【CVPR 2019】 论文阅读:3D human pose estimation in video with temporal convolutions and semi-supervised training
2019 CVPR的文章,使用时序卷积和半监督训练的3D人体姿态估计
论文链接:https://arxiv.org/abs/1811.11742
github:https://github.com/facebookresearch/VideoPose3D
已经有前辈对这篇文章做过理解:https://www.cnblogs.com/zeroonegame/p/15037269.html
此处不介绍引言和相关工作,具体可参考前辈的阅读笔记,写的已经很好了。本文也只是做一个阅读记录。
摘要
这篇文章主要工作:
(1)使用基于空洞时序卷积的全卷积模型评估视频中的3D姿势
(2)引入了半监督训练方法,作者称为back-projection
2. 模型内容
2.1 Temporal dilated convolutional model
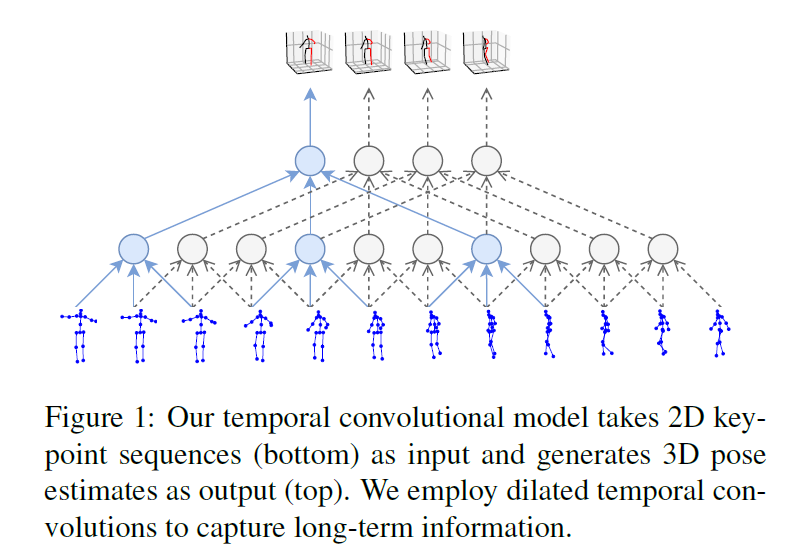
时序卷积模型将2D关键点序列作为输入,生成3D姿态估计,其间采用空洞卷积来提取时序信息。
关于空洞卷积,贴一个链接:https://zhuanlan.zhihu.com/p/113285797
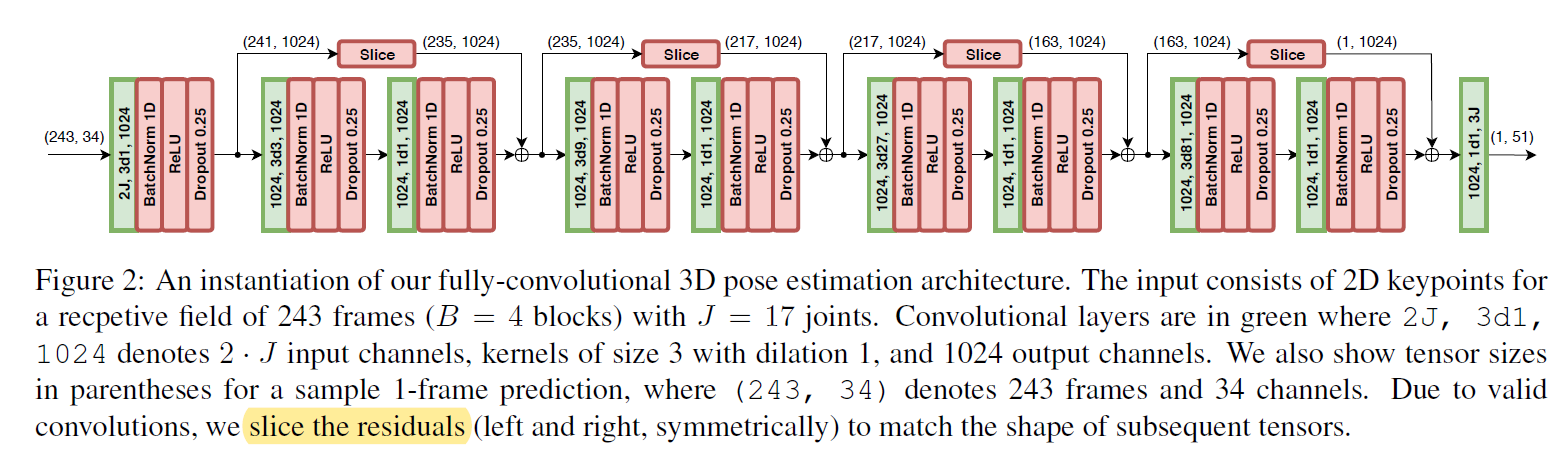
上图为网络结构图,输入为(243,34)大小的2D关键点序列,开始为一个不完整的块,将输出通道数设置为1024,后续由四个包含残差结构的块组成,最后一层输出所有帧的的三维姿态预测。
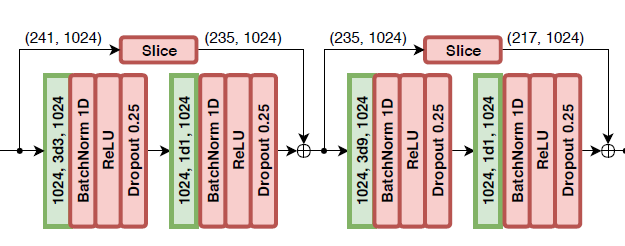
以第一个块为例,绿色部分为卷积层,每个块前后有两个卷积层,前者的卷积核(kernel size)W大小为3,后者的为1。前者的空洞卷积超参数(dilated factor) D = W^B,B的大小取决于当前处在第几个块,如第一个块D=3^1=3,网络中则为3d3,以此类推第四个块为3d81。卷积之后经过归一化,线性函数ReLU和Dropout后输出特征。每一个块输出的特征,类似于ResNet,经过一次slice操作后又加入到下下个块中,防止梯度消失。这边的slice操作是为了匹配前后两个块的张量大小,确保能够进行残差连接。
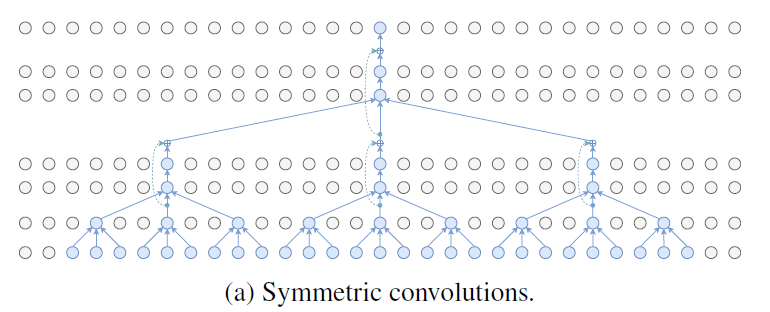
作者主要采用的是如下图的对称卷积:
为了用于实时场景,实际是不能用到未来帧的,作者也尝试了如下图的因果卷积(causal convolutions,)
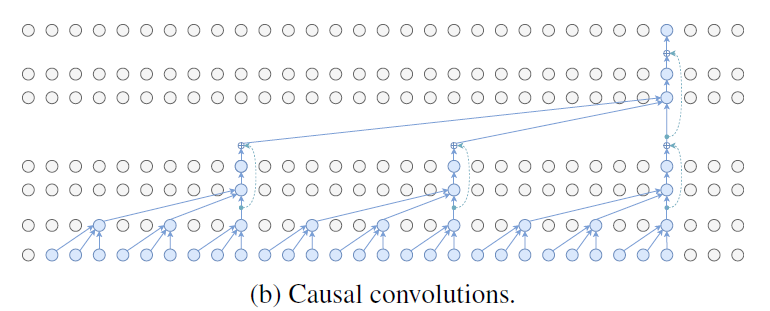
2.2 Semi-supervised approach
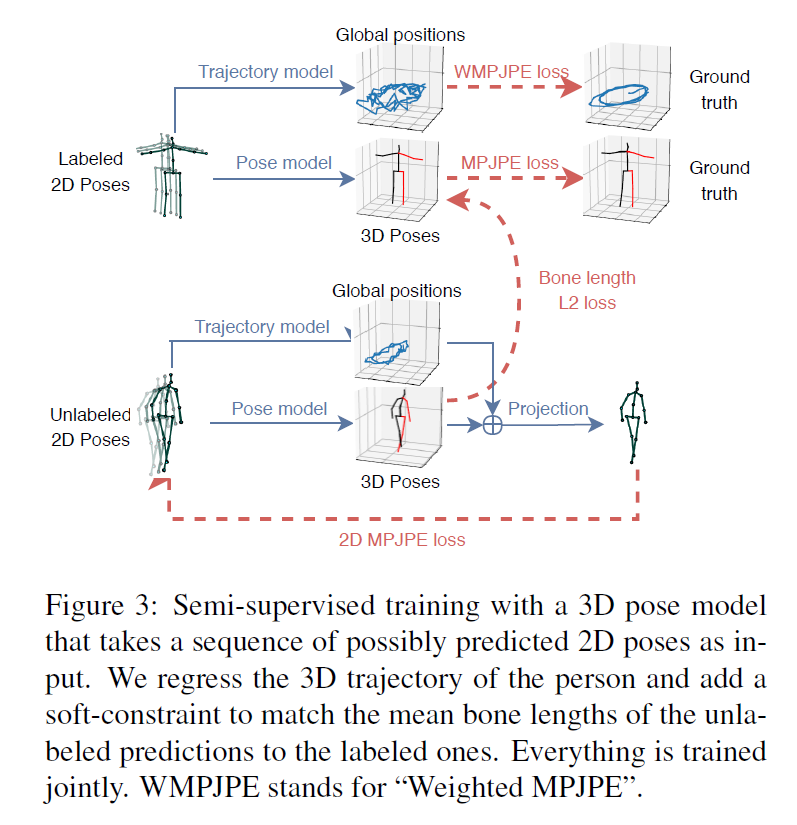
作者利用现成的2D关键点检测器(2D keypoint detector)和back-projection相结合,将未标注的视频产生的loss加到总loss中,以加强监督学习
2.2.1 Trajectory model
由于透视投影,屏幕中的2D姿态取决于轨迹(trajectory)和3D姿势,轨迹可以是人体根关节的全局位置,从figure 3可以看出,最后通过译码器投影出的2D姿势,包含了global position和 3D pose两部分信息。
如果没有这个全局位置信息,那么2D姿势的主体会被固定投影在屏幕的中心。因此,这边也对3D轨迹进行了回归,以正确的进行2D反向投影。
为此,优化了第二个网络,这个网络在相机空间中对gloabl trajectory进行回归,后者将其投影到2D之前加到姿势中。两个网络具有相同的架构,但不共享一套参数,因为作者发现以多任务方式训练时,两者会产生负面影响。
如果人体离相机较远,就会更加难以对起trajectory进行精确回归,因此作者优化了trajectory的加权平均关节位置误差(WMPJPE)损失函数:
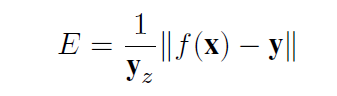
使用相机空间中的真实深度值(y_z)的倒数对每个样本进行加权,对于我们的目的来说,回归远目标的精确trajectory是不必要的,因为相应的2D keypoints往往集中在一个小区域周围,因此对于目标越远的目标,loss权重越低。
2.2.3 Bone length L2 loss
作者通过添加一个软约束,对无标签batch中subjects的平均骨长与有标签batch的subjects的骨长做近似匹配,发现效果是更好的,即figure 3中计算的Bone length L2 Loss。计算这个loss对自监督学习起到了很重要的作用。
2.3 Discuss
该方法仅需要一些相机的内置参数,这些参数基本商业相机都能够提供。该方法不依赖于特定的网络结构,可以应用在任何以2D关键点作为输入的3D姿态检测器中。
在实验中,作者按照本章中描述的架构将2D姿势映射到三维,为了将3D姿势重新投影到2D,作者使用了一个简单的投影层,该投影层考虑到了线性参数(焦距、焦点)和非线性的镜头畸变系数(切向、径向)来实现。这边也提到了在Human3.6M数据集中使用的镜头畸变参数对于姿态估计几乎没有影响,但仍然将其囊括进来,因为是相机真实的一个参数。
3. 实验及结果
3.1 实验设置
评估使用的数据集:Human3.6M 和 HumanEva-I
Human3.6M中标志了3D姿态的7个子集,从中提取17的关节点,(S1,S5,S6,S7,S8)作为训练集,(S9, S11)作为测试集。
HumanEva-I相对小得多,从三个视角记录同一个对象,作者既通过对每个动作训练不同模型来评估三个动作,也未所有动作训练了一个模型。
衡量指标:MPJPE、P-MPJPE、N-MPJPE
3.2 实现细节
3.2.1 Implementation details for 2D pose estimation
之前的工作大部分都是在ground-truth bounding boxes提取目标,后使用stacked hourglass detector预测ground-truth bounding boxes中的2D关键点的位置。这篇文章并不依赖于任何特定的2D关键点检测器。作者研究了集中不依赖于ground-truth boxes的2D detectors,使得该实验在真实场景也可用。
除了stacked hourglass detector ,作者研究了包含一个ResNet-101-FPN bone的Mask-R-CNN网络,参考其在Detectron中的实现,以及cascaded pyramid network(CPN) ——FPN表示的扩展,CPN实现需要外部提供边界框(在这一情况下使用Mask R-CNN)
对于Mask R-CNN和CPN,因为关键点在COCO和Human3.6M不同,作者在COCO上进行预训练,后在Huaman3.6M上fine-tune 2D投影的检测器。在消融实验中,作者还实验了直接将3D姿态估计应用于预训练的2D COCO关键点,以估计Human3.6M中的3D joints。
对于Mask R-CNN,作者采用了“stretched 1x”表训练的ResNet-101作为backbone。微调时重新初始化了最后一层的keypoint network,反卷积层,来回归hetmaps来学习一组新的keypoints。使用4个GPU进行步长衰减学习率训练。
CPN使用输入分辨率为384x288的ResNet-50作为backbone,微调时重新初始化GlobalNet和RefineNet的最后一层。训练时采用指数衰减学习率。在微调时保持batch normalization。
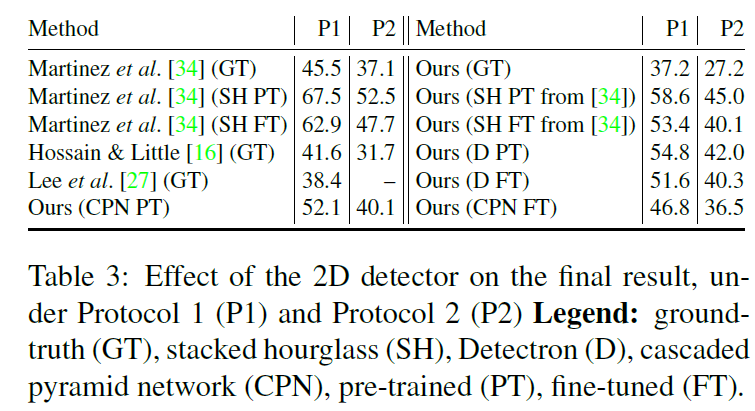
下图为作者研究的几个2D key joints检测器的效果对比
3.2.2 Implementation details for 3D pose estimation
这部分留个坑
3.3 结果
3.3.1 Temporal dilated convolutional model
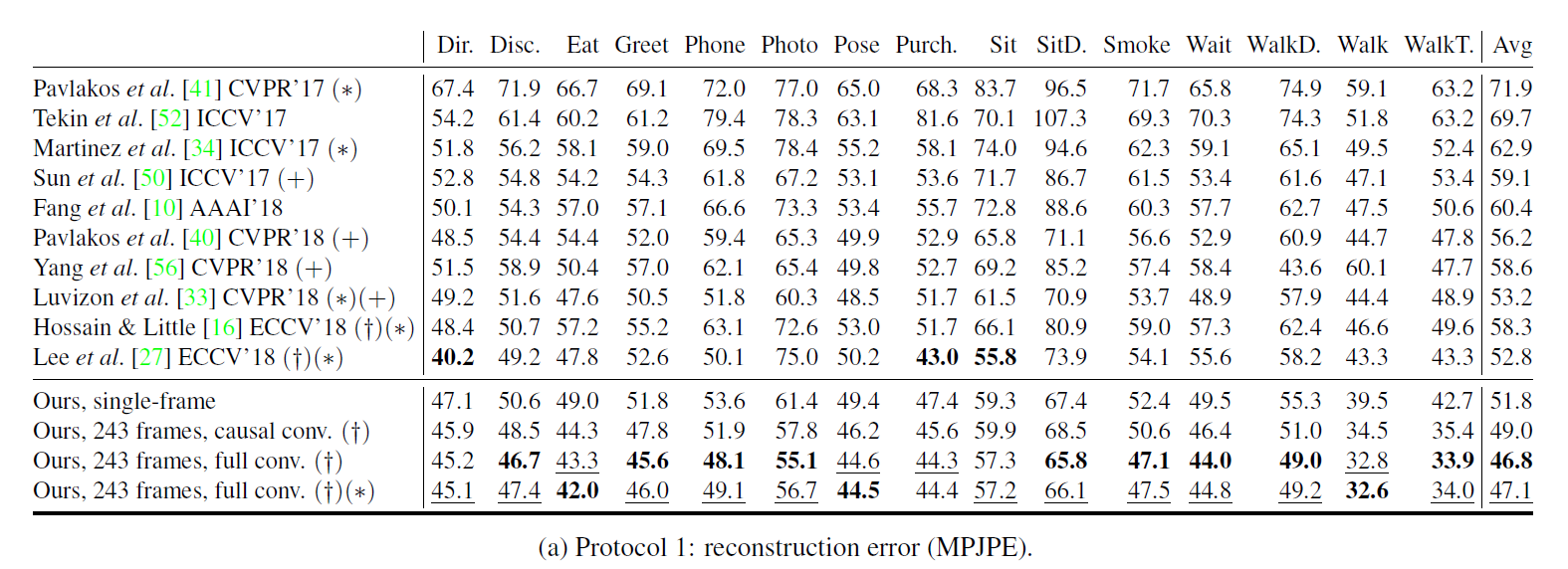
下面两张表显示的是B=4blocks,receptive field=243 frames时的结果,可以看到两个指标的效果普遍是比较好的,(+)表示需要额外依赖数据。
MPJPE Metric
P-MPJPE Metric
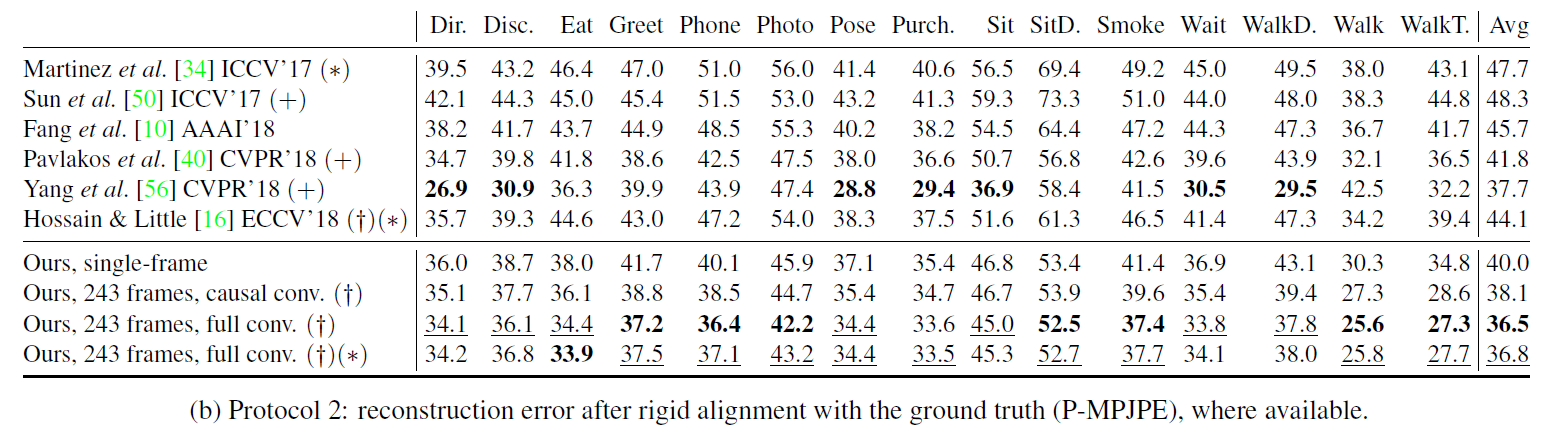
table 2展示了在单帧情况和时序情况下实现3D pose预测的Velocity error,即3D pose sequence的MPJPE(mean per-joint position error)的一阶倒数,这一失序模型将单帧的MPJVE(measure joint velocity errors)平均降低了76%。
可以这么理解,绝位置对误差(Abosolute position errors)是无法衡量预测的平滑性的,需要对其进行求导,一般误差越大,就越不平滑,误差越小,就会越平滑。

table4展示了在HumanEva-I的结果,结果也是很好的,说明可以推广到更小的数据集上。
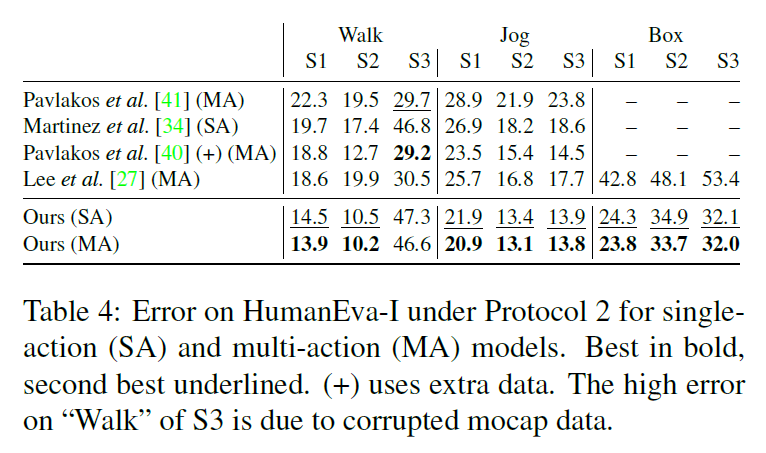
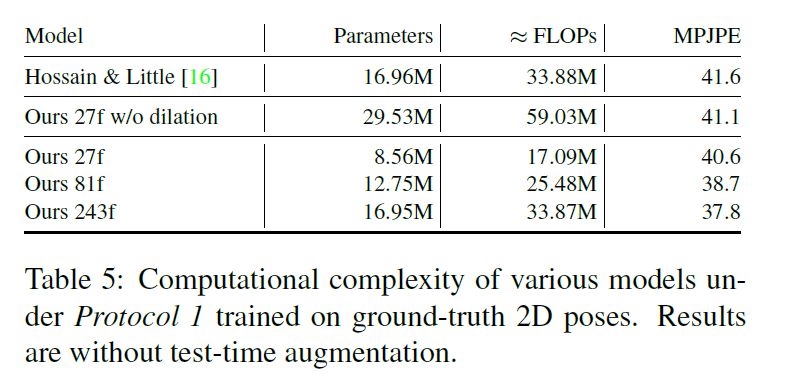
table 5 对比了与LSTM的复杂度,主要比较参数量、浮点运算量和MPJPE,27f表示使用27个frame预测一个3D pose,类似的,81f表示81 frames预测一个3D pose。
3.3.2 Semi-supervised approach
Figure 5a 显示,随着标记数据量的减少,半监督方法变得更加有效,当标记帧少于5K时,要比以 supervised 为 baseline的效果提升大约9-10.4 mm N-MPJPE

Figure 5b显示了对数据集进行非下采样版本的结果,这种设置方法更加适合这个模型,因为可以充分利用视频中完整的时间信息,即使在感受野为27或者9时,也比baseline效果好上很多。
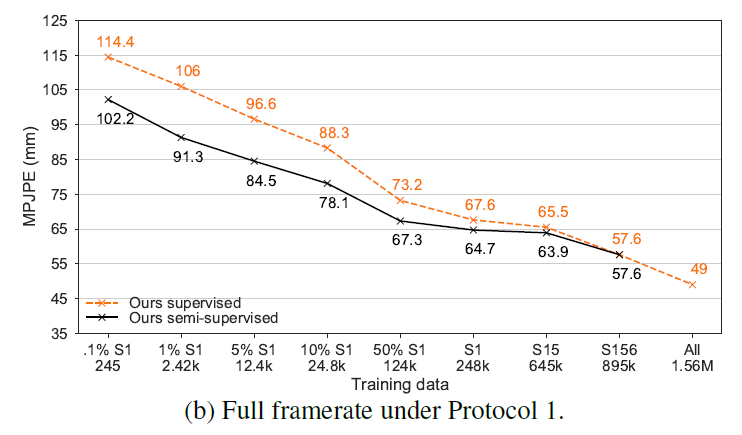
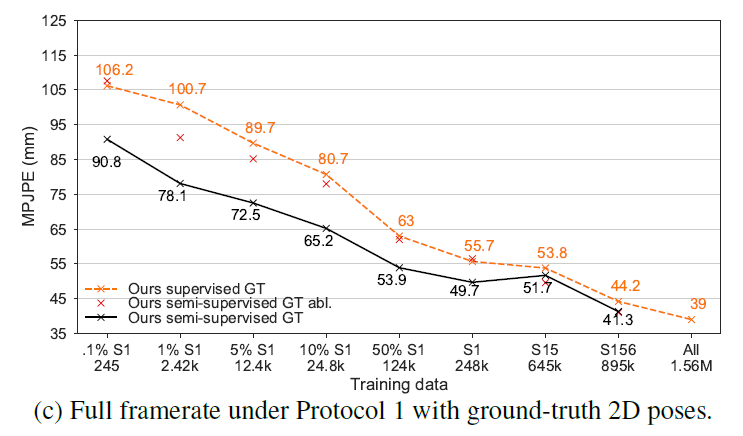
Figure 5c 更换了2D keypoints detector,发现会影响最终的误差,说明一个好的detector是很重要的,最高可以提高22.6mm MPJPE(1% S1的情况下)
4. Conclution
本文介绍了一个简单的全卷积模型。用于视频中的3D人体估计。主要贡献在于两个:
(1)该架构通过在2D keypoint trajectory上使用空洞卷积,利用了视频中的时序信息。
(2)使用半监督训练,提高了数据缺少时的效果。该方法使用于未标记视频,且只需要用到相机的一些内部参数。
附录部分还有不少内容,作者其实做了很多工作,后续要学习一下代码才能更深入领会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号