jobStore.useProperties:false
#quartz数据表的前缀,quartz的数据表在 quartz-2.2.3\docs\dbTables 文件夹中,
#选择对应的数据库版本,将数据库创建出来
org.quartz.jobStore.tablePrefix:QRTZ_
最关键的 是否支持集群 选择true
org.quartz.jobStore.isClustered:true
org.quartz.jobStore.clusterCheckinInterval:15000
第三步:修改spring的配置文件,把容器交给spring管理
加入一个bean为
第四步:修改QuartzManager的addJob方法
public class QuartzManager {undefined
private static Logger logger=Logger.getLogger(QuartzManager.class);
private static SchedulerFactory gSchedulerFactory = new StdSchedulerFactory();
private static String JOB_GROUP_NAME = “EXTJWEB_JOBGROUP_NAME”;
private static String TRIGGER_GROUP_NAME = “EXTJWEB_TRIGGERGROUP_NAME”;
private static Scheduler scheduler;
public static Scheduler getScheduler() { return scheduler; } public static void setScheduler(Scheduler scheduler) { QuartzManager.scheduler = scheduler; } public static void addScheduler(Scheduler schedulerOther){ scheduler=schedulerOther; } public static void addJob(String jobName, Class cls, String time,QuartzTask task) { try { JobDetail jobDetail = new JobDetail(jobName, JOB_GROUP_NAME, cls);// 任务名,任务组,任务执行类 jobDetail.getJobDataMap().put("task", task); CronTrigger trigger = new CronTrigger(jobName, TRIGGER_GROUP_NAME);// 触发器名,触发器组 trigger.setCronExpression(time);// 触发器时间设定 scheduler.scheduleJob(jobDetail, trigger); // 启动 if (!scheduler.isShutdown()) { scheduler.start(); } } catch(org.quartz.ObjectAlreadyExistsException e){ logger.info("已经存在定时任务e"+e); } catch (Exception e) { throw new RuntimeException(e); } }
这个时候scheduler是无法注入的,也就是空,我们的项目采用项目启动时加载定时任务,那么需要在项目启动的时候加载一下
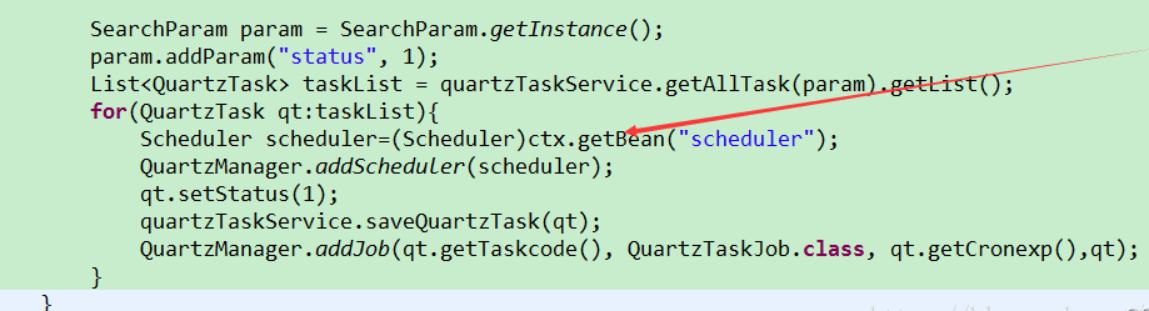
这样,注入的参数就进去了。
这样,项目的分布式搭建成功。。。修改原来的项目只需要这四步
把碰到的错误分享一下。
第一:出现这个错误OPTION SQL_SELECT_LIMIT=5,这个错误是mysql连接驱动版本过低导致的,我原来的版本是mysql-connector-java-5.1.18,升级到5.1.31,这个问题就解决了。升级的时候原来的版本要删除掉,一定要删除掉,保证项目只有一个connector才可以,我就是升级了也不好使,最后只保留一个才可以的。
第二:出现这个错误
Couldn’t store job: JobDataMap values must be Strings when the ‘useProperties’ property is set. Key of offending value:
修改一下org.quartz.jobStore.useProperties:false就可以了。具体的原因,我看了一下,如果设置为true,需要把存错的键值对当做字符串来进行保存,报错信息也是键值对无法按照string进行报错,所以需要改成false。这样就不报错了
第三:database is null
在做分布式quartz里面,数据库需要命名,我的程序是用jdbc连接,采用bonecp作为连接池,也就是说在我没修改定时任务的分布式的时候,配置文件里面就是dataSource这个数据库连接池了。所以需要在quartz的配置文件里面加上org.quartz.jobStore.dataSource = dataSource,记住,这个数据库的名字要统一,不要写乱了。否则总会报数据库连接的错误。
分布式搭建完毕,业务处理还没完事,剩下的都是业务问题,可以自行处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号