【简读】3DConvCaps: 3DUnet with Convolutional Capsule Encoder for Medical Image Segmentation
简读
还是源于Unet的,将Unet的模块替换成了胶囊网络,替换源于CNN中存在以下原因:
(1)CNN中的池化会丢失一部分空间信息(个人觉得这个是见仁见智的,如果不通过池化,特征提取就可能满足不了平移不变性了)
(2)CNN对旋转和仿射变换敏感(CNN的卷积有良好的平移不变性,若发生旋转特征识别就可能失效了,因此对齐是很重要的)
胶囊网络的优势:
(1)胶囊网络与卷积神经网络的最大不同在于输出类型。前者为一组向量,向量中可以包含对目标的各种维度描述(见图1),如检测鸟时可分为:体型大小、羽毛颜色、鸟喙长度等等;而后者仅为对应特征值,该值即代表该鸟类。
(2)由于胶囊网络的向量形式,当目标发生旋转或放射变换时,向量仅需改变长度或角度即可适应这种变换。而卷积神经网络则没有这种特性
(3)需求更少的训练数据但训练较为缓慢
(4)非常适用于处理密集/拥挤的场景但较难识别靠得近且类型相同的目标(如检测人眼睛和鼻子非常轻松,但检测左眼和右眼则不容易)
于是,有人结合两者,在图像分割领域搞了一个3DUnet。
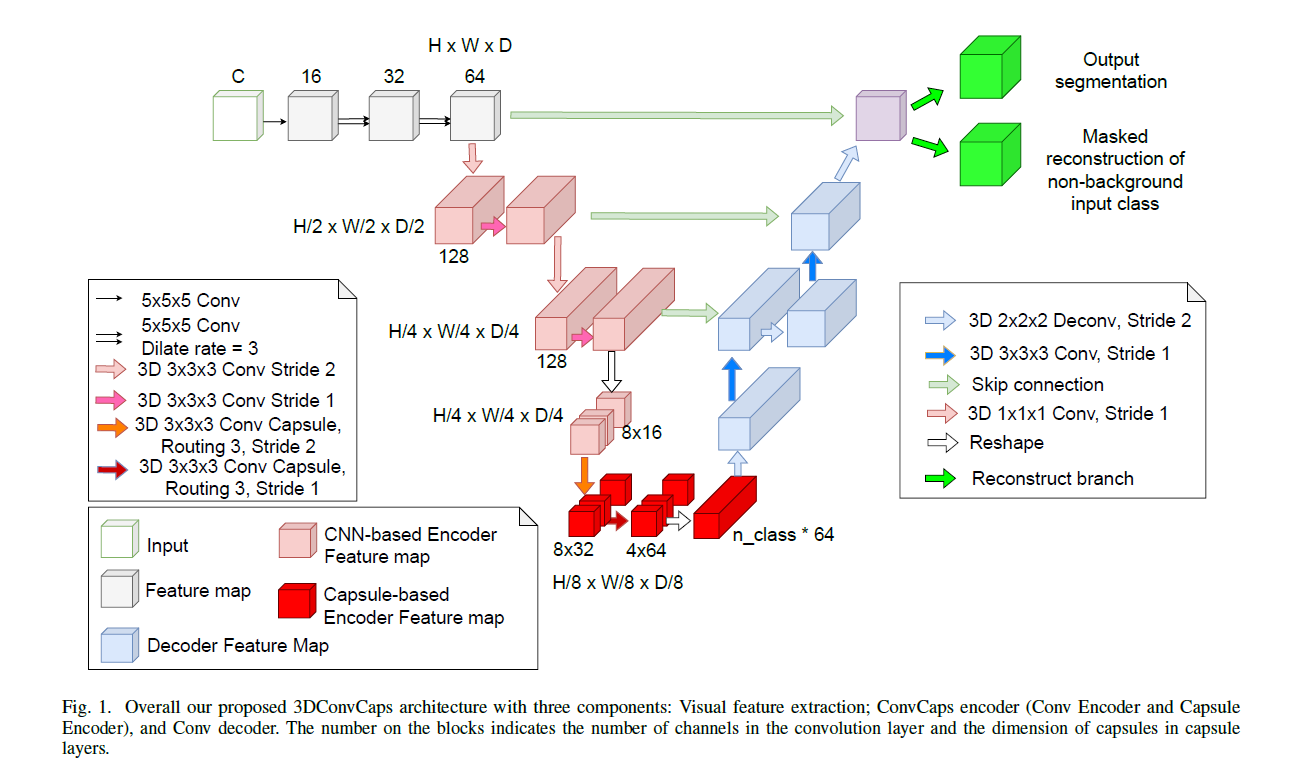
下图为结果,可见本文方法即使略逊色于纯卷积的3D-Unet,也远优于过往含胶囊网络的SOTA模型。

Reference
https://mp.weixin.qq.com/s/uV2RqIpQeqCzVsg4GP9pIw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号