【CVPR 2022】【简读】MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video
论文地址:https://arxiv.org/abs/2203.00859
Github:https://github.com/JinluZhang1126/MixSTE
单位:武汉大学、苏州大学、慕尼黑工业大学、布法罗大学
这也是一篇基于Transformer对3D HPE进行研究的论文,因为个人觉得这篇论文和去年的PoseFormer关联性挺大,就只读了其方法部分。
作者发现不同关节的运动具有明显的差异性,而之前的研究没有有效地对每个帧之间对应关节进行建模,导致时空相关性的学习不足。作者提出了MixSTE(Mixed Spatio-Temporal Encoder),包含temporal transformer block和spatial transformer block,其中temporal transformer block分别对每个关节在时序运动上进行建模,spatial transformer block则学习关节间的空间关系。两个块交替循环,以提取到更好的时空信息。另外网络输出不再像之前只输出中间帧,而是整个序列帧,提高了输入和输出序列之间的一致性。
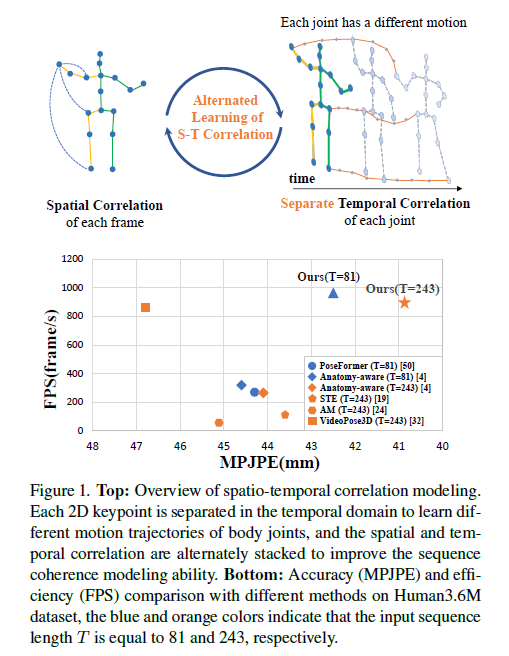
Figure1的上半部分图用于表示关节间时序关系的重要性,因此需要对其关节进行分离学习时序运动上的特征。
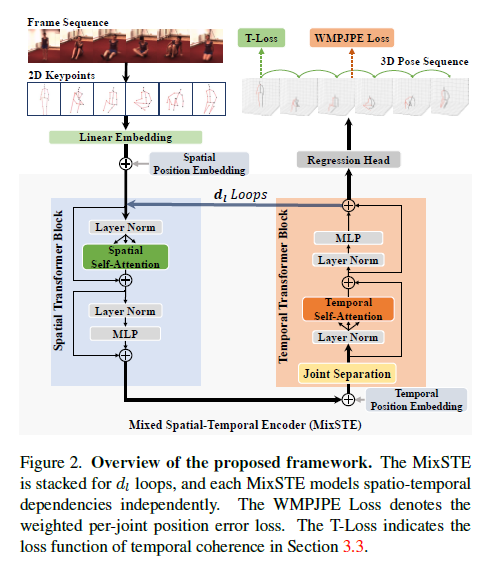
FIgure 2是MixSTE的整体框架,将视频转换为2D关节点序列,经过线性层后加入空间位置向量,feeding到Spatial Transformer block中,得到的输出加入时间位置向量后再放到Temporal Transformer block中,输出的块又回到Spatial block中,做l次循环,两个block都是含有残差结构的。经过l次循环后,经过回归得到一个序列的3D pose,这有别于之前研究只输出一个中间帧。不过作者没有在块之间加上残差结构,可能再加个残差机构效果会更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号