【CVPR 2022】论文阅读:PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision
论文地址:https://arxiv.org/pdf/2203.15625.pdf
Github:https://github.com/Garfield-kh/PoseTriplet
单位:新加坡国立大学、南洋理工大学、华为
2022CVPR Oral Presentation
摘要
现有的自监督三维人体姿势估计方法在很大程度上依赖于一致性损失等弱监督来指导学习,这不可避免地导致在真实场景中,不可见姿势的结果较差。在本文中,作者提出了一种新的自监督方法,该方法允许通过self-enhancing dual-loop学习框架显式生成2D-3D姿势对以增强监督。这可以通过引入基于强化学习的imitator来实现,该imitator与pose estimator和pose hallucinator一起学习,这三个组件在训练过程中形成两个循环,相互补充和加强。具体来说,姿态估计器(pose estimator)将输入的2D姿势序列转换为低分辨率的3D输出,然后由实施物理约束的imitator进行优化增强。经过优化的3D姿势随后被输入到pose hallucinator,以产生更加多样化的数据,而这些数据又被imitator强化,并进一步用于训练姿势估计器。在实践中,这种协同进化方案能够在不依赖任何给定3D数据的情况下,根据自生成的运动数据训练姿势估计器。在各种基准的广泛实验表明,作者的方法产生的结果显著优于现有技术,并且在某些情况下,甚至与完全监督方法的结果一致。
1&2 Introduction&Related works
主要讲之前的方法都是有监督的,需要标签的训练,当然也有采用半监督和弱监督的训练方式,来解决3D标签不足的问题。在本文中,作者提出一种新的自监督方法,作者的方法属于单视图环境下的自监督方法。与以往通过一致性或对抗实现弱监督信号的自监督方法不同,该方法直接使用自生成数据中的强监督信号,从而获得更准确、更稳定的模型性能。半监督类别下的伪标签策略与该方法非常接近。但是,作者的方法不需要真实标签数据进行模型预训练,引入了物理合理性改进和多样性增强,以实现更好的性能。
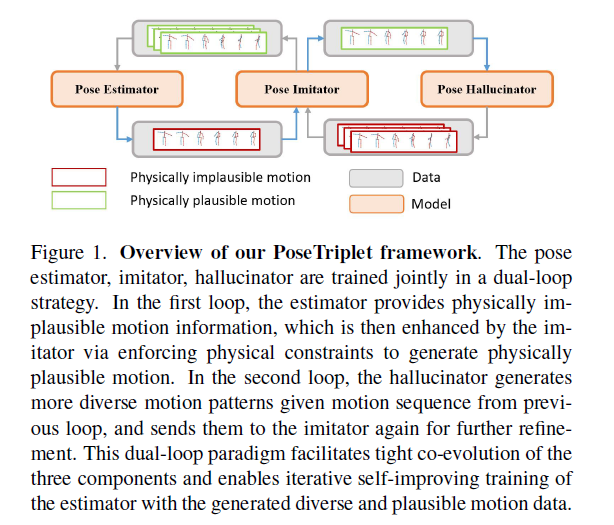
主要贡献:
通过pose estimator、imitator和hallucinator的共同进化,实现了一种用于自监督3D姿势估计的新方案。这三个组件相互补充,相互受益,共同形成了一个独立的系统,可以实现逼真的3D姿势序列,并进一步实现2D-3D增强监控。通过仅采用2D姿势作为输入,PosetReplet在各种基准测试中提供了真正令人鼓舞的结果,在很大程度上超过了最先进的水平,甚至接近完全监督的结果。
3. Methodology
注:含有上下标的符号有点多,注意区分。
给定一段2D pose sequence x1:T=(x1,…,xT)作为输入,帧长为T,x为每个2D节点的坐标,目标为3D pose sequence X1:T=(X1,…,XT),X为对应三维关键点的坐标。
通常,姿势估计器P通过完全监督学习方法,使用大量成对的2D和3D姿势数据进行训练,可表示为:
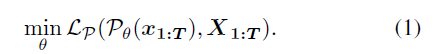
其中Lp表示损失函数,通常被定义为预测和真实3D姿态序列之间的均方误差(MSE)。然而,真实3D姿势数据的捕获成本很高,这限制了这些方法的适用性。为了避免使用3D数据,以前的自监督方法通常采用弱2D再投影损失来学习三维估计器:
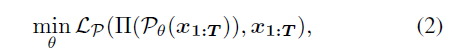
Ⅱ表示透视投影函数。再投影损失只提供了微弱的监督,这往往会导致不稳定或不自然的估计。在这项工作中,作者的目标是设计一个自我监督学习框架,其核心是一个迭代的自我改进范式,作者建议使用一些专门设计的变换T来增强当前估计(例如,产生更平滑和多样的运动):
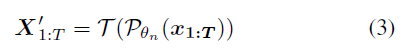
然后将增强的估计投影到二维姿势,以获得成对的训练数据{x′1:T,X′1:T},用于改进姿势估计器:(X'是增强后的3D,x'是增强的3D投影得到的2D,Pθ(x'1:T)为输入增强后的2D得到的3D估计)

这里θn和θn+1表示当前估计器和改进估计器的参数。然后,可以利用改进的估计器开始数据增强和训练的新迭代。基于这种自我改进的范例,可以从一组二维姿势序列{x1:T}开始训练一个效果良好的姿势估计器。
3.1. PoseTriplet
为了构建一个有效的自我改进框架,作者确定了增强三维运动序列的两个挑战性方面:1)由于忽略力、质量和接触建模,估计器的姿势估计在物理上可能不合理;2) 现有的二维运动可能在多样性方面受到限制,因此学习的模型不能很好地推广。为了应对这些挑战,作者引入了一种基于强化学习辅助人体运动建模的姿势仿真器(pose imitator)和一种基于生成运动插值的姿势幻觉器(pose hallucinator),从而对三维运动进行细化和多样化。前者帮助纠正物理上不自然/反常的部分(physical artifacts),而后者生成新的基于已存在姿势的姿势序列。作者发现运动中的这两个方面是互补的,因此将它们结合在一起。生成的管道有助于获取3D运动数据{x'1:T,X′1:T},具有显著改善的物理合理性和运动多样性。然而,这两种方法的简单两步组合会生成质量较差的3D姿势序列,原因是,由于估计不可信,首先执行运动多样化可能无效,而随后执行运动多样化可能会引入物理伪影。因此,作者进一步引入了一个双环方案,并将这两个分量与姿态估计器统一到一个新的自监督框架PoseTriplet中。
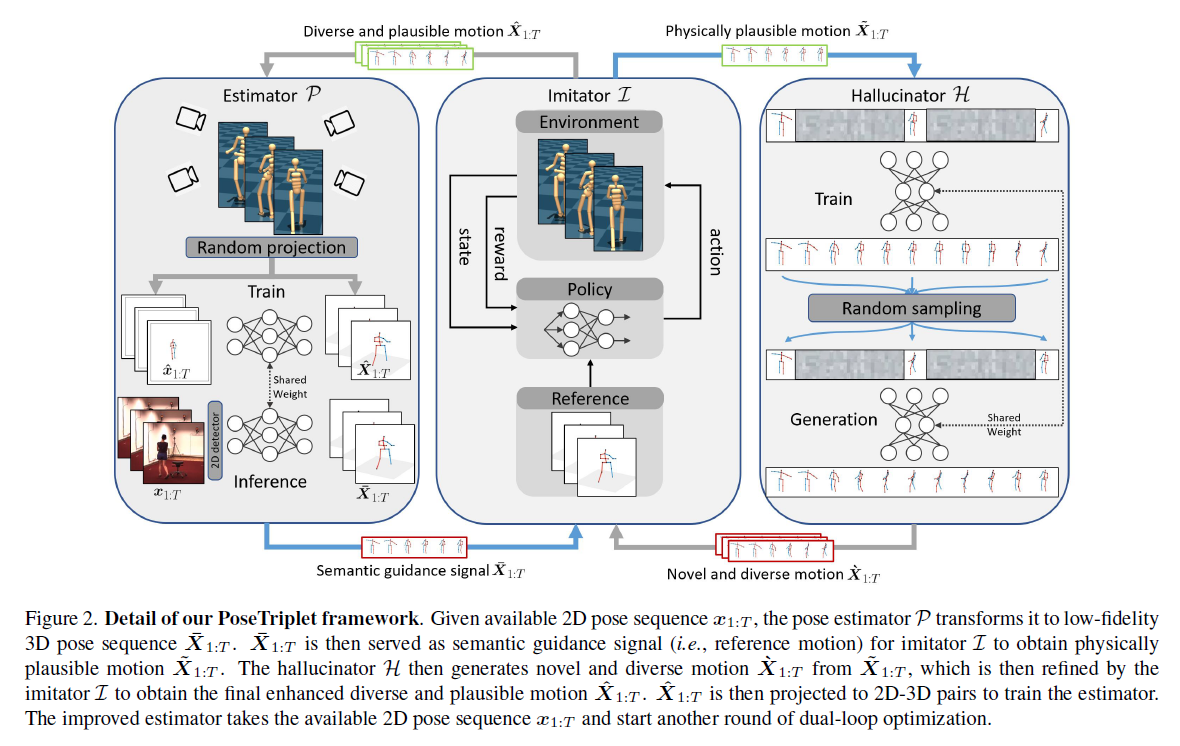
Dual-loop architecture 如Figure2所示,这个双环结构包含三个模块:a pose estimator P, a pose imitatorI, 以及 a pose hallucinator H。给定一段2D pose sequence x1:T=(x1,…,xT)作为输入,pose estimator首先将其转换为低分辨率的3D pose sequence:
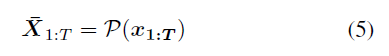
{X-1:T}为被转换为低分辨率的相应动作,并作为语义引导信号发送给pose imitator,后者实施物理人体运动动力学建模,并获得物理上合理的运动序列:

通过学习生成动作完全模型,然后pose hallucinator生成新颖且多样的运动序列{`X 1:T}基于imitator改进的动作:
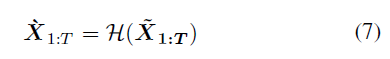
之后,不是将{`x1:T}作为estimator的增强数据来关闭循环,而是引入另一个循环。将{`x1:T}反馈给imitator,以纠正诱发的物理伪影,并获得最终预期的合理且多样的运动序列:

然后将{ˆX1:T}投影到2D以获得配对数据{ˆx1:T,ˆX1:T}用于训练姿势估计器。
通过联合优化这种双环结构,三个组成部分形成了一个紧密的协同进化范式:1)estimator受益于多样且合理的增强数据,以学习更准确的估计。2) imitator根据改进的估计和hallucinator生成的各种数据学习更健壮、更自然的运动。3) hallucinator根据来自imitator的改进数据生成质量更高的各种姿势序列。
Loop starting 这种自我提升学习范式的另一个挑战是循环启动,不能获取3D运动数据时,整个框架无法开始学习。回想一下,pose imitator采用基于物理的人体运动模型,因此作者开发了一种零数据生成策略,生成初始3D姿势序列,用于启动双循环学习。具体来说,在水平面上以随机方向和适当速度生成根轨迹信号。然后,该轨迹被用作RL代理的制导信号。通过控制代理跟随生成的轨迹,可以生成物理上合理的运动序列。然后将这些运动序列投影以获得2D-3D姿势对,并用于训练初始pose estimator。这样,整个双环学习就可以开始了。
3.2. Module detail
3.2.1 Pose estimator
pose estimator根据输入2D序列x1:T估计3D姿势序列X1:T。具体来说,作者采用了与VideoPose类似的估计器架构,它可以预测根轨迹和根相对关节位置。该轨迹可作为pose imitator的附加运动信号。同时,pose estimator可以校正根运动中的噪声。我们使用均方误差(MSE)损失进行与根相关的姿势估计,并使用加权L1损失进行以下轨迹估计[38]。
Projection for training estimator 给定生成的3D动作序列数据{ˆX1:T},将其投影到2D以获得成对的训练数据。考虑两种投影策略:1) 启发式随机投影,将虚拟摄像机设置为一定的仰角、方位角范围、高度和距离范围,以匹配室内拍摄环境;2) 基于生成对抗学习的投射,Generator用于回归每个运动序列的相机方向和位置,该回归通过Discriminator学习,Discriminator通过生成的相机参数区分真实和投影的二维姿势序列,通过这种方式,可以从真实的2D姿势数据中提取合理的相机视点分布,从而提高生成的2D-3D成对数据的合理性。这两种策略结合在作者的框架中,以确保相机视点的多样性。
3.2.2 Pose imitator
由于缺乏物理约束,由pose estimator P预测的3D姿势序列{X-1:T}会产生不自然的伪影,例如脚部滑动伪影、漂浮、地板穿透等。这些伪影使得它不能直接用作estimator P或Hallucinator H的训练数据。为了解决这个问题,作者引入了一个基于强化学习的pose imitator L,用于模仿pose estimator产生的3D姿势序列{X-1:T},以生成物理上合理的动作序列{X~1:T}。
Background 仿真过程(imitate process)可以看作是一个马尔可夫决策过程。给定参考动作和当前状态st∈ S、 代理与仿真环境进行交互,当动作at∈A时得到奖励rt。其中,动作at由一个策略函数:π(at | st)决定,该策略函数以当前状态st为前提,奖励rt取决于代理的动作与参考动作的相似程度。当动作被采纳,当前状态st通过转移函数T(st+1|st, at)转至下一状态st+1。目标是学习到一个策略,使平均累积报酬最大化∑∞i=1γirt(即,在物理仿真中执行与参考运动类似的行为),其中γ是贴现因子。更具体的策略下文展开说明。
State 包括参考运动的当前姿势qt、当前速度q˙t和目标姿势q~t+1。为了处理来自pose estimator含有噪声的参考动作,引入了额外的编码特征ϕ,连接和融合过去与未来的动作信息。通过这种方式,控制策略能够感知过去和未来的参考动作,因此对噪声更具鲁棒性。
Action 涉及两种力:内力和外力。内力是(有个actuator,不知如何翻译比较好)施加在非根部关节(如肘部、膝盖)上的。外力ηt是施加在根关节(即髋关节)上的虚拟力,用于额外的交互作用(例如坐在椅子上),并由策略网络进行回归。
Rewards 衡量代理和参考动作之间的差异。这些差异反映了姿势相关(姿势、速度)、根相关(根部高度、根部速度)和身体末端因素(位置、速度)。此外,为了避免不必要的外力跟随,对虚拟力施加了调节损失。作者发现,由于参考动作的噪声,代理很难在上述设置下移动,因此进一步在动作特征中引入脚的相对位置来增强脚的运动。
3.2.3 Pose hallucinator
pose hallucinator的目标是根据来自pose imitator的改进数据(refined data)生成新颖多样的动作序列。在这项工作中,作者选择了动作插值技术来生成新的姿势动作。具体的,从改进的姿势序列(refined pose sequence)中采样关键帧,并通过神经网络插值缺失帧以生成新的动作数据。具体来说,pose hallucinator是由一个递归神经网络(RNN)结构构成的,输入是采样的时序关键帧(以一定的帧间隔采样关键帧)。基于这些采样关键帧,模型按顺序预测中间帧。利用reconstrcution loss和adversary loss对该模型进行训练。reconstrcution loss衡量真实姿势和预测姿势之间的L2距离。adversary loss提供了时间监督,以避免RNN坍塌(即预测平均动作)。在推理阶段,从不同的动作序列帧(motion clips)中随机选择帧,并基于这些采样的关键帧生成新的运动序列。
4. Experiments
4.2. Quantitative results
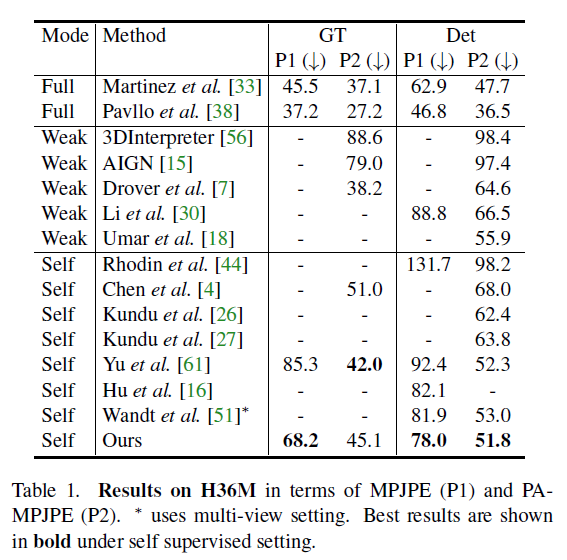
自监督能够做到和监督学习一样的效果,可以说非常好了,下面是在三个数据集上的实验结果对比:
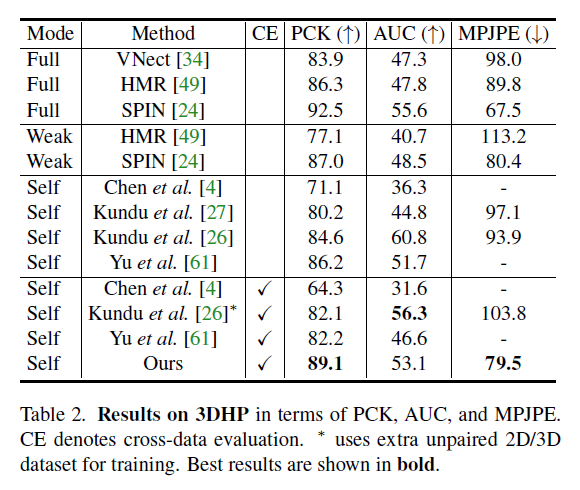
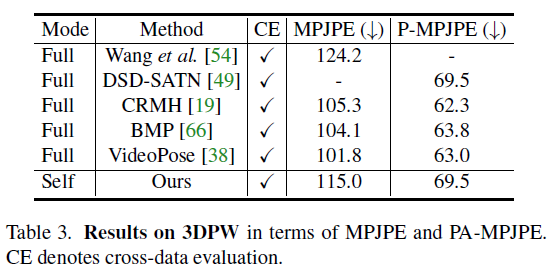
4.3. Qualitative results
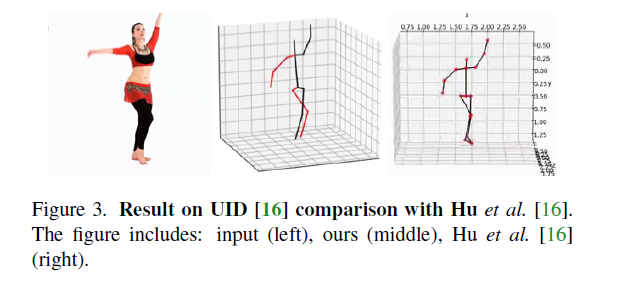
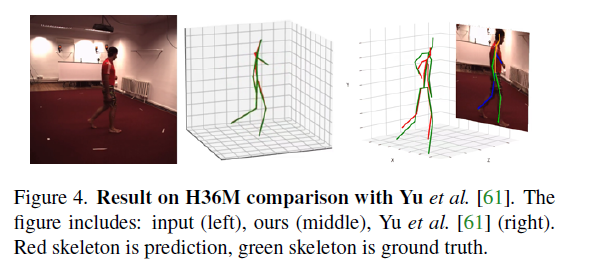
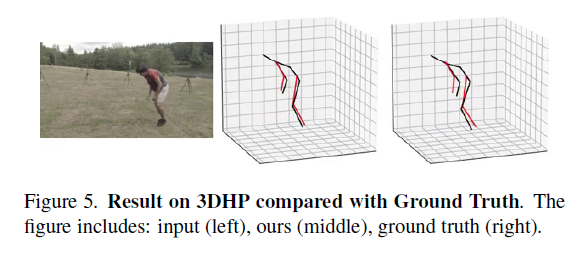
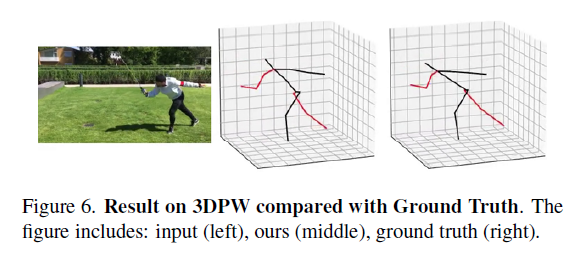

4.4. Ablation study

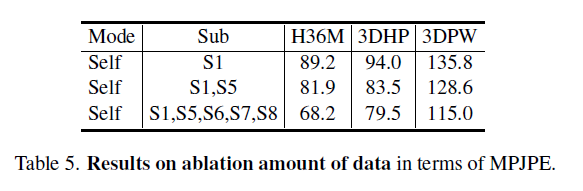
5. Conclusion
优势前面都说了,我赶着去吃饭,就不写了。
Limitations 主要的限制是训练效率较低,例如,在配备英特尔至强金6278C CPU和特斯拉T4 GPU的机器上训练3轮需要7天。原因是imitator(L)是用基于CPU的强化学习(RL)实现的,hallucinator(H)是用RNN架构实例化的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号