常用对象API(集合框架)★★★★★
目录
集合框架Collection
概述



数组也可以存对象,但是数组长度是固定的,使用集合长度是可变的,不确定长度用集合好一些
注意:集合里面是保存的对象
集合类的由来:
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定。
就使用集合容器进行存储。
集合的特点:
-
对象封装数据,对象多了也需要存储。集合用于存储对象的容器。
-
对象的个数确定可以使用数组,但是不确定怎么办?可以用集合。因为集合是可变长度的。
-
集合中不可以存储基本数据类型值。
集合和数组的区别:
集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;
集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;
集合存储的对象可以是不同数据类型。
体系&共性功能
数据结构:就是容器中存储数据的方式。
集合容器因为内部的数据结构不同,有多种具体容器。
集合容器在不断的向上抽取,就形成了集合框架。
在使用一个体系时,原则:参阅顶层内容。建立底层对象。
框架的顶层就是Collection接口:

Collection接口的常见方法:
- 添加。
boolean add(Object obj)://添加元素。
boolean addAll(Collection coll)://添加某集合所有元素
//创建一个集合容器。使用Collection接口的子类。ArrayList
ArrayList c1 = new ArrayList();
//1,添加元素。
c1.add("abc1");//add(Object obj);
c1.add("abc2");
c1.add("abc3");
c1.add("abc4");
打印:["abc1","abc2"....]
ArrayList c2 = new ArrayList();
c2.add("abc5");//add(Object obj);
c2.add("abc6");
c2.add("abc7");
c1.addAll(c2); //将c2中的元素添加到c1中

- 删除。
boolean remove(object obj):
boolean removeAll(Collection coll);
//将两个集合中的相同元素从调用removeAll的集合中删除。
void clear();//清空集合。
//演示removeAll
boolean b =c1.removeAll(c2);
//将两个集合中的相同元素从调用removeAll的集合中删除。
System.out.println("removeAll:"+b);

- 判断:
boolean contains(object obj):
//如果此集合包合此元素,返回true。
boolean containsAll(Colllection coll);
//如果此集合包含集合所有元素,返回true。
boolean isEmpty();//判断集合中是否有元素。
//演示containsAll
boolean b =c1.containsAll(c2);
//如果此集合包含集合所有元素,返回true。
System.out.println("containsAll:"+b);
//输出:containsAll:false

- 获取:
int size();//返回此集合中的元素数。
// 如果此集合包含Integer.MAX_VALUE元素,则返回Integer.MAX_VALUE 。
- 取交集:
boolean retainAll(Collection coll);//取交集。
//演示retainAll
boolean b = c1.retainAll(c2);
//取交集,保留和指定的集合相同的元素,而删除不同的元素。
//和removeAll功能相反。
System.out.println("retainAll:"+b);

- 获取集合中所有元素:
Iterator iterator();//取出元素的方式:迭代器。
/*该对象必须依赖于具体容器,因为每一个容器的数据结构都不同。
所以该迭代器对象是在容器中进行内部实现的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,
也就是iterator方法。
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
其实就是抓娃娃游戏机中的夹子!
*/
7.将集合变成数组
Object[] toArray()://将集合转成数组。
迭代器的使用Iterator
Interface Iterator
Iterator是一个接口。作用:用于取集合中的元素。
| boolean | [hasNext] 如果仍有元素可以迭代,则返回 true。 |
|---|---|
| E | [next] 返回迭代的下一个元素。 |
| void | [remove]从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。 |
Collection coll = new ArrayList();
coll.add("abc1");
coll.add("abc2");
coll.add("abc3");
coll.add("abc4");
// System.out.println(coll);
//使用了Collection中的iterator()方法。 调用集合中的迭代器方法,是为了获取集合中的迭代器对象。
// Iterator it =coll.iterator();
// while(it.hasNext()){
// System.out.println(it.next());
// }
for(Iterator it = coll.iterator(); it.hasNext(); ){
System.out.println(it.next());
}
//实际开发中用这种,for循环释放内存
//但是如果你想循环结束以后迭代器还能用就使用while,for与while的区别不就是在这儿吗。
迭代器原理:
- 取元素,无论是什么数据结构,最终共性的取出方式:
一个一个取,取之前判断。有,取一个。没有,结束 - 这种共性的方式称为:迭代。


List和Set的特点
List(列表)和set(集)
Collection
|--List:有序(存入和取出的顺序一致),该集合体系元素都有索引(角标),元素可以重复。
|--Set:元素不能重复,无序(LinkedHashSet集合有序)。
所以有序不有序不重要,重要的是唯不唯一,需要唯一走Set,不需要走List
使用集合的一些技巧
需要唯一吗?
- 需要:用Set
- 需要制定顺序:
- 需要TreeSet
- 不需要HashSet
- 但是想要一个和存储一致的顺序(有序):LinkeHashSet
- 需要制定顺序:
- 不需要List
- 需要频繁增删吗?
- 需要:LinkeList
- 不需要:ArrayList
- 需要频繁增删吗?
如何记录每个容器的结构和所属体系呢?
List
- ArrayList
- LinkedList
Set
- HashSet
- TreeSet
后缀名就是该集合所属的体系
前缀名就是该集合的数据结构
- 看到array:就要像到数组,就要想到查询快,有角标。
- 看到Link:就要想到链表,就要想到增删快,就要想到add,get,remove+frist、last方法。
- 看到hash:就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashCode方法和equals方法。
- 看到tree:就要想到二叉树,就要想到排序,就要想到两个接口Comparable,Comparator。
List接口
List接口的常见方法
List特有的常见方法:有一个共性方法就是操作角标
List本身是Collection接口的子接口,具备了Collection的所有方法。现在学习List体系特有的共性方法,查阅方法发现List的特有方法都有索引,这是该集合最大的特点。
List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引。元素可以重复。
List常用子类的特点:
- Vector:底层的数据结构就是数组,线程同步的,被ArrayList替代了,Vector无论查询和增删都巨慢。
- ArrayList:底层的数据结构是数组,线程不同步,ArrayList替代了Vector,查询元素的速度非常快,但是增删稍慢。
- LinkedList:底层的数据结构是链表,线程不同步,增删元素的速度非常快,查询稍慢
可变长度数组的原理:
当元素超出数组长度,会产生一个新数组,将原数组的数据复制到新数组中,再将新的元素添加到新数组中。
ArrayList:是按照原数组的50%延长。构造一个初始容量为 10 的空列表。
Vector:是按照原数组的100%延长。
注意:对于list集合,底层判断元素是否相同,其实用的是元素自身的equals方法完成的。所以建议元素都要复写equals方法,建立元素对象自己的比较相同的条件依据。
说说ArrayList为什么查询快,为什么LinkList为什么查询慢的原因吗?(ps按ctrl键跳转
List集合支持对元素的增、删、改、查。
- 添加
void |
add(int index, E element) |
在此列表中的指定位置插入指定的元素。 |
|---|---|---|
boolean |
add(E e) |
将指定的元素追加到此列表的末尾。 |
add(index,element) :在指定的索引位插入元素。
addAll(index,collection) :在指定的索引位插入一堆元素。
- 删除
remove(index) :删除指定索引位的元素。 返回被删的元素。
- 获取
Object get(index) :通过索引获取指定元素。
int indexOf(obj) :获取指定元素第一次出现的索引位,如果该元素不存在返回—1;
所以,通过—1,可以判断一个元素是否存在。
int lastIndexOf(Object o) :反向索引指定元素的位置。
List subList(start,end) :获取子列表。包含头不包含尾。
- 修改
Object set(index,element) :对指定索引位进行元素的修改。返回被修改的元素
- 获取所有元素
ListIterator listIterator():list集合特有的迭代器。
List集合因为角标有了自己的获取元素的方式: 遍历。
for(int x=0; x<list.size(); x++){
sop("get:"+list.get(x));
}
在进行list列表元素迭代的时候,如果想要在迭代过程中,想要对元素进行操作的时候,比如满足条件添加新元素。会发生.ConcurrentModificationException并发修改异常。
导致的原因是:
集合引用和迭代器引用在同时操作元素,通过集合获取到对应的迭代器后,在迭代中,进行集合引用的元素添加,迭代器并不知道,所以会出现异常情况。
如何解决呢?
既然是在迭代中对元素进行操作,找迭代器的方法最为合适.可是Iterator中只有hasNext,next,remove方法.通过查阅的它的子接口,ListIterator,发现该列表迭代器接口具备了对元素的增、删、改、查的动作。
代码实现:
import java.util.*;
class ListDemo
{
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void method()
{
ArrayList al = new ArrayList();
//添加元素
al.add("java01");
al.add("java02");
al.add("java03");
sop("原集合是:"+al);
//在指定位置添加元素。
al.add(1,"java09");
//删除指定位置的元素。
//al.remove(2);
//修改元素。
//al.set(2,"java007");
//通过角标获取元素。
sop("get(1):"+al.get(1));
sop(al);
//获取所有元素。
for(int x=0; x<al.size(); x++)
{
System.out.println("al("+x+")="+al.get(x));
}
Iterator it = al.iterator();
while(it.hasNext())
{
sop("next:"+it.next());
}
//通过indexOf获取对象的位置。
sop("index="+al.indexOf("java02"));
List sub = al.subList(1,3);
sop("sub="+sub);
}
ListIterator接口
ListIterator是List集合特有的迭代器。ListIterator是Iterator的子接口。
ListIterator it = list.listIterator;//取代Iterator it = list.iterator;
在迭代时,不可以通过集合对象的方法操作集合中的元素。
因为会发生ConcurrentModificationException异常。
所以,在迭代器时,只能用迭代器的放过操作元素,可是Iterator方法是有限的,
只能对元素进行判断,取出,删除的操作,
如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。
该接口只能通过List集合的listIterator方法获取。
-
- | Modifier and Type | 方法 | 描述 |
| ----------------- | ----------------- | ------------------------------------------------------------ |
|void|add(E e)| 将指定的元素插入列表(可选操作)。 |
|boolean|hasNext()| 如果此列表迭代器在向前方向遍历列表时具有更多元素,则返回true。 |
|boolean|hasPrevious()| 如果此列表迭代器在相反方向遍历列表时具有更多元素,则返回true。 |
|E|next()| 返回列表中的下一个元素,并且前进光标位置。 |
|int|nextIndex()| 返回由后续调用返回的元素的索引next()。 |
|E|previous()| 返回列表中的上一个元素,并向后移动光标位置。 |
|int|previousIndex()| 返回由后续调用返回的元素的索引previous()。 |
|void|remove()| 从列表中删除next()或previous()(可选操作)返回的最后一个元素。 |
|void|set(E e)| 用指定的元素(可选操作)替换next()或previous()返回的最后一个元素。 |
- | Modifier and Type | 方法 | 描述 |
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void main(String[] args)
{
//演示列表迭代器。
ArrayList al = new ArrayList();
//添加元素
al.add("java01");
al.add("java02");
al.add("java03");
sop(al);
ListIterator li = al.listIterator();
//sop("hasPrevious():"+li.hasPrevious());
//正向遍历
while(li.hasNext())
{
Object obj = li.next();
if(obj.equals("java02"))
//li.add("java009");
li.set("java006");
}
//逆向遍历
while(li.hasPrevious())
{
sop("pre::"+li.previous());
}
//sop("hasNext():"+li.hasNext());
//sop("hasPrevious():"+li.hasPrevious());
sop(al);
/*
//在迭代过程中,准备添加或者删除元素。
Iterator it = al.iterator();
while(it.hasNext())
{
Object obj = it.next();
if(obj.equals("java02"))
//al.add("java008");
//java.util.ConcurrentModificationException 故障快速迭代器异常
一个线程通常不允许修改集合,而另一个线程正在遍历它。
it.remove();//将java02的引用从集合中删除了。
sop("obj="+obj);
}
sop(al);
*/
}
ConcurrentModificationException:

数组和链表

为什么快:因为空间是连续的所以快
为什么慢:空间不连续吗,挨个去判断吗
LinkedList有角标吗?
先不说原因,它是不是list接口的子类,是啊,list最大的特点是不是有角标啊,所以也它有啊
Vector集合(了解)
只是讲解了Vector迭代的特有方法而已,但是我们现在一般都不用了,只是作为了解而已
该接口的功能由Iterator接口复制。 此外, Iterator添加了可选的删除操作,并且具有较短的方法名称。 新的实现应该考虑使用Iterator ,而不是Enumeration 。 因此能够适应一个Enumeration到Iterator通过使用asIterator()方法。
/*
枚举就是Vector特有的取出方式。
发现枚举和迭代器很像。
其实枚举和迭代是一样的。
因为枚举的名称以及方法的名称都过长。
所以被迭代器取代了。
枚举郁郁而终了。
*/
class VectorDemo
{
public static void main(String[] args)
{
Vector v = new Vector();
v.add("java01");
v.add("java02");
v.add("java03");
v.add("java04");
Enumeration en = v.elements();
while(en.hasMoreElements())
{
System.out.println(en.nextElement());
}
//用迭代器代替
Iterator it =v.iterator();
while(it.hasNext()){
System.out.println("next:"+it.next());
}
}
}
}
LinkedList集合
void addFirst(); //在该列表开头插入指定的元素。
void addLast(); //将指定的元素追加到此列表的末尾。
//JDK1.6后
boolean offerFirst();//在此列表的前面插入指定的元素。
boolean offerLast(); //在该列表的末尾插入指定的元素。
返回null的作用是可以加判断
e getFirst();//获取链表中的第一个元素。如果链表为空,抛出NoSuchElementException;
e getLast();
//在jdk1.6以后。返回null的作用是可以加判断
E peekFirst();//获取链表中的第一个元素。如果链表为空,返回null。
E peekLast();
E removeFirst()://获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表为空,抛出NoSuchElementException
E removeLast();
//在jdk1.6以后。
E pollFirst();//获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表为空,返回null。
E pollLast();
LinkedList link =new LinkedList();
link.addFirst("abc1");
link.addFirst("abc2");
link.addFirst("abc3");
link.addFirst("abc4");
// System.out.println(link);
// System.out.println(link.getFirst());//获取第一个但不删除。
// System.out.println(link.getFirst());
// System.out.println(link.removeFirst());//获取元素但是会删除。
// System.out.println(link.removeFirst());
while(!link.isEmpty()){
System.out.println(link.removeLast());
}
System.out.println(link);
// Iterator it =link.iterator();
// while(it.hasNext()){
// System.out.println(it.next());
// }
}
练习#(堆栈和队列)
★★★面试考点:
面讲一个在面试中经常会被出的面试题
/*
* 请使用LinkedList来模拟一个堆栈或者队列数据结构。
* 堆栈:先进后出 First In Last Out FILO
* 队列:先进先出 First In First Out FIFO
* 我们应该描述这样一个容器,给使用提供一个容器对象完成这两种结构中的一种。
*/
并不是需要你把这样一个效果演示完,而是需要你做一个这样的容器出来,
是我要给你提供一个对象,这个对象就能实现,你怎么存进去,你调用我的方法时候就能怎么取出来,你得去把这种结构封装起来
这里面的代码就不贴出来了,先自己去做一下,
LinkedList:
addFirst();
addLast():
jdk1.6
offerFirst();//在此列表的开头插入指定的元素
offetLast();
getFirst();.//获取但不移除,如果链表为空,抛出NoSuchElementException.
getLast();
jdk1.6
peekFirst();//获取但不移除,如果链表为空,返回null.
peekLast():
removeFirst();//获取并移除,如果链表为空,抛出NoSuchElementException.
removeLast();
jdk1.6
pollFirst();//获取并移除,如果链表为空,返回null.
pollLast();
ArrayList集合存储自定对象
定义一个ArrayList,然后往这里面存入Person,然后再把这里面的数据遍历出来
import java.util.*;
/*
将自定义对象作为元素存到ArrayList集合中,并去除重复元素。
比如:存人对象。同姓名同年龄,视为同一个人。为重复元素。
思路:
1,对人描述,将数据封装进人对象。
2,定义容器,将人存入。
3,取出。
List集合判断元素是否相同,依据是元素的equals方法。
*/
class Person
{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
public boolean equals(Object obj)
{
if(!(obj instanceof Person))
return false;
Person p = (Person)obj;
//System.out.println(this.name+"....."+p.name);
return this.name.equals(p.name) && this.age == p.age;
}
/**/
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}
class ArrayListTest2
{
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void main(String[] args)
{
ArrayList al = new ArrayList();
al.add(new Demo());
al.add(new Person("lisi01",30));//al.add(Object obj);//Object obj = new Person("lisi01",30);
//al.add(new Person("lisi02",32));
al.add(new Person("lisi02",32));
al.add(new Person("lisi04",35));
al.add(new Person("lisi03",33));
//al.add(new Person("lisi04",35));
//al = singleElement(al);
sop("remove 03 :"+al.remove(new Person("lisi03",33)));//remove方法底层也是依赖于元素的equals方法。
Iterator it = al.iterator();
while(it.hasNext())
{
Person p = (Person)it.next();
sop(p.getName()+"::"+p.getAge());
}
}
public static ArrayList singleElement(ArrayList al)
{
//定义一个临时容器。
ArrayList newAl = new ArrayList();
Iterator it = al.iterator();
while(it.hasNext())
{
Object obj = it.next();
if(!newAl.contains(obj))
newAl.add(obj);
}
return newAl;
}
}
**堆内存图: **PS:集合中装的全是对象的引用,不可能直接把对象装进去。

Set接口
Set接口特点
Set:元素不可以重复,是无序。
Set接口中的方法和Collection中方法一致的。Set接口取出方式只有一种,迭代器。
-
HashSet:底层数据结构是哈希表,线程是不同步的。无序,高效;
-
HashSet是如何保证元素唯一性的呢?
- 是通过元素的两个方法,hashCode和equals来完成。
- 如果元素的hashcode值不同,不会调用equals,就直接存储到哈希表中。
- 如果元素的HashCode值相同,才会判断equals是否为true。
- 如果为true,视为相同元素,不存。如果为false,那么视为不同元素,就进行存储。
-
注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。
-
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖equals,hashCode方法。
建立对象判断是否相同的依据。
-
-
LinkedHashSet:有序,hashSet的子类,此线程不同步。
-
TreeSet:对Set集合中的元素的进行指定顺序的排序。不同步。TreeSet底层的数据结构就是二叉树。
-
判断元素唯一性的方式,就是根据比较方法的返回结果是否为0;是0,就是相同元素。
-
TreeSet对元素进行排序的方式一:
让元素自身具备比较功能,元素就需要实现Comperable接口。覆盖compareTo方法。
-
HashSet集合
-
- | Modifier and Type | 方法 | 描述 |
| ----------------- | -------------------- | ------------------------------------------------------------ |
|boolean|add(E e)| 将指定的元素添加到此集合(如果尚未存在)。 |
|void|clear()| 从此集合中删除所有元素。 |
|Object|clone()| 返回此HashSet实例的浅拷贝:元素本身不被克隆。 |
|boolean|contains(Object o)| 如果此集合包含指定的元素,则返回true。 |
|boolean|isEmpty()| 如果此集合不包含元素,则返回true。 |
|Iterator<E>|iterator()| 返回此集合中元素的迭代器。 |
|boolean|remove(Object o)| 如果存在,则从该集合中删除指定的元素。 |
|int|size()| 返回此集合中的元素数(其基数)。 |
|Spliterator<E>|spliterator()| 在此集合中的元素上创建late-binding和故障快速Spliterator。 |
- | Modifier and Type | 方法 | 描述 |

package com.practice;
import java.util.HashSet;
import java.util.Iterator;
public class Demo {
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void main(String[] args)
{
HashSet hs = new HashSet();
sop(hs.add("java01"));
sop(hs.add("java01"));
hs.add("abc1");
hs.add("abc2");
hs.add("abc3");
hs.add("abc4");
Iterator it = hs.iterator();
while(it.hasNext())
{
sop(it.next());
}
}
}
哈希表
在使用HashSet在存储元素的时候也,有一个hash算法

hashCode判断元素相同的方式
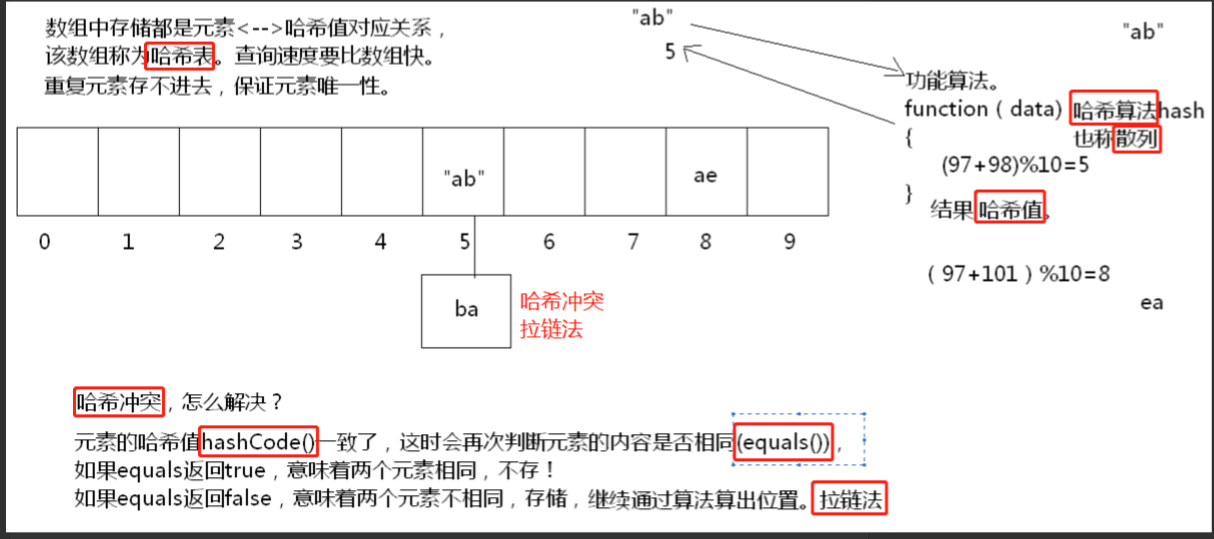
哈希表的原理:
1,对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值 称为哈希值。
2,哈希值就是这个元素的位置。
3,如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。
4,存储哈希值的结构,我们称为哈希表。
5,既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。
这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。
哈希表确定元素是否相同
是通过元素的两个方法,hashCode和equals来完成。
-
判断的是两个元素的哈希值是否相同
- 如果元素的HashCode值相同,才会判断equals是否为true。
-
判断哈希值相同,其实判断的是对象的hashCode的方法。
-
判断内容相同,用的是equals方法。
- 如果为true,视为相同元素,不存。
- 如果为false,那么视为不同元素,就进行存储。
-
注意:如果哈希值不同,是不需要判断equals。
-
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都覆盖equals,hashCode方法。
建立对象判断是否相同的依据:
对于ArrayList集合,判断元素是否存在,或者删元素底层依据都是equals方法。
对于HashSet集合,判断元素是否存在,或者删除元素,底层依据的是hashCode方法和equals方法。
HashSet存储自定义对象
package com.practice;
import java.util.HashSet;
import java.util.Iterator;
public class Demo {
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void main(String[] args)
{
HashSet hs = new HashSet();
/*
* HashSet集合数据结构是哈希表,所以存储元素的时候
* 使用的元素的hashCode方法来确定位置,如果位置相同,在通过元素的equals来确定是否相同。
*
* */
hs.add(new Person("shishuo01",18));
hs.add(new Person("shishuo02",19));
hs.add(new Person("shishuo03",19));
hs.add(new Person("shishuo03",19));
hs.add(new Person("shishuo04",20));
// sop("a1:"+hs.contains(new Person("shishuo04",20)));//如果此集合包含指定的元素,则返回 true
// hs.remove(new Person("shishuo04",20));//移除
Iterator it = hs.iterator();
while(it.hasNext())
{
Person p = (Person)it.next(); //add()方法的参数是Object,所以这里要做类型提升
sop(p.getName()+"::"+p.getAge());
}
}
}
class Person
{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
@Override
public int hashCode()
{
// System.out.println(this.name+"....hashCode");
return name.hashCode()+age*37;
//age乘一个数字,减少哈希冲突,然后去调用equals,
//尽量保持哈希值唯一,提升效率
}
@Override
public boolean equals(Object obj)
{
//健壮性判断
if(this == obj){
return true;
}
if(!(obj instanceof Person))//instanceof可以用来判断继承中的子类的实例是否为父类的实现
throw new ClassCastException("类型错误");
Person p = (Person)obj;
// System.out.println(this.name+"...equals.."+p.name);
return this.name.equals(p.name) && this.age == p.age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}
练习(消除ArrayList中重复元素 )
package com.Set;
import java.util.ArrayList;
import java.util.Iterator;
/*
将自定义对象作为元素存到ArrayList集合中,并去除重复元素。
比如:存人对象。同姓名同年龄,视为同一个人。为重复元素。
思路:
1,对人描述,将数据封装进人对象。
2,定义容器,将人存入。
3,取出。
List集合判断元素是否相同,依据是元素的equals方法。
*/
public class LinkedHashSet {
public static void main(String[] args)
{
ArrayList arrayList = new ArrayList();
arrayList.add(new Person("shishuo01",18));
arrayList.add(new Person("shishuo02",19));
arrayList.add(new Person("shishuo03",19));
arrayList.add(new Person("shishuo03",19));
arrayList.add(new Person("shishuo03",19));
arrayList.add(new Person("shishuo03",19));
arrayList.add(new Person("shishuo04",20));
System.out.println(arrayList);
sop("a1:"+arrayList.contains(new Person("shishuo04",20)));//如果此集合包含指定的元素,则返回 true
arrayList.remove(new Person("shishuo04",20));//移除
arrayList = getSingleElement(arrayList);
System.out.println(arrayList);
}
public static ArrayList getSingleElement(ArrayList arrayList) {
//1.定义一个临时容器
ArrayList temp = new ArrayList();
//2.迭代元素
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
//3.判断被迭代的元素是否存在于临时容器中
if (!temp.contains(obj))//因为contains方法也是用equals的基础来判断的,所以要重写equals方法
temp.add(obj);
}
return temp;
}
private static void sop(String s) {
System.out.println(s);
}
}
class Person
{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
// @Override
// public int hashCode()
// {
//// System.out.println(this.name+"....hashCode");
// return name.hashCode()+age*37;
// //age乘一个数字,减少哈希冲突,然后去调用equals,
// //尽量保持哈希值唯一,提升效率
// }
//对于ArrayList集合,判断元素是否存在,或者删元素底层依据都是equals方法。
@Override
public boolean equals(Object obj)
{
//健壮性判断
if(this == obj){
return true;
}
if(!(obj instanceof Person))//instanceof可以用来判断继承中的子类的实例是否为父类的实现
throw new ClassCastException("类型错误");
Person p = (Person)obj;
// System.out.println(this.name+"...equals.."+p.name);
return this.name.equals(p.name) && this.age == p.age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString(){
return name+":"+age;
}
}
LinkedHashSet集合

所以有序不有序不重要,重要的是唯不唯一,需要唯一走Set,不需要走List
HashSet hs = new LinkedHashSet();
//多态指向子类的add
hs.add("java02");
hs.add("java03");
hs.add("java03");
hs.add("java04");
Iterator it = hs.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
TreeSet集合
TreeSet概述特点
TreeSet:可以对Set集合中的元素的指定顺序排序。是不同步的。排序需要依据元素自身具备的比较性。
如果元素不具备比较性,在运行时会发生ClassCastException异常。
所以需要元素实现Comparable接口,强制让元素具备比较性,复写compareTo方法。
依据compareTo方法的返回值,确定元素在TreeSet数据结构中的位置。
TreeSet方法保证元素唯一性的方式:就是参考比较方法的返回值结果是否为0,如果return 0,视为两个对象重复,不存。
注意:
在进行比较时,如果判断元素不唯一,比如,同姓名,同年龄,才视为同一个人。
在判断时,需要分主要条件和次要条件,当主要条件相同时,再判断次要条件,按照次要条件排序。
TreeSet集合排序两种方式
Comparable和Comparator区别:
1. 让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
- 如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然顺序。也就是说对象是别人的,你无法进去覆盖compareTo,只能当个舔狗,适应人家的对象,怎么办?
2. 让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
第二种方式较为灵活,Comparator优先。
package com.Set;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
/*
*按Person_01类中年龄排序
*
*/
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(new ComparatorByName());
treeSet.add(new Person_0("shishuo_01",18));
treeSet.add(new Person_0("shishuo_02",18));
treeSet.add(new Person_0("chenyufan",18));
treeSet.add(new Person_0("shiying",20));
treeSet.add(new Person_0("chaiyun",21));
treeSet.add(new Person_0("cwhat",22));
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){
Person_0 p = (Person_0)iterator.next();
System.out.println("姓名:"+p.getName()+" 年龄:"+p.getAge());
}
}
}
class Person_0 implements Comparable
{
private String name;
private int age;
Person_0(String name,int age)
{
this.name = name;
this.age = age;
}
//方法一:按Person_01类中年龄排序,元素对象实现Comparable接口,覆盖compareTo方法
@Override
public int compareTo(Object o) {
Person_0 p = (Person_0) o;
int temp = this.age - p.age;
return temp==0?this.name.compareTo(p.name):temp; //漂亮代码
/* 烂透了代码
if (this.age > p.age)
return 1;
if (this.age < p.age)
return -1;
else
return this.name.compareTo(p.name);
*/
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString(){
return name+":"+age;
}
}
//第二种方法实现Comparator接口的比较器
class ComparatorByName implements Comparator
{
public int compare(Object o1,Object o2)
{
Person_0 s1 = (Person_0)o1;
Person_0 s2 = (Person_0)o2;
int temp = s1.getName().compareTo(s2.getName());
return temp == 0 ?s1.getAge()-s2.getAge():temp;
// return 1;//有序
// return -1;//倒序
}
}
/*
姓名:chaiyun 年龄:21
姓名:chenyufan 年龄:18
姓名:cwhat 年龄:22
姓名:shishuo_01 年龄:18
姓名:shishuo_02 年龄:18
姓名:shiying 年龄:20
TreeSet集合——二叉树
小插曲:
怎样实现怎么存进去就怎样取出来(有序)
让Comparator接口比较器的compare返回值为1,就可以,怎样比较都是1,结果为正数,就会有序输出。
反之返回值改为-1,就是倒序。优雅,实在是太优雅了
TreeSet练习
/*
* 对字符串进行长度排序
*/
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(new CompareByLength());
treeSet.add("shishuo_01");
treeSet.add("shiying");
treeSet.add("shishuo_02");
treeSet.add("chenyufan");
treeSet.add("chaiyun");
treeSet.add("cwhat");
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
class CompareByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
String s1 = (String) o1;
String s2 = (String) o2;
int temp = s1.length() - s2.length();
return temp == 0 ? s1.compareTo(s2) : temp;
}
}
/*
输出:
cwhat
chaiyun
shiying
chenyufan
shishuo_01
shishuo_02
泛型
概述
泛型:JDK1.5 出现的安全机制。表现格式:<>
好处:
- 将运行时期的问题ClassCastException()转到了编译时期。
- 避免了强制转换的麻烦。
<>:什么时候用?
当操作的引用数据类型不确定的时候。就使用<>。将要操作的引用数据类型转入即可。
其实<>就是一个用于接收具体引用数据类型的参数范围。
在程序中,只要用到了带有<>的类或者接口,就要明确传入的具体引用数据类型。
当使用集合时,将集合中要存储的数据类型作为参数传递到<>中即可。
小知识:Class ArrayList
擦除&补偿
泛型技术:其实应用在编译时期,是给编译器使用的技术,到了运行时期,泛型就不存在了。
为什么? 因为泛型的擦除:
也就是说,编辑器检查了泛型的类型正确后,在生成的类文件中是没有泛型的。
在运行时,如何知道获取的元素类型而不用强转呢?
泛型的补偿:因为存储的时候,类型已经确定了是同一个类型的元素,所以在运行时,只要获取到该元素的类型,在内部进行一次转换即可,所以使用者不用再做转换动作了。
import java.util.*;
class GenericDemo2
{
public static void main(String[] args)
{
TreeSet<String> ts = new TreeSet<String>(new LenComparator());
ts.add("abcd");
ts.add("cc");
ts.add("cba");
ts.add("aaa");
ts.add("z");
ts.add("hahaha");
Iterator<String> it = ts.iterator();
while(it.hasNext())
{
String s = it.next();
System.out.println(s);
//补偿:Class c = "abcd".getClass();获取到该元素的类型
// c.getName(); 元素类型名称。
}
}
}
class LenComparator implements Comparator<String>
{
public int compare(String o1,String o2)
{
int num = new Integer(o2.length()).compareTo(new Integer(o1.length()));
if(num==0)
return o2.compareTo(o1);
return num;
}
}
泛型类
什么时候用泛型类呢?
当类中的操作的引用数据类型不确定的时候,以前用的Object来进行扩展的,现在可以用泛型来表示。这样可以避免强转的麻烦,而且将运行问题转移到的编译时期。
class Worker{}
class Student{}
//泛型前做法。
class Tool
{
private Object obj;
public void setObject(Object obj)
{
this.obj = obj;
}
public Object getObject()
{
return obj;
}
}
//泛型类。
//在jdk1.5后,使用泛型来接收类中要操作的引用数据类型。
/*
什么时候定义泛型类?
当类中要操作的引用数据类型不确定的时候,
就用泛型类来表示。
*/
class Utils<QQ>
{
private QQ q;
public void setObject(QQ q)
{
this.q = q;
}
public QQ getObject()
{
return q;
}
}
class GenericDemo3
{
public static void main(String[] args)
{
Utils<Worker> u = new Utils<Worker>();
u.setObject(new Worker());
Worker w = u.getObject();;
/*
Tool t = new Tool();
t.setObject(new Student());
Worker w = (Worker)t.getObject();
*/
}
}
泛型方法
/**
*
* 将泛型定义在方法上。
*/
public <W> void show(W str){
System.out.println("show : "+str.toString());
}
public void print(QQ str){
System.out.println("print : "+str);
}
/**
* 当方法静态时,不能访问类上定义的泛型。如果静态方法使用泛型,
* 只能将泛型定义在方法上。
* @param obj
*/
//静态方法上的泛型:静态方法无法访问类上定义的泛型。
//如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
public static <Y> void method(Y obj){
System.out.println("method:"+obj);
}
Tool<String> tool = new Tool<String>();
tool.show(new Integer(4));
tool.show("abc");
tool.print("hahah");
// tool.print(newInteger(8));
Tool.method("haha");
Tool.method(new Integer(9));
泛型接口
package com.Generic;
public class GenericDemo_2 {
public static void main(String[] args) {
InterImp interImp = new InterImp();
interImp.show("陈宇凡");
InterImp_02<Integer> imp_02 = new InterImp_02<Integer>();//在调用的时候才明确数据类型
imp_02.show(1228);
}
}
interface Inter<T>{public void show(T t);}
//第一种开始就确定了数据类型
class InterImp implements Inter<String>{
@Override
public void show(String s) {
System.out.println(s);
}
}
//第二种,不明确数据类型,将问题抛给调用者
class InterImp_02<W> implements Inter<W>{
@Override
public void show(W w) {
System.out.println(w);
}
}
泛型限定 ——上下限
泛型中的通配符:可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
泛型限定:
上限:?extends E:可以接收E类型或者E的子类型对象。
下限:?super E:可以接收E类型或者E的父类型对象。
private static void PrintCollection(Collection<? extends Person> al)
private static void PrintCollection(Collection<? super Student> al)
上限什么时候用:往集合中添加元素时,既可以添加E类型对象,又可以添加E的子类型对象。为什么?因为取的时候,E类型既可以接收E类对象,又可以接收E的子类型对象。
下限什么时候用:当从集合中获取元素进行操作的时候,可以用当前元素的类型接收,也可以用当前元素的父类型接收。
泛型的细节:
-
泛型到底代表什么类型取决于调用者传入的类型,如果没传,默认是Object类型;
-
使用带泛型的类创建对象时,等式两边指定的泛型必须一致;
原因:编译器检查对象调用方法时只看变量,然而程序运行期间调用方法时就要考虑对象具体类型了;
-
等式两边可以在任意一边使用泛型,在另一边不使用(考虑向后兼容);
ArrayList<String> al = new ArrayList<Object>(); //错//要保证左右两边的泛型具体类型一致就可以了,这样不容易出错。
ArrayList<? extends Object> al = new ArrayList<String>(); al.add("aa"); //错因为集合具体对象中既可存储String,也可以存储Object的其他子类,所以添加具体的类型对象不合适,类型检查会出现安全问题。
?extends Object 代表Object的子类型不确定,怎么能添加具体类型的对象呢?
public static void method(ArrayList<? extends Object> al) { al.add("abc"); //错 }只能对al集合中的元素调用Object类中的方法,具体子类型的方法都不能用,因为子类型不确定。
package com.Generic;
/*
* 上下限演示:
*/
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class GenericAdvanceDemo {
public static void main(String[] args) {
ArrayList<Person> arrayList = new ArrayList<Person>();
arrayList.add(new Person("石硕",12));
arrayList.add(new Person("陈宇凡",13));
ArrayList<Student_> shi = new ArrayList<Student_>();
shi.add(new Student_("shishuo",14));
shi.add(new Student_("chenyufan",15));
ArrayList<String> shuo = new ArrayList<String>();
shuo.add("wflafl");
shuo.add("fhsalfla");
PrintCollection(arrayList);
PrintCollection(shi);
// PrintCollection(shuo);
}
private static void PrintCollection(Collection<? extends Person> al) {
//Collection<Person> al =new ArrayList<Person>();
Iterator<? extends Person> it = al.iterator();
while (it.hasNext()){
// T t = it.next();
// System.out.println(it.next());
Person p = it.next();
System.out.println(p);
}
}
// private static<T> void PrintCollection(Collection<T> al) {
//
// Iterator<T> it = al.iterator();
// while (it.hasNext()){
// T t = it.next();
// System.out.println(t);
// }
// }
}
class Person
{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString(){
return name+":"+age;
}
}
class Student_ extends Person{
Student_(String name, int age) {
super(name, age);
}
}
泛型限定——上限的体现
public static void main(String[] args) {
ArrayList<Person>al1 = new ArrayList<Person>();
al1.add(new Person("abc",30));
al1.add(new Person("abc4",34));
ArrayList<Student>al2 = new ArrayList<Student>();
al2.add(new Student("stu1",11));
al2.add(new Student("stu2",22));
ArrayList<Worker>al3 = new ArrayList<Worker>();
al3.add(new Worker("stu1",11));
al3.add(new Worker("stu2",22));
ArrayList<String>al4 = new ArrayList<String>();
al4.add("abcdeef");
// al1.addAll(al4);//错误,类型不匹配。
al1.addAll(al2);
al1.addAll(al3);
System.out.println(al1.size());
// printCollection(al2);
// printCollection(al);
}
}
/*
* 一般在存储元素的时候都是用上限,因为这样取出都是按照上限类型来运算的。不会出现类型安全隐患。
*/
class MyCollection<E>{
public void add(E e){
}
public void addAll(MyCollection<? extends E> e){
}
}
泛型限定——下限的体现
public static void main(String[] args) {
TreeSet<Person> al1 = new TreeSet<Person>(new CompByName());
al1.add(new Person("abc4",34));
al1.add(new Person("abc1",30));
al1.add(new Person("abc2",38));
TreeSet<Student>al2 = new TreeSet<Student>(new CompByName());
al2.add(new Student("stu1",11));
al2.add(new Student("stu7",20));
al2.add(new Student("stu2",22));
TreeSet<Worker>al3 = new TreeSet<Worker>();
al3.add(new Worker("stu1",11));
al3.add(new Worker("stu2",22));
TreeSet<String>al4 = new TreeSet<String>();
al4.add("abcdeef");
// al1.addAll(al4);//错误,类型不匹配。
// al1.addAll(al2);
// al1.addAll(al3);
// System.out.println(al1.size());
Iterator<Student>it = al2.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
/*
* class TreeSet<Worker>
* {
* Tree(Comparator<? super Worker> comp);
* }
* 什么时候用下限呢?通常对集合中的元素进行取出操作时,可以是用下限。
*/
class CompByName implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByStuName implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByWorkerName implements Comparator<Worker> {
@Override
public int compare(Worker o1, Worker o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
Map集合
Map方法摘要
-
- | Modifier and Type | 方法 | 描述 |
| ----------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|void|clear()| 从该地图中删除所有的映射(可选操作)。 |
|default V|compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)| 尝试计算指定键的映射及其当前映射值(如果没有当前映射,则null)。 |
|default V|computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)| 如果指定的键尚未与值相关联(或映射到null),则尝试使用给定的映射函数计算其值,并将其输入到此映射中,除非是null。 |
|default V|computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)| 如果指定的密钥的值存在且非空,则尝试计算给定密钥及其当前映射值的新映射。 |
|boolean|containsKey(Object key)| 如果此映射包含指定键的映射,则返回true。 |
|boolean|containsValue(Object value)| 如果此映射将一个或多个键映射到指定的值,则返回true。 |
|static <K,V> Map.Entry<K,V>|entry(K k, V v)| 返回包含给定键和值的不可变Map.Entry。 |
|Set<Map.Entry<K,V>>|entrySet()| 返回此地图中包含的映射的Set视图。 |
|boolean|equals(Object o)| 将指定的对象与此映射进行比较以获得相等性。 |
|default void|forEach(BiConsumer<? super K,? super V> action)| 对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常。 |
|V|get(Object key)| 返回指定键映射到的值,如果此映射不包含该键的映射,则返回null。 |
|default V|getOrDefault(Object key, V defaultValue)| 返回指定键映射到的值,如果此映射不包含该键的映射,则返回defaultValue。 |
|int|hashCode()| 返回此地图的哈希码值。 |
|boolean|isEmpty()| 如果此映射不包含键值映射,则返回true。 |
|Set<K>|keySet()| 返回此地图中包含的键的Set视图。 |
|default V|merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)| 如果指定的键尚未与值相关联或与null相关联,则将其与给定的非空值相关联。 |
|static <K,V> Map<K,V>|of()| 返回一个包含零映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1)| 返回包含单个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2)| 返回包含两个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3)| 返回包含三个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4)| 返回包含四个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5)| 返回一个包含五个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6)| 返回包含六个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7)| 返回包含七个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7, K k8, V v8)| 返回包含八个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7, K k8, V v8, K k9, V v9)| 返回包含九个映射的不可变地图。 |
|static <K,V> Map<K,V>|of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7, K k8, V v8, K k9, V v9, K k10, V v10)| 返回包含十个映射的不可变地图。 |
|static <K,V> Map<K,V>|ofEntries(Map.Entry<? extends K,? extends V>... entries)| 返回包含从给定条目提取的键和值的不可变地图。 |
|V|put(K key, V value)| 将指定的值与该映射中的指定键相关联(可选操作)。 |
|void|putAll(Map<? extends K,? extends V> m)| 将指定地图的所有映射复制到此映射(可选操作)。 |
|default V|putIfAbsent(K key, V value)| 如果指定的键尚未与值相关联(或映射到null)将其与给定值相关联并返回null,否则返回当前值。 |
|V|remove(Object key)| 如果存在(从可选的操作),从该地图中删除一个键的映射。 |
|default boolean|remove(Object key, Object value)| 仅当指定的密钥当前映射到指定的值时删除该条目。 |
|default V|replace(K key, V value)| 只有当目标映射到某个值时,才能替换指定键的条目。 |
|default boolean|replace(K key, V oldValue, V newValue)| 仅当当前映射到指定的值时,才能替换指定键的条目。 |
|default void|replaceAll(BiFunction<? super K,? super V,? extends V> function)| 将每个条目的值替换为对该条目调用给定函数的结果,直到所有条目都被处理或该函数抛出异常。 |
|int|size()| 返回此地图中键值映射的数量。 |
|Collection<V>|values()| 返回此地图中包含的值的Collection视图。 |
- | Modifier and Type | 方法 | 描述 |
Map集合特点:
Map的底层其实就是Set
|——Hashtable:底层是哈希表数据结构,是线程同步的。不可以存储null键,null值。
|——HashMap:底层是哈希表数据结构,是线程不同步的。可以存储null键,null值。替代了Hashtable.
|——TreeMap:底层是二叉树结构,可以对map集合中的键进行指定顺序的排序。
Map集合存储和Collection集合的区别:
- Collection一次存一个元素;Map一次存一对元素。
- Collection集合称为单列集合;Map是双列集合。
Map中的存储的一对元素:一个是键,一个是值,键与值之间有对应(映射)关系。
特点:要保证map集合中键的唯一性。
基本方法
新建一个Map集合
Map<Integer,String> map = new HashMap<Integer,String>();
method(map);
private static void method(Map<Integer, String> map) {
}
1,添加。
Value put(key,value)://当存储的键相同时,新的值会替换老的值,并将老值返回。如果键没有重复,返回null。
void putAll(Map<? extends K,? extends V> m)//将指定地图的所有映射复制到此映射(可选操作)。
// 添加元素。
System.out.println(map.put(8,"wangcai"));//null
System.out.println(map.put(8,"xiaoqiang"));//wangcai 存相同键,值会覆盖。
map.put(2,"zhangsan");
map.put(7,"zhaoliu");
2,删除。
void clear();//清空map集合
value remove(key); //根据指定的Key删除这个键值对。
System.out.println("remove:"+map.remove(2));
3,判断
boolean isEmpty(); //如果此映射不包含键值映射,则返回 true 。
boolean containsKey(key); //是否包含key
boolean containsValue(value); //是否包含value
System.out.println("containskey:"+map.containsKey(7));
//containsKey:true
4,获取。
int size;//获取键值对的个数
value get(key);//通过指定键获取对应的值。如果返回null,可以判断该键不存在。
//当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的。
Collection<V> values();//返回此地图中包含的值的Collection视图。
★获取Map中所有的元素:
Set<K> keySet(); //返回此地图中包含的键的Set视图。
Set<Map.Entry<K,V>> entrySet();//返回此地图中包含的映射的Set视图。 取的是键和值的映射关系。
Entry就是Map接口中的内部接口;
为什么要定义在map内部呢?entry是访问键值关系的入口,是map的入口,访问的是map中的键值对。
获取Map中所有的元素,把map集合转成set的方法:
原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了。
之所以转成set,是因为map集合具备着键的唯一性,其实set集合就来自于map,set集合底层其实用的就是map的方法。
方法一:KeySet
取出map集合中所有元素的方式一:keySet()方法。
Set
keySet:将map中所有的键存入到Set集合。因为set具备迭代器。
所有可以迭代方式取出所有的键,在根据get方法。获取每一个键对应的值。Map集合的取出原理:将map集合转成set集合。在通过迭代器取出。
//取出map中的所有元素。
//原理,通过keySet方法获取map中所有的键所在的Set集合,在通过Set的迭代器获取到每一个键,
//在对每一个键通过map集合的get方法获取其对应的值即可。
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"石硕");
map.put(2,"陈宇凡");
//先获取map集合的所有键的Set集合,keySet();
Set<Integer> keySet = map.keySet();
//有了Set集合。就可以获取其迭代器。
Iterator<Integer> it = keySet.iterator();
while(it.hasNext())
{
Integer key = it.next();
//有了键可以通过map集合的get方法获取其对应的值。
String value = map.get(key);
System.out.println(key+":"+value);
}
keySet——演示图解

方法二:EntrySet
取出map集合中所有元素的方式二:entrySet()方法。
Set<Map.Entry<k,v>> entrySet:将map集合中的映射关系存入到了set集合中,
而这个关系的数据类型就是:Map.Entry Entry其实就是Map中的一个static内部接口。
为什么要定义在内部呢?
因为只有有了Map集合,有了键值对,才会有键值的映射关系。
关系属于Map集合中的一个内部事物。
而且该事物在直接访问Map集合中的元素。
/*
Map.Entry 其实Entry也是一个接口,它是Map接口中的一个内部接口。
interface Map
{
public static interface Entry
{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map
{
class Hahs implements Map.Entry
{
public Object getKey(){}
public Object getValue(){}
}
}
*/
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"石硕");
map.put(2,"陈宇凡");
//将Map集合中的映射关系取出。存入到Set集合中。
Set<Map.Entry<Integer,String>> entrySet = map.entrySet();
Iterator<Map.Entry<Integer,String>> it = entrySet.iterator();
while(it.hasNext()){
Map.Entry<Integer,String> me = it.next();
Integer Key = me.getKey();
String value = me.getValue();
System.out.println(Key +" "+value);
}
EntrySet——演示图解

方法Values
map.put(8,"zhaoliu");
map.put(2,"zhaoliu");
map.put(7,"xiaoqiang");
map.put(6,"wangcai");
Collection<String> values = map.values();
Iterator<String> it2 = values.iterator();
while(it2.hasNext()){
System.out.println(it2.next());
}
/*输出:
zhaoliu
wangcai
xiaoqiang
zhaoliu
*/
常见子类对象:
Map常用的子类:
-
Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
- Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
-
HashMap: 内部结构是哈希表,线程不同步。允许null作为键,null作为值。
-
TreeMap : 内部结构是二叉树,线程不同步。可以对Map集合中的键进行排序。
HashMap储存自定义对象
package com.Map;
/*
每一个学生都有对应的归属地。
学生Student,地址String。
学生属性:姓名,年龄。
注意:姓名和年龄相同的视为同一个学生。
保证学生的唯一性。
1,描述学生。
2,定义map容器。将学生作为键,地址作为值。存入。
3,获取map集合中的元素。
*/
import java.util.HashMap;
import java.util.Iterator;
import java.util.Objects;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
HashMap<Student_1,String> hashMap = new HashMap<Student_1,String>();
hashMap.put(new Student_1("lisi1",21),"beijing");
hashMap.put(new Student_1("lisi1",21),"tianjin");
hashMap.put(new Student_1("lisi2",22),"shanghai");
hashMap.put(new Student_1("lisi3",23),"nanjing");
hashMap.put(new Student_1("lisi4",24),"wuhan");
//第一种取出方式 keySet
Set<Student_1> keySet = hashMap.keySet();
Iterator<Student_1> it = keySet.iterator();
// 上面两句,其实就是这一句:Iterator<Student_1> it = hashMap.keySet().iterator();
while(it.hasNext())
{
Student_1 stu = it.next();
String addr = hashMap.get(stu);
System.out.println(stu+".."+addr);
}
}
}
class Student_1 implements Comparable<Student_1>
{
private String name;
private int age;
Student_1(String name,int age)
{
this.name = name;
this.age = age;
}
//如果想保证键相同,必须提供键相同的依据,可以在hashMap复写hashCode和equals方法。
public int compareTo(Student_1 s)
{
int temp = this.age - s.age;
return temp == 0 ? this.name.compareTo(s.name):temp;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student_1 student_1 = (Student_1) o;
return age == student_1.age && Objects.equals(name, student_1.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString()
{
return name+":"+age;
}
}
/*
lisi1:21..tianjin
lisi2:22..shanghai
lisi3:23..nanjing
lisi4:24..wuhan
*/
TreeMap存储自定义对象
/*
需求:对学生对象的年龄进行升序排序。
因为数据是以键值对形式存在的。
所以要使用可以排序的Map集合。TreeMap。
*/
import java.util.*;
class StuNameComparator implements Comparator<Student>
{
public int compare(Student s1,Student s2)
{
int num = s1.getName().compareTo(s2.getName());
if(num==0)
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
return num;
}
}
class MapTest2
{
public static void main(String[] args)
{
TreeMap<Student,String> tm = new TreeMap<Student,String>(new StuNameComparator());
tm.put(new Student("blisi3",23),"nanjing");
tm.put(new Student("lisi1",21),"beijing");
tm.put(new Student("alisi4",24),"wuhan");
tm.put(new Student("lisi1",21),"tianjin");
tm.put(new Student("lisi2",22),"shanghai");
Set<Map.Entry<Student,String>> entrySet = tm.entrySet();
Iterator<Map.Entry<Student,String>> it = entrySet.iterator();
while(it.hasNext())
{
Map.Entry<Student,String> me = it.next();
Student stu = me.getKey();
String addr = me.getValue();
System.out.println(stu+":::"+addr);
}
}
}
/*
lisi1:21..tianjin
lisi2:22..shanghai
lisi3:23..nanjing
lisi4:24..wuhan
*/
LinkedHashMap&关联源码
HashMap<Integer,String>hm = newLinkedHashMap<Integer,String>();
hm.put(7, "zhouqi");
hm.put(3, "zhangsan");
hm.put(1, "qianyi");
hm.put(5, "wangwu");
Iterator<Map.Entry<Integer,String>>it = hm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer,String> me = it.next();
Integer key = me.getKey();
String value = me.getValue();
System.out.println(key+":"+value);
}
Map练习
记录字母次数
package com.Map;
import java.util.Iterator;
import java.util.Map;
import java.util.TreeMap;
public class MapEndTest {
public static void main(String[] args) {
String str = "fjlaglSGewh#%……a765FDl88g8n*(dlah6365 goDGeiw gnalgdhaGSDAhg l j *-/-tg";
String s = getCharCount(str);
System.out.println(s);
}
private static String getCharCount(String str) {
//1.将字符串变为单个字符
char[] chars = str.toCharArray();
//2.定义map集合表
Map<Character,Integer> map = new TreeMap<Character,Integer>();
for (int i = 0; i < chars.length; i++) {
if (!(chars[i] >= 'a' && chars[i] <= 'z' || chars[i] >= 'A' && chars[i] <= 'Z'))
continue;
//将数组中的字母作为键去查表
Integer value = map.get(chars[i]);
int count = 1;
//4.判断值是否为null
if (value!=null) count = value + 1;
map.put(chars[i],count); //第一遍循环,值为1
// if (value==null)
// map.put(chars[i],1);
// else
// map.put(chars[i],value+1);//自动装箱拆箱
}
return mapToString(map);
}
private static String mapToString(Map<Character, Integer> map) {
StringBuilder sb = new StringBuilder();
Iterator<Character> it = map.keySet().iterator();
while (it.hasNext()) {
Character key = it.next();
Integer value = map.get(key);
sb.append(key + "(" + value + ")");
}
return sb.toString();
}
}
Map查表法
键值关系多就往Map表里存
Map集合在有映射关系时,可以优先考虑。
在查表法中的应用较为多见。
package com.Map;
import java.util.HashMap;
import java.util.Map;
public class MapSearch {
public static void main(String[] args) {
String week = "星期一";
System.out.println(week);
System.out.println(getWeekByMap(week));
}
private static String getWeekByMap(String week) {
Map<String,String> map = new HashMap<>();
map.put("星期一","Mon");
map.put("星期二","Tus");
map.put("星期三","Wes");
map.put("星期天","Sun");
map.put("礼拜天","Sun");
return map.get(week);
}
}
使用集合的技巧
看到Array就是数组结构,有角标,查询速度很快。
看到link就是链表结构:增删速度快,而且有特有方法。addFirst; addLast; removeFirst(); removeLast(); getFirst();getLast();
看到hash就是哈希表,就要想要哈希值,就要想到唯一性,就要想到存入到该结构的中的元素必须覆盖hashCode,equals方法。
看到tree就是二叉树,就要想到排序,就想要用到比较。
比较的两种方式:
一个是Comparable:覆盖compareTo方法;
一个是Comparator:覆盖compare方法。
LinkedHashSet,LinkedHashMap:这两个集合可以保证哈希表有存入顺序和取出顺序一致,保证哈希表有序。
集合什么时候用?
当存储的是一个元素时,就用Collection。当存储对象之间存在着映射关系时,就使用Map集合。
保证唯一,就用Set。不保证唯一,就用List。
集合框架工具类
Collections:
它的出现给集合操作提供了更多的功能。这个类不需要创建对象,内部提供的都是静态方法。
静态方法:
Collections-排序
Collections.sort(list);//list集合进行元素的自然顺序排序。
Collections.sort(list,new ComparatorByLen());//按指定的比较器方法排序。
class ComparatorByLen implements Comparator<String>{
public int compare(String s1,String s2){
int temp = s1.length()—s2.length();
return temp==0?s1.compareTo(s2):temp;
}
}
Collections-折半&最值
Collections.max(list); //返回list中字典顺序最大的元素。
int index = Collections.binarySearch(list,"zz");//二分查找,返回角标。
Collections-逆序&替换
Collections.reverseOrder();//逆向反转排序。
Collections.replaceAll(list,"cba", "nba"); // set(indexOf("cba"),"nba");
Collections.fill(list,"cc");//用指定的元素替换指定列表的所有元素。
Collections.shuffle(list);//随机对list中的元素进行位置的置换。
Collection-将非同步集合转成集合
List list = new ArrayList();//非同步的。
list = MyCollections.synList(list);//返回一个同步的list.
Collections中的 XXX synchronized XXX(XXX);
List synchronizedList(list);
Map synchronizedMap(map);
原理:定义一个类,将集合所有的方法加同一把锁后返回。
//给非同步的集合加锁。
class MyCollections{
publicstatic List synList(List list){
return new MyList(list);
}
privateclass MyList implements List{
privateList list;
privatestatic final Object lock = new Object();
MyList(Listlist){
this.list = list;
}
publicboolean add(Object obj){
synchronized(lock)
{
returnlist.add(obj);
}
}
publicboolean remove(Object obj){
synchronized(lock)
{
returnlist.remove(obj);
}
}
}
}
Arrays-方法介绍
用于操作数组对象的工具类,里面都是静态方法。
//17-常用对象API(集合框架-工具类-Arrays-方法介绍)
int[] arr = {3,1,5,6,3,6};
//toString的经典实现。
public static String myToString(int[] a){
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {//中间省略条件判断[i<a.length() 因为每循环一次就调用一次],提高了效率。
b.append(a[i]);
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}
Arrays-asList方法
asList方法:将数组转换成list集合。
String[] arr = {"abc","kk","qq"};
List<String> list = Arrays.asList(arr);//将arr数组转成list集合。
// list.add("hiahia");//UnsupportedOperationException
用aslist方法,将数组变成集合的好处:
可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set;
注意(局限性):数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException);
如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。
如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。
Collection-toArray方法
集合变数组:用的是Collection接口中的方法:toArray();
toArray方法需要传入一个指定类型的数组。
长度该如何定义呢?
-
如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。
-
如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。
- 所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
List<String> list= new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
String[] arr =list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(arr));
将集合变成数组后有什么好处?限定了对集合中的元素进行增删操作,只要获取这些元素即可。
JDK5.0新特性-增强ForEach循环
Collection在jdk1.5以后,有了一个父接口Iterable,这个接口的出现的将iterator方法进行抽取,提高了扩展性。
增强for循环:foreach语句,foreach简化了迭代器。
格式:// 增强for循环括号里写两个参数,第一个是声明一个变量,第二个就是需要迭代的容器
for( 元素类型 变量名 : Collection集合 & 数组 ) {
…
}
高级for循环和传统for循环的区别:
高级for循环在使用时,必须要明确被遍历的目标。这个目标,可以是Collection集合或者数组,如果遍历Collection集合,在遍历过程中还需要对元素进行操作,比如删除,需要使用迭代器。
如果遍历数组,还需要对数组元素进行操作,建议用传统for循环因为可以定义角标通过角标操作元素。如果只为遍历获取,可以简化成高级for循环,它的出现为了简化书写。
高级for循环可以遍历map集合吗?
不可以。但是可以将map转成set后再使用foreach语句。
优点:
-
作用:对存储对象的容器进行迭代: 数组 collection map
-
增强for循环迭代数组:
int[] arr = {1,56,45,6,89,34,5};//数组的静态定义方式,只试用于数组首次定义的时候
for (int al: arr) {
System.out.print(al+" ");
}
- 单列集合 Collection:
List list = new ArrayList();
list.add("aaa");
// 增强for循环, 没有使用泛型的集合能不能使用增强for循环迭代?能
for(Object obj : list) {
String s = (String) obj;
System.out.println(s);
}
- 双列集合 Map:
Map map = new HashMap();
map.put("a", "aaa");
**// 传统方式:必须掌握这种方式**
Set entrys = map.entrySet(); // 1.获得所有的键值对Entry对象
iter = entrys.iterator(); // 2.迭代出所有的entry
while(iter.hasNext()) {
Map.Entry entry = (Entry) iter.next();
String key = (String) entry.getKey(); // 分别获得key和value
String value = (String) entry.getValue();
System.out.println(key + "=" + value);
}
增强for循环迭代:
原则上map集合是无法使用增强for循环来迭代的,因为增强for循环只能针对实现了Iterable接口的集合进行迭代;Iterable是jdk5中新定义的接口,就一个方法iterator方法,只有实现了Iterable接口的类,才能保证一定有iterator方法,java有这样的限定是因为增强for循环内部还是用迭代器实现的,而实际上,我们可以通过某种方式来使用增强for循环。
for(Object obj : map.entrySet()) {**
Map.Entry entry = (Entry) obj; // obj 依次表示Entry
System.out.println(entry.getKey() + "=" + entry.getValue());
}
-
集合迭代注意问题:在迭代集合的过程中,不能对集合进行增删操作(会报并发访问异常);可以用迭代器的方法进行操作(子类listIterator:有增删的方法)。
-
增强for循环注意问题:在使用增强for循环时,不能对元素进行赋值;
int[] arr = {1,2,3};
for(int num : arr) {
num = 0; //不能改变数组的值
}
System.out.println(arr[1]); //2
JDK5.0-函数可变参数
可变参数(...):用到函数的参数上,当要操作的同一个类型元素个数不确定的时候,可是用这个方式,这个参数可以接受任意个数的同一类型的数据。
package com.practice;
/*
* 函数的可变参数。
* 其实就是一个数组,但是接收的是数组的元素。
* 自动将这些元素封装成数组。简化了调用者的书写。
* 注意:可变参数类型,必须定义在参数列表的结尾。
*/
public class Demo {
public static void main(String[] args) {
int sum = newAdd(5,1,4,7,3);
System.out.println("sum="+sum);
int sum1 = newAdd(5,1,2,7,3,9,8,7,6);
System.out.println("sum1="+sum1);
}
public static int newAdd(int a,int... arr){
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum+=arr[i];
}
return sum;
}
/*
public static int add(int a,int b){
return a+b;
}
*/
}
和以前接收数组不一样的是:
以前定义数组类型,需要先创建一个数组对象,再将这个数组对象作为参数传递给函数。现在,直接将数组中的元素作为参数传递即可。底层其实是将这些元素进行数组的封装,而这个封装动作,是在底层完成的,被隐藏了。所以简化了用户的书写,少了调用者定义数组的动作。
如果在参数列表中使用了可变参数,可变参数必须定义在参数列表结尾(也就是必须是最后一个参数,否则编译会失败。)。
如果要获取多个int数的和呢?可以使用将多个int数封装到数组中,直接对数组求和即可。
例如:
-
- |
static <T> List<T>|asList(T... a)| 返回由指定数组支持的固定大小的列表。 |
| -------------------- | ---------------- | ------------------------------------ |
- |
JDK5.0-静态导入
导入了类中的所有静态成员,简化静态成员的书写。
import static java.util.Collections.*; //导入了Collections类中的所有静态成员
public static void main(String[] args) {
sort(list); //Collections.sort(list);
System.out.println(list);
String max = max(list);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号