
python数据挖掘绘图
import pandas as pd
catering_sale=(r'D:\数据挖掘\catering_sale.xls')
data=pd.read_excel(catering_sale,index_col='日期')
print(data.describe())

import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure()
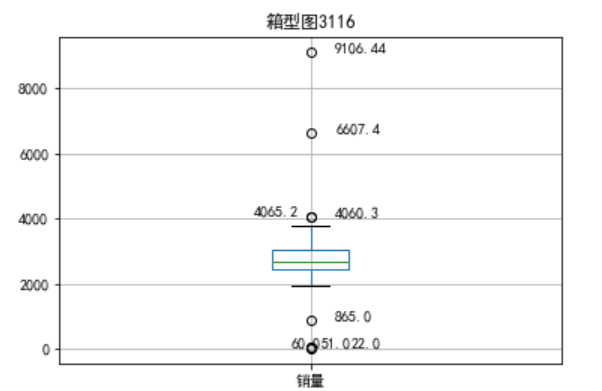
p=data.boxplot(return_type='dict')
x=p['fliers'][0].get_xdata()
y=p['fliers'][0].get_ydata()
y.sort()
for i in range(len(x)):
if i>0:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.08,y[i]))
plt.title("箱型图3116")
plt.show()
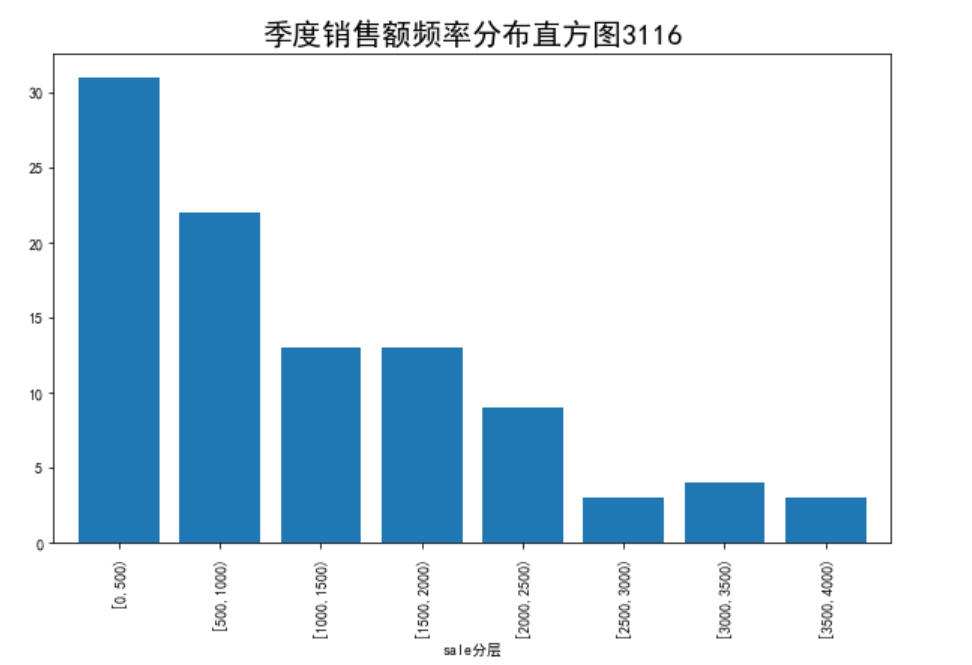
# 代码3-3 捞起生鱼片的季度销售情况
import pandas as pd
import numpy as np
catering_sale = (r'D:\数据挖掘\catering_fish_congee.xls') # 餐饮数据
data = pd.read_excel(catering_sale,names=['date','sale']) # 读取数据,指定“日期”列为索引
bins = [0,500,1000,1500,2000,2500,3000,3500,4000]
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)']
data['sale分层'] = pd.cut(data.sale, bins, labels=labels)
aggResult = data.groupby('sale分层').agg({'sale':'count'})
pAggResult = round(aggResult/aggResult.sum(), 2, ) * 100
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
pAggResult['sale'].plot(kind='bar',width=0.8,fontsize=10) # 绘制频率直方图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('季度销售额频率分布直方图3116',fontsize=20)
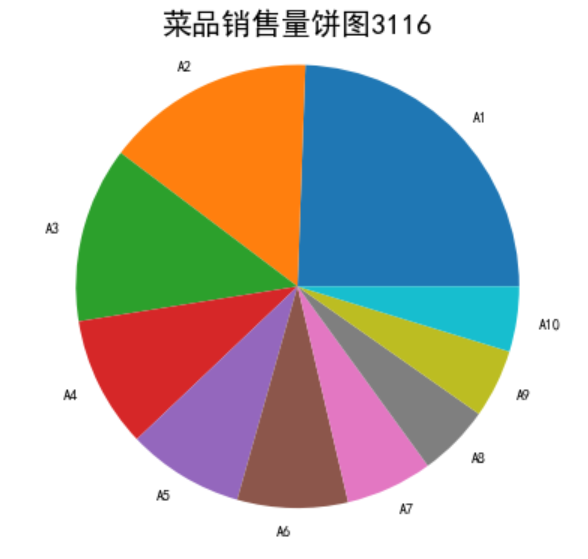
catering_dish_profit= (r'D:\数据挖掘\data\catering_dish_profit.xls')
data=pd.read_excel(catering_dish_profit)
x=data['盈利']
labels=data['菜品名']
plt.figure(figsize=(8,6))
plt.pie(x,labels=labels)
plt.rcParams['font.sans-serif']='SimHei'
plt.axis('equal')
plt.title('菜品销售量饼图3116',fontsize=20)
plt.show()
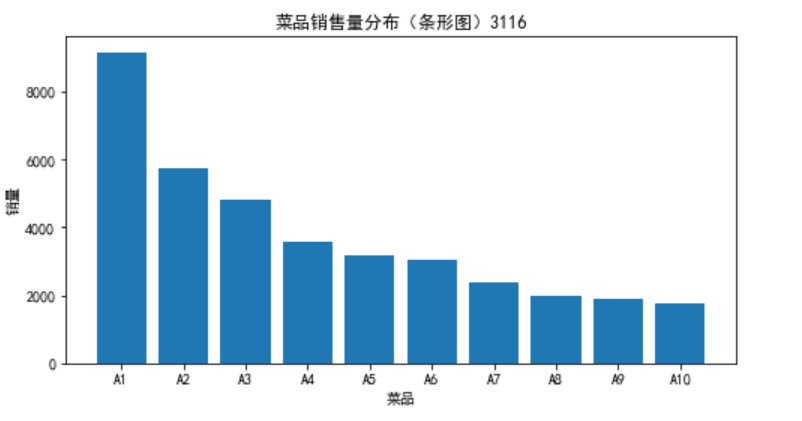
x=data['菜品名']
y=data['盈利']
plt.figure(figsize=(8,4))
plt.bar(x,y)
plt.rcParams['font.sans-serif']='SimHei'
plt.xlabel('菜品')
plt.ylabel('销量')
plt.title('菜品销售量分布(条形图)3116')
plt.show()
dish_sale= (r'D:\数据挖掘\data\dish_sale.xls')
data=pd.read_excel(dish_sale)
plt.figure(figsize=(8,4))
plt.plot(data['月份'],data['A部门'],color='green',label='A部门',marker='o')
plt.plot(data['月份'],data['B部门'],color='red',label='B部门',marker='s')
plt.plot(data['月份'],data['C部门'],color='skyblue',label='C部门',marker='x')
plt.legend()
plt.ylabel('销售额(万元)')
plt.title('部门销售额比较3116',fontsize=20)
plt.show()

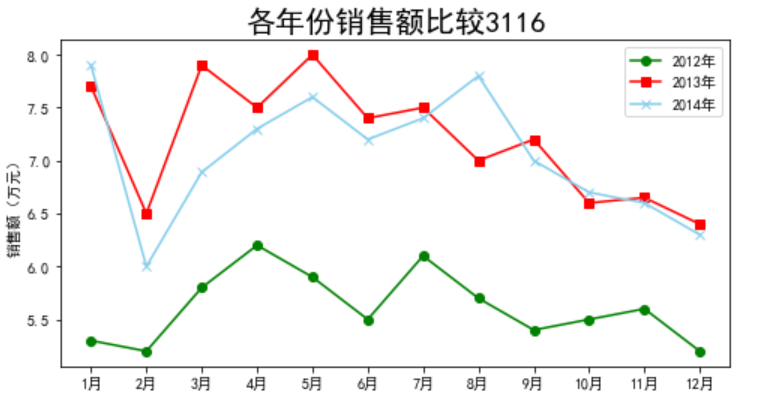
dish_sale_b= (r'D:\数据挖掘\data\dish_sale_b.xls')
data=pd.read_excel(dish_sale_b)
plt.figure(figsize=(8,4))
plt.plot(data['月份'],data['2012年'],color='green',label='2012年',marker='o')
plt.plot(data['月份'],data['2013年'],color='red',label='2013年',marker='s')
plt.plot(data['月份'],data['2014年'],color='skyblue',label='2014年',marker='x')
plt.legend()
plt.ylabel('销售额(万元)')
plt.title('各年份销售额比较3116',fontsize=20)
plt.show()
import numpy as np
x=np.linspace(0,2*np.pi,25,endpoint=True)
s=np.sin(x)
plt.figure()
plt.plot(x,s,'b-*')
plt.xlabel("x")
plt.ylabel("y")
plt.title("y=sin(x)3116")
plt.legend("sin(x)")
plt.show()

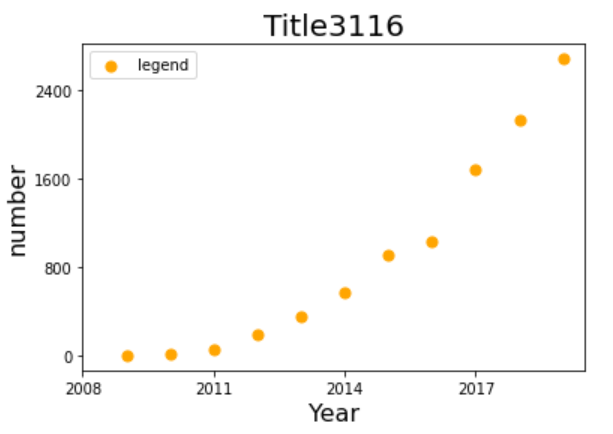
import matplotlib.pyplot as plt
years = [2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
turnovers = [0.5, 9.36, 52, 191, 350, 571, 912, 1027, 1682, 2135, 2684]
plt.figure()
plt.scatter(years, turnovers, c='orange', s=50, label='legend')
plt.xticks(range(2008, 2020, 3))
plt.yticks(range(0, 3200, 800))
plt.xlabel("Year", fontdict={'size': 16})
plt.ylabel("number", fontdict={'size': 16})
plt.title("Title3116", fontdict={'size': 20})
plt.legend(loc='best')
plt.show()
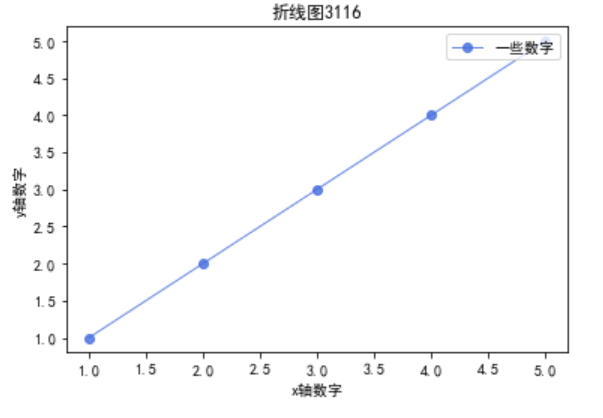
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文
x_axis_data = [1, 2, 3, 4, 5]
y_axis_data = [1, 2, 3, 4, 5]
# plot中参数的含义分别是横轴值,纵轴值,线的形状,颜色,透明度,线的宽度和标签
plt.plot(x_axis_data, y_axis_data, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='一些数字')
# 显示标签,如果不加这句,即使在plot中加了label='一些数字'的参数,最终还是不会显示标签
plt.legend(loc="upper right")
plt.xlabel('x轴数字')
plt.ylabel('y轴数字')
plt.title("折线图3116")
plt.show()
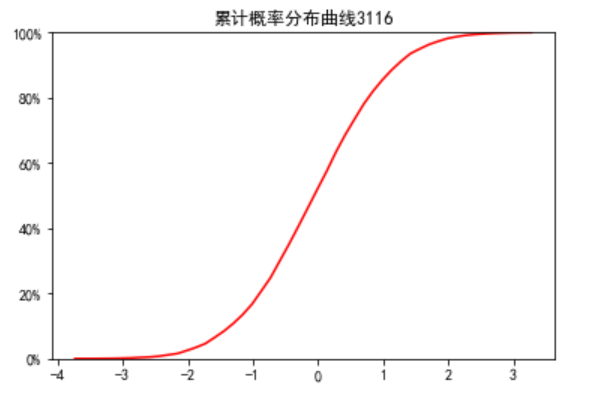
example_list=[]
n=10000
for i in range(n):
tmp=[np.random.normal()]
example_list.extend(tmp)
width=50
n, bins, patches = plt.hist(example_list,bins = width,color='blue',alpha=0.5)
plt.clf() # clear the figure
X = bins[0:width]+(bins[1]-bins[0])/2.0
bins=bins.tolist()
freq=[f/sum(n) for f in n]
acc_freq=[]
for i in range(0,len(freq)):
if i==0:
temp=freq[0]
else:
temp=sum(freq[:i+1])
acc_freq.append(temp)
plt.plot(X,acc_freq,color='r') # Cumulative probability curve
yt=plt.yticks()
yt1=yt[0].tolist()
def to_percent(temp,position=0): # convert float number to percent
return '%1.0f'%(100*temp) + '%'
ytk1=[to_percent(i) for i in yt1 ]
plt.yticks(yt1,ytk1)
plt.ylim(0,1)
plt.title("累计概率分布曲线3116")
plt.show()
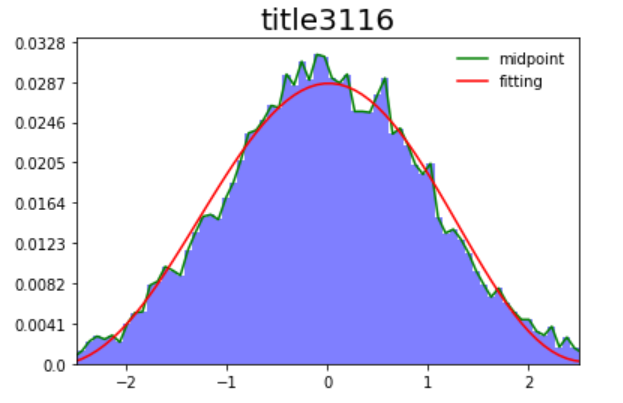
import numpy as np
example_list=[]
n=10000
for i in range(n):
tmp=[np.random.normal()]
example_list.extend(tmp)
width=100
n, bins, patches = plt.hist(example_list,bins = width,color='blue',alpha=0.5)
X = bins[0:width]+(bins[1]-bins[0])/2.0
Y = n
maxn=max(n)
maxn1=int(maxn%8+maxn+8*2)
ydata=list(range(0,maxn1+1,maxn1//8))
yfreq=[str(i/sum(n)) for i in ydata]
plt.plot(X,Y,color='green') #利用返回值来绘制区间中点连线
p1 = np.polyfit(X, Y, 7) #利用7次多项式拟合,返回拟多项式系数,按照阶数从高到低排列
Y1 = np.polyval(p1,X)
plt.plot(X,Y1,color='red')
plt.xlim(-2.5,2.5)
plt.ylim(0)
plt.yticks(ydata,yfreq) #这条语句控制纵坐标是频数或频率,打开是频率,否则是频数
plt.legend(['midpoint','fitting'],ncol=1,frameon=False)
plt.title("title3116", fontdict={'size': 20})
plt.show()
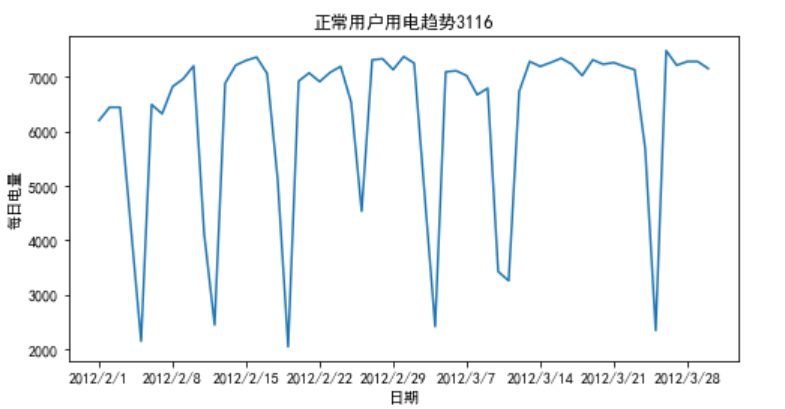
df_normal=pd.read_csv(r'D:\数据挖掘\data\user.csv')
plt.figure(figsize=(8,4))
plt.plot(df_normal["Date"],df_normal["Eletricity"])
plt.xlabel("日期")
x_major_locator=plt.MultipleLocator(7)
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.ylabel("每日电量")
plt.title("正常用户用电趋势3116")
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
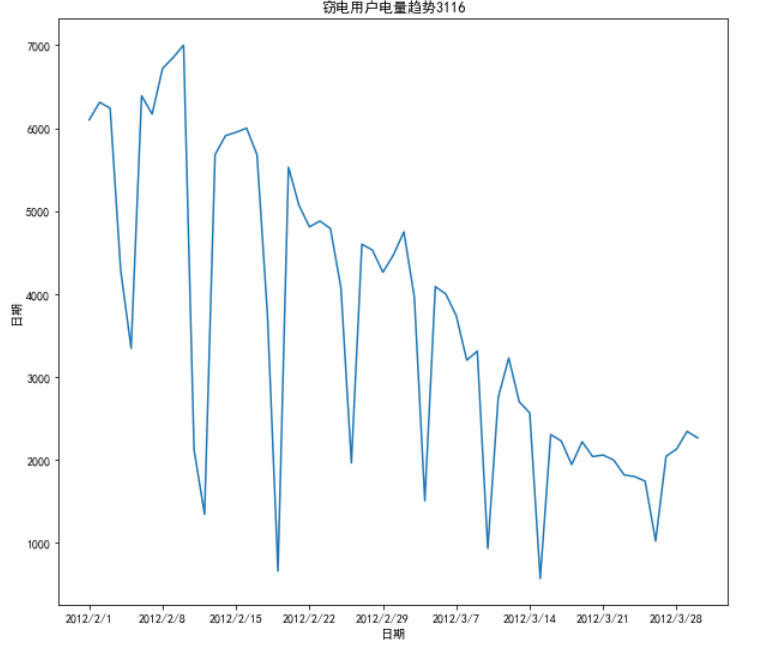
df_steal=pd.read_csv(r'D:\数据挖掘\data\Steal user.csv')
plt.figure(figsize=(10,9))
plt.plot(df_normal["Date"],df_steal["Eletricity"])
plt.xlabel("日期")
plt.ylabel("日期")
x_major_locator=plt.MultipleLocator(7)
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("窃电用户电量趋势3116")
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
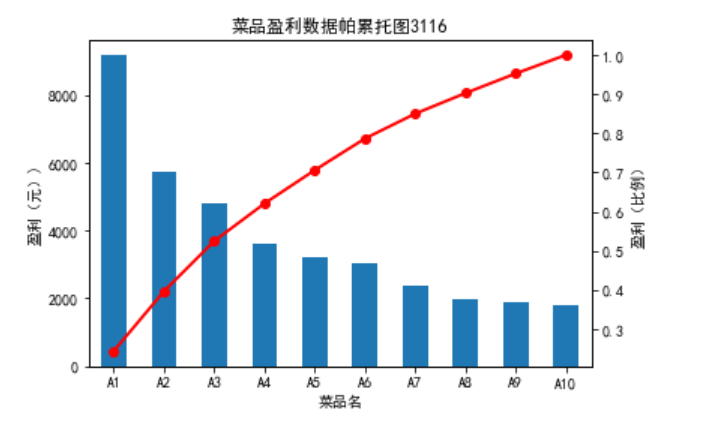
import pandas as pd
dish_profit= (r'D:\数据挖掘\data\catering_dish_profit.xls')
data=pd.read_excel(dish_profit,index_col='菜品名')
data=data['盈利'].copy()
data.sort_values(ascending=False)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure()
data.plot(kind='bar')
plt.ylabel('盈利(元))')
p=1.0*data.cumsum()/data.sum()
p.plot(color='r',secondary_y=True,style='-o',linewidth=2)
#plt.annotate(format(p[6], '.4%'), xy=(6,p[6]), xytext=(6*0.9, p[6]*0.9),arrow-props=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
plt.ylabel('盈利(比例)')
plt.title("菜品盈利数据帕累托图3116")
plt.show
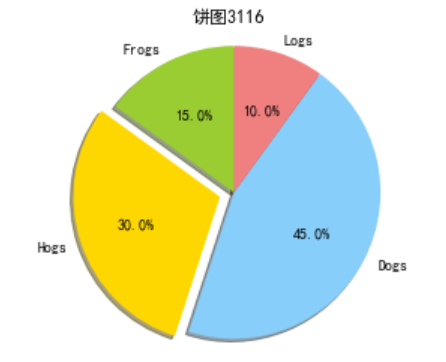
labels='Frogs','Hogs','Dogs','Logs'
sizes=[15,30,45,10]
colors=['yellowgreen','gold','lightskyblue','lightcoral']
explode=(0,0.1,0,0)
plt.pie(sizes,explode=explode,labels=labels,colors=colors,autopct='%1.1f%%',shadow=True,startangle=90)
plt.axis('equal')
plt.title("饼图3116")
plt.show()
import matplotlib.pyplot as plt
import numpy as np
x=np.random.randn(1000)
plt.hist(x,10)
plt.title("条形直方图3116")
plt.show()
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
x=np.random.randn(1000)
D=pd.DataFrame([x,x+1]).T
D.plot(kind='box')
plt.title("箱型图3116")
plt.show()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import numpy as np
import pandas as pd
x=pd.Series(np.exp(np.arange(20)))
plt.figure(figsize=(8,9))
ax1=plt.subplot(2,1,1)
x.plot(label='原始数据图',legend=True)
plt.title("title3116")
ax1=plt.subplot(2,1,2)
x.plot(logy=True,label='对数数据图',legend=True)
plt.title("title3116")
plt.show()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import numpy as np
import pandas as pd
error=np.random.randn(10)
y=pd.Series(np.sin(np.arange(10)))
y.plot(yerr=error)
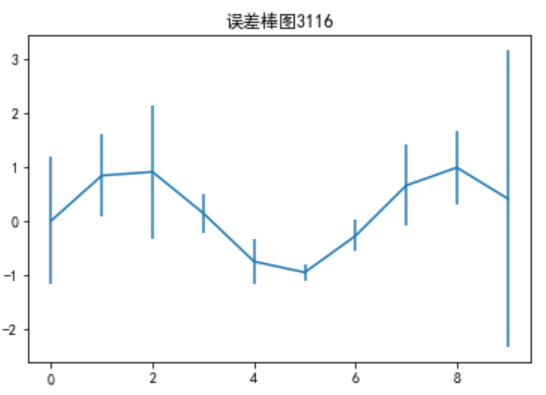
plt.title("误差棒图3116")
plt.show()
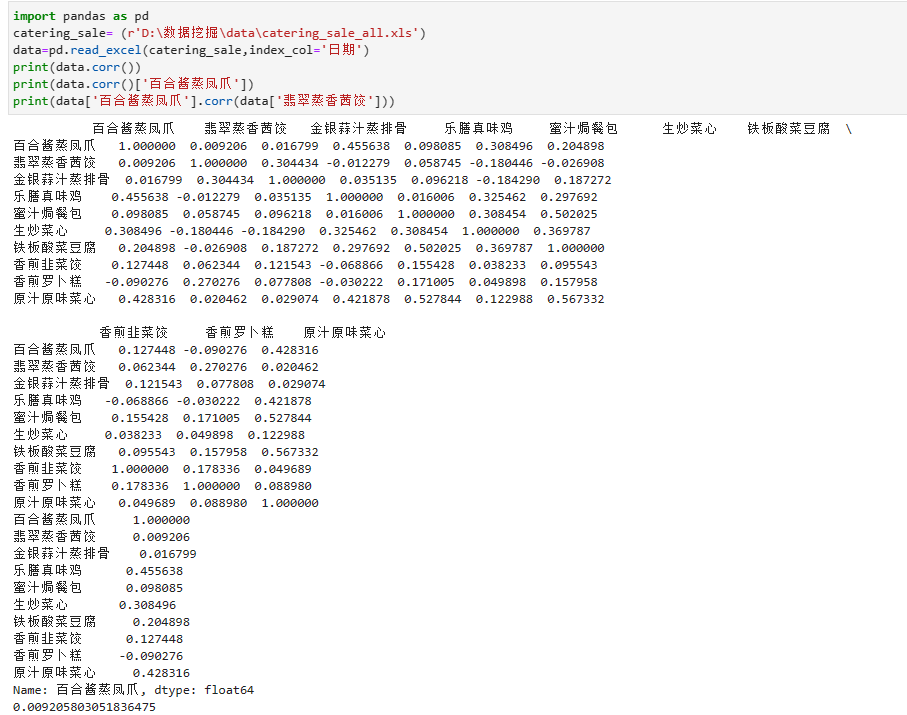
餐饮销售量相关性分析:
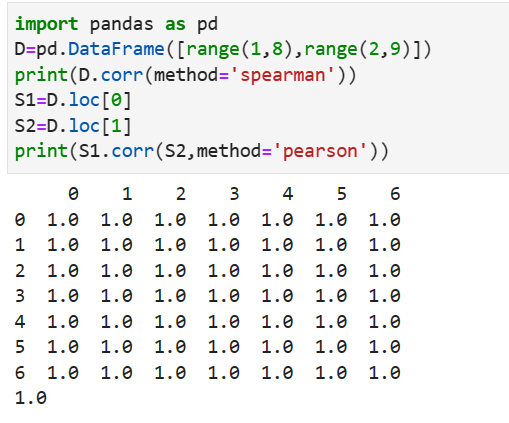
计算两个列向量的相关系数:
计算6×5随机矩阵的协方差:

计算6×5随机矩阵的偏度(三阶矩)/峰度(四阶矩)

6×5随机矩阵的基本统计量:

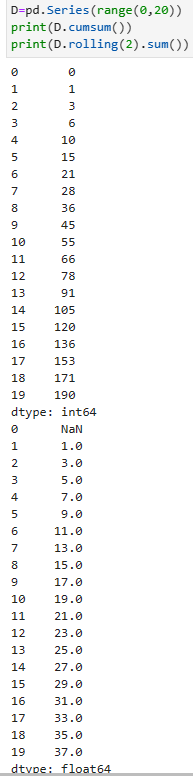
pandas累计计算统计特征函数、滚动计算统计特征函数:
总结:
第三章主要学习了利用python的各种函数对数据进行可视化以及对数据间的关系进行分析,可以作为将来要进行数据分析的一个基础。

