
对象序列化内存占用问题
一般而言,前端发起一个查询,后端接收请求而后去数据库检索并得到结果集,之后序列化为字符串返回给前端展示。
在序列化方法接收一个集合到序列化(比如这里是json)的过程中,内存占用会增大吗?肯定会的,总体而言我们new出的对象,对象引用的字符、数字等都是存放在堆内存中;未序列化这些对象之前,他们就是被集合(这里是List)引用,占用内存大小是List集合所有对象的数据大小;
而当序列化的时候,我们把对象全部转为了一个字符串(集合越大这个字符串越大),这个字符串对象是要重新再堆内存中开辟一个空间来存储的。在这个过程中,可能内存的占用是未序列化时的2倍,直到线程请求结束,GC回收集合对象、字符串对象。
下面展示一个小实验来说明:
代码不具体展示,很简答,创建一个集合,new很多对象比如User什么的,往里面丢;序列化使用jackson什么都可以。
JVM参数为:-Xms64M -Xmx64M
| 未加入序列化之前 | 加入序列化代码之后 | |
|
内存 |
|
|
|
详细 |
|
|
|
大 |
|
|
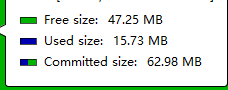
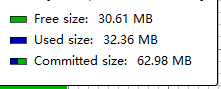


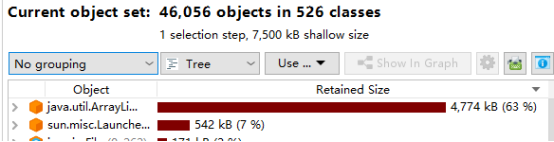
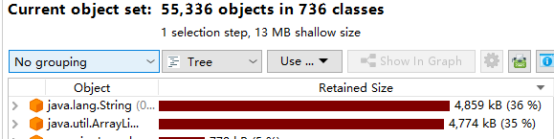
可以看到序列化的时候,内存占用几乎是之前的2倍多,对象都停留在了老年代中,Meataspace也略有增长(毕竟引入了其他相关类,属于正常);大对象的占用由原来List大小为7M左右增长为13M,而且大对象还加入了一个String字符串。
- 总之,传输的对象要保持一个合适的大小,比如采用分页,更细致的查询、分批处理、限制大小等,尽可能避免大对象传递以及序列化和反序列化
- 追求性能的情况下,避免采用json、xml等这种序列化协议,而是采用Kryo、Protobuf、Thrift等
分类:
Java技术 / 疑难杂症


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义