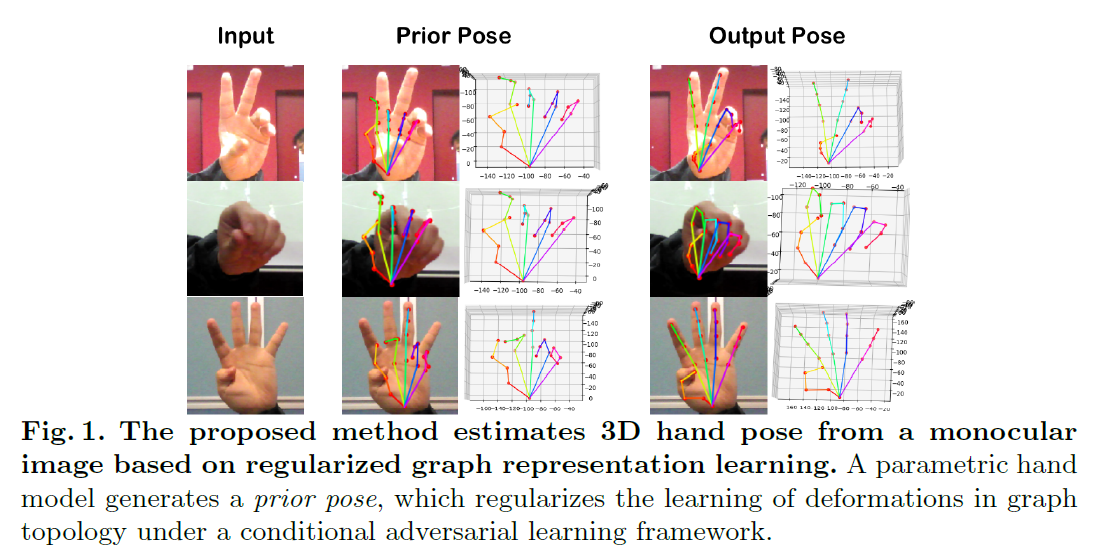
【AAAI 2022?】论文阅读:3D Hand Pose Estimation via Regularized Graph Representation Learning
论文地址:https://arxiv.org/abs/1912.01875?context=cs.CV
单位:北大王选研究院
这篇文章应该是AAAI2022录了,看记录改了好久。主要讲怎么改进模型的,理论扎实,公式比较多。
摘要
本文研究基于单目RGB图像的三维手部姿态估计问题。尽管之前的方法取得了很大的成功,但手的结构还没有得到充分利用,而手的结构是姿势估计的关键。为此,作者提出了一种基于对抗学习框架的正则化图表示学习方法,用于三维手部姿态估计,旨在捕捉关节的结构相关性。特别的,作者从参数化的手部模型中估计初始的手部姿势,作为手部结构的先验,这里将正则化先验姿势中结构形变的推理结果(reference),再通过残差图卷积(residual graph convolution)实现精确的图表示学习。为了进一步优化手部结构,作者提出了两个骨约束(bone-constrained)损失函数,它们明确描述了手部姿势的形变结构。此外,作者引入了一个对抗学习框架,该框架运用在输入图像上且包含一个多源判别器,该框架将结构约束加到生成的3D手部姿势分布上,以实现拟人且有效的手部姿势。
1&2.Introduction
主要贡献:
(1)提出了单目估计三维手部姿势的正则化图表示学习,充分利用了结构信息
(2)通过推导结构形变来学习手部姿态的图表示,而结构形变是通过正则化初始手部模型得到的,初始手部模型估计基于参数手部模型。
(3)引入了两个骨约束损失函数,通过明确地加强对骨骼拓扑的约束来优化手部结构的估计。
(4)提出条件对抗学习框架,施加结构约束到生成的3D手的分布,从而能够解决手部外观统一的挑战。
3. Methodology
3.1 Overview of the Proposed Approach
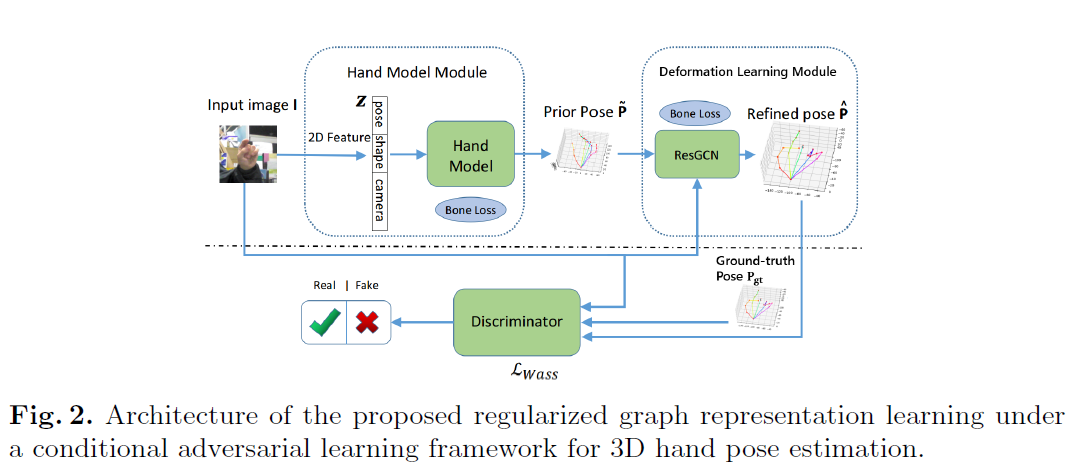
作者的目标是在对抗学习框架下,通过正则化图表示学习来推断出三维手的姿态,如图Fig2所示,由一个手部姿势生成器G和一个条件判别器D组成。
多源判别器D在输入图像上生成的三维手部姿态分布施加结构约束,从而将真实的三维姿态与预测的三维姿态区分开来。
3.2 The Proposed Hand Pose Generator G
给定输入图像I和真实的手部姿势Pgt,作者将从单目图像中估计手部姿势的训练描述为最大后验估计(Maximum a Posteriori, MAP)问题:
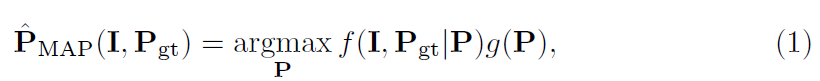
其中P表示要估计的手部姿势,g(P)表示手势的先验概率分布,其提供了P的先验知识。f(I,Pgt|P)表示似然函数,表示在给定估计的手部姿势P的情况下,得到观测图像I和真实手部姿势Pgt的概率是多少。
作者将似然函数定义为估计位姿与真实位姿/输入图像之间距离的指数函数:
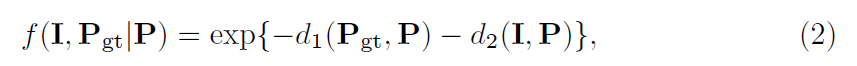
其中d1()为估计出的手姿与真实值之间的距离度量,d2()为估计出的手姿与输入图像之间的距离度量。
对于g(P),从参数化的手模型中获得一个先验姿态后,它是一个常数C。因此,将式(2)和g(P) = C代入式(1),取对数,乘以-1,得到一个求最小值的函数:
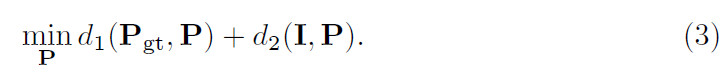
特别的,作者使用参数化的手部模型来提供P的先验,并指定形变学习模块在真实位姿和输入图像的监督下学习位姿。下面将详细讨论生成器的两个模块。
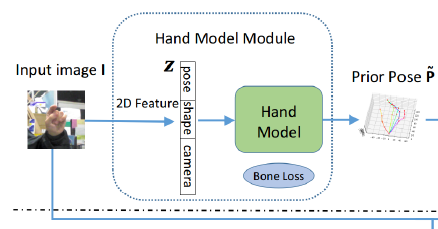
The Hand Model Module 给定一个单目图像作为输入,旨在生成一个3D手部姿势估计P~作为先验。手部模型能够用较少的参数表示手的形状和姿态,因此是一个适合于手姿态估计的先验。
首先预测手部模型的参数。具体来说,将输入的图像裁剪并调整大小到手部的显著区域,然后将其送入到ResNet-50中,提取特征得到潜在构造编码z,即手部模型的参数。
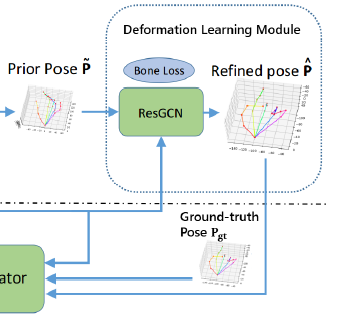
The Deformation Learning Module 该模块的目标是实现手部姿态估计的精确图表示学习,模块直接在先验P~上操作,由输入图像和ground truth pose作为监督。
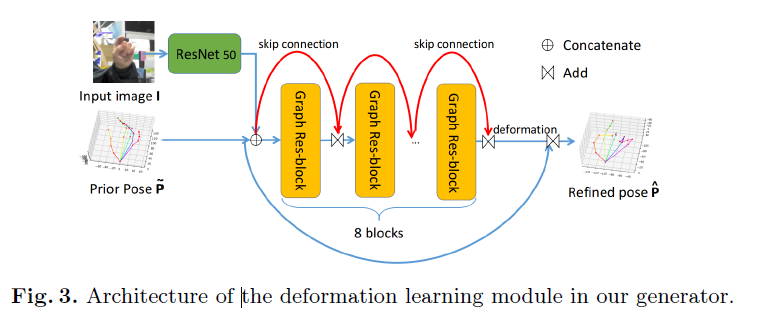
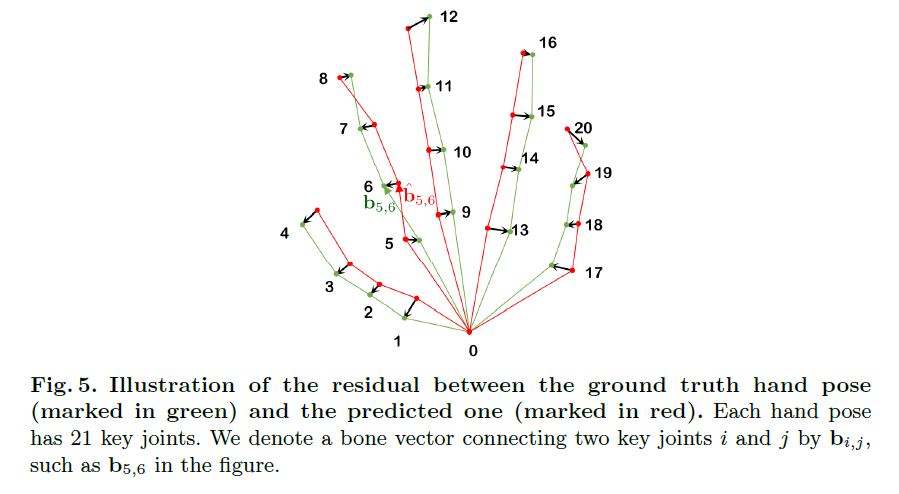
首先在P~上构造一个未加权的图,将手掌上不规则采样的关键点(即关节)投影到节点上。每个节点上的图信号(graph signal)是输入图像的全局特征向量与输入前位姿中每个关节的三维坐标向量的拼接。如果节点表示手的相邻关键点,则将节点连接起来,其中邻接关系遵循Fig 5所示的人手结构,得到邻接矩阵A。
基于以图方式表达的矩阵A,结合Fig3,最终可以得到调整后的公式:
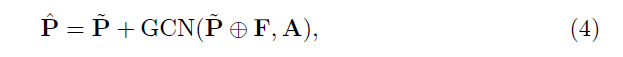
其中,F表示F维的图片特征向量,圆圈里面有个+表示特征相连操作,GCN()表示先验P~和真实值之间的形变,将先验的位姿P~和它的变形相加,就得到了改进的手姿。
设Xl表示 Graph Res-block输入的第l层,则第l层的 Graph Res-block的输出为:
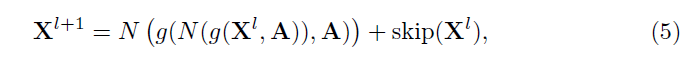
3.3 The Proposed Conditional Discriminator D
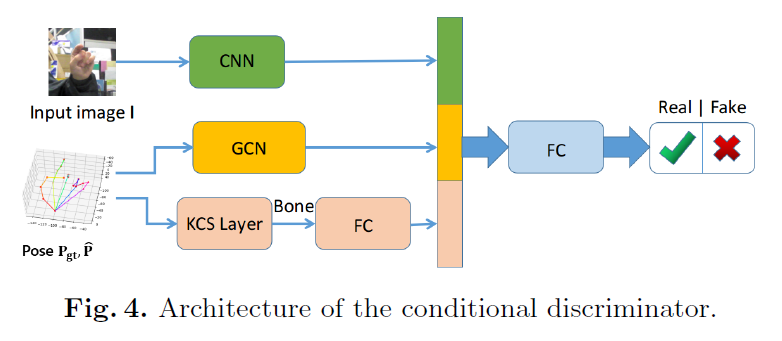
一个简单的手部姿态识别器结构是全连接(FC)网络,但它有两个缺点:1)忽略了RGB图像与推断的手部姿态之间的关系;2)没有明确地考虑手位姿的结构特性。
为了解决上述问题,作者设计了一个有三个输入的条件多源鉴别器。输入包括:1)输入单目图像的特征;2)精细的手部姿势P^或真实姿势Pgt的特征;3)通过KCS层的骨骼特征,它通过一个简单的矩阵乘法从P^或Pgt计算骨骼矩阵,骨骼特征包含了骨骼长度、方向等突出的结构信息,从而准确地表征了手部结构。
条件判别器的损失函数为Wasserstein loss:
![]()
3.4 The Proposed Bone-Constrained Loss Functions
直接用欧几里得距离来衡量估计值与真实值损失Lpose,估计投影的2D手部姿势和图像的损失Lproj:
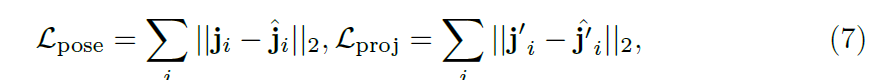
由于Lpose和Lproj不能明确地捕捉手部姿势的结构属性,作者提出了两个新颖的骨约束损失函数来表征每块骨的长度和方向。如图5所示,定义骨向量为:

第一个骨约束损失Llen,用于测定真实手部和估计手部骨长的误差:
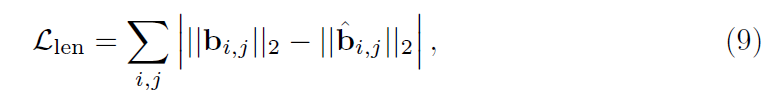
第二个骨约束损失Ldir,用于衡量骨方向偏差:
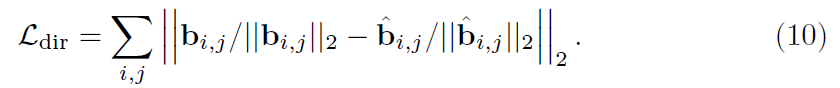
使用对抗学习框架时,也将Wasserstein loss引入到总的损失函数中,则总的损失函数为:
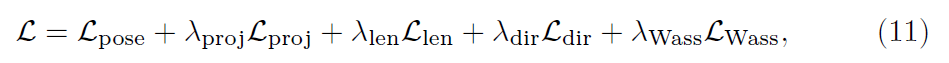
其中,
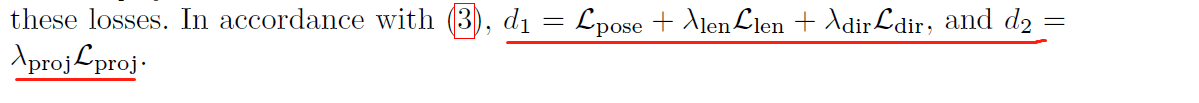
4 Experimental Results
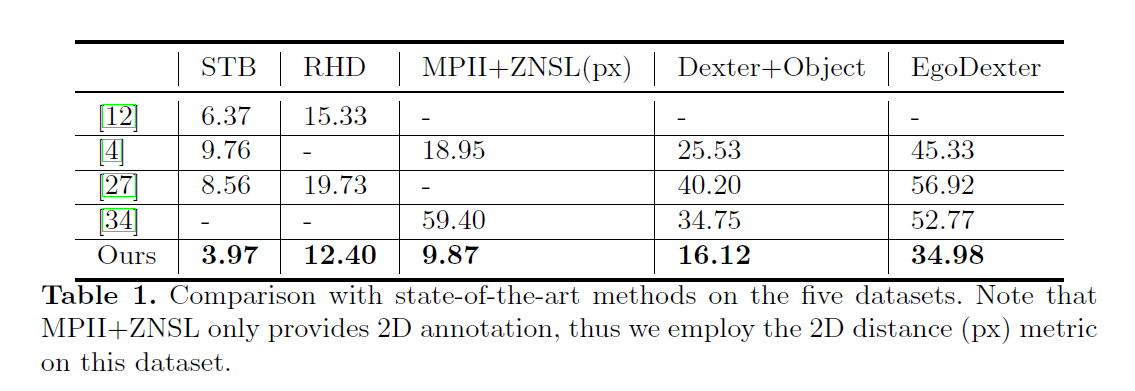
实验在5个数据集上的结果:
多阶段对比:

消融实验:


