验证 .NET 4.6 的 SIMD 硬件加速支持的重要性
SIMD 的意思是 Single Instruction Multiple Data。顾名思义,一个指令可以处理多个数据。
.NET Framework 4.6 推出的 Nuget 程序包 System.Numerics.Vectors 里面的 Vector`1 类型是有硬件加速功能的。这个硬件加速功能就是指即时编译的时候根据硬件环境选用一些 SIMD 的指令让程序运行更快。
这个硬件加速功能的威力可以用下面的方式得到验证。
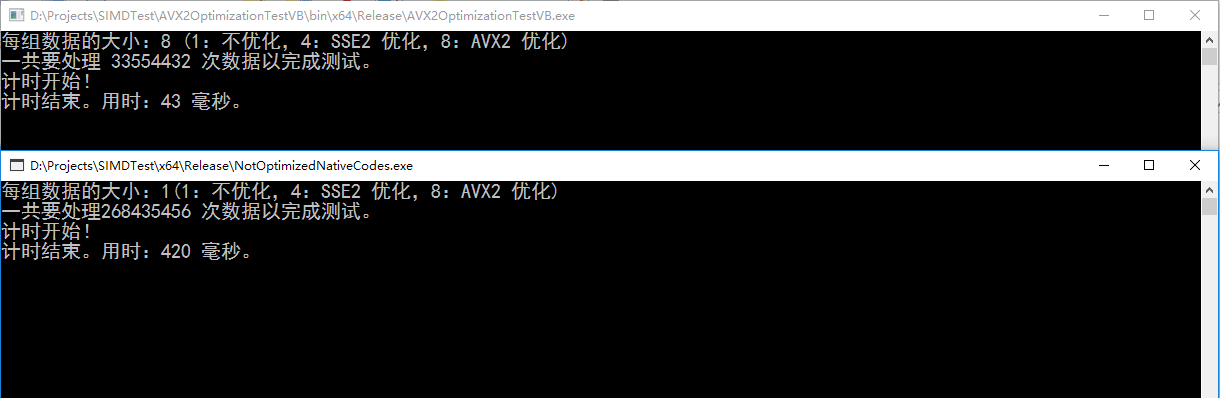
用单线程的程序重复 10000000H 个单精度浮点数的加法。加法的每一个输入都是引用类型,输出也必须获取值的引用。
VB 2017 程序:
动态获取当前硬件支持一组算多少个单精度浮点数的加法,然后分组计算。Release x64 编译,优化代码(反编译验证没有优化掉循环),取消整数溢出检查(为了跟 c# 执行时间一样)。
VB
Imports System.Numerics Module Program Sub Main() Const TotalDataSize = &H1000_0000 Dim watch As New Stopwatch Dim groupSize = Vector(Of Single).Count Dim groupCount = TotalDataSize / groupSize Console.WriteLine($"每组数据的大小:{groupSize} (1:不优化,4:SSE2 优化,8:AVX2 优化) 一共要处理 {groupCount} 次数据以完成测试。") Console.WriteLine("计时开始!") watch.Start() Dim groupA(groupSize - 1), groupB(groupSize - 1) As Single Dim vecA As New Vector(Of Single)(groupA), vecB As New Vector(Of Single)(groupB), vecResult As Vector(Of Single) For i = 1 To groupCount vecResult = vecA + vecB Next watch.Stop() Console.WriteLine($"计时结束。用时:{watch.ElapsedMilliseconds} 毫秒。") Console.ReadKey() End Sub End Module
VC++ 2017程序:
用循环 0x10000000 次的 for 循环,Release x64 编译,禁止优化(开优化不管循环多少次都是 0 毫秒,肯定是把循环优化掉了)。
C++
#include "stdafx.h" #include <iostream> #include "NotOptimizedNativeCodes.h" const int TotalDataSize = 0x10000000; #pragma unmanaged void NativeTest() { float groupA[1] = { 0 }, groupB[1] = { 0 }, *groupResult; for (size_t i = 0; i < TotalDataSize; i++) { float result = groupA[0] + groupB[0]; groupResult = &result; } } #pragma managed using namespace System; using namespace System::Diagnostics; int NotOptimizedNativeCodes::Program::main(array<System::String ^> ^args) { auto watch = gcnew Stopwatch(); std::cout << "每组数据的大小:" << 1 << "(1:不优化,4:SSE2 优化,8:AVX2 优化)" << std::endl << "一共要处理" << TotalDataSize << " 次数据以完成测试。" << std::endl; Console::WriteLine(L"计时开始!"); watch->Start(); NativeTest(); watch->Stop(); std::cout << "计时结束。用时:" << watch->ElapsedMilliseconds << " 毫秒。" << std::endl; Console::ReadKey(); return 0; } int main(array<System::String ^> ^args) { NotOptimizedNativeCodes::Program::main(args); }
执行结果(CPU 是 i5 6400,有 AVX2 指令集)
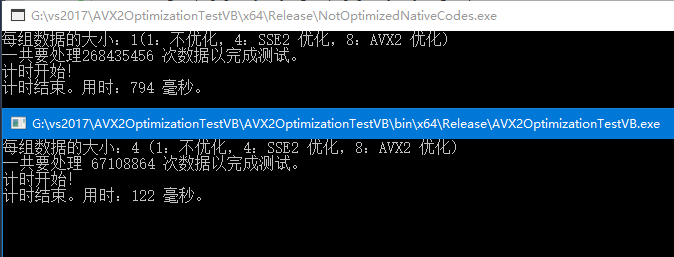
使用 i7 3632QM (没有 AVX2 但是有 SSE2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号