商品零售购物篮分析
import numpy as np
import pandas as pd
inputfile='GoodsOrder.csv'
data=pd.read_csv(inputfile,encoding='gbk')
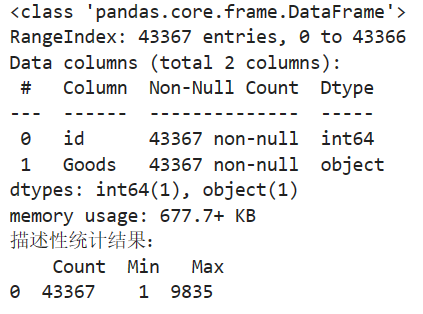
data.info()
data=data['id']
description=[data.count(),data.min(),data.max()]
description=pd.DataFrame(description,index=['Count','Min','Max']).T
print('描述性统计结果:\n',np.round(description))
import pandas as pd
inputfile='GoodsOrder.csv'
data=pd.read_csv(inputfile,encoding='gbk')
group=data.groupby(['Goods']).count().reset_index()
sorted=group.sort_values('id',ascending=False)
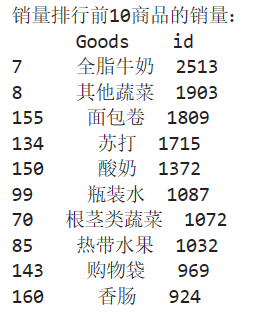
print('销量排行前10商品的销量:\n',sorted[:10])
import matplotlib.pyplot as plt
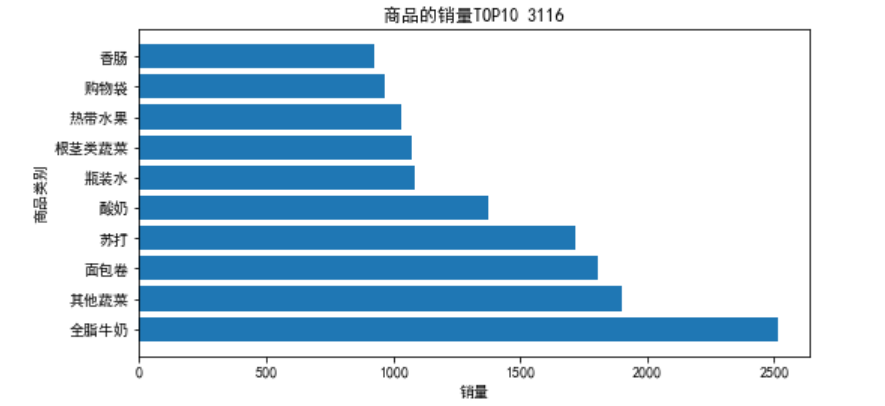
x=sorted[:10]['Goods']
y=sorted[:10]['id']
plt.figure(figsize=(8,4))
plt.barh(x,y)
plt.rcParams['font.sans-serif']='SimHei'
plt.xlabel('销量')
plt.ylabel('商品类别')
plt.title('商品的销量TOP10 3116')
plt.savefig('top10.png')
plt.show()
data_nums=data.shape[0]
for index,row in sorted[:10].iterrows():
print(row['Goods'],row['id'],row['id']/data_nums)

import pandas as pd
inputfile1='GoodsOrder.csv'
inputfile2='GoodsTypes.csv'
data=pd.read_csv(inputfile1,encoding='gbk')
types=pd.read_csv(inputfile2,encoding='gbk')
group=data.groupby(['Goods']).count().reset_index()
sort=group.sort_values('id',ascending=False).reset_index()
data_nums=data.shape[0]
del sort['index']
sort_links=pd.merge(sort,types)
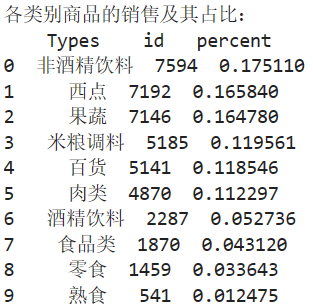
sort_link=sort_links.groupby(['Types']).sum().reset_index()
sort_link=sort_link.sort_values('id',ascending=False).reset_index()
del sort_link['index']
sort_link['count']=sort_link.apply(lambda line:line['id']/data_nums,axis=1)
sort_link.rename(columns={'count':'percent'},inplace=True)
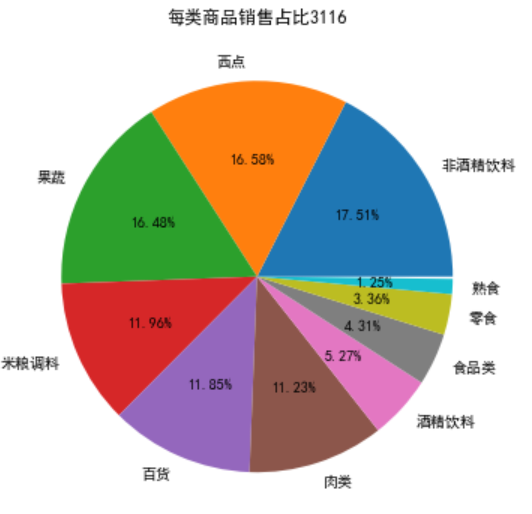
print('各类别商品的销售及其占比:\n',sort_link)
outfile1='percent.csv'
sort_link.to_csv(outfile1,index=False,header=True,encoding='gbk')
import matplotlib.pyplot as plt
data=sort_link['percent']
labels=sort_link['Types']
plt.figure(figsize=(8,6))
plt.pie(data,labels=labels,autopct='%1.2f%%')
plt.rcParams['font.sans-serif']='SimHei'
plt.title('每类商品销售占比3116')
plt.savefig('persent.png')
plt.show()
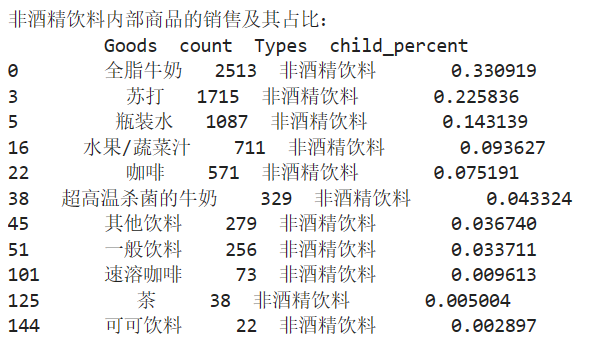
selected=sort_links.loc[sort_links['Types']=='非酒精饮料']
child_nums=selected['id'].sum()
selected['child_percent']=selected.apply(lambda line:line['id']/child_nums,axis=1)
selected.rename(columns={'id':'count'},inplace=True)
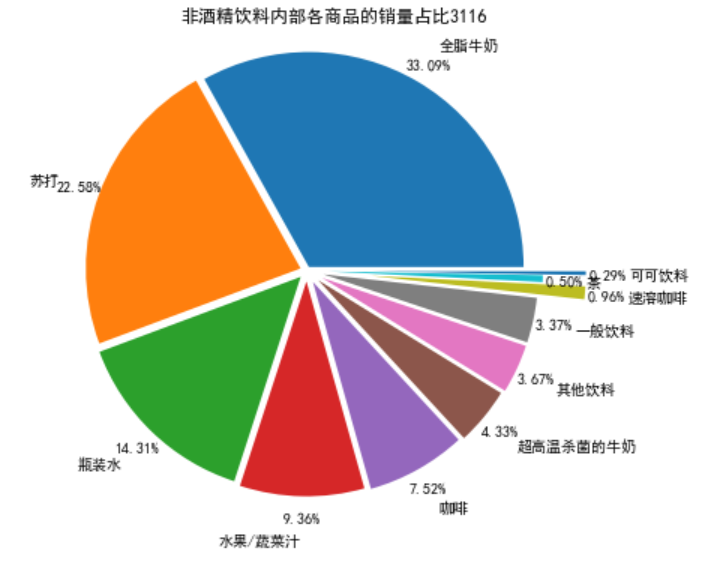
print('非酒精饮料内部商品的销售及其占比:\n',selected)
outfile2='child_percent.csv'
sort_link.to_csv(outfile2,index=False,header=True,encoding='gbk')
import matplotlib.pyplot as plt
data=selected['child_percent']
labels=selected['Goods']
plt.figure(figsize=(8,6))
explode=(0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3)
plt.pie(data,explode=explode,labels=labels,autopct='%1.2f%%',pctdistance=1.1,labeldistance=1.2)
plt.rcParams['font.sans-serif']='SimHei'
plt.title("非酒精饮料内部各商品的销量占比3116")
plt.axis('equal')
plt.savefig('child_persent.png')
plt.show()
import pandas as pd
inputfile='GoodsOrder.csv'
data=pd.read_csv(inputfile,encoding='gbk')
data['Goods']=data['Goods'].apply(lambda x:','+x)
data=data.groupby(['id'])['Goods'].sum().reset_index()
data['Goods']=data['Goods'].apply(lambda x: [x[1:]])
data_list=list(data['Goods'])
data_translation=[]
for i in data_list:
p=i[0].split(',')
data_translation.append(p)
print('数据转换结果的前5个元素:\n',data_translation[0:5])

from numpy import *
def loadDataSet():
return [['a','c','e'],['b','d'],['b','c'],['a','b','c','d'],['a','b'],['b','c'],['a','b'],['a','b','c','e'],['a','b','c'],['a','c','e']]
def createC1(dataSet):
C1=[]
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset,C1))
def scanD(D,Ck,minSupport):
ssCnt={}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not can in ssCnt:
ssCnt[can]=1
else:
ssCnt[can]+=1
numItems=float(len(D))
retList=[]
supportData={}
for key in ssCnt:
support=ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key]=support
return retList,supportData
def calSupport(D,Ck,min_support):
dict_sup={}
for i in D:
for j in Ck:
if j.issubset(i):
if not j in dict_sup:
dict_sup[j]=1
else:dict_sup[j]+=1
sumCount=float(len(D))
supportData={}
relist=[]
for i in dict_sup:
temp_sup=dict_sup[i]/sumCount
if temp_sup>=min_support:
relist.append(i)
supportData[i]=temp_sup
return relist,supportData
def aprioriGen(Lk,k):
retList=[]
lenLk=len(Lk)
for i in range(lenLk):
for j in range(lenLk):
L1=list(Lk[i])[:k-2]
L2=list(Lk[i])[:k-2]
L1.sort()
L2.sort()
if L1==L2:
a=Lk[i]|Lk[j]
a1=list(a)
b=[]
for q in range(len(a1)):
t=[a1[q]]
tt=frozenset(set(a1)-set(t))
b.append(tt)
t=0
for w in b:
if w in Lk:
t+=1
if t==len(b):
retList.append(b[0]|b[1])
return retList
def apriori(dataSet,minSupport=0.2):
C1=createC1(dataSet)
D=list(map(set,dataSet))
L1,supportData=calSupport(D,C1,minSupport)
L=[L1]
k=2
while(len(L[k-2])>0):
Ck=aprioriGen(L[k-2],k)
Lk,supK=scanD(D,Ck,minSupport)
supportData.update(supK)
L.append(Lk)
k+=1
del L[-1]
return L,supportData
def getSubset(fromList,toList):
for i in range(len(fromList)):
t=[fromList[i]]
tt=frozenset(set(fromList)-set(t))
if not tt in toList:
toList.append(tt)
tt=list(tt)
tt=list(tt)
if len(tt)>1:
getSubset(tt,toList)
def calcConf(freqSet,H,supportData,ruleList,minConf=0.7):
for conseq in H:
conf=supportData[freqSet]/supportData[freqSet-conseq]
lift=supportData[freqSet]/(supportData[conseq]*supportData[freqSet-conseq])
if conf>=minConf and lift>1:
print(freqSet-conseq,'-->',conseq,'支持度',round(supportData[freqSet],6),'置信度:',round(conf,6),'lift值为:',round(lift,6))
ruleList.append((freqSet-conseq,conseq,conf))
def gen_rule(L,supportData,minConf=0.7):
bigRuleList=[]
for i in range(1,len(L)):
for freqSet in L[i]:
H1=list(freqSet)
all_subset=[]
getSubset(H1,all_subset)
calcConf(freqSet,all_subset,supportData,bigRuleList,minConf)
return bigRuleList
if __name__=='__main__':
dataSet=data_translation
L,supportData=apriori(dataSet,minSupport=0.02)
rule=gen_rule(L,supportData,minConf=0.35)

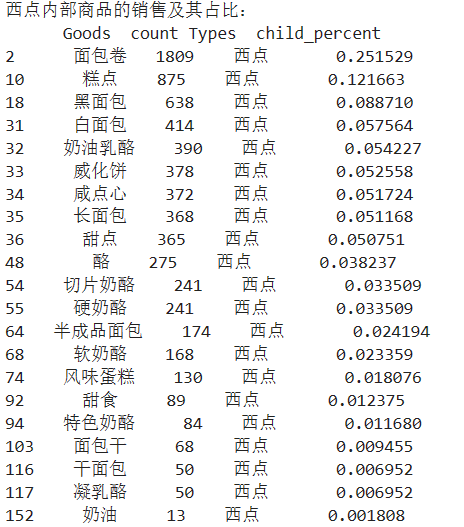
西点类占比:
selected=sort_links.loc[sort_links['Types']=='西点']
child_nums=selected['id'].sum()
selected['child_percent']=selected.apply(lambda line:line['id']/child_nums,axis=1)
selected.rename(columns={'id':'count'},inplace=True)
print('西点内部商品的销售及其占比:\n',selected)
outfile2='child_percent.csv'
sort_link.to_csv(outfile2,index=False,header=True,encoding='gbk')
import matplotlib.pyplot as plt
data=selected['child_percent']
labels=selected['Goods']
plt.figure(figsize=(8,6))
explode=(0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1)
plt.pie(data,explode=explode,labels=labels,autopct='%1.2f%%',pctdistance=1.1,labeldistance=1.2)
plt.rcParams['font.sans-serif']='SimHei'
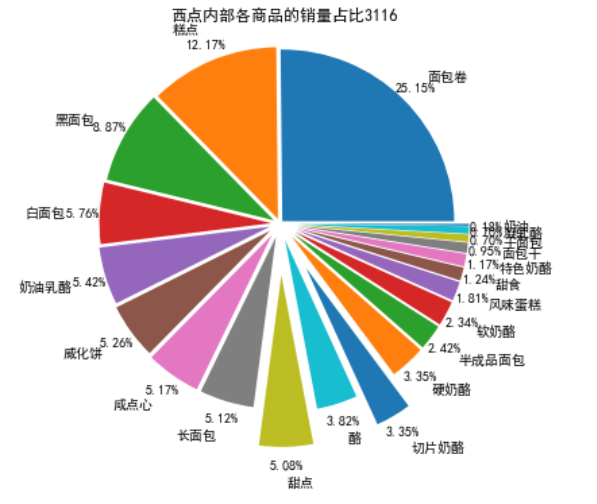
plt.title("西点内部各商品的销量占比3116")
plt.axis('equal')
plt.savefig('child_persent2.png')
plt.show()
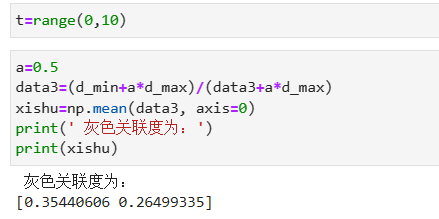
灰色关联度:
导入数据:

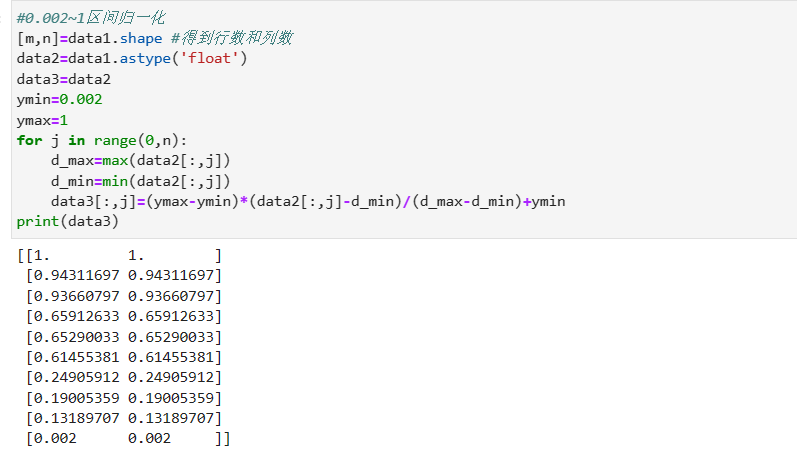
归一化:
求灰色关联度: