tensorflow读书笔记
Tensorflow简介
TensorFlow是采用数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流流图,然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算. 节点(Nodes)在图中表示数学操作,图中的边(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor).训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来.
张量(Tensor):张量有多种. 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如 [1],一阶张量为 向量 (vector), 比如 一维的 [1, 2, 3],二阶张量为 矩阵 (matrix), 比如 二维的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]],以此类推, 还有 三阶 三维的 …
神经网络实现数据分类:
准备数据
数据集读入
数据集乱序
生产训练集和测试集
配成(输入特征,标签)对,每次读入一小撮(batch)
搭建网络
定义神经网络中所有可训练参数
参数优化
嵌套循环迭代,with结构更新参数,显示当前loss
测试效果
计算当前参数前向传播后的准确率,显示当前acc
acc/loss可视化
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
fashion_mnist=keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels)=fashion_mnist.load_data()
class_names=['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle boot']
train_labels
train_images.shape
len(train_labels)
test_images.shape
len(test_labels)
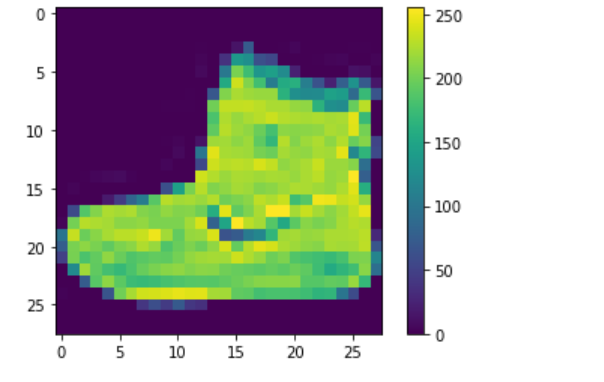
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
train_images=train_images/255.0
test_images=test_images/255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i],cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
model=keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(128,activation='relu'),
keras.layers.Dense(10)])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_images,train_labels,epochs=10)
test_loss,test_acc=model.evaluate(test_images,test_labels,verbose=2)
print('\nTest accuracy:',test_acc)
probability_model=tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions=probability_model.predict(test_images)
predictions[0]
np.argmax(predictions[0])
test_labels[0]
def plot_image(i,predictions_array,true_label,img):
predictions_array, true_label, img=predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
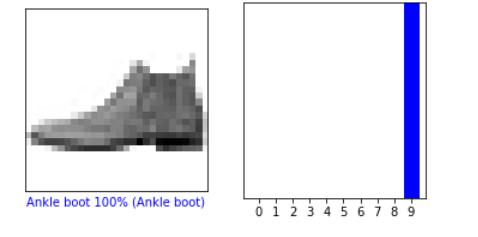
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i,predictions[i],test_labels)
plt.show()
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
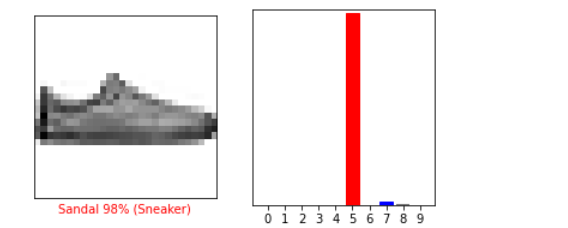
for i in range(num_images):
plt.subplot(num_rows,2*num_cols,2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
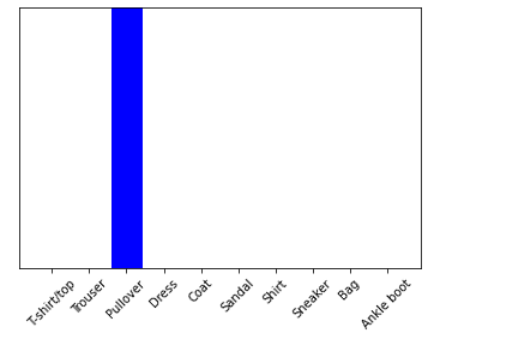
#测试部分
img=test_images[1]
print(img.shape)
img=(np.expand_dims(img,0))
print(img.shape)
predictions_single=probability_model.predict(img)
print(predictions_single)
plot_value_array(1,predictions_single[0],test_labels)
_ =plt.xticks(range(10),class_names,rotation=45)
np.argmax(predictions_single[0])

课后习题:
(1)全连接:层间神经元完全连接,每个输出神经元可以获取到所有神经元的信息,有利于信息汇总,常置于网络末尾;连接与连接之间独立参数,大量的连接大大增加模型的参数规模。局部连接:层间神经只有局部范围内的连接,在这个范围内采用全连接的方式,超过这个范围的神经元则没有连接;连接与连接之间独立参数,相比于去全连接减少了感受域外的连接,有效减少参数规模。
(2)卷积运算原理,最基本的就是单通道对应一个输出通道,那就用一个二维矩阵对输入图像进行运算,提取图像特征。但是单通道输入得到多通道(k个通道)输出,就需要k个滤波器,每个滤波器是就是一个二维的33矩阵,也就是每个滤波器包含一个卷积核。但是当输入是多通道(t)得到多通道(k个通道)输出,那这次卷积就包括k个滤波器,每个滤波器就是一个3维矩阵,33t,每个滤波器就包含t个卷积核。上面输出通道是k,那就得到了k个特征图,每个输出通道就是一个特征图。
(3)池化的目的:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。
激活函数的作用:如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
(4)1.归一化有助于快速收敛; 2.对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)梯度下降,依照所给数据,判断函数,随机给一个初值w,之后通过不断更改,一步步接近原函数的方法。更改的过程也就是根据梯度不断修改w的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号