获取全部校园新闻
1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
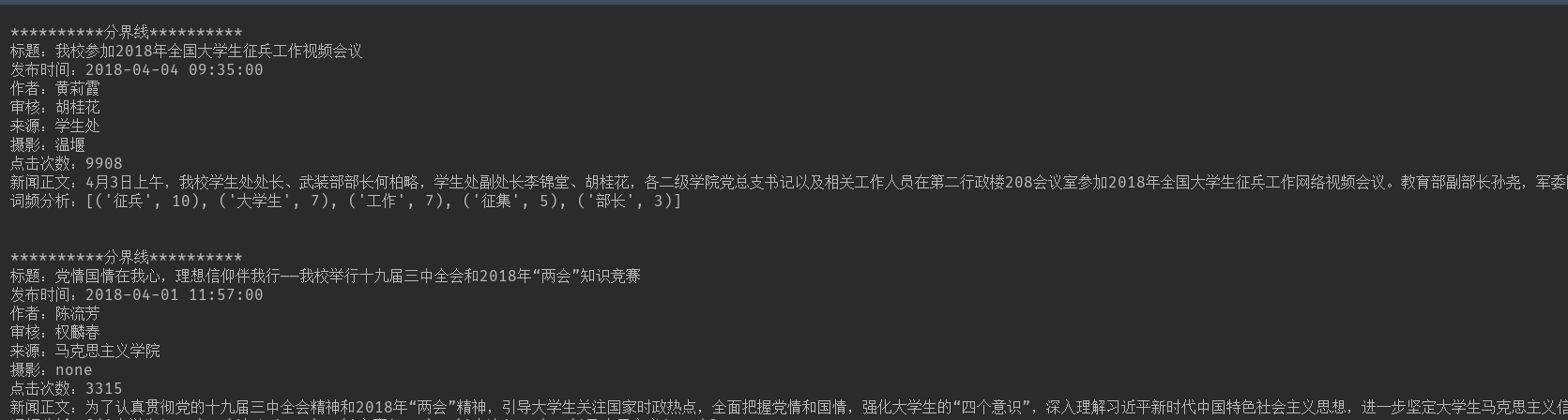
import requests from bs4 import BeautifulSoup from datetime import datetime import re import jieba def countWord(content): wordList = list(jieba.cut(content)) wordDict = {} for word in wordList: if (len(word) == 1): continue wordDict[word] = wordList.count(word) wordListSort = sorted(wordDict.items(), key=lambda d: d[1], reverse=True) return wordListSort def getClickCount(newsUrl): #获取点击次数 newId = re.search('_(.*)/(.*).html', newsUrl).group(2) clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newId) clickStr = requests.get(clickUrl).text return(re.search("hits'\).html\('(.*)'\);",clickStr).group(1)) def getNewsDetail(newsUrl): newsDist={} resp = requests.get(newsUrl) resp.encoding = 'utf-8' soup = BeautifulSoup(resp.text, 'html.parser') title=soup.select('.show-title')[0].text showInfo = soup.select('.show-info')[0].text time = showInfo.lstrip('发布时间:')[0:19] dTime = datetime.strptime(time, '%Y-%m-%d %H:%M:%S') author='none' if showInfo.find('作者:')> 0: author=showInfo[showInfo.find('作者:'):].split()[0].lstrip('作者:') audit='none' if showInfo.find('审核:')>0: audit = showInfo[showInfo.find('审核:'):].split()[0].lstrip('审核:') origin='none' if showInfo.find('来源:') > 0: origin = showInfo[showInfo.find('来源:'):].split()[0].lstrip('来源:') photography='none' if showInfo.find('摄影:') > 0: photography = showInfo[showInfo.find('摄影:'):].split()[0].lstrip('摄影:') print('\n\n'+'*'*10+'分界线'+'*'*10) print('标题:'+title) print('发布时间:{}'.format(dTime)) print('作者:'+author) print('审核:' + audit) print('来源:'+origin) print('摄影:'+photography) print('点击次数:'+getClickCount(newsUrl)) print('新闻正文:' + soup.select('#content')[0].text.strip().replace('\u3000','').replace('\n','').replace('\r','')) print('词频分析:'+ str(countWord(soup.select('#content')[0].text.strip().replace('\u3000','').replace('\n','').replace('\r',''))[0:5])) newsDist['title']=title newsDist['audit']=audit newsDist['origin']=origin newsDist['photography']=photography newsDist['clickTime']=getClickCount(newsUrl) newsDist['content']=soup.select('#content')[0].text.strip().replace('\u3000','').replace('\n','').replace('\r','') return newsDist def getFirstPage(soup): fistDistList=[] newsPage = soup.select('.news-list > li') for news in newsPage: newsUrl = news.select('a')[0].attrs['href'] fistDistList.append(getNewsDetail(newsUrl)) return fistDistList def getPage(pageUrl): DisrList=[] pageResp = requests.get(pageUrl) pageResp.encoding = 'utf-8' pageSoup = BeautifulSoup(pageResp.text, 'html.parser') newsPage = pageSoup.select('.news-list > li') for news in newsPage: newsUrl=news.select('a')[0].attrs['href'] DisrList.append(getNewsDetail(newsUrl)) # print(DisrList) return DisrList firstPageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/' firstPageResp=requests.get(firstPageUrl) firstPageResp.encoding='utf-8' firstPageSoup=BeautifulSoup(firstPageResp.text,'html.parser') totleDistList=[] totleDistList.extend(getFirstPage(firstPageSoup)) pageMaxNum=int(firstPageSoup.select('#pages > a')[len(firstPageSoup.select('#pages > a'))-2].text) for i in range(2,10): pageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) totleDistList.extend(getPage(pageUrl)) # print(totleDistList)
结果如下: