
Jaeger 简介
Jaeger遵守OpenTracing标准中描述的数据模型。了解这个模型和相关术语将帮助您更好地理解jaeger架构。
模型
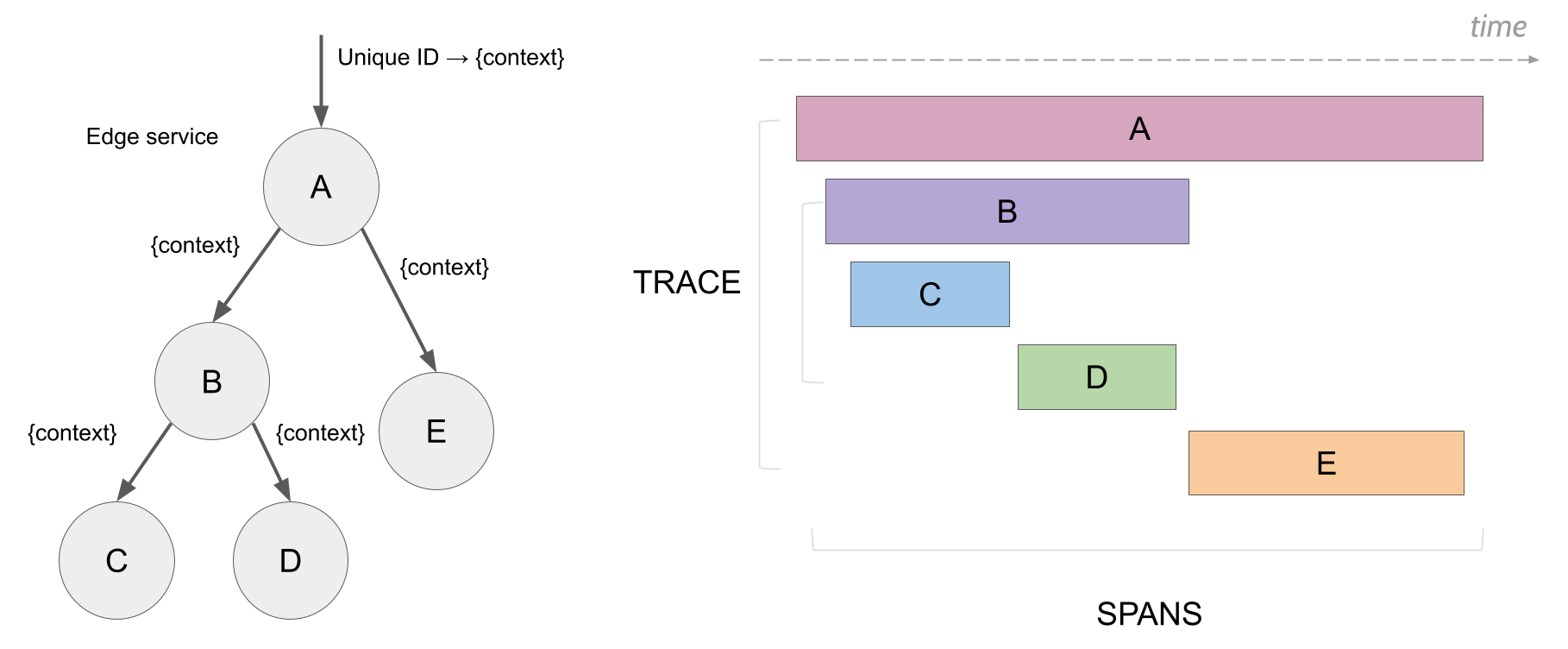
一个tracer过程中,各span的关系
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 后被调用, FollowsFrom)
上述tracer与span的时间轴关系
[––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
|
| [Span A···················································]
tracer| [Span B··············································]
| [Span D··········································]
| [Span C········································]
[ [Span E·······] [Span F··] [Span G··] [Span H··]
术语
Traces
一个trace代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。一个trace可以认为是多个span的有向无环图(DAG)。
Spans
一个span代表系统中具有开始时间和执行时长的逻辑运行单元。span之间通过嵌套或者顺序排列建立逻辑因果关系。
SpanContext
每个span必须提供方法访问SpanContext。SpanContext代表跨越进程边界,传递到下级span的状态 (例如,包含<trace_id, span_id, sampled>元组) 。SpanContext在跨越进程边界,和在追踪图中创建边界的时候会使用。
在sidercar中具体指的是request Header 的key 为uber-trace-id的value。value具体组成为:{trace-id}:{span-id}:{parent-span-id}:{flags}。
flags是用于采集方式的一些参数设置。
Tags
每个span可以有多个键值对(key:value)形式的Tags,Tags是没有时间戳的,支持简单的对span进行注解和补充。sidecar中用于将需要显示的信息注入到tag中,在调用链监控中就可以看到。
Carrier
Carrier是用于携带SpanContext 内容,sidecar中具体指的是 HTTP头。也可以是HTTP Body,由于HTTP Body会和业务强耦合,所以不考虑。
Inject and Extract
SpanContexts可以通过Injected操作向Carrier增加,或者通过Extracted从Carrier中获取,跨进程通讯数据(例如:HTTP头)。通过这种方式,SpanContexts可以跨越进程边界,并提供足够的信息来建立跨进程的span间关系(因此可以实现跨进程连续追踪),这两个动作sidecar已经帮服务做了。
架构
Jaeger可以作为多合一二进制(其中所有Jaeger后端组件都在单个进程中运行)进行部署,也可以作为可扩展的分布式系统进行部署,如下所述。有两个主要的部署选项:
- 收集器正在直接写入存储。
- 收集者正在写信给Kafka作为初步缓冲。
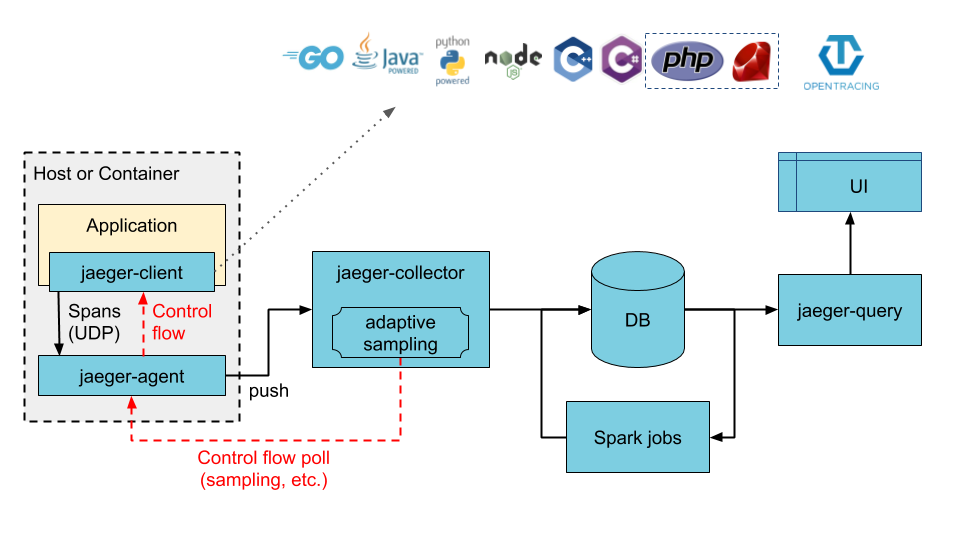
本节详细介绍Jaeger的组成部分以及它们之间的关系。它由应用程序跨域与它们交互的顺序安排。
Jaeger Client库
Jaeger Client 是OpenTracing API的特定于语言的实现。它们可用于手动或与已经与OpenTracing集成的各种现有开源框架(例如Flask,Dropwizard,gRPC等)一起为分布式跟踪应用程序进行检测。
检测服务在接收新请求时创建跨度,并将上下文信息(跟踪ID,跨度ID和baggage)附加到传出请求。只有ID和行李随请求一起传播;所有其他概要分析数据(如操作名称,时间,标签和日志)都不会传播。相反,它在后台异步地传输到Jaeger后端。
仪器设计为始终在生产中使用。为了最大程度地减少开销,Jaeger客户采用了各种采样策略。对跟踪进行采样时,将捕获分析范围数据并将其传输到Jaeger后端。当不对跟踪进行采样时,根本不会收集任何性能分析数据,并且对OpenTracing API的调用会被短路,以产生最小的开销。默认情况下,Jaeger客户端对0.1%的迹线进行采样(每1000条中的1条),并且能够从Jaeger后端检索采样策略。
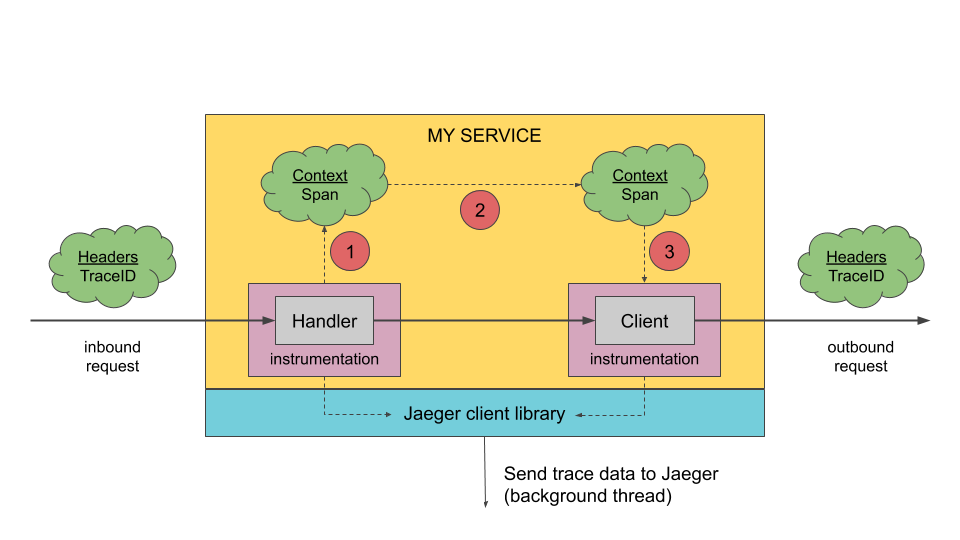
Agent
Jaeger Agent是一个网络守护程序,它侦听通过UDP发送的跨度,然后将其分批发送给收集器。它旨在作为基础结构组件部署到所有主机。该代理将收集器的路由和发现抽象为远离客户端。
Collector
Jaeger Collector从Jaeger Agent接收跟踪,并通过处理管道运行它们。当前,我们的管道会验证跟踪,为其建立索引,执行任何转换并最终存储它们。
Jaeger的存储是一个可插拔组件,存储支持。
Query
Query是一项从存储中检索跟踪并托管UI来显示跟踪的服务。
Ingester
Ingester是一项从Kafka主题读取并写入另一个存储后端(Cassandra,Elasticsearch)的服务。
参考链接
https://www.jaegertracing.io
https://opentracing.io
如果觉得写得不好,欢迎指出;如果觉得写得不错,欢迎大佬们夸赞。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· .NET Core 中如何实现缓存的预热?
· 三行代码完成国际化适配,妙~啊~
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?