【ACM MM 2021】论文阅读:Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
论文地址:https://arxiv.org/abs/2107.13994
Github:https://github.com/paTRICK-swk/Pose3D-RIE
单位:北大、上交、中科院
摘要
现有的大多数三维人体姿势估计方法主要侧重于预测根关节和其他人体关节之间的三维位置关系(局部运动),而不是人体的整体轨迹(全局运动)。尽管这些方法取得了巨大的进步,但它们对全局运动的鲁棒性不强,并且缺乏在较小运动范围内准确预测局部运动的能力。为了缓解这两个问题,我们提出了一种相对信息编码方法,可以产生位置和时间增强表示。首先,我们利用二维姿态的相对坐标对位置信息进行编码,以增强输入和输出分布之间的一致性。具有不同绝对2D位置的相同姿势可以映射到一个公共表示。这有利于避免全局运动对预测结果的干扰。其次,我们通过建立同一个人在一段时间内的当前姿势和其他姿势之间的联系来编码时间信息。将更多地关注当前姿势前后的运动变化,从而在较小的运动范围内获得更好的局部运动预测性能。消融研究验证了所提出的相对信息编码方法的有效性。此外,我们在整个框架中引入了一种多阶段优化方法,以进一步利用位置和时间增强表示。在两个公共数据集上,我们的方法优于最先进的方法。
1&2 INTRODUCTION & RELATED WORKS
3 METHOD
下图为模型框架图,以序列二位姿态的帧作为模型输入,首先对二维姿态进行位置编码,得到当前帧的3D姿势作为输出,再通过几个局部特征编码器提取局部特征,同时对二维姿态序列进行全局特征提取,之后将全局特征与局部特征进行特征融合,以进一步得到最终的三维姿态。
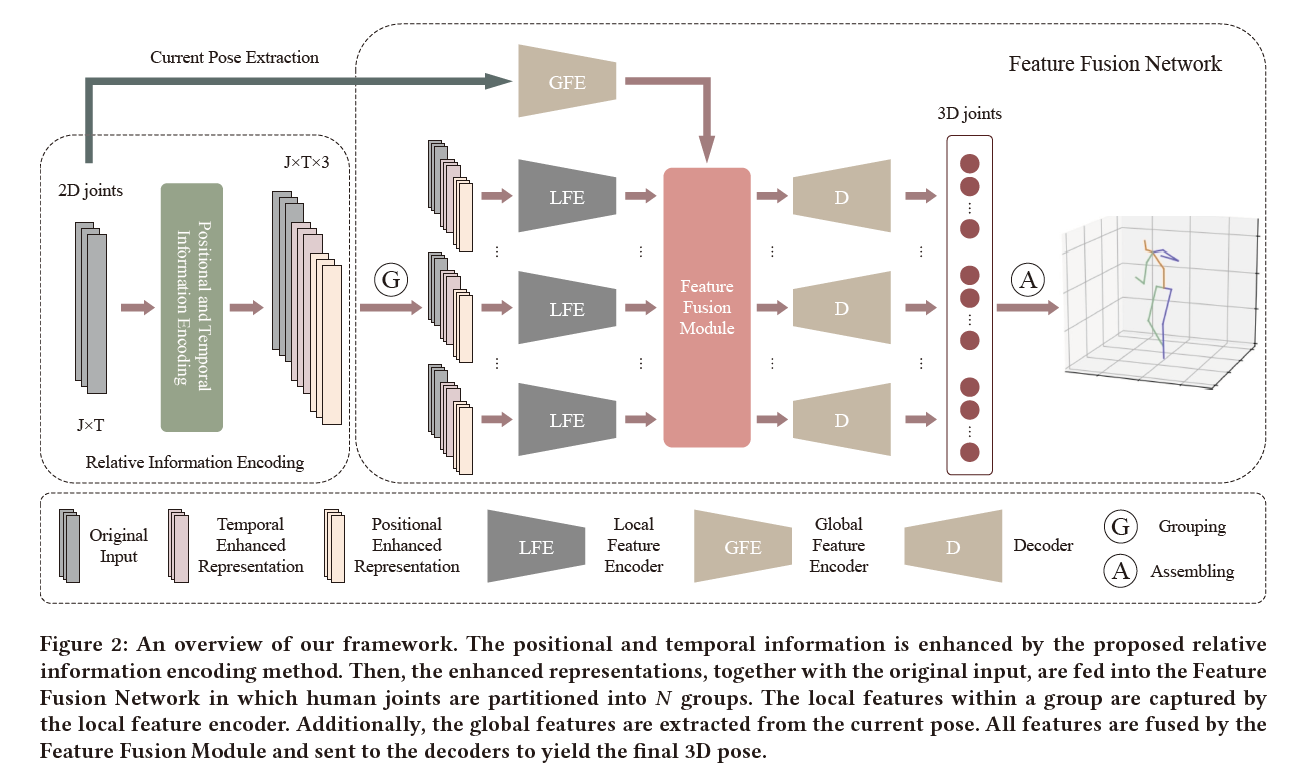
3.1 Baseline
为了将相关信息编码融入到三维人体姿态估计中,我们针对人体的生理结构提出了一种特征融合网络作为基线。对于每个姿势,我们采用[30]中使用的分组策略。
作者将图像空间中的二维矢量化姿势序列表示为K,对应的三维姿态为P,具体符号如下图,J为关节点数量,T为帧长:

对于每个姿势,作者将人类关节都分为5组,分别为躯干、左臂、右臂、左腿和右腿,每组的表达形似为:

局部特征编码器使用TCN作为主干,从分组的2D关键点提取局部特征。这个过程可以表示为:
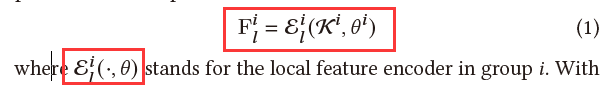
为了使框架不受其他框架干扰,保持人体关节的全局一致性,从当前姿态中提取全局特征Kc

几个符号要与局部特征编码器区分开,懒人法则直接使用截图。
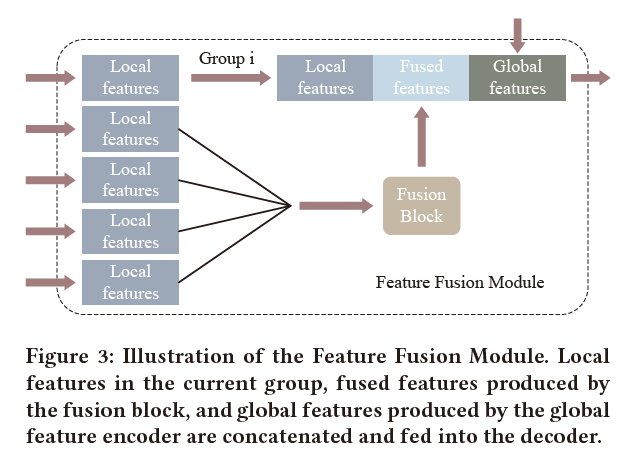
虽然每组中都保留了空间联系,但不同组之间的联系被阻隔。在推断3D姿势时,当前组完全不知道其他组的关节位置,这不利于保持整体身体姿势的一致性。理想情况下,这些网络应该考虑到群体之间关节的连续性。这促使我们提出一个特征融合模块(FFM),将其他组的信息传输到当前组。该模块与所提出的多阶段优化方法相结合,可以有效地工作。通过融合块获得融合特征:
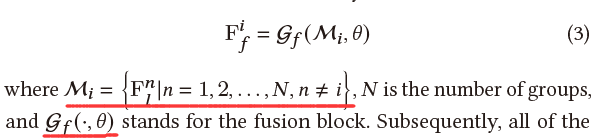
特征融合模块对应的结构图为:
将所有特征串联起来并发送到解码器,以估计3D姿势:

3.2 Positional Information Encoding
为了产生对全局运动不太敏感的3D姿势,我们提出了一种位置信息编码方法。以前的大多数方法都是估计相对于根关节的三维关节位置。它们消除了3D全局轨迹,从而限制网络专注于估计人体姿势。然而,它们都没有考虑输入和输出形式的一致性。在某个时间𝑡 , 之前网络的目标可以表述为一个函数:
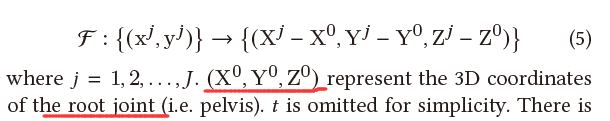
输入和输出的分布存在不一致性,这将降低对全局运动的鲁棒性。例如,当手持式相机拍摄具有相同姿势的人时,相机容易移动。在移动之前和之后,相机拍摄的视频中,人的整体2D位置不同,而相应关节的相对2D位置保持不变。在这种情况下,2D坐标的整体移动可视为全局运动,因此方程(5)可以重新表述为:
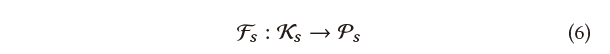
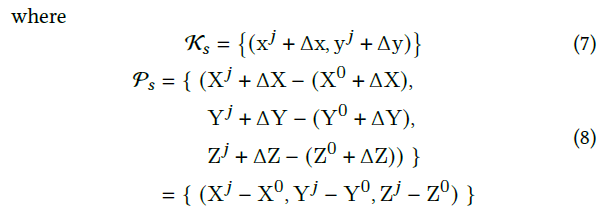
全局运动会影响输入,但输出仍然相同。除了推断人体的3D姿势外,该网络还应该学习从多个输入到同一输出的映射函数。也就是说,网络需要完成从图像空间中的绝对二维坐标到三维空间中的相对坐标的转换。当网络无法学习这种映射关系时,在移动前后由相机拍摄的相同姿势的人将对应不同的3D姿势估计结果,这是不可取的。
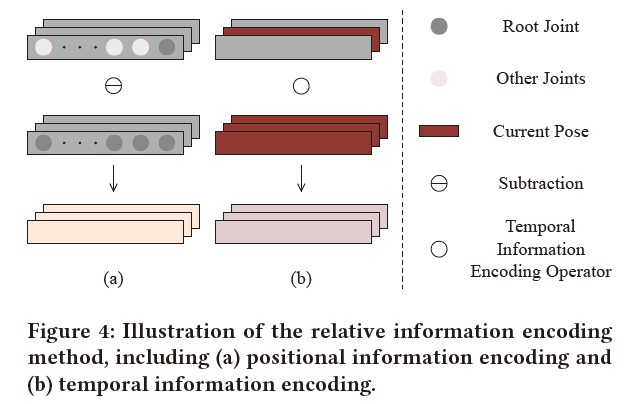
为了解决这个问题,我们通过从所有其他关节的位置中减去根关节的坐标,在输入端对位置信息进行编码。如图4(a)所示,位置信息编码可以表示为:
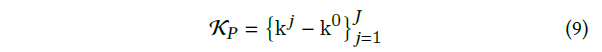
网络的目标可以改写为:
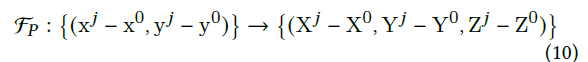
其中(x0,y0)表示根关节的2D坐标。当全局运动发生时,方程(10)可以重新表述为:
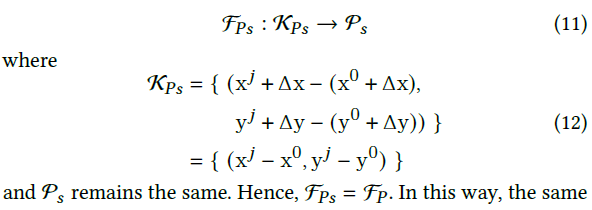
位置信息编码迫使网络仅捕获与人体姿势相关的有意义信息,而不是二维全局轨迹。这有助于网络对全局运动变得更加健壮。此外,二维全局轨迹不可丢弃,因为它有利于三维姿态推断。
3.3 Temporal Information Encoding
除了增强位置信息外,我们还提出了一种时间信息编码方法,以缓解运动范围小的局部运动性能差的问题。以前的方法使用时间卷积网络(TCN),该网络将一系列2D姿势作为输入,并生成单个3D姿势。Fig 5显示了TCN的两个缺点:1)虽然将短时间内的多个2D姿势输入TCN,但只估计序列中间的一个姿势。所有其他姿势在保持当前姿势在时域中的连续性方面起辅助作用。因此,它们不如当前姿势重要。TCN平等对待所有姿势,不知道哪个姿势需要提升到3D空间。没有明确强调当前姿势和其他姿势之间的相对位置关系。2) 根据卷积运算的性质,神经网络的浅层具有较小的感受野,仅在局部区域聚集信息,而深层具有较大的感受野。这表明,在达到更深层次之前,远离当前姿势的姿势无法获得与当前姿势相关的任何信息。这两个缺点将导致网络对当前姿势周围发生的变化没有给予足够的关注。当姿势的运动范围相对较小时,这些变化很难被网络捕获,从而导致对小动作的预测性能较差。
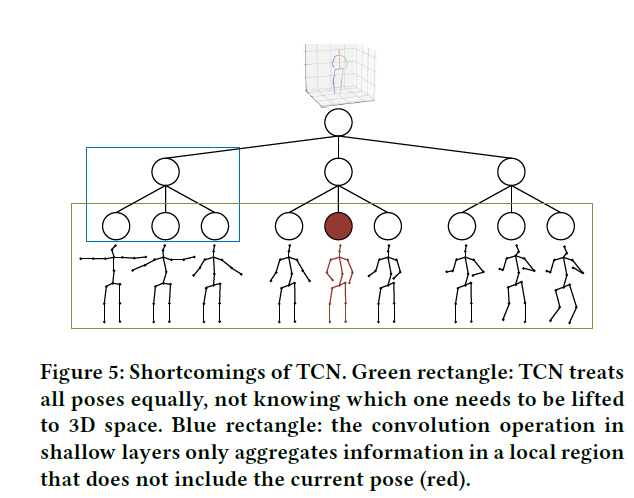
由于我们使用TCN作为局部特征编码器的主干,我们提出了一种时态信息编码方法来克服这些缺点。我们通过时间增强的表示来模拟当前姿势和其他姿势之间的关系。该方法驱动网络学习当前姿势对其他姿势的影响。它允许所有姿势从网络的浅层开始关注与当前姿势的时间相关性,无论它们在时域上距离当前姿势很远还是很近。换句话说,网络关注当前姿势周围的位置变化,而不是每个姿势的绝对位置。当运动范围较小的局部运动发生时,这些变化将被放大,这有助于对三维姿势进行细粒度建模。如Fig 4(b)所示,时间信息编码可以如下表示:
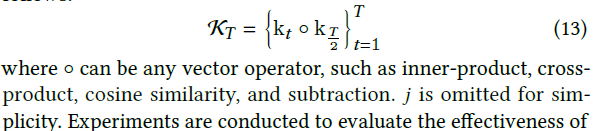
作为特征融合网络的附加输入。因此,式(1)可以重新表述为:
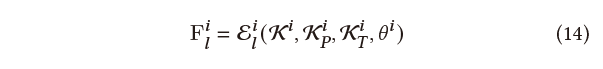
3.4 Multi-Stage Optimization
我们提出了一种多阶段优化方法,以充分利用每个组中的位置和时间信息。信息交换应该在保持编码过程独立性的前提下,有选择地、全面地在组之间进行。在[43]中,捕获每个组的内部共性以及在组之间交换有用信息的过程被混合在一起。这将导致每个组中的特征受到其他组的干扰。因此,我们分离了特征融合网络中的前两个过程,并将所提出的多阶段优化方法应用到我们的框架中。通过这种方法,我们保留了局部特征编码和特征融合的独立性,从而阐明了这两个过程的作用。
特征融合网络可以分为三个部分:编码器、解码器和FFM。在优化的第一阶段,我们暂时删除FFM,以便局部特征编码器能够独立地提取相关关节的区域特征。同时,全局特征编码器解释了人体的整体一致性。局部和全局功能被连接并发送到解码器,从而确保端到端培训框架的完整性。局部和全局特征编码器的参数将保留在优化的第二阶段。在第二阶段,只有FFM和解码器参与优化。编码器的参数被加载并固定,而第一阶段的解码器的参数被丢弃。在这一阶段对解码器进行再培训。通过这种方式,在不干扰编码器优化过程的情况下,FFM充分理解了组间依赖关系。在第三阶段,对整个框架进行了微调,以使编码器与解码器和FFM更有效地协同工作。借助于所提出的多阶段优化方法,可以在每个组中独立地提取位置和时间表示中的姿势相关信息,并且组之间形成正交互,以便于进行三维人体姿势估计。
4. EXPERIMENTS
4.1 Datasets and Evaluation Protocols
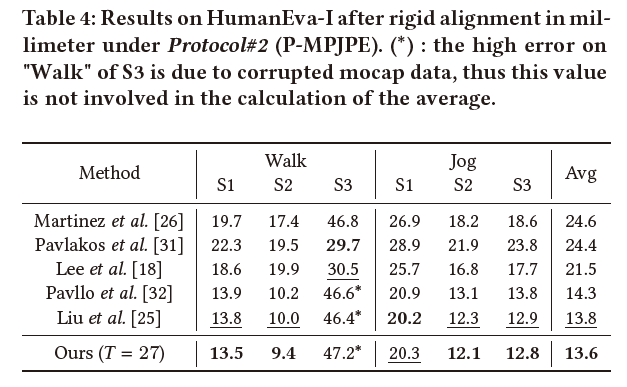
常规的几组实验结果:
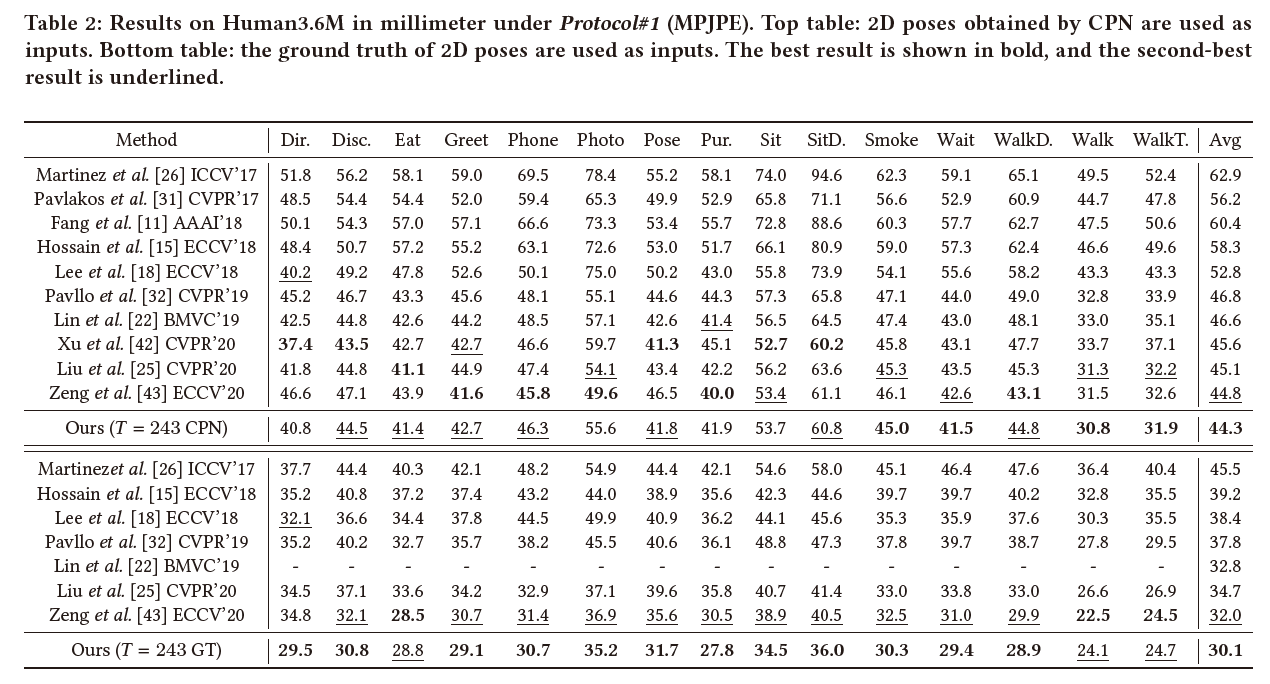
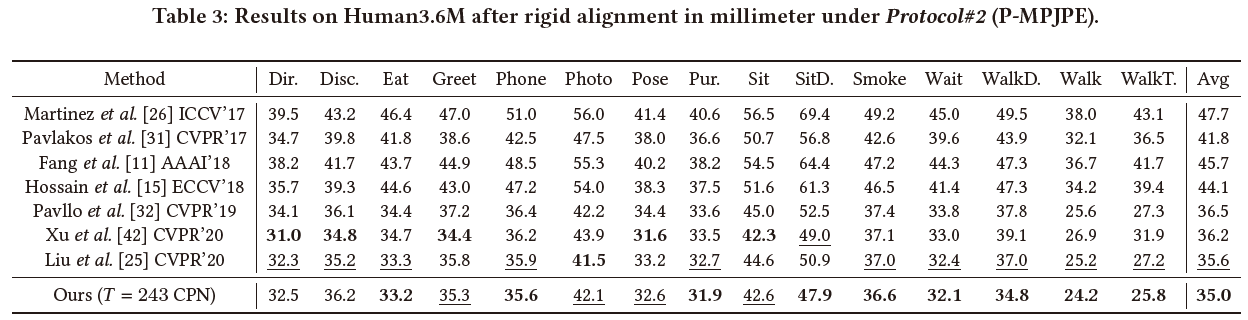
4.2 Ablation Studies
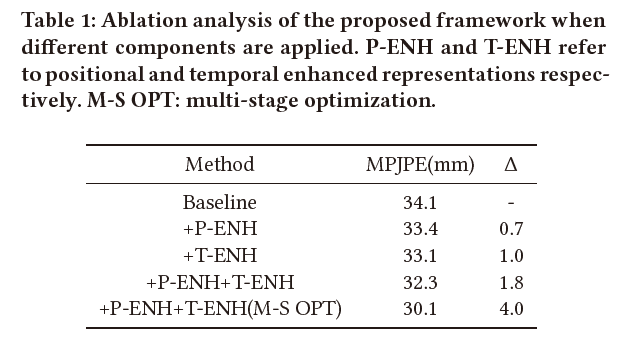
消融实验是最重要的,直接决定了你的模型提出是否有效:
5 CONCLUSION
在本文中,我们介绍了一种相对信息编码方法,该方法提供了所有人类关节内位置关系以及序列中姿势之间的时间关系的显式和强先验。该方法有助于在较小运动范围内对局部运动进行合理的三维姿态估计,并对全局运动产生更鲁棒的结果。此外,针对整个框架提出了一种多阶段优化方法。实验表明,我们的方法在Human3.6M和HumanEva-I数据集上的性能优于最先进的方法。

