笔试准备-牛客-京东算法岗试卷-单选/不定项/编程
目的:准备2020京东春季实习生笔试 2020/04/18 星期六 19:00-21:00
- 选择30道:估计做对一半吧
- 编程2道:27% 数学类;0% 平行线段
也是为了之后秋招做准备。因为回顾一下,之前的笔试考前就笼统地刷几道leetcode,考后也没有再复盘,暴露出了2个问题:1. 没有针对每家公司的考点总结;2. 下次遇到不会的还是不会。所以这次要摆正心态,在牛客上能搜到的真题,在考前好好刷一遍,准备一个自己的题库,真正做到能够以战养战。
感觉每道题都是一个新的知识点 可见自己的掌握程度。
每道题都写题解,而且还分类加排版,有点太慢了。京东这个就当做第一个题库,慢慢磨,补齐吧,后面其他企业的题库,就碰到新知识或者不会的记一下。
-----------------------------------------------------------------
数据结构与算法:字符串、栈与队列
---------------------------- 未完成----------------------------
京东2019校招算法工程师笔试题
- 单选52道:数据结构与算法 10道 (DONE);数据库 7道;C/C++ 15道;JAVA 10道;Python 6道;机器学习 6道 (DONE)
- 不定项12道:操作系统 1道 (DONE);数据结构与算法 1道 (DONE);C/C++ 6道;Python 1道;机器学习 1道 (DONE)
-----------------------------完成:除编程题------------------
京东2019春招京东算法类试卷
- 单选28道:数据结构与算法 8道;数据库 2道;C/C++ 3道;JAVA 3道;Python 4道;分布式集群 2道;机器学习 6道 (DONE)
- 不定项2道:C++ 1道;操作系统1道 (DONE)
- 编程1道:数学+DP
京东2018秋招算法工程师笔试题
- 单选15道:数据结构与算法 7道 ;机器学习 4道 ;概率论 4道;(DONE)
- 不定项15道:机器学习 12道;概率论:3道;(DONE)
- 编程2道:数学题
=============================
单选题
数据结构与算法类单选题:
1. 考察软件开发模型(出现2次)
问题:下列有关增量模型描述正确的是 .
a) 已使用一种线性开发模型,具有不可回溯性 --> 瀑布模型
b) 把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件 --> 增量模型
c) 适用于已有产品或产品原型(样品),只需客户化的工程项目 --> 快速原型模型
d) 软件开发过程每迭代一次,软件开发又前进一个层次 --> 演化模型
- 瀑布模型:分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,线性;
- 快速原型模型:快速建立原型,让用户与系统交互,再根据需求细化;
- 增量模型:将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件,可以分批次提交;
- 螺旋模型:瀑布模型和快速原型模型结合,适合大型复杂系统;风险驱动,需要准确分析风险
- 演化模型:迭代开发方法。
2. 考察运算符优先级
问题:以下运算符中运算优先级最高的是 .
a) +
b) OR
c) >
d) \ (√)
- \:转义运算符,比如换行‘\n’,水平制表'\t';
- 上述选项中的优先级为:'\' 先于 '+' 先于 '>' 先于 'OR';
3. 考察字符串比较大小
字符串”ABCD”和字符串”DCBA”进行比较,如果让比较的结果为真,应选用关系运算符 < .
字符串比较规则
- 从左至右,逐个字符比较,第一个不同时即可结束
- 比如'ADC'<'BD',因为‘A’已经小于‘B’了,就不需要看后面的字符以及长度。
4. 考察子串数目
问题:若串S=”UP!UP!JD”,则其子串的数目 37 .
- 子串:字符串中任意个连续的字符组成的子序列+空串;
- 此题不去掉重复的子串S共9个字符
- 长度为1的:9个;
- 长度为2的:8个;
- 一直到长度为9的:1个。
- 所以子串个数为$\frac{(1+n)*n}{2}+1$。
5. 交换变量元素
6. 考察线性链表:存储空间、存储顺序都任意。即有表头元素不一定存储在其他元素的前面。
7. 考察链表:
问题:在 中,只要指出表中任何一个结点的位置,就可以从它出发依次访问到表中其他所有结点。
a) 线性单链表
b) 双向链表
c) 线性链表
d) 循环链表 (√)
8. 考察栈和队列
用两个栈模拟实现一个队列,如果栈的容量分别是O和P(O>P),那么模拟实现的队列最大容量是 2P+1 .
目的:要实现队列的先进先出
大容量的栈(记为A)作为存储栈,小容量的栈(记为B)作为缓冲栈
入队:
1,2,...,P入栈A,再从栈A弹出P,P-1,...1,入栈B,此时栈B中的元素为1(栈顶),2,...,P(栈底);
P+1, P+2,...2P+1入栈A;
出队:
从栈B中弹出:1,2,...,P;
再从栈A弹出2P+1, 2P, ..., P+2,入栈B;
从栈A中弹出:P+1;
最后从栈B中弹出:P+2, P+3, ..., 2P+1
有点类似于汉诺塔的铜钱转移
9. 考察队列:先进先出
10. 考察栈:先进后出
问题:栈底至栈顶依次存放元素A、B、C、D, 在第五个元素E入栈前,栈中元素可以出栈,则出栈序列可能是 .
DCBA的顺序不会变,E可插在其中5个位置的任意一个位置上,如DECBA.
11. 考察出栈顺序
问题:按1234的顺序入栈,则出栈的可能有 14 种.
比如:可以是1324:1入栈-->1出栈;2,3 入栈--> 3,2出栈;4入栈-->4出栈;
但不可能是4213:4出栈,由于先进后出,说明1,2,3已经入栈,那么之后出栈的顺序只有可能是321.
方法1:
1看作入栈,0看作出栈,从左往右看,入栈次数>出栈次数,即1的个数>0的个数;总共n次入栈,n次出栈
总体:从2n个位置选择n个位置存放1,即C(n,2n);
不合法:在2n个位置放n+1个0,n-1个1
0的个数多了2个,总共2n个位置是偶数 --> 在某个奇数位上出现0的累计数>1的累计数
在后面部分0和1互换,也是一个不符合要求的数
比如:1 0 1 0 1 0 0 1 0 1 0 1 0 0 第7个位置是0,此时从左往右,0的个数已经大于1的个数,不合法
1 0 1 0 1 0 0 0 1 0 1 0 1 1 在第7个位置后,互换0和1,仍不合法
所以,由n+1个0和n-1个1组成的2n位数对应一个不合法数,即C(n+1,2n)
即出栈次数=C(n,2n)-C(n+1,2n)=C(n,2n)/(n+1)
这种解释有点问题,觉得应该是总共n个1和n个0排列,再去掉排列中,从左往右0的个数大于1的个数的排列,这里不合法的为什么就变成了n+1 个0和n-1个1?
参考:卡特兰数应用——n个元素的出栈顺序与从(0,0)到(n,n)不穿过对角线的方法数 https://blog.csdn.net/u014097230/article/details/53391091
方法2:
$f(n)$:n个字符的出栈顺序的方法数
假设数1在第k个位置出栈,那么值钱有k-1个字符已经出栈,之后还有n-k个字符未出栈
那么$$f(n)=f(0)*f(n-1)+f(1)*f(n-2)+...+f(n-1)*f(0)$$
其中,$f(0)=1,f(1)=1$
此题中,n=4, 出栈次数=$C_8^4$/5=14
12. 考察回溯法与分支界限法
- 回溯法:DFS 深度优先搜索,可以回到该结点继续搜索;
- 分支界限法:BFS广度优先搜索,BFS维护一个队列,每次pop出一个元素时,与该元素所有相连的结点入队;而分支界限法估计某个结点往后的消耗最小(效益最大),该结点一旦成为扩展结点,将其所有满足要求(可以导致可行解/最优解)的儿子结点入队。即分支界限法是BFS+舍弃导致非可行解/非最优解的儿子结点。
问题:在对问题的解空间树进行搜索的方法中,一个结点有多次机会成为活结点的是___ 回溯法__ __.
13. 考察递归与递推
关于递归法的说法不正确的是 .
a) 程序结构更简洁 (√)
b) 占用CPU的处理时间更多 (√)
c) 要消耗大量的内存空间,程序执行慢,甚至无法执行 (√)
d) 递归法比递推法的执行效率更高 (×)
- 递归:自顶向下分解问题,直到可以直接求解,再逐级向上回溯到初始问题,即由$f(n)$扩展到$f(1)$,再从$f(1)$逐步计算回到$f(n)$;
- 调用自身函数,参数不断地压栈和出栈,且有重复计算,开销大;
- 递归的深度一旦过大,会消耗完栈空间
- 递推:利用循环一步步迭代,直接自底向上;即从$f(1)$算到$f(n)$;
- 所以递推法比递归法的执行效率高。
14. 考察堆排序
问题:以下哪种排序算法一趟结束后能够确定一个元素的最终位置 .
a) 简单选择排序
b) 基数排序
c) 堆排序 (√)
d) 二路归并排序
存疑:觉得a) 简单选择排序每次从无序部分选择最小的,放到有序部分,也能确定一个元素的最终位置。
- 大顶堆:升序;小顶堆:降序;
- 以大顶堆为例,堆顶就是最大元素,每次都可以确定一个最大元素;
- 每次输出堆顶元素 --> 堆顶元素与最后一个元素交换 --> 再调整成大顶堆;
- 平均时间复杂度O(NlogN),空间复杂度O(1),数据不敏感,不稳定。
15. 考察二分查找
问题:一个序列为(13,18,24,35,47,50,63,83,90,115,124),如果利用二分法查找关键字为90的,则需要 2 次比较.
在排好序后,n=11, left=0, right=10,
mid=(0+10)/2=5, lst[5]=50<90 --> left=6, right=10
mid=(6+10)/2=8,lst[8]=90=90 --> 查找到,所以一共比较2次
16. 考察图
a) 在有向图中,出度为0的结点成为叶子结点 (√)
b) 用邻接矩阵表示图,容易判断任意两个结点之间是否有边相连,并求得各结点的度(√)
c) 按深度方向遍历图和前序遍历树类似,得到的结果是唯一的 (×)
d) 若有向图G中从结点Vi到结点Vj有一条路径,则在图G的结点的线性序列中结点Vi必在结点Vj之前的话,则称为一个拓扑序列(√)
- 图的存储:数组表示法、邻接表/十字链表/邻接多重表;
- 图的遍历:DFS(栈实现)、BFS(队列实现);
- 应用1:构造最小生成树:Prim算法:将所有顶点归类,适用稠密网;Kruskal算法:将所有边归类、适用稀疏网;
- 应用2:求解最短路径: Dijkstra算法:求有向图从源点到其余各顶点的最短路径O(N^2);Floyd算法:每一对顶点之间的最短路径O(N^3);
- 应用3:拓扑序列:基于AOV网(不存在回路),可以将图中所有活动排列成一个线性序列,不唯一;
- 应用4:关键路径:基于AOE网,以拓扑排序为基础,不唯一;关键路径上的活动均为关键活动,影响整个项目进度的关键。
17. 考察二叉树性质
问题:一颗二叉树的叶子结点有5个,出度为1的结点有3个,该二叉树的结点总个数是 12 .
- $n_0$:叶子结点个数 ;$n_1$:度为1的结点个数;$n_2$:度为2的结点个数
- 公式1:n=$n_0$+$n_1$+$n_2$ (二叉树的特性)
- 公式2:n=$n_1$+2*$n_2$+1 (树的性质:树中结点数目=所有结点的度+1)
- 公式3:$n_0$=$n_2$+1 (由公式1、2推出)
- 所以此题中,$n_0$=5, $n_1$=3, $n_2$=n_0-1=5-1=4,相加可得n=5+3+4=12。
18. 考察二叉树的高度
问题:某二叉树有2000个结点,则该二叉树的最小高度为 11 .
$2^{10}=1024$,$2^{11}=2048$,所以最小高度为11。
19. 考察二叉树遍历
问题:中序遍历一棵二叉树得到E A C K F H D B G;后序遍历得到E C K A H B G D F;则先序遍历___F A E K C D H G B___.
a) 后序遍历的最后一个节点是根节点,F;根据F在中序遍历中找到左子树EACK,右子树HDBG
b) 在后序遍历的左子树ECKA中,找到整体左子树的根节点为A;再回到中序遍历中根据A分为左子树E,右子树CK;
c) 在后序遍历的A的左子树C,A的右子树CK,找到A的右子节点K;再回到中序遍历中,根据K分为左子树C,右子树NULL;
d) F的右子树也如b), c)处理。
中序 E A C K F H D B G
后序 E C K A H B G D F
中序 E A C K F H D B G
后序 E C K A H B G D F
中序 E A C K F H D B G
后序 E C K A H B G D F
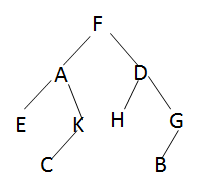
20. 考察二叉树遍历
问题:已知一个二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为___D G E B H F C A ___.
中序:D B G E A C H F
前序:A B D E G C F H
中序:D B G E A C H F
前序:A B D E G C F H
中序:D B G E A C H F
前序:A B D E G C F H
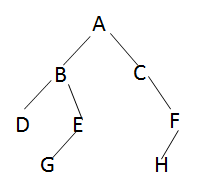
21. 考察平衡二叉树的插入调整
问题:把14,27,71,50,93,39按顺序插入一棵树,插入的过程不断调整使树为平衡排序二叉树,最终形成平衡排序二叉树高度为 3 .
a) 正常插入14,27,71
b) 插入50后,平衡因子>1,需要调整 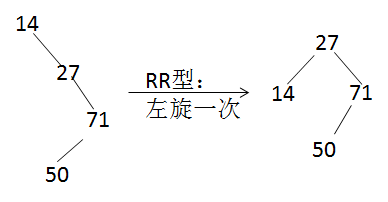
c) 正常插入93 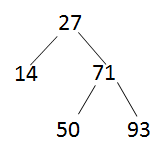
d) 插入39后,平衡因子>1,需要调整
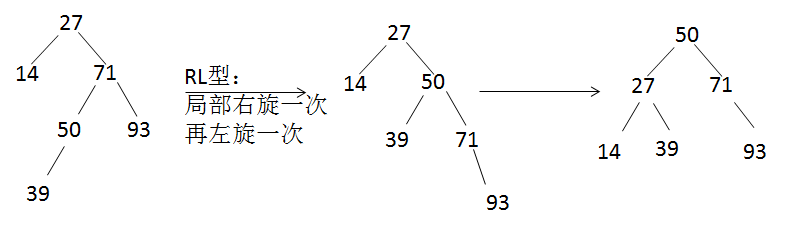
觉得即使不画出平衡树,也能做这道题。一共6个点,一个根结点,根结点的两个子结点,这样已经用掉3个结点,且高度为2了。若高度为4,则显然不满足AVL树的定义,所以一定是3层。
22. 考察小顶堆
问题:已知小顶堆:{51,32,73,23,42,62,99,14,24,39,43,58,65,80,120},请问62对应节点的左子节点是 73 .
- 小顶堆:每个非叶子结点的关键值都<其孩子节点的关键值
- 按照完全二叉树将数字填入
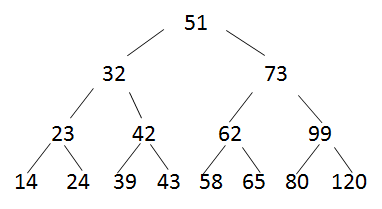
- 再从最后一个非叶子结点开始调整,选孩子结点中小的那个
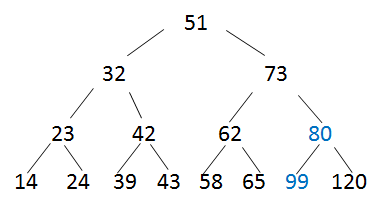
- 对第3层都做如上调整
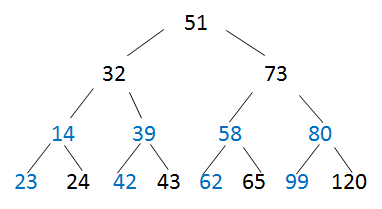
- 对第3个结点调整时,需要一直比较到叶子结点
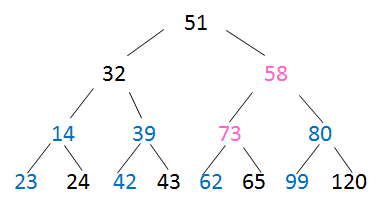 ---->
----> 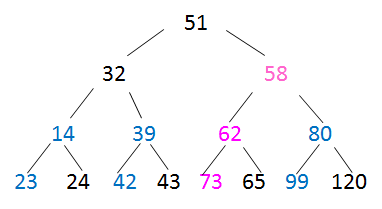 此时,已经可以做该题,62的左孩子就是73。
此时,已经可以做该题,62的左孩子就是73。
-
调整第2个结点:
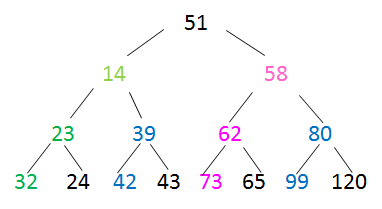
-
最后调整根结点,得到小顶堆为:
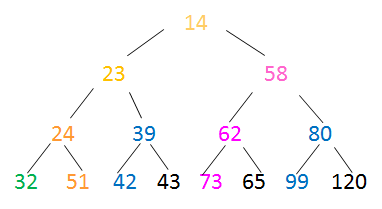
23. 考察哈夫曼树
问题:权值分别为9、3、2、8的结点,构造一棵哈夫曼树,该树的带权路径长度是?
- 树的路径长度:从树根结点到每一个结点的路径长度之和;
- 哈夫曼树构造:先选权值最小的两个结点,构成一棵二叉树,再剩下的最小的结点组合,以此下去;
- 哈夫曼编码应用:用二进制前缀编码使报文总长度最短。
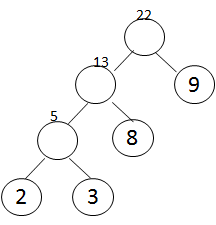
相邻路径间为1,所以树的路径长度为:2*3+3*3+8*2+9*1=40;或者直接5+13+22=40。
统计:
1.在贝叶斯线性回归中, 假定似然概率和先验概率都为高斯分布, 假设先验概率的高斯准确率参数为a, 似然概率的高斯准确率参数为b, 则后验概率相当于平方误差+L2正则,则其正则化参数为
a) a + b (√) --> L1正则
b) a / b
c) a^2 + b^2
d) a^2 / (b^2)
存疑:感觉题目都没明白
2. 考察贝叶斯公式
问题:有A,B 两个国家,人口比例为4:6,A国的犯罪率为0.1,B国的为0.2。现在有一个新的犯罪事件,发生在A国的概率是 0.25 .
- 对于任意n个独立同分布随机变量$Xi$,如果他们有期望和方差,那么他们的和趋向于正态分布,且n越大,效果越好;
- 高斯分布,就是正态分布;
- 服从均匀分布的随机变量,只要n充分大,随机变量
就服从均值为零,方差为1的正态分布。
4. 考察二元函数求极值
问题:关于x,y的函数f(x,y)=x*e^(-x^2-y^2),(x,y∈R),则该函数有___1_ _个极小值点.
- $\frac{\partial f}{\partial x}=0$,$\frac{\partial f}{\partial y}=0$
- f(x,y)是奇函数:一个极小值点,一个极大值点
数据库:
1. 考察索引的分类
以下对主键描述正确的是 .
a) 主键是唯一索引,唯一索引也是主键 (×)--> 主键是唯一索引,但唯一索引不一定是主键
b) 主键是一种特殊的唯一性索引,只可以是聚集索引 (×)--> 主键是唯一索引,但唯一索引不是主键
c) 主键是唯一、不为空值的列 (√)
d) 对于聚集索引来说,创建主键时,不会自动创建主键的聚集索引 (×) --> MySQL创建主键时默认为聚集索引
- 唯一索引 UNIQUE:索引列值唯一、允许空值;
- 主键索引 PRIMARY KEY:索引列值唯一、不允许空值;(MySQL创建主键时默认为聚集索引);
- 覆盖索引 COVERING:包含了所有满足查询所需要的数据;查询时只需要读取索引,而不用回表读取数据;
- 聚集索引 CLUSTERED:对磁盘上存放数据的物理地址重新组织,以使这些数据按照一定规划排序;
- 非聚集索引:只记录逻辑顺序,不改变物理顺序
主键列:一种约束,不允许空值+唯一索引;可以被其他表引用为外键,一张表只能创建一个主键列;适用:不容易更改的唯一标识,如自动递增列、身份证号。
唯一索引:一种索引;不能被其他表引用,一张表能创建多个唯一索引。
2. 如果ORDER BY子句后未指定ASC或DESC,默认使用 ASC .
3.
C/C++:
1. 考察字符串
问题:以下程序统计给定输入中每个大写字母的出现次数(不需要检查合法性),补全程序
void AlphabetCounting(char a[],int n){ int count[26]={},i,kind=0; for(i=0;i<n;++i) (____________); for(i=0;i<26;++i){ if(++kind>1) putchar(';'); printf("%c=%d",(____________)); } }
a) ++count[a[i]-'z']
'Z'-i,count['Z'-i]
b) ++count['A'-a[i]]
'A'+i,count[i]
c) ++count[i]
i,count[i]
d) ++count['Z'-a[i]]
'Z'-i,count[i]
用排除法,快速求解该题:a) 用小写字母排除;c)和大写字母不沾边;关键是排除b):index是负数,比如a[i]='B',则'A'-a[i]=-1。正确应为++count[a[i]-'A']。
题意为输入设定全是大写 (ASCII码A-Z为65-90,递增):
- 如果count存储A-Z的个数,即count[0]存储A的个数,于是 ++count[a[i]-‘A’]; 'A’+i,count[i];
- 此题的存储顺序是反的,即count存储Z~A的个数,即count[0]存储Z的个数,于是 ++count[‘Z’-a[i]]; ’Z’-i,count[i]。
2. 考察指针*p和引用&b
已知int占4个字节,bool占1个字节;问value, condition 的值为__1024, 0 __.
unsigned int value = 1024; bool condition = *((bool *)(&value)); if (condition) value += 1; condition = *((bool *)(&value)); if (condition) value += 1; condition = *((bool *)(&value));
&value:获取整型value的地址
(bool *) (&value):把 &value 指针 强转为 bool型指针 bool*
*( (bool *) (&value) ):外面再嵌套一个*(),获取bool指针指向的值
bool 占1个字节,1个字节=8位二进制,就是取整型1024转化为二进制后的后8位。
因为1024 的后8位都是0, 所以 condition为false,后面的条件语句没执行,value值不变。
- “地址”运算符&:用于获得一个对象的地址
-
int x=7; &y=x; //引用b存的是x的别名,即y和x在内存占有同一个存储单元
- “内容”操作符*:一元运算符;也可被用于赋值操作的左侧
-
int x=7; int *pi=&x; //int指针pi:存储整型变量x的地址 double e=2.71828; double *pd=&e; //double指针pd:存储双精度变量e的地址 cout<<*pi<<"\n"; //输出整数7 *pi=27; //正确:可将27赋予pi指向的int pi=27; //错误:不能将一个int赋予一个int* *pd=*pi; //正确:可将一个int (*pi)赋予一个double (*pd) int i=pi; //错误:不能将一个int*赋予一个int
3. 考察x++和++x
- x++:先输出再自加;++x:先自加再输出 (就按照显示的顺序记即可)
问:以下输出结果为 12353514 .
main() { int m=12,n=34; printf("%d%d",m++,++n); printf("%d%d\n",n++,++m); }
m++,++n --> 先输出m=12,m再自加1,此时m为13;先自加1,再输出n=35;即输出1235。
n++, ++m --> 先输出n=35,n再自加1,此时n为36;先自加1,再输出m=14;即输出3514。
JAVA:
1. 考察JVM(Java Virtual Machine) JAVA虚拟机内存的五大区域:
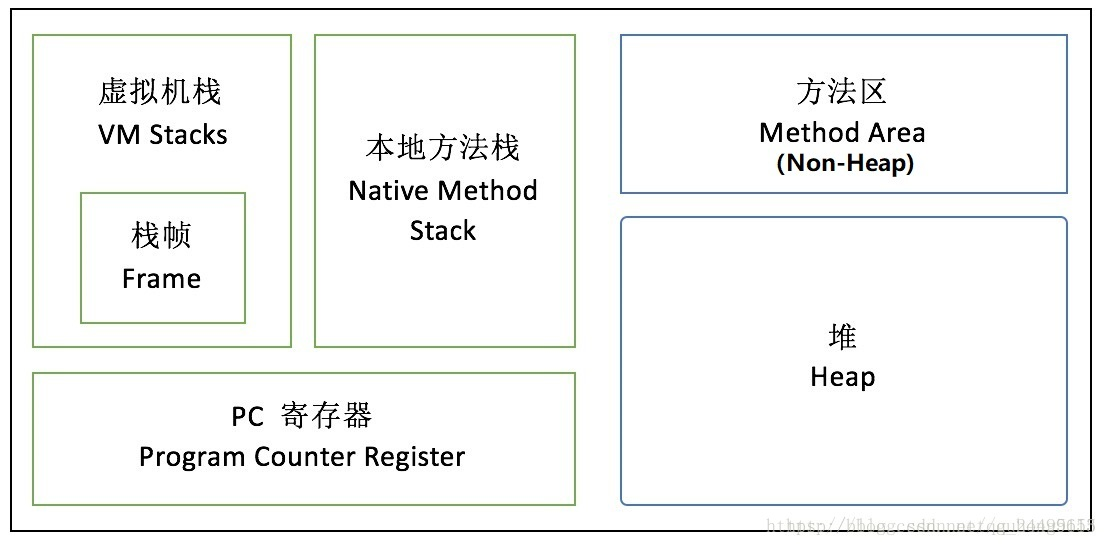
- 两个栈,其中一个包含栈帧
- 一个程序计数器
- 一个堆Heap
- 一个非堆
问题:JVM内存不包含如下哪个部分( d )
a) Stacks
b) PC寄存器
c) Heap
d) Heap Frame
2. 考察哈希冲突的解决和JAVA中的实现
java8中,下面哪个类用到了解决哈希冲突的开放定址法 ()
哈希冲突:
不同数据元素的关键字通过哈希函数H计算可能得到相同的哈希地址
即key1!=key2,但H(key1)=H(key2)
处理哈希冲突主要是2类:
a) 开放地址法 --> JAVA实现:HashMap
以$p_0$为基础,按照某种方法生成新的哈希地址$p_1$,直到$p_k$不再发生冲突
$$p_i=(p_0+d_i)%m$$
根据增量序列$d_i$的不同,可以分为
线性探测法:$d_i=1,2,3,...,m-1$;总能探测到哈希表的空闲地址;但容易发生"聚类"现象:哈希地址不同的关键字试图占用同一个新的地址单元,处理同义词冲突时加入了非同义词冲突;
平法探测法:$d_i=1^2, -1^2, 2^2, -2^2, ..., +k^2, -k^2 (k<=m/2)$;避免“聚类”现象,但不一定能探测到哈希表的空闲地址。
b) 拉链法 --> JAVA实现:ThreadLocal
构建哈希函数(用除留余数法),用链表存储;从单链表的头指针开始依次向后查找
| 开放地址法 | 拉链法 | |
| 存储空间 | 无多余指针域,存储效率高 | 附加指针域,低 |
| 查找 | 可能存在“聚集”现象,查找效率低 | 高 |
| 插入或删除 | 不易实现 | 易于实现 |
| 使用情况 | 哈希表的长度固定 | 长度不固定 |
3. 考察JAVA并发
可见性:
背景:
可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉。
通常,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有时甚至是根本不可能的事情。
为了确保多个线程之间对内存写入操作的可见性,必须使用同步机制。
定义:
可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。
也就是一个线程修改的结果,另一个线程马上就能看到。
举例:
比如:用volatile修饰的变量,就会具有可见性。
volatile修饰的变量不允许线程内部缓存和重排序,即直接修改内存。所以对其他线程是可见的。
但是这里需要注意一个问题,volatile只能让被他修饰内容具有可见性,但不能保证它具有原子性。
比如 volatile int a = 0;之后有一个操作 a++;这个变量a具有可见性,但是a++ 依然是一个非原子操作,也就是这个操作同样存在线程安全问题。
实现:在Java中volatile、synchronized和final实现可见性。
原子性:
背景:
非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。
定义:
原子是世界上的最小单位,具有不可分割性。一个操作是原子操作,那么我们称它具有原子性。
举例:
原子操作:a=0; a非long和double类型,这个操作是不可分割的;
非原子操作:a++; 这个操作实际是a=a+1,是可分割的。
实现:
java的concurrent包下提供了一些原子类,可通过阅读API来了解这些原子类的用法。比如:AtomicInteger、AtomicLong、AtomicReference等。
在Java中synchronized和在lock、unlock中操作保证原子性。
有序性:
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,
volatile是因为其本身包含“禁止指令重排序”的语义;
synchronized是由“一个变量在同一个时刻只允许一条线程对其进行lock操作”这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行执行。
- volatile:a.易变的;synchronized:a.同步的
- volatile是线程同步的轻量级实现,所以volatile性能肯定比synchronized要好,并且只能修改变量;多线程访问volatile不会发生阻塞;能保证数据的可见性,但不能保证原子性;解决的是变量在多线程之间的可见性
- synchronized可以修饰方法,以及代码;会出现阻塞;可以保证原子性,也可以间接保证可见性,因为它会将私有内存和公共内存中的数据做同步;解决的是多线程之间资源同步问题
问题:下列说法正确的是 .
a) volatile,synchronized都可以修改变量,方法以及代码块(×) --> volatile只能修饰变量
b) volatile,synchronized 在多线程中都会存在阻塞问题 (×) --> volatile不会出现阻塞
c) volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性 (√)
d) volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性 (×) --> volatile解决的是多个变量的可见性,不能保证原子性
Python:
1. 考察在函数内部定义另一个函数
问题:以下代码的输出为 .
def adder(x): def wrapper(y): return x + y return wrapper adder5 = adder(5) print(adder5(adder5(6)))
构成闭包:
- 内函数wrapper:用了外函数adder的临时变量x;
- 外函数的返回值:内函数的引用
一般情况:函数结束时,内部所有东西都释放掉,还给内存,即临时变量也会消失。
特例:外函数在结束时,发现自己的临时变量将来会在内函数中用到,就将这个临时变量绑定给了内函数,然后自己再结束。这里adder5=adder(5),即外函数adder将临时变量5绑定给了内函数,所以
adder5(1) >> 5+1=6
adder5(2) >> 5+2=7
adder5(6) >> 5+6=11
adder5(adder5(6)) >>(5+6)+5=16
2. 考察Python中的复数
- 实数部分和虚数部分组成:均为浮点数;虚数部分后缀为j或J
- 纯虚数也必须和一个值为0.0的实数部分组成;
- 举例:6.23+1.5j; -.022+0j; 0+1J
- 方法conjugate返回复数的共轭复数
3. 考察Python的数据类型:不可变的是 元组tuple .
4. 考察import其他模块
print_func.py如下:
print('Hello World!') print('__name__value: ', __name__) def main(): print('This message is from main function') if __name__ =='__main__': main()
print_module.py如下:
import print_func print("Done!")
问:运行print_module.py的结果 .
当运行自身模块的时:__name__等于“__main__”;
如果import到其他模块中,则__name__等于模块名称(不包含后缀.py)
所以该题结果是
Hello World!
__name__ value: print_func
Done!
4.
分布式集群:
1. 考察Zookeeper
问题:Zookeeper在 config 命名空间下,每个znode最多能存储 1M 数
参考:ZooKeeper详解 https://zhuanlan.zhihu.com/p/72902467
zookeeper 就是动物园管理员:
- 用来管 hadoop(大象)、Hive(蜜蜂)、pig(小 猪)的管理员;
- 一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目;
- 配置管理、名字服务、分布式锁、集群管理
- 存储结构:树形结构;节点:znode(4种类型) ,一个跟 Unix 文件系统路径相似的节点,存储或获取数据
- 默认1MB 的数据(对于记录状态性质的数据来说,够了)
2. 考察串行程序并行化设计步骤
含义:将工作进行拆分,使得分布在每个进程中的工作量大致相仿,并行让它们之间的通信量最少
步骤:
1->3->4->2
机器学习:
1. 考察模型分类( 2次考察!)
- 判别式模型(Discriminative Model):直接对条件概率p(y|x)进行建模;常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
- 生成式模型:更普适;关注数据是如何产生的,寻找的是数据分布模型;可以产生判别式模型
- 判别式模型:更直接,目标性更强;关注的数据的差异性,寻找的是分类面;不可以产生生成式模型
问题:以下哪个模型是生成式模型:
a) 贝叶斯模型 --> 生成式模型
b) 逻辑回归 --> 判别式模型
c) SVM --> 判别式模型
d) 条件随机场 --> 判别式模型
2. 问题:以下是产生式模型的机器学习算法为:
a) LR --> 逻辑回归,判别式模型
b) SVM --> 支持向量机,判别式模型
c) 神经网络 --> 判别式模型
d) 隐马尔科夫 HMM --> 生成式模型
3. 考察有监督/无监督学习分类
- 聚类:都是无监督学习
- 谱聚类:求前k个最小的特征值对应的特征向量;建立在谱图理论基础上,与传统的聚类算法相比,能在任意形状的样本空间上聚类且收敛于全局最优解的优点;
- 降维:
- PCA:无监督,基于最小投影距离,求前k个最大的特征值对应的特征向量,将方差最大的方向作为主要特征;
- 线性判别LDA:有监督,投影后类内方差最小,类间方差最大;
- 相同点:都利用矩阵特征分解思想;都假设数据符合高斯分布;
- 不同点:PCA无监督,能降到任意维,选择样本点投影具有最大方差的方向;LDA有监督,只能降到类别数k-1维,选择分类性能最好的投影方向,还能用于分类
- NLP:
- 主体模型LDA:无监督的贝叶斯模型;仅有数据输入,没有数据输出;举例HR看简历,新手HR通过不断地看简历(学习过程)来猜测一份简历的好坏,但是简历中只包括各种特征,并不包括简历的好坏。
4. 考察精确率&召回率
- 精确率Precision=TP/(TP+FP)
- 召回率Recall=TP/(TP+FN)
- F1值=2*P*R/(P+R)=2TP/(2TP+FP+FN)
问题:以下关于准确率,召回率, f1-score说法错误的是
a) 准确率为TP/(TP+FP) (√)
b) 召回率为TP/(TP + FN) (√)
c) f1-score为 2TP/(2TP + FP + FN) (√)
d) f1-score为 准确率*召回率/(准确率+召回率) (×) --> 少了2倍
5. 考察ROC曲线
- ROC曲线越靠近左上,越好
- ROC曲线下方的面积越大,则模型越好;AUC:Area Under Curve
- AUC值:
- 一个概率值,随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率;
- AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
- 只考虑所有样本的结果的统计值,不考虑正负样本的分布。
问题:若一个学习器的ROC曲线被另外一个学习器低的曲线完全“包住”,则断言后者的性能优于前者;若两个学习器的曲线出现交叉,该如何处理最为合适?
a) 比较ROC曲线线上的面积 (×)--> 是ROC曲线线下的面积
b) 使用AUC进行比较 (√)
c) 目测进行判断
d) 通过其他方法判断两个学习器的优劣
6. 考察数据抽样的假设
随机抽样一致算法(random sample consensus,RANSAC):采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。
基本假设:
a)“内群”数据可以通过几组模型的参数来叙述其分布,而“离群”数据则是不适合模型化的数据。
b) 数据会受噪声影响,噪声指的是离群,例如从极端的噪声或错误解释有关数据的测量或不正确的假设。
c) 给定一组(通常很小)的内群,存在一个程序,这个程序可以估算最佳解释或最适用于这一数据模型的参数。
算法过程:
a) 在数据中随机选择几个点设定为内群;
b) 计算拟合内群的模型;
c) 把其它刚才没选到的点带入刚才建立的模型中,计算是否为内群;
d) 记下内群数量;
e) 重复以上步骤多做几次;
f) 比较哪次计算中内群数量最多,内群最多的那次所建的模型就是我们所要求的解
应用场景:CV中,对应点问题、估算立体摄影机双眼相对点的基本矩阵
问题:对于RANSAC的基本假设描述不正确的是 .
a) 给定一组(通常很小)的内群,存在一个程序,这个程序可以估算最佳解释或最适用于这一数据模型的参数
b) 离群点离inliers集中区域的差距再可控范围内(×)
c) "内群”数据可以通过几组模型的参数来叙述其分别,而“离群”数据则是不适合模型化的数据
d) 数据会受噪声影响,噪声指的是离群,例如从极端的噪声或错误解释有关数据的测量或不正确的假设
7. 考察防止过拟合方法
- 正则化:对参数增加限制,即正则化惩罚项;
- dropout:神经网络训练时,让部分神经元失活,阻断部分神经元之间的协同作用;强制要求一个神经元和随机挑选出的神经元共同工作;
- 提前终止:观察训练模型在验证集上的误差,当在验证集上的误差不再下降时,说明过拟合,可以提前终止训练;
- 增加样本量:实在!
- (BN batch normalization 批正则化:本质是加快模型收敛速度,减轻过拟合;神经网络在归一化后,经过BN层,能在一定程度上还原成原始输入)
- bootstrap自采样:bootstrap n. 靴带;原样本借助自身的数据得出新的样本和统计量;有放回地全抽,进行N次,每次求一个相应的统计量,最后看统计量的稳定性
- 交叉验证:相当于重采样
参考:bootstrap自采样再理解 https://blog.csdn.net/iterate7/article/details/79740136
问题:下列方面不可以防止过拟合的是 .
a) 加入正则项 (√)
b) 增加样本 (√)
c) 建立更加复杂的模型 (×) --> 模型可能拟合到更复杂的过拟合函数上
d) Bootstrap重采样 (√)
8. 考察SVM支持向量机的支持向量
- 支持向量:和超平面$w^Tx+b=0$平行、保持一定函数距离的两个超平面对应的向量
- SVM模型:监督学习,所有的点到超平面的距离>一定距离,即所有的分类点要在各自类别的支持向量两边
问题:有如下两组数据 {(-1,0),(-1,2),(1,2)};{(0,0),(1,0),(1,1)}。在该数据集上训练一个线性SVM模型,该模型中的支持向量是 (-1,0), (1,2), (0,0), (1,1) .
画图,根据已知数据类,找直线
(注意:选项中(0,1):数据点(0,1)在支持向量(-1,0)和(1,2)构成的直线上,所以也可看作是支持向量。)
9. 考察最优化方法之间的差别
- GD(BGD,SGD, MBGD):梯度下降法,当前位置负梯度方向作为搜索方向
- BGD:更新参数时,用所有的样本进行更新;
- SGD:仅选一个样本来求梯度;
- MBGD:对m个样本,用x个样本来迭代
- 牛顿法/拟牛顿法
- 牛顿法:用函数$f(x)$的泰勒级数的前面几项来寻找方程$f(x)=0$的根,需要用二阶Heissen矩阵求解;用二次曲面拟合当前所处位置的局部曲面,在选择方向时,不仅考虑坡度是否够大,还考虑走了一步后,坡度是否会变得更大;
- 拟牛顿法:改善牛顿法中每次要求解Heissen矩阵的逆矩阵,用正定矩阵近似Heissen矩阵的逆
- 对比GD:收敛更快,但每次迭代时间更长
- 共轭梯度法:每一个搜索方向互相共轭,且这些搜索方向仅是负梯度方向与上一次迭代的搜索方向的组合;介于梯度下降法与牛顿法之间,仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点;适用:大型线性方程组、大型非线性最优化。
- 启发式优化:利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案;比如:模拟退火方法、遗传算法、蚁群算法以及粒子群算法。
问题:以下关于共轭梯度说法正确的是
a) 共轭梯度需要计算hessian矩阵的逆 (×) --> 牛顿法需要
b) 共轭梯度只需要一阶梯度即可,所以收敛速度较慢 (×) --> 克服GD收敛速度慢的问题
c) 共轭梯度法所需的存储量小,收敛快,稳定性高的优点 (√)
d) 共轭梯度梯度方向与最速下降法的梯度相同 (×) --> 不同
10. 考察随机森林
问题:关于随机森林的训练过程下列描述正确的是?
a) 样本扰动
b) 属性扰动
c) 样本扰动并且属性扰动(√)
d) 不存在扰动现象
11. 考察聚类算法的均值移动(Mean Shift)
参考:机器学习(十) Mean Shift聚类算法https://blog.csdn.net/hjimce/article/details/45718593
Mean Shift:基于核密度的爬山估计,求解一个向量,使球心位置$x$沿密度大的方向移动
$$x=x+M_h$$
$$M_h=\frac{1}{K} \sum_{x_i \in S_k} (x_i - x)$$
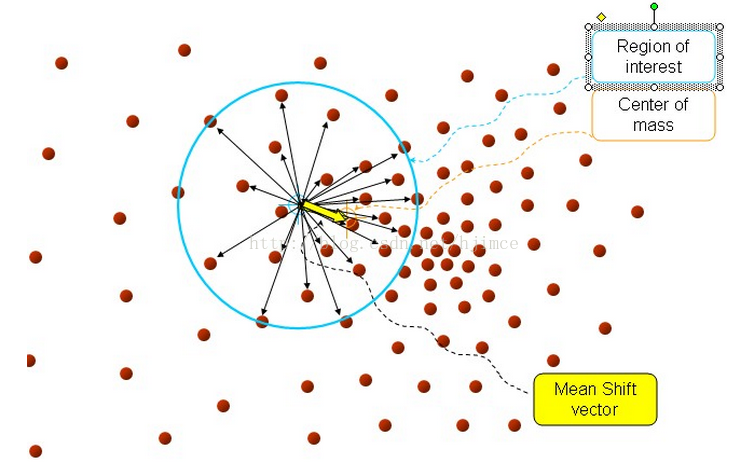
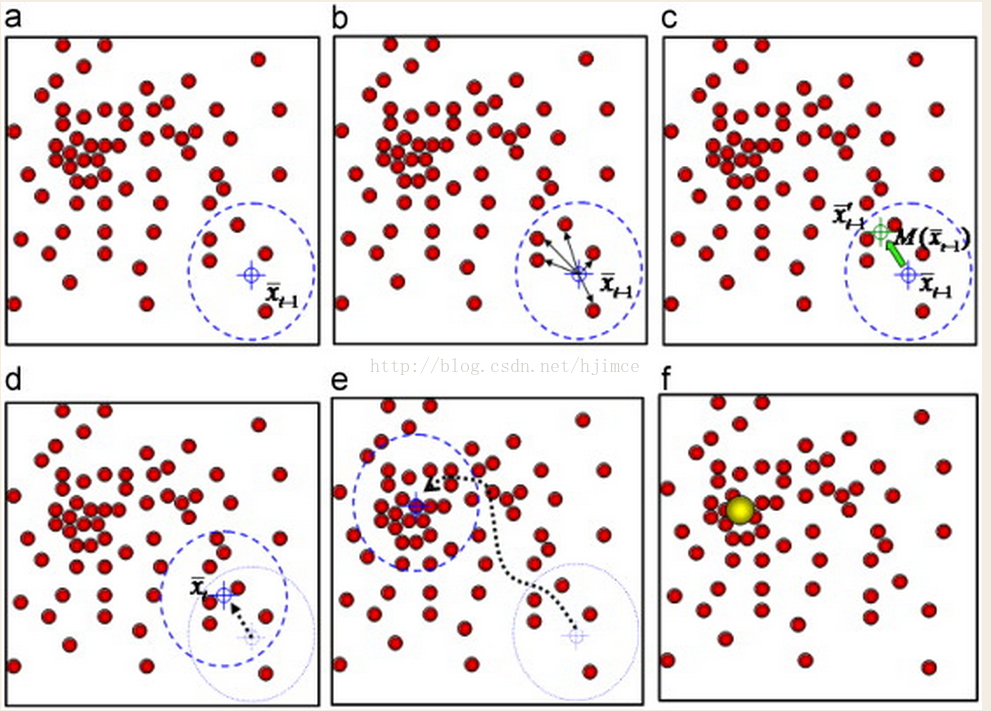
加入核函数,即加入一个高斯权重,使圆心每次在力的合成方向上。
问题:均值移动(Mean Shift)算法的核心思想是 .
a) 构建Hessian矩阵,判别当前点是否为比邻域更亮或更暗的点,由此来确定关键点的位置 (×)不是每个点都判断
b) 找到概率密度梯度为零的采样点,并以此作为特征空间聚类的模式点 (√)
c) 从每一个点开始作为一个类,然后迭代的融合最近的类。能创建一个树形层次结构的聚类模型(×) --> 不是树形层次结构
12. 考察人脸识别
问题:下列关于人脸识别技术说法不正确的是?
a) Adaboost算法可用于人脸检测(√)
b) 基于代数特征的表征方法主要是根据人脸器官的形状描述以及他们之间的距离特性来获得有助于人脸分类的特征数据(×)
c) 人脸识别技术中基于统计形变的校正理论可以优化人脸姿态 (√)
d) 人脸图像预处理包括光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等 (√)
13. 考察逻辑
问题:假设一种基因同时导致两件事情,一是使人喜欢抽烟,二是使这个人和肺癌就是()关系,而吸烟和肺癌则是()关系。
a) 因果;相关 (√)
b) 相关;因果
c) 并列;相关
d) 因果;并列
14. 考察NLP数据预处理
参考:自然语言处理时,通常的文本清理流程是什么?https://www.itcodemonkey.com/article/9361.html
- Normalization 规范化:小写转换和标点移除
- Tokenization 分词
- Stop words 无含义的词:例如‘is’,'our','the','in','at'等,词频高但无意义,需清除
- Part-of-Speech Tagging 标注词性:明确词之间的关系、识别出交叉引用
- Named Entity Recognition 名词短语识别:适用大型语料库,例如对新闻文章建立索引和进行搜索,可搜索自己感兴趣的公司的相关新闻。
- Stemming and Lemmatization :将词的不同变化和变形标准化。Stemming:将词还原成词干,利用简单搜索和替换样式规则,例如,后缀'ing'和'ed'可以丢弃,'ies'可用'y'替换;Lemmatization:将词还原成标准化形式的另一种技术,利用词典,将一个词的不同变形映射到它的词根,例如,is/was/were还原成be。
以下不是自然语言数据预处理过程的是?
a) 词汇规范化 (√)
b) 词汇关系统一化 (×)
c) 对象标准化 (√)
d) 噪声移除 (√)
15. 考察NLP数据预处理
问题:当在文本数据上训练一个机器学习模型,构建了一个输入数据的文档-单词矩阵。下面哪些方法可以用于降低数据维度?
a) 潜在狄利克雷分布(LDA) (√)
b) 潜在语义索引 (√)
c) 关键词规范化 (√)
16. 考察NLP
可以从新闻文本数据中分析出名词短语,动词短语,主语的技术是?
a) 词性标注
b) 依存分析和句法分析 (√)
c) N-Gram抽取
d) 词袋模型
存疑:不明白a)和b)的区别
17. 考察NLP
问题:社交媒体平台是文本数据最直观的表现形式。当给你一批社交媒体数据语料,如何创建一个模型显示标签?
a) 利用主题模型来获取语料库中最重要的单词
b) 训练一个N-gram词袋模型来获取top n-gram—单词和它们的组合
c) 训练一个词向量模型来学习文本表示
d) 其他几项都行 (√)
=============================
不定项选择题:
数据结构与算法:
1. 考察二叉树的遍历
问题:采用哪种遍历方法可唯一确定一棵二叉树
a) 给定一棵二叉树的先序和后序遍历序列 (×)
b) 给定一棵二叉树的后序和中序遍历序列 (√)
c) 给定先序、中序和后序遍历序列中的任意一个即可 (×)
d) 给定一棵二叉树的先序和中序遍历序列 (√)
- 注意:给定先序和后序,二叉树不唯一;
- 单选题会考给定先序+中序或者后序+中序,计算出二叉树结构。
C++:
1. 考察静态成员
问题:c/c++语言中,关于类的静态成员的不正确描述是 .
a) 静态成员不属于对象,是类的共享成员(√)
b) c++11之前,非const的静态数据成员要在类外定义和初始化 (√)
c) 静态成员函数不拥有this指针,需要通过类参数访问对象成员 (√)
d) 只有静态成员函数可以操作静态数据成员(×)
参考:C++静态成员的使用 https://blog.csdn.net/qq_35721743/article/details/87279546
C++中的静态成员:静态数据成员和静态成员函数
- 属于类所有,不属于类的对象;
- 与普通的成员相比,静态成员无this指针。
a) 静态数据成员
- 初始化:只能在类体外;不能在类内初始化或通过构造函数或初始化列表初始化;
- 引用:公有的静态数据成员:可以在类外通过类名直接引用,也可以通过对象名引用;
- 私有的静态数据成员:只能公用的成员函数引用。
-
class A{ public: static void print() { cout << "x="<<x << endl; //通过公有成员函数访问私有静态数据成员 } static int z; private: static int x; }; int A::z = 0; //类外初始化 int A::x = 0; //类外初始化 int main(){ A::print(); cout << "z=" << A::z << endl;//类外直接访问公用的静态数据成员 system("pause"); }
b) 静态成员函数
- 作用:主要用来访问静态数据成员,而不访问非静态成员,由于没有this指针,静态成员函数不能直接访问类的非静态数据成员;
- 如果一定要访问本类的非静态成员,应该加对象名和成员运算符"."
-
class A{ public: A(int x) :_x(x){} static void print(A a) { cout << "x="<<a._x << endl;//正确,静态成员函数不能直接访问非静态数据成员 cout<<"x="<<_x<<endl; //错误 } private: int _x; }; int main() { A a(10); A::print(a); system("pause"); }
2. 考察值类型、引用类型
问题:下面有关值类型和引用类型描述正确的是 .
a) 值类型的变量赋值只是进行数据复制,创建一个同值的新对象,而引用类型变量赋值,仅仅是把对象的引用的指针赋值给变量,使它们共用一个内存地址。 (√)
b) 值类型数据是在栈上分配内存空间,它的变量直接包含变量的实例,使用效率相对较高。而引用类型数据是分配在堆上,引用类型的变量通常包含一个指向实例的指针,变量通过指针来引用实例。 (√)
c) 引用类型一般都具有继承性,但是值类型一般都是封装的,因此值类型不能作为其他任何类型的基类。 (√)
d) 值类型变量的作用域主要是在栈上分配内存空间内,而引用类型变量作用域主要在分配的堆上。 (×) --> 落脚点在“作用域”
3.
操作系统:
1. 考察释放锁资源
问题:下列哪些操作会使线程释放锁资源?
a) sleep()
b) wait() (√)
c) join() (√)
d) yield()
释放锁资源:通知对象内置的monitor对象进行释放,所以前提是:所有对象都有内置的monitor对象;
所有类都继承自Object,所以wait()就成了Object方法,即通过wait()来通知对象内置的monitor对象释放;而且事实上因为这涉及对硬件底层的操作,所以wait()方法是native方法,底层是用C写的。
其他都是Thread所有,所以其他3个是没有资格释放资源的
join()有资格释放资源其实是通过调用wait()来实现的
sleep()方法
- 在指定时间内让当前正在执行的线程暂停执行,进入阻塞状态,但不会释放“锁标志”。不推荐使用。
wait()方法
- 在其他线程调用对象的notify或notifyAll方法前,导致当前线程等待。线程会释放掉它所占有的“锁标志”,从而使别的线程有机会抢占该锁。
- 当前线程必须拥有当前对象锁。如果当前线程不是此锁的拥有者,会抛出IllegalMonitorStateException异常。
- 唤醒当前对象锁的等待线程使用notify或notifyAll方法,也必须拥有相同的对象锁,否则也会抛出IllegalMonitorStateException异常。
- waite()和notify()必须在synchronized函数或synchronized block中进行调用。如果在non-synchronized函数或non-synchronized block中进行调用,虽然能编译通过,但在运行时会发生IllegalMonitorStateException的异常。
yield()方法
- 暂停当前正在执行的线程对象。
- 只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
- 只能使同优先级或更高优先级的线程有执行的机会。
join()方法
- 等待调用join方法的线程结束,再继续执行。如:t.join();//主要用于等待t线程运行结束,若无此句,main则会执行完毕,导致结果不可预测
2. 考察避免死锁
问题:如何在多线程中避免发生死锁 .
a) 允许进程同时访问某些资源。(√)
b) 允许进程强行从占有者那里夺取某些资源。(√)
c) 进程在运行前一次性地向系统申请它所需要的全部资源。(√)
d) 把资源事先分类编号,按号分配,使进程在申请,占用资源时不会形成环路。 (√)
- 对应死锁的4个发生条件
机器学习:
1. 考察XOR
(Exclusive-OR XOR)异或问题
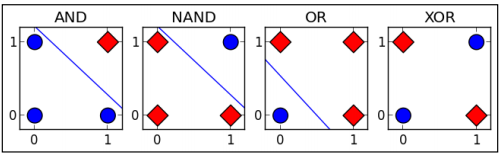
XOR问题不能通过线性模型解决
线性模型:LR,单层感知机;
非线性模型:2层感知机:1个输入层+1个隐藏层+1个输出层的神经网络;如果神经元个数足够多,通过非线性的激活函数可以拟合任意函数。
问题:以下说法正确的是:
a) XOR问题不能简单的用线性分类解决 (√)
b) XOR问题可以通过2层感知器解决 (√)
c) XOR可以通过LR模型解决 (×) --> 线性模型
d) XOR可以通过单层感知器解决 (×) --> 线性模型
2. 考察图模型分类
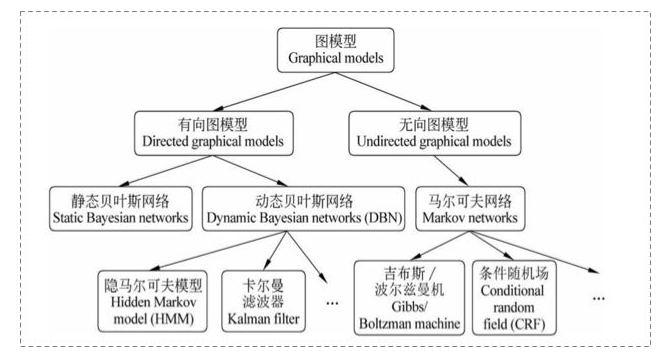
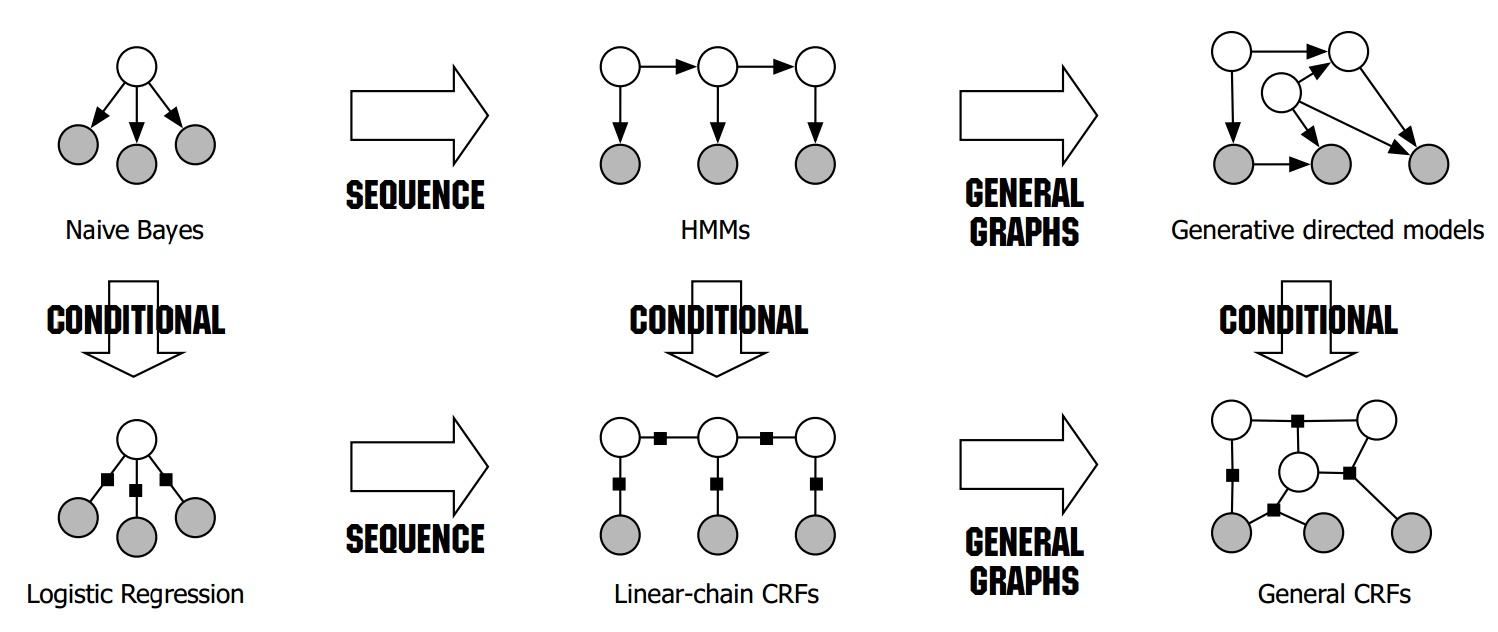
有向图:朴素贝叶斯 --> HMM --> Generative directed models
无向图:LR --> Linear-chain CRFs --> General CRFs
问题:以下模型哪些是无向图
a) 朴素贝叶斯 (×) --> 有向图模型
b) LR (√) --> 无向图模型,从朴素贝叶斯CONDITIONAL后,变成逻辑回归
c) CRF (√) --> 无向图模型,条件随机场
d) HMM(×) --> 有向图模型,从朴素贝叶斯序列化后变成隐马尔可夫链HMM
3. 考察图特征的降维方法
机器学习4大降维方法:
- 线性降维
- PCA:非监督
- LDA:监督
- 非线性降维
- LLE:Locally Linear Embedding,能够使降维后的数据较好地保持原有流形结构。
- LE:Laplacian Eigenmaps,也是从局部角度构建数据之间的关系,它的直观思想是希望相互间有关系的点(在图中相连的点)在降维后的空间中尽可能的靠近;可以反映出数据内在的流形结构。
突然发现自己学的专业,这个非线性降维方法就是一个很好的应用!
问题:以下是基于图的特征降维方法的是 .
a) LE(Laplacian eigenmap) (√)
b) LLE(local linear embedding) (√)
c) PCA (×)
d) KL (×)
- KL变换 Karhunen-Loeve Transform:是建立在统计特性基础上的一种变换,将离散信号变换成一串不相关系数的方法,应用于数据压缩技术。
4. 考察协同过滤模型
- 分类
- 基于用户(user-based):用户与用户之间的相似度 --> 找出相似用户喜欢的物品,并预测目标用户对应物品的评分 --> 将评分最高的若干个物品推荐给用户;
- 基于项目(item-based):找物品与物品之间的相似度;
- 基于用户:在线,计算复杂度高,可推荐有惊喜的物品;基于项目:离线,准确度一般可接受,但难有惊喜
- 基于模型(model-based):主流,一大堆机器学习算法的用武之地。目标是用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户
- 不足:
- 冷启动问题:没有历史数据
- 情景差异问题:基于用户所在场景和用户当前情绪
- 小众独特喜好:可以基于内容推荐
问题:协同过滤经常被用于推荐系统, 包含基于内存的协同过滤, 基于模型的协同过滤以及混合模型, 以下说法正确的是 .
a) 基于模型的协同过滤能比较好的处理数据稀疏的问题 (√)
b) 基于模型的协同过滤不需要item的内容信息 (×) --> 需要
c) 基于内存的协同过滤可以较好解决冷启动问题 (×) --> 不能
d) 基于内存的协同过滤实现比较简单, 新数据可以较方便的加入 (√)
5. 考察神经网络/激活函数
问题:协同过滤经常被用于推荐系统, 包含基于内存的协同过滤, 基于模型的协同过滤以及混合模型, 以下说法正确的是 .
a) 神经网络可以实现非线性分类 (√)
b) 神经网络可以实现线性分类 (√) --> 线性分类器就是一个单层神经网络
c) 神经网络的每层神经元激活函数必须相同 (×) --> 不用相同
d) 神经网络的每层神经元激活函数值阈必须在[-1,1] (×) --> Relu,值域范围就在[0,+inf)
- 激活函数还没有很清楚
6. 考察LR的数据误差
问题:使用LR来拟合数据, 一般随机将数据分为训练集和测试集。 则随着训练集合的数据越来越多, 以下说法正确的是 .
a) 测试集上的测试误差会越来越小 (√)
b) 测试集上的测试误差会越来越大 (×)
c) 训练集上的训练误差会越来越小 (×)
d) 训练集上的训练误差会越来越大 (√)
前提:测试数据不变,只增加训练数据
- 减少过拟合,泛化更好,测试误差变小;
- 训练集多样性增加,数据输入分布改变,训练误差变大。
7. 考察时序模型
问题:以下模型是时序模型的是 .
a) GRU (√)
b) LSTM (√)
c) RNN (√)
d) CNN (×)
- RNN(Recurrent Neural Network)递归神经网络:RNN被称为并发的(recurrent),是因为它以同样的方式处理句子中的每个字词,并且对后面字词的计算依赖于前面的字词。

- LSTM(Long Short-Term Memory)长短期记忆网络:LSTM是为了解决RNN中的反馈消失问题而被提出的模型,它也可以被视为RNN的一个变种。与RNN相比,增加了3个门(gate):input门,forget门和output门,门的作用就是为了控制之前的隐藏状态、当前的输入等各种信息,确定哪些该丢弃,哪些该保留。

- GRU(Gated Recurrent Unit)封闭复发性单位:GRU具有与LSTM类似的结构,但是更为简化。

问题:以下为防止过拟合的方法的是
a) 增加样本 (√)
b) L1正则 (√)
c) 交叉验证 (√)
d) 增加复杂特征 (×)
9. 考察BN
问题:以下关于batch normalization说法正确的是:
a) normalization的均值方差计算是基于全部训练数据的 (×)
b) normalization的均值方差只基于当前的minibatch (√)
c) normalization对输入层的每一维单独计算均值方差 (√)
d) normalization的输出分布服从均值为0,方差为1的高斯分布 (×) --> 输入保持0,1的正态分布,但是输出就不能保证了
- BN还要再看一下相关专题
10. 考察CRF模型的类别
- CRF Conditional Random Field条件随机场:从LR序列化后演变过来,所以LR是判别式模型、无向图,CRF也是判别式模型,无向图。
- LR逻辑回归是最简单的CRF模型,CRF相当于有多个输出。
问题:CRF模型可以用来做专名识别, 语义消歧等, 以下关于CRF模型说法正确的是
a) CRF模型是产生式模型 (×)
b) CRF模型是判别式模型 (√)
c) CRF模型的图模型为无向图(√)
d) CRF模型的图模型为有向图 (×)
11. 考察随机森林
参考:方差和偏差的区别 https://blog.csdn.net/baichoufei90/article/details/87886893
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力,$bias^2(x)=(\bar(f)(x)-y)^2$
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响,$Var(x)=E_D[(f(x;D)-\bar(f)(x))^2]$
- 噪声:度量了真实标记与数据集中的实际标记间的偏差,在当前任务上,任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度,$e^2=E_D[(y_D-y)^2]$

- 偏差-方差窘境 (bias-variance dilemma)
- 训练初期:由于训练不足, 学习器的拟合能力不够强,偏差比较大, 也是由于拟合能力不强, 数据集的扰动也无法使学习器产生显著变化, 也就是欠拟合的情况;
- 训练程度的加深:学习器的拟合能力逐渐增强, 训练数据的扰动也能够渐渐被学习器学到;
- 充分训练后,:学习器的拟合能力已非常强, 训练数据的轻微扰动都会导致学习器发生显著变化, 当训练数据自身的、非全局的特性被学习器学到了, 则将发生过拟合.
- 决策树:高方差、低偏差,即训练的模型精确,但常常在同一数据集中的不同数据样本之间显示出很大程度的变化
- 随机森林:
- 用训练数据的不同子集训练每个单独的决策树,用数据中随机选择的属性对每个决策树的每个节点进行分割。通过分割打乱元素,使其具有随机性。
- 创建彼此不相关的模型。这导致可能的误差均匀分布在模型中,意味着误差最终会通过随机森林模型的多数投票决策策略被消除
- 随机森林数据处理:
- 增加数据 --> 降低由数据的不稳定性所带来的方差;
- 增加模型复杂度 --> 降低偏差;
- 噪音是无法避免的
- 存疑:子树越多,方差越小,偏差越大??
问题:以下关于random forest说法错误的是
a) rf中的每棵子树都是独立同分布的 (×) --> 近似分布,但不独立(因为子样本集的相似性)
b) rf中模型方差随着子树的增加而减少 (√)
c) rf主要通过增加子树之间的相关性来减少模型的方差 存疑:答案是(√),但是 子树之间相关相关性越强,模型方差不一定减小,RF反而是通过D-C来处理子模型,降低子模型间的相关性,来降低方差
d) rf中模型偏差随着子树的增加而减少(×) --> 不一定减少,主要是为了降低方差
12. 考察正交矩阵
正交矩阵A:$AA^T$=E
13. 考察图像分析
问题:下列关于图像分析说法不正确的是?
a) 图像分析主要研究图像传输、存储、增强和复原(×)--> 图像处理
b) 图像分析主要研究点、线、面和体的表示方法以及视觉信息的显示方法(×)--> 计算机图形学
c) 图像分析研究构造图像的描述方法,更多地用符号表示各种图像(√)
d) 图像分析主要研究对图像内容的分析、解释和识别(√)
概率论:
1. 考察联合概率分布的期望和方差
问题:两个随机变量x,y,服从联合概率分布p(x,y), 以下等式成立的有
 (√)
(√)
 (√)
(√)
2. 考察二项分布
问题:以下关于二项分布说法正确的是
a) 二项分布是一种离散概率分布,表示在n次伯努利试验中, 试验k次才得到第一次成功的概率
b) 二项分布是一种离散概率分布,表示在n次伯努利试验中,有k次成功的概率 (√)
c) 当n很大时候,二项分布可以用泊松分布和高斯分布逼近
d) 当n很大时候,二项分布可以用高斯分布逼近,但不能用泊松分布逼近 (√)
问题:以下属于凸函数的是 .
a) e的x次方 (√)
b) x的a次方
c) log(x)
d) f(x, y) = x的平方/y (√)
- 判断是否为凸函数
- 一元函数:$f^{''}(x) >=0$
- $(e^x)^{''}=e^x$
- $x^a$,如果a=0,那就直接不是
- $(log(x))^{'}$=$\frac{1}{x} lna$,以a为底;$(log(x))^{''}$=$-\frac{1}{x^2} lna$<0,所以不是凸函数
- 二元函数:Heissen矩阵正定
- $\frac{\partial^2f}{\partial x^2}=\frac{2}{y}$;$\frac{\partial^2f}{\partial y^2}=\frac{x^2}{y^3}$;$\frac{\partial^2f}{\partial x \partial y}=\frac{-2x}{y^2}$;det(Hess)=$\frac{2x^2}{y^4}+\frac{4x^2}{y^4}$ >0,所以$f(x)=\frac{x^2}{y}$是凸函数
- 一元函数:$f^{''}(x) >=0$
=============================
编程题
1. 有一个含有n个数字的序列,每个数字的大小是不超过200的正整数,同时这个序列满足以下条件:
$a_1$<=$a_2$
$a_n$<=$a_(n-1)$ (此时n>2)
$a_i$<=max($a_(i-1)$,$a_(i+1)$)
但是很不幸的是,在序列保存的过程中,有些数字丢失了,请你根据上述条件,计算可能有多少种不同的序列可以满足以上条件。
示例:
输入:3
2 0 1
输出:1
2. 东东从京京那里了解到有一个无限长的数字序列: 1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, ...(数字k在该序列中正好出现k次)。东东想知道这个数字序列的第n项是多少,你能帮帮他么?
分析:一道简单的数学题,主要在于优化。
n= 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,...
1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5,...
可以看到,当n=10时,10=1+2+3+4
3. 东东对幂运算很感兴趣,在学习的过程中东东发现了一些有趣的性质: 9^3 = 27^2, 2^10 = 32^2
东东对这个性质充满了好奇,东东现在给出一个整数n,希望你能帮助他求出满足 a^b = c^d(1 ≤ a,b,c,d ≤ n)的式子有多少个。
例如当n = 2: 1^1=1^1
1^1=1^2
1^2=1^1
1^2=1^2
2^1=2^1
2^2=2^2
一共有6个满足要求的式子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号