Java语言重点章节学习笔记
该博客主要使用的参考书目为 Java编程思想. 主要看的内容是 集合, 并发, 类加载/反射, 字节码, 线程同步, GC
对应书本章节为: 14章 15章 17章 19章 20章 21章
书本相对于PDF的页面数量为 书本页码 + 15 = pdf页码
14 类型信息 P313 ~ P350
Java中关于在运行过程中获取对象的类型和类的信息有两种方式: Rtti 和 反射. 这里的RTTI主要指的是对于一个Object对象获取其实际的类型, 反射则是对于类型获取其字段和函数
14.1 为什么需要RTTI
因为Java的类型转换都是在运行中进行类型检查, 所以需要RTTI进行对象类型的识别. 另外对于Java的多态机制, 由于需要对于一个对象获取其需要执行的代码, 所以需要使用RTTI机制进行类型的获取
14.2 Class对象
Class对象是RTTI在实现中的表示方式. 在Java中对于每个类型都会创建一个Class对象, 该Class对象是被保存在于类同名的.class文件中.
类的加载: 类型的加载是由JVM中名为类加载器的子系统进行实现的. 类加载器的子系统是由一条加载器链组成的. 以从Java原生类到用户自定义类的顺序进行类型的加载. 通常情况下该加载器链不需要自定义加载器, 但是如果需要以一些特殊方式加载类型, 则需要手动挂接类加载器
所有的类都是在对其第一次使用时动态加载到JVM中的. 这里的第一次使用一般指的是静态对象(如构造函数)
在加载的过程中, 类加载器会检查一个类的Class对象是否已经被加载, 如果没有被加载则会根据类名寻找对应的.class文件, 将该.class文件载入内存之后就会使用该Class对象创建该类的所有对象.
这里的.class文件就是Java的字节码.
Class对象是仅在类型被需要的时候进行加载, 类型中的static子句则是在类加载过程中进行执行
基于类型名称的Class对象获取: Class.forName("类型名称 -- 包含大小写"). 如果该输入名称的类型没有被加载, 则其会寻找字节码并进行加载, 如果找不到需要加载的类型, 则会报出ClassNotFoundException. 注意进行forName类型获取的时候需要输入全限定名. 也就是包含包名和类名
基于对象获取其对应的Class对象: Object.getClass()
Class对象的功能: 能够获取类型名称, 是否为接口, 其继承了哪些接口等基本信息
Class对象一些常用的功能函数:
getSimpleName();
getCanonicalName();
isInterface();
getInterfaces();
getSuperClass();
newInstance();
由.class文件到Class对象的三个步骤
- 加载: 由类加载器查找字节码位置, 并从该字节码中创建一个Class对象
- 链接: 对于字节码的安全性进行验证, 为类型的静态域分配空间, 解析该类型创建的对于其他类型的引用 (递归的创建其所引用的所有其他类型)
- 初始化: 如果该类型具有超类则对其进行初始化, 执行静态初始化器, 和静态初始化块
Note: 加载和链接是在读取.class文件后直接运行的, 初始化步骤是再对静态方法或者是非常数静态域进行首次引用时执行的
JVM对于Class对象的初始化遵循尽可能惰性的初始化策略. 直接使用CLASSNAME.class不会进行初始化, 但是如果使用.forName进行Class引用的产生则进行了Class的初始化.
对于不同字段的访问域: static final字段一般是编译期常量, 不需要对Class对象进行初始化就可以读取, 但是如果是static字段则在访问之前需要进行链接和初始化
14.2.2 泛化的Class对象
可以认为Class对象是用于构建类型实例的单例对象. Class的实例是表示其所指向的对象的确切类型, 该实例本身是Class类型的一个实例.
为了显式的标记该Class实例指向的是哪一个类型, Java中除了支持Class类型以外, 还支持Class<T>类型. 泛型化的Class类型相比于没有泛型化的Class类型是强制编译器进行额外的类型判断
在使用泛型Class的情况下进行一定程度的通配: Class<?>可以使用?作为通配符匹配所有类型. 其意义上和没有泛型的Class类型是等价的, 但是其意味着用户不是在不知情的情况下使用非具体的类型引用, 而是在有意识的使用非具体的类型引用
使用通配符进行类型间关系的匹配和传输: (注意: 所有这些检查都是在编译时期的类型检查)
Class<? extends Number> numberClass = int.class;
numberClass = double.class;
numberClass = Number.class;
由于newInstance的类型的模糊性所以newInstance返回值是Object
Class<FancyToy> ftClz = FancyToy.class;
Class<? super FancyToy> upperClz = ftClz.getSupperClass();
Object obj = upperClz.newInstance();
14.2.3 使用Class的新的转型语法
这种转型语法并不常用, 但是可以用以参考
Building b = new House();
Class<House> houseType = House.class;
House h = houseType.cast(b);
// 上面三行等效于以下一行
h = (House)b;
另外还有更加不常用的接口如 Class.asSubclass
14.3 类型转换前进行检查
目前已经看到的RTTI表现形式有以下几种:
A a = (A) b;如果无法被正常转换则会报出ClassCastExceptionClass<A> clz = A.class;使用Class类型的对象表现一个类型a instanceof A;使用关键字返回一个是否为特定类型实例的布尔值
基于Class对象的一些有趣的应用: 可以在字段中创建List<Class<? extend X>>可以获取一个类的所有实现并根据实际情况选择类型进行实例化. 这是一种特殊的泛型实现方式 — 由开发人员手动管理泛型变量而不是由编译器进行自动管理.
相比较Class而言instanceof是一个更加严格的限制, 其只允许和在编译节点定义好的类型名称进行比较, 不允许对Class变量进行比较. 由于instanceof表明程序员没有将对于类型的限制完全的展现在外部, 所以当一个程序中过多使用instanceof的时候表明该程序的外在需求和实际需求距离相差很大. 也就表明该程序在结构设计上有缺陷.
14.3.1 使用类字面常量
类字面常量指的是在代码中hardcode类型名称. 其优势在于类型名称在编译阶段就可以得到检查, 所以不会出现还需要进行异常处理的情况
14.3.2 动态的instanceof
使用Class.isInstance(Object)是和静态instanceof意义一致的. 其和instanceof的差别在于后者只能使用类型字面常量进行定义, 但是前者可以使用Class对象对于类型进行定义, 其使用范围更广, 使用方式更加灵活
其主要使用范围是类型列表会随着时间进行改变, 需要在不同阶段下使用不同类型列表的情况
14.3.3 递归计数
由于依赖树的树状图结构, 且从子类到父类的单一继承结构, 所以可以使用递归的方式由子类到父类进行递归, 在每层递归中可以对当前对象进行对应任务的处理
14.4 注册工厂
这是一个使用了RTTI的设计模式, 是对于传统工厂的修改. 由于传统工厂只能生产固定类型的对象, 当出现新增的类型的时候需要对传统工厂的代码进行修改.
在注册工厂中, 将所有子类的工厂以一个工厂注册列表的形式维护在父类工厂中, 使得在进行新增子类的时候只需要在工厂注册列表中添加新的工厂信息即可. (将工厂类型和工厂的调用进行解耦, 使得能够保证新增类型的时候不需要修改其他函数)
14.5 instanceof和Class的等价性
这一部分是描述使用instanceof和直接比较两个Class对象之间的差异
目前有三种类型比较的方式: instanceof, Class.isInstance, Class equal
其中instanceof和Class.isInstance返回true的条件是对象完全是指定类型或者是指定类型的子类. 但是Class.equal则并不是这样, Class.equal只考虑对象完全是指定类型, 而没有考虑对象是否是指定类型的子类.
class A{}
class B extends A {}
public class Main{
public static void main(String[] args){
B b = new B();
b instanceof A; // true
A.class.isInstance(b); // true
A.class.equals(b.getClass()); // false
}
}
14.6 反射: 在运行时获取类的信息
RTTI的局限在于, 类型的信息在编译时必须可知, 如果你获取了一个并不在当前程序空间中的类型的对象的引用, 则会导致报错.
在基于构建的编程环境中会使用一些快速应用开发(RAD)构建工具,(其一般指的就是集成开发环境或者可视化编程环境). 在这些环境中需要能够对一个组件的接口和属性进行配置, 能够在尚未运行的时候暴露组件的一些接口和信息用于用户配置
另一个需要使用到反射的环境是希望提供跨网络的远程平台上创建和运行对象的能力, 这种设计方式一般被称为远程方法调用(RMI), 其能够支持将一个Java程序对象分布在多台机器上.
反射使用Class类型和java.lang.reflect库一起进行支持的, 该类库包含了Field, Method, Constructor类型, 以及Member接口. 这些类型的对象是由JVM在运行时进行创建的, 用来表示一个未知类型中的成员. 其能够帮助我们使用Constructor进行类型的实例化, 使用get,set方式对于字段内容进行设置和读取, 以及通过invoke进行方法的调用.
反射类型的工作流程: 当接触到一个未知类型的对象的时候, JVM通过类似RTTI检查的方式检查该对象的Class信息, 然后加载该Class对象, 后续关于对于类型字段, 功能等的操作都是在获取了Class对象之后进行的.
反射和RTTI的核心区别: 对于RTTI而言, 其Class对象是在编译时期生成的, 需要能够在编译时期查看对应.class文件. 对于反射机制而言, .class文件在编译时是不可获取的, 而是在运行时动态的进行.class文件的加载和内容的获取
14.6.1 类方法提取器
一般而言做简单代码开发的时候是不需要使用反射机制的, 但是其是其他一些高级特征的重要支撑(例如对于对象的序列化以及JavaBean的处理)
类方法提取器指的是对于一个对象自动获取其构造函数和方法函数的功能代码, 该功能一般使用在IDE中. 该功能是直接通过Class.forName进行类型的获取和加载, 然后使用反射列出其所有函数和构造函数
14.7 动态代理
动态代理是对于代理设计模式的一个反射化的改动. 代理是为用户提供相较于实际对象接口外更多的操作, 通过作为一个中间人的角色和目标对象进行通信
该设计模式的意义在于将额外操作和实际操作的对象进行拆分, 能够在不修改底层逻辑的情况下修改上层接口
动态代理相比于传统代理的区别在于其能够动态地创建代理并动态地处理所代理方法的调用
传统的代理的一种实现方式是将工作类和代理类同时实现同一个接口, 代理类中保有一个接口的字段, 用于存放任何实现了该接口的对象, 然后再每个符合接口的函数中对于工作类进行调用 – 可以手动对于接口添加预处理和后处理.这一点在Spring中是通过了AOP的方式进行实现了的
对于这里动态代理的内容我看的不是太懂, 但是基本功能是通过ClassLoader进行类型加载然后进行消费. 实现比较复杂. 通过反射进行方法的过滤, 可以选择特定的函数进行调用
动态代理由于可以支持不同接口的执行, 所以可以用于对于操作的事务性包装, 当出现异常的时候可以对外部内容进行回滚
14.8 空对象
很少涉及到空对象的概念, 该概念在java中一般是通过null值进行展现的, 但是在一些需要更加显式判断是否是空或者是对于空对象和有值的对象有明显逻辑区别的时候应当定义并使用空对象.
public interface Null{}
public class Person{
String name;
public Person(String name){this.name = name;}
public static class NullPerson extends Person implements Null{
public NullPerson(){super("None");}
}
public static final Person NULL = new NullPerson(); // 定义全局常量的Null值
}
public static void main(String[] args){
Person p = //...
if(p.equals(Person.NULL)){ // 使用这种形式进行为空的判断
// ...
}
}
使用空对象的价值在于对于一些情况下可以不用判断其值是否为null. 例如对于toString方法而言, 不需要在调用该方法之前确认对象是否为空, 这样可以避免进行没有必要的检查以及使得打印出的信息更加可读
可以将动态代理和空类型进行合并使用, 在需要创建一个类型的空类型的时候, 传入该类型的信息令代理器自动根据父类和接口进行NULL值的搜索和获取
14.8.1 模拟对象和桩
空对象的逻辑变体就是模拟对象和桩, 模拟对象和桩都表示最终程序中的使用的实际对象. 相比于空对象, 模拟对象和桩更加智能, 而不是仅限于替代null的作用
这两个概念之间的区别在于模拟对象一般是较为轻量级的, 一般是用于进行测试的数据常量
桩一般是重量级的, 而且经常在测试之间被复用, 可以通过配置接口进行配置.
14.9 接口与类型信息
接口并不是代码解耦的最佳方式: 因为即使使用接口承接了一个类型变量, 但是客户还是可以使用instanceof的判断和强转型将该类型变量的类型转化为其实际的类型. – 虽然形式上使用了接口降低了耦合, 但是由于用户的强转导致实际的耦合程度高于了预期. (导致为了维护这些不在预期之内的耦合,耗费大量的精力)
对于这一个问题的一种解决方式是通过包访问权限进行限制, 使得用户在外部无法访问被承接的类型. 这种解决方法虽然一定程度上的解决了问题, 但是如果用户使用javap进行名称获取以及使用反射进行功能的访问, 还是能够访问到对应的被隐藏的接口.
所以对于反射而言, 所有试图隐藏的接口和字段都是可以访问的. (注意: final字段可以在不抛出异常的情况下 保证不会被修改)
14.10 总结
反射的意义在于: 在传统限制死的层次化访问限制以外提供了能够绕过这些限制的手段. 虽然反射不应当被频繁使用, 但是对于一些特殊需求, 使用反射可以优雅地进行实现.
反射某种程度上可以用于避免父类的过度臃肿(将一些特殊功能写在子类中, 通过RTTI和反射的方式进行调用)
Java的RTTI和反射造成的动态代码是将Java和C++之类语言区分的最重要因素之一
15 泛型 P352 ~ P432
一般的类型和方法只能用于具体的类型, 如果需要编写面向多种类型的代码, 传统的刻板的限制对实现的束缚就很大, 所以需要出现泛型使得类型能够为多种其他类型提供支持.
泛型的设计目的是使得类型能够为其他不具体的类型提供服务
泛型的实现是通过参数化类型, 通过在参数中定义类型信息, 使得编译器可以在编译阶段就进行转型并确保类型的正确性.
Java的泛型相较于C++的泛型是相对局限的, 其有些功能无法使用泛型实现
15.1 与C++的比较
与C++进行对比了解Java泛型的生成历史, 并且了解Java泛型的功能边界. 在进行编程的时候只有了解了边界在哪才能避免在死胡同中乱转
15.2 简单泛型
促成泛型的出现的一个最重要的原因是容器类的出现. 由于容器中一般只有固定类型的数据, 使用泛型让编译器保证输入数据类型的正确性
15.2.1 一个元组类库
元组类库的起源是因为对于返回值限定只有一个的情况. 通过将返回值设置为指定类型的元组对象可以通过传出多个参数.
public class TwoTuple<A,B>{
public final A a;
public final B b;
public TwoTuple(A a,B b){
this.a = a;
this.b = b;
}
}
public class ThreeTuple<A,B,C> extends TwoTuple<A,B>{
public final C c;
public ThreeTuple(A a, B b, C c){
super(a,b);
this.c = c;
}
}
15.2.2 一个堆栈类
通过私有的Node泛型类存储节点, 在外部的Stack类中将Node聚合为LinkedList进行FILO. 通过在堆栈最底层创建一个末端哨兵的阶段用于判断堆栈中是否已经没有数据
15.2.3 RandomList
这是一个存储了数据的列表, 当调用select的时候随机返回一个值.
15.3 泛型接口
泛型除了应用在类型上还可以应用在接口上.
例如使用泛型接口定义一个生成器. 在生成器接口中只需要定义一个用于生成对应类型对象的方法, 例如next()
public class Test{
// ...
}
public interface Generator<T> {
T next();
}
public TestGenerator implements Generator<Test>{
Test next(){
return new Test();
}
}
public Fibonacci implements Generator<Integer>{
Integer next(){
// ...
}
}
可以使用泛型接口对于各种设计模式进行预定义, 当然这种可以预定义的设计模式只能是设计一个类型的设计模式. 然后在编码中就能写出清晰明确的类型了
Java泛型的一个局限性: 由于限制传入的类型一定是Object的子类, 所以不支持使用基础类型进行泛型参数的输入.
对于类型接口的实现除了直接在源代码基础上进行适配之外, 更好的方式是针对需要实现的接口写一个匿名内部类进行适配. 这种写法叫做使用适配器实现接口
15.4 泛型方法
Java中可以定义泛型方法, 即是该方法可以输入泛型. 但是该方法是否为泛型和该方法所在的类是否为泛型没有关系.
泛型方法使得Java中方法能够独立于类进行变化. 无论在什么时候如果能够使用泛型方法替代泛型类, 就应当使用泛型方法
定义泛型方法的方式:
public class Trail{
// 定义泛型方法的方式是将泛型声明放在方法返回值和方法形参之前
public <T> void funct(T x){
// ...
}
public static void main(String[] args){
Trail t = new Trail();
t.funct("hello");
// 和泛型类不同, 使用泛型方法的时候一般不需要指定泛型值
// 因为编译器会自动根据输入或者输出的类型推断泛型的值
t.funct(1);
// 如果传入的是一个基础类型值, 自动打包器会将其自动转化为对应的类型
// 如将int都转化为Integer
}
}
15.4.1 杠杆利用类型参数推断
可以利用编译器对于泛型函数的泛型的推断功能快速创建对应泛型的对象
public class Trial{
public static <K,V> Map<K,V> newMap(){
return new HashMap<K,V>;
}
public static void mian(String[] args){
Map<String, String> map = newMap();
}
}
但是该类型推断只适用于赋值操作, 对于其他操作, 编译器无法推断其对应的泛型值. 例如当需要以形参的方式传入一个指定泛型的对象的时候, 无法使用该函数自动推断类型.
例如:
public class Trail1{
public static void funct(Map<String, ? extends Object> inMap){}
public static void main(String[] args){
funct(Trail.newMap()); // 会返回编译错误
}
}
这种限制抵消了对于Trail中自动泛型推断的价值, 所以这种自动推断方式只能是作为借鉴而不是作为常用设计思路
15.4.2 可变参数与泛型方法
可以在泛型方法中使用可变参数列表. 其在java类库中被频繁使用例如Arrays.asList(T ... objs)
15.4.3 用于Generator的泛型方法
这是对于生成器的一个简单应用, 使用泛型输入生成器类型, 然后是有循环使用生成器填充一个容器并返回容器对象
15.4.4 一个通用的Generator
通过约定所有使用该生成器的类型都需要具有无参数构造函数, 在生成器中调用该类型的Class.newInstance方法进行对象的创建. 然后使用外层一个一层泛型函数输入泛型. 可以避免进行复杂的泛型输入. 而是直接创建并生成对应Class的对象
public class GeneralGenerator <T>{
private final Class<T> type;
public GeneralGenerator(Class<T> type){this.type = type;}
public T generate(){
return type.newInstance();
// try catch ...
}
}
public class GeneratorWraper{
public static <T> T getNewInstance(Class<T> type){
return new GeneralGenerator<T>(type).generate();
}
}
15.4.5 简化元组的使用
在之前的TwoTuple, ThreeTuple之上使用泛型函数进行包装, 直接推断类型并创建对应类型的元组.
public class TupleWraper{
public static <A,B> TwoTuple<A,B> tuple(A a,B b){
return new TwoTuple<A,B>(a,b);
}
public static <A,B> TwoTuple tupleUnparamized(A a,B b){ // 可以直接返回非参数化的类型, 相当于将泛型类转化为其父类进行返回
return new TwoTuple<A,B>(a,b);
}
}
15.4.6 一个Set实用工具
这个实例是使用Set来进行数学中的集合计算.使用泛型来使得输入的Set没有限制具体类型. 创建union, intersection, difference, complement四个函数
使用EnumSet.range对于枚举类根据其实际整形值的范围进行枚举内容的获取.
15.5 匿名内部类
在匿名内部类中可以使用泛型用来进行对应类型的对象的构造.
15.6 构建复杂模型
利用泛型简单安全地创建复杂的模型. 虽然泛型可能导致名称上看起来比较冗长, 但是其避免了众多重复的代码.
在使用多层容器的时候, 使用泛型能够使得容器可被容易的管理和使用.
15.7 擦除的神秘之处
在Java中ArrayList.clss是可以获取的, 但是ArrayList<String>.class是不能够获取的
在泛型中虽然可以使用Class.getTypeParameters获取, 但是其结果只是泛型的占位符. 在Java中的一个现实是, 在泛型代码内部无法获取任何有关泛型类型信息的数据.
因为Java的泛型的类型信息是只在编译阶段确认的, 在运行的时候所有的泛型对象都被擦除为其原生对象进行使用.
15.7.1 C++中对于泛型类型的处理方法
C++中对于泛型的处理方式是在编译阶段获取泛型类型参数信息, 然后再编译泛型内部的泛型类型函数, 如果函数无法找到则报编译错误.
Java中由于对于所有的泛型都进行擦除, 所以根本无法在运行时对于泛型参数类型执行其特有的函数. 所以当需要在泛型内部执行某些泛型参数类特有的函数的时候, 需要使用extends或者implements对于泛型参数的可选边界进行修饰. 虽然其泛型参数也会被擦除, 但是由于在编译阶段知道了其参数的范围, 所以可以根据父类或者接口运行泛型参数特有函数.
这种需要使用泛型边界的执行方式使得Java的泛型相当受限.(这一限制可能是由于Java的编译方式导致的, 其无法根据代码中对于泛型参数的设置创建多个泛型类型副本) Java泛型的使用环境是当希望使用的类型参数比某个具体的接口或者类型更加泛化的时候. 除非项目的代码足够复杂, 所以没有必要使用泛型进行抽象
对于Java中擦除功能的自定义修改: 通过创建返回泛型参数的函数来确定泛型的类型参数.
class Template<T> {
private T obj;
public Template(T obj){
this.obj = obj;
}
public Class<?> getTClass(){
T.class; // error 由于擦除后无法访问T所以这个编译失败
return obj.getClass();
}
}
15.7.2 迁移兼容性
Java的擦除不是一个语言特性, 而是一个泛型实现的折中. 因为泛型不是Java在一开始设计时就考虑进去的, 所以其的实现向对别扭. 这种折中导致在Java中泛型没有那么有用, 但是在一些特殊情况下泛型依旧是非常重要的实现手段.
在基于擦除的实现中泛型被当做第二类类型进行处理, 也就是说不能在某些重要的上下文环境中使用. 泛型的类型检查只在静态类型检查期间才会出现. 在这之后所有泛型类型都被擦除. 泛型类型被转化为一个非泛型的上界.
使用擦除方式进行实现的核心动机是使得泛化的客户端可以在非泛化的类库中使用.(例如对于kafka的消费客户端的输出类型通过泛型进行输入, 但是在消费的时候使用泛化的客户端进行外部的使用.)
因为Java的泛型是在后续更新中才出现的, 所以要保证现有的类库和类文件依旧合法并且能够保持之前的含义.
15.7.3 擦除的问题
擦除的正当理由是在不破坏现有代码的情况下将泛型功能进行引入. 擦除的代价是显著的, 其不能显式地引用运行时类型检查. 使用泛型并不是强制的.
由于擦除问题, 所以在执行带有泛型的函数的时候编译器会报出unchecked的warning. 在Java中提供了@SuppressWarnings("unchecked")写在函数的调用方前面, 使得该warning被忽略
15.7.4 边界处的动作
由于有了擦除机制, 所以导致泛型可能不安全, 其可以表示没有任何实际意义的事物.
擦除机制导致泛型内部的类型模具有一致性, 但是对于外部的使用通过在编译阶段的确认, 能够保证在外部使用上的一致性. 所以我们可以这么说: 泛型只是一个和类型紧密绑定的接口处自动转型功能
15.8 擦除的补偿
通过引入自定义的类型标签可以对于擦除进行补偿. 通过显式的将输入对象的类型提取并存放到内部变量中, 就可以在内部维护泛型的类型参数信息, 以及使用该类型参数进行内部执行的确认和转型.
15.8.1 创建类型的泛型的实例
使用工厂对象, 显式输入泛型类型参数, 然后在内部进行class的newInstance. 但是这种实现方式的约定式需求是需要类型有默认构造函数, 其可能导致失败. 所以最好使用接口限制输入的类型为一个工厂类型. 来保证其能够正确地创建所需要的对象.
15.8.2 泛型数组
由于无法直接创建泛型的数组T[]所以需要使用泛型的容器ArrayList进行列表功能的实现.
如果想创建一个泛型数组只能创建一个被擦除类型的数组然后对其进行转型.
正确地返回泛型数组的方式:
public class Template<T>{
@SuppressWarnings("uncheck")
public T[] getArray(Object ... obj){
Object[] objArray = new Object[100];
for(int i = 0; i < obj.lenght; i++){
objArray[i] = obj[i];
}
return (T[]) objArray;
}
}
15.9 边界
边界的一个更重要的应用环境是按照自己的边界类型来调用方法. 当规定了边界的时候, 就可以在泛型中调用边界中含有的方法.
15.10 通配符
以下这个语句是无法被编译的List<Fruit> fList = new ArrayList<Apple>();因为Fruit的列表运行插入任何水果类型, 但是Apple列表只允许插入Apple的子类和Apple类型, 由于两者的操作不统一所以无法进行赋值.
使用通配符进行List的向上转型的问题: List<? extends Fruit>fList = new ArrayList<Apple>()这个操作是可以编译以及可以运行的. 但是被转化为List<? extends Fruit>类型之后由于不清楚类型内部具体是那种Fruit的子类, 而且用户也不关心其中是那种Fruit的子类, 所以不能在向其中插入任何的数据. 即使是Apple也不行. 其唯一能做的只是进行Fruit数据的获取.
15.10.1 编译器对于该问题的处理方式
对于将泛型列表进行了向上转型的情况, 对于编译器会自动阻止任何参数中含有泛型的函数的执行, 但是不会阻止参数中不含泛型的函数的执行. 因为这些函数都是使用Object进行类型的输入然后在内部进行类型的转化.
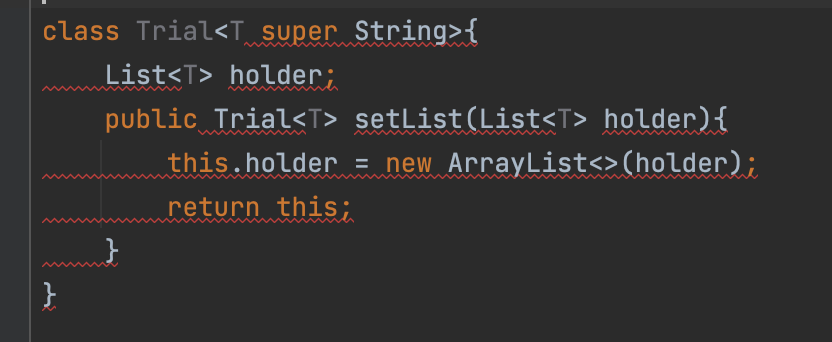
所以可以使用List<?>将列表设置为只读的
public class trial1 {
public static void main(String[] args) {
List<String> stringList = Arrays.asList("1", "2");
List<? extends String> readOnlyHolder = new Trial<String>().setList(stringList).getReadOnlyHolder();
System.out.println(readOnlyHolder.get(1));
}
}
class Trial<T>{
List<T> holder;
public Trial<T> setList(List<T> holder){
this.holder = new ArrayList<>(holder);
return this;
}
public List<? extends T> getReadOnlyHolder(){
return this.holder;
}
}
15.10.2 逆变
通过在泛型中使用超类通配符. 这种通配符只能使用在容器泛型类型中, 而不能使用在自定义的泛型类型中.
ArrayList<? super String>和ArrayList<String>的效果是一致的. 都表示可以将String的子类放置到列表中.
public static void main(String[] args) {
List<? super String> strings = new ArrayList<>();
strings.add("init");
System.out.println(strings.get(0));
}
public static void main(String[] args) {
List<String> strings = new ArrayList<>();
strings.add("init");
System.out.println(strings.get(0));
}
15.10.3 无界通配符
无界通配符是<?>其在一定程度上等效于<Object>. 使用无界通配符是在申明这里并不是在使用原生类型而是当前情况下泛型参数所能支持的一切类型.
<?>和<Object>的差别: List<Object>表示的是持有任务Object类型的原生List. 而List<?>表示的具有某种特定类型的非原生List, 且我们不知道那种类型是什么
这部分讲的云里雾里, 没有听懂
15.10.4 捕获转换
这是一种必须使用通配符的情况. 使用通配符进行输入, 然后利用编译器对于实际类型参数的推断来调取另一个制定了输入类型的函数.
class Trial{
static <T> void f1 (Holder<T> holder){
T t = holder.get();
sout(t.getClass());
}
static void f2 (Holder<?> holder){
f1(holder);
}
}
15.11 Java中使用泛型的问题
15.11.1 任何基本类型都不能作为类型参数
需要使用以Object作为父类的对象类型作为类型参数. 这种方式使用起来没有问题, 但是如果性能存在问题可以使用org.apache.commons.cllections.primitives这一针对基本类型参数专门适配了的容器版本
这个问题的一个表现是: 虽然可以使用基础类型对应的包装类型存储对应数据, 但是当取回数据的时候, 会无法自动转换为对应基础类型.
15.11.2 实现参数化接口
由于直接实现两种不同参数的参数化接口, 会导致编译器需要判断同样的函数是否针对两种类型进行了定义, 会导致语义的不清晰. 所以无法进行编译. 但是如果删除两个接口的泛型则只是对一个接口实现了两次, 是可以编译通过的.
这一问题在使用一些非常基础的Java接口如Comparable<T>时会造成非常令人恼火的问题
class A implements Inferf<Integer>{}
class B extends A implements Inferf<String>{} // error
15.11.3 转型和警告
使用带有泛型类型参数的转型或者instanceof不会有任何效果. List<Integer>.class是无效的. 进行类型的转型(List<Integer>)是会触发警告的.
15.11.4 重载
public class Trial <W,T>{
void f(List<W>){}
void f(List<T>){} // 由于擦除导致两个函数的签名完全一致
}
15.11.5 基类劫持了接口
一个接口如果在基类中实现了, 而在子类中需要修改输入类型为基类函数输入类型的子类, 会造成重载的错误.
public A implements Comparable<A>{
public int compareTo(A a){return 0;}
}
public B extends A implements Comparable<B>{
public int compareTo(B b){return 0;} // error -- 对于接口的重定义
}
public C extends A{
public int compareTo(A c){return 0;} // 只能以这种方式进行实现
}
15.12 自限定的类型
class A <T extends A<T> >{
// ...
}
15.12.1 古怪的循环泛型
这种代码方式其实是将基类变为一种其所有导出类的公共功能模板, 其产生的类将使用确切的类型而不是类型模板
public class BasicHolder<T>{
// 这里其实是导出类的功能模板
T element;
void set(T input){
element = input;
}
T get(){
return element;
}
void Class<?> getElementClass(){
return element.getClass();
}
}
// 使用导出类作为基类的类型参数可以对于基类中定义的功能模板进行实现而且使用导出类作为输入输出参数
class SubClass extends BasicHolder<SubClass>{}
// 当不使用子类作为类型参数的时候也可以强行保证接口类型
class IntegerHolder extends BasicHolder<Integer>{}
public static void main(String[] args){
SubType s1 = new SubType();
SubType s2 = new SubType();
s1.set(s2);
SubType getS = s1.get();
IntegerHolder ih = new IntegerHolder();
Integer i = new Integer(100);
ih.set(i);
Integer getI = ih.get();
}
15.12.2 自限定
自限定是通过引入额外的步骤来保证使用泛型参数作为自己的边界类型参数.
自限定的意义在于保证类型参数必须与正在被定义的类型相同
class SelfBounded <T extends SelfBounded>{
T element;
void set(T args){
element = t;
}
T get(){
return element;
}
}
class A extends SelfBounded<A>{}
15.12.3 参数协变
自限定类型的价值在于其能够产生方法类型随着子类类型变化的方法.
但是这个功能并不算多么有价值, 因为在子类覆盖方法中修改类型已经在JavaSE5中进行了实现.
class Base{}
class Derived extends Base{}
interface BaseGetter{
Base get();
}
interface DerivedGetter{
Derived get();
}
15.13 动态类型安全
泛型容器中由于其都是使用Object进行存储, 所以在函数中放入了一个不符合容器内容的对象的时候, 不会报错, 但是在取出数据的时候会报错.
所以最好不要传递不含泛型的容器参数, 其会导致编译的类型检查失效.
15.14 异常
由于所有泛型信息都会在运行时擦除, 所以不能使用泛型进行异常的定义, 因为其会导致无法获取异常的具体类型, Java编译器也不允许用户这么做
15.15 混型
混型术语的意义是混合多个类的能力, 产生一个可以表示混型中所有类型的类. 混型的价值在于其能够将特性和行为一致地应用于多个类型上.
15.15.1 C++中的混型
C++中的混型主要方式是使用多重继承或者使用泛型进行定义.
这种混型在逻辑架构上有点类似AOP的思想. 其能够为组件附加一些额外功能
template<class T> class TimeStamped : public T {
long timeStamp;
public:
TimeStamped(){timeStamp = time(0);}
long getStamp() {return timeStamp;}
}
template<class T> class SerialNumbered : public T {
long serialNumber;
static long serialNumberSta = 0;
public:
SerialNumbered(){serialNumber = serialNumberSta++;}
long getSerialNumber() {return serialNumber;}
}
class WorkerClass{
// ...
}
typedef SerialTimeWorker TimeStamped<SerialNumbered<WorkerClass>>;
int main(){
SerialTimeWorker worker1(), worker2();
worker1.getStamp();
worker1.getSerialNumber();
}
15.15.2 Java中与接口进行混合
使用接口定义工作组件的接口, 然后使用变量组合的方式将外部的其他附加功能添加进类型.
interface TimeStamped{Long getStamp();}
class TimeStampedImpl{
private Long timeStamp;
TimeStampedImpl(){
timeStamp = new Long(new Date().getTime());
}
public Long getStamp(){
return timeStamp;
}
}
class Worker{
// ...
}
class TimeStampWorker extends Worker implements TimeStamped{
TimeStamped t = new TimeStampedImpl();
public Long getStamp(){return t.getStamp();}
// ...
}
15.15.3 使用装饰器模式
混型的概念和装饰器的概念非常相近可以使用装饰器来满足格式可能的组合. 装饰器使用组合和装饰物/装饰器层次结构进行实现. 而混型是一种基于继承的装饰方式, 所以可以将混型作为一个泛型装饰器机制.
装饰器的使用方式是通过接口确定包装在基础类型对象的周围的所有装饰对象都有统一的接口, 使用分层的方式将功能包裹在核心对象周围. 使得装饰器与对象的使用是透明的.
package com.sankuai.example.demo.util;
// 所有不论是否被包装的worker的基础功能接口
interface WorkerInterface {
String getValue();
void setValue(String value);
}
public class Trial {
public static void main(String[] args) {
CounterDecorator counterWorker = new CounterDecorator(new BasicWorker());
System.out.println(counterWorker.getDecorator());
System.out.println(counterWorker.getIndex());
counterWorker.setValue("void");
counterWorker.getValue();
}
}
// 一个基础功能实体类
class BasicWorker implements WorkerInterface {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
// 用于包装基础功能的包装类 -- 使用组合的方式代理基础功能类型
abstract class WorkerDecorator implements WorkerInterface {
private final WorkerInterface worker;
public WorkerDecorator(WorkerInterface worker) {
this.worker = worker;
}
@Override
public String getValue() {
return worker.getValue();
}
@Override
public void setValue(String value) {
worker.setValue(value);
}
abstract Class<? extends WorkerDecorator> getDecorator();
}
// 包装器实体类 对于当前基础功能类提供额外功能
class CounterDecorator extends WorkerDecorator {
private static int counter = 0;
private final int index;
public CounterDecorator(WorkerInterface worker) {
super(worker);
index = counter++;
}
public static int getCounter() {
return counter;
}
public int getIndex() {
return index;
}
@Override
Class<? extends WorkerDecorator> getDecorator() {
return CounterDecorator.class;
}
}
15.15.4 与动态代理混合
将所有包装类都实现一个公共接口, 然后使用代理的方式进行层级的运行, 有点类似对于消息流的AOP设计思路.
15.16 潜在类型机制
这种机制在Java中没有实现, 但是在Go中有实现: 如果一个类型包含了一个接口中的所有函数接口, 那么即使其没有显示实现该接口也认为该类型实现了该接口.
通过潜在类型机制, 使得类似Go这种语言可以使用更加广泛的泛化能力.
常用的两种潜在类型机制语言是Python和C++. 因为Python是在运行阶段进行函数的确认, C++则是在编译阶段进行类型确定, 所以其潜在类型机制不需要使用静态或者动态类型检测
15.17 对缺乏潜在类型机制的补偿
15.17.1 使用反射对潜在类型机制进行补偿
使用反射类似Python的在执行阶段对于接口进行确认
15.17.2 将一个方法用于序列
使用泛型类型包装反射接口, 使用反射运行实际函数. 能够在调用自定义功能的同时保留统一的对外接口, 通过基于名称的反射函数获取.
public class Apply{
private final Object obj;
private final Method f;
public Apply(Object obj, Method f){this.obj = obj; this.f = f;}
public apply(Object ... args) throws Exception{
f.invoke(obj, args);
}
}
15.17.4 使用适配器仿真潜在类型机制
潜在类型机制创建了一个包含所需方法的隐式接口. 适配器设计模式的一个功能是使用中介类型来适配需要的接口. (这里的适配器和Kafka中的消费者的定义方式比较相近, 通过定义一个内部类的形式进行接口的实现)
15.18 将函数对象用作策略
策略设计模式: 将变化的事物完全隔离在一个函数对象中.
15.19 总结
转型的核心缺陷: 由于向容器中插入不合法类型的操作是在最后返回RunTimeException的. 其异常返回点和错误发生点相去甚远, 所以造成对于错误的排查困难
泛型的核心价值是可表达性, 能够创建类型安全的容器, 使用类型安全的容器能够创建更加通用的代码
17 容器深入研究 P459 ~ P524
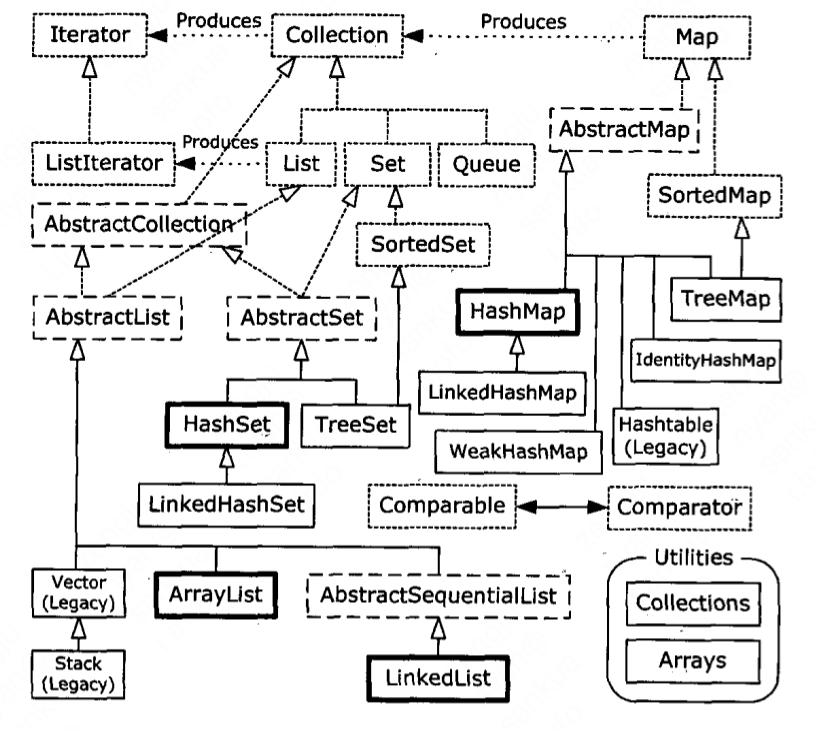
17.1 完整的容器分类法
SE5中添加了的容器类型: Queue接口, ConcurrentMap, CopyOnWriteArrayList, CopyOnWriteArraySet, EnumSet, EnumMap
17.2 填充容器
使用fill和addAll进行容器的填充. 其中fill一般是进行默认值的设置, 其是将一个对象填充所有列表中的对象.
打印列表中的对象的打印方式默认为类型名称字符串+使用hashCode生成的十六进制数
17.2.1 一种Generator解决方案
所有的容器都有使用其他容器作为参数的构造函数.
17.2.2 Map生成器
map的构建需要插入Pair类型. (注意: Map.Entity是由Map导出的只读数据, Pair才是写入数据)
17.2.3 使用Abstract类型
Collection和Map是抽象类, 可以使用java.util中对于容器类的抽象类创建自己的容器类型
可以使用享元设计模式创建自己的容器类型. 享元模式是将对象的一部分具体化. 例如创建一个只读的Map的时候将所有键值对的Entry以对于Pair的引用的形式存储下来. 当需要进行查询的时候根据引用去获取数据而不是重新包装Entry对象.
17.3 Collection的功能方法
重点是其中没有随机访问的get方法. 因为对于Map或者Set而言, 其内部顺序是由其自己维护的, 所以随机访问没有意义
17.4 可选操作
对于Collection而言所有的添加和移除操作都是可选操作, 因为在不同容器中其实现方式和逻辑有较大的区别, 为了防止出现接口爆炸所以令其作为可选接口进行实现
如果调用了没有实现的可选接口会报出: UnsupportedOperationException
17.4.1 未获支持的操作
最常见的未获支持的操作是在使用Arrays.asList方法将数组转化为只读列表时出现. 可以使用Collections.unmodifiableList将一个可编辑列表转化为一个不可编辑的列表
17.5 List的功能方法
这是一个List的使用示例
17.6 Set和存储顺序
HashSet: 为了快速搜索而创建的Set, 需要实现hashCode方法
TreeSet: 能够保证次序的Set, 底层为Tree结构, 可以从Set获取有序序列. 需要实现Comparable接口. 其维护的排序方式是降序
LinkedHashSet: 使用功能Hash提升查询速度, 内部使用链表维护了元素的插入顺序, 所以可以使用迭代器遍历Set并返回其插入顺序, 其元素也必须是定义了HashCode方法
对于Comparable接口实现的问题: 使用简单粗暴的 i1-i2 进行返回是错误的, 因为当一个大正整数减去一个大负整数的时候, 会出现数值的溢出导致返回一个负数. 正确的方式是通过判断其大小关系并返回 -1, 0 ,1中的一个
17.6.1 SortedSet
SortedSet中的元素是有序状态可以使用以下几个接口
Object first()返回容器中的第一个元素
Object last()返回容器中的最后一个元素
SortedSet subSet(fromElement, toElement)返回前包后不包的有序元素列表
SortedSet headSet(fromElement), SortedSet tailSet(toElement)返回前包后不包的有序元素列表
17.7 队列
队列的实现除了并发队列以外只有两种实现 LinkedQueue, PriorityQueue.
使用queue.offer进行对象的追加
使用queue.remove进行对象的获取.
17.7.1 优先级队列
需要使用Comparable进行对象的比较, 使用add函数对于对象进行插入, 使用remove进行对象的获取. 按照从小到大的形式进行结果的获取.
17.7.2 双向队列
双向队列可以在队列的任何一端机械能元素的添加或者移除. Java中没有原生的对于双端队列的支持, 需要自己通过LinkedList进行包装. 但是由于很少有需要对于双端队列的两端同时进行输入和输出, 所以双端队列的使用频率较小
17.8 理解Map
Map的基本思想是键值对以及维护键和值之间的关联.
17.8.1 性能
Hash通过散列值进行搜索. 由于Object中已经实现了hashCode方法, 所以可以使用HashCode进行快速的查询
其他Map的实现方式
- LinkedHashMap: 通过对于对象进行链表的包装使得对其的迭代器获取时其顺序为插入顺序
- TreeMap: 通过红黑树进行实现, 数值之间会进行排序. TreeMap是唯一带有subMap方法的Map类型, 其通过返回一个子树进行子表的创建. 其机械能迭代返回的数据是有序的需要实现Comparable或者Comparator
- WeakHashMap: 通过弱键进行映射. 允许释放弱键所引用的对象. 如果处理弱键以外没有其他引用指向某个键则该键值对可以被垃圾回收. 是一个针对特殊场景下可回收Map的设计
- ConcurrentHashMap: 线程安全的Map, 不涉及进行同步加锁
- IdentityHashMap: 可以使用==替代Equal对于键进行比较, 为解决特殊问题进行的设计
所有的键值都需要拥有一个Equal方法进行比较
注意: 默认情况下Object.equals方法只是比较两个对象的地址是否相同, 不是比较两个对象的内容是否相同, 需要自己实现.equals方法才能够进行Map, Set的使用
17.8.2 SortedMap
由于其对于键保持了排序状态, 所以可以有一些额外功能.
firstKey, lastKey, subMap, headMap, tailMap
17.8.3 LinkedHashMap
可以在LinkedHashMap中使用功能基于最近最少访问的对象排序. 能够将最需要删除的对象放置在最前面, 能够提供Map存储的同时进行对象的清理
public LinkedHashMap(int initialCapacity, // 初始化时预留的空间大小
float loadFactor,
// 负载因子: 当hash表中的数据量大于 loadFactor * hash桶数目时添加新的hash桶
boolean accessOrder) // 是使用访问频率顺序访问还是插入顺序访问
17.9 散列和散列码
注意: 默认的Object的散列码是通过对象地址计算的散列码, 而不是对象内容计算的散列码. 另外equals比较的也是地址是否一致, 而不是内容是否一致. 所以当需要使用自定义结构体作为键值的时候需要手写hashCode内容以及equals内容
实现equals的时候的几个条件:
x.equals(x) == truex.equals(y) == y.equals(x)if x.equals(y) and y.equals(z) then x.equals(z)- 多次使用
x.equals(y)其结果值不变 x.equals(null) == false
示例代码:
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.commons.codec.digest.DigestUtils;
@Data
@AllArgsConstructor
class MapableClass{
static String a; // 由于是静态变量不计入hash
private String b;
private int c;
@Override
public int hashCode() {
byte[] bytes = DigestUtils.sha256("" + b + c);
int res = 0;
for (byte b : bytes) {
res += b;
};
return res;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof MapableClass){
MapableClass input = (MapableClass) obj;
return (b.equals(input.b) && c==input.c);
}else {
return false;
}
}
}
17.9.1 正确理解hashCode()
通过在函数调用中输出调用内容可知, HashMap在创建索引的时候同时使用了HashCode和Equals, 当两个对象hash相同但是不相等的时候会创建多个不同的索引
17.9.2 为速度而散列
Map中对于散列的效率相关的实现: 使用一个固定长度的数组对于键信息进行存储. 其中存储的键信息并不是键本身而是一个指向了键的内容信息. 每个数组元素的地址和其hash值数值相关.
查询对象的时候先按照hash值进行搜索, 然后再依次使用equals进行排查. 这样就能找到所有的对象.
为了能够将hash值均匀地放到每一个桶中, 所以使用2^n作为数组长度, 使用2^n对hash值的掩码作为hash对象的存放地址
17.9.3 覆盖hashCode()
对于String而言, 一个String内容对应唯一HashCode例如以下代码只含有一个地址: "Hello Hello".split(" ")
最简单的hash算法: 首先以映射将基础类型映射为整形, 然后使用叠加方式将所有结果聚合
@AllArgsConstructor
class TrialHash{
boolean aBoolean;
int anInt;
long aLong;
float aFloat;
double aDouble;
Object anObject;
@Override
public int hashCode() {
return getHash(0,aBoolean,anInt,aLong, aFloat,aDouble,anObject);
}
private static int getHash(int basicRes, Object ... params){
ToIntFunction<Object> hashCodeHelper = new ToIntFunction<Object>() {
@Override
public int applyAsInt(Object o) {
if (o == null) {
return 0;
}
if (Boolean.class.equals(o.getClass())) {
return Boolean.TRUE.equals(o) ? 0 : 1;
} else if (Integer.class.equals(o.getClass())) {
return (Integer) o;
} else if (Byte.class.equals(o.getClass())) {
Byte byteObj = (Byte) o;
return byteObj.intValue();
} else if (Character.class.equals(o.getClass())) {
return (Character) o;
} else if (Short.class.equals(o.getClass())) {
return (Short) o;
} else if (Long.class.equals(o.getClass())) {
long o1 = (Long) o;
return (int) (o1 ^ (o1 >>> 32));
} else if (Float.class.equals(o.getClass())) {
return Float.floatToIntBits((Float) o);
} else if (Double.class.equals(o.getClass())) {
long l = Double.doubleToLongBits((Double) o);
return (int) (l ^ (l >>> 32));
}
return o.hashCode();
}
};
int res = basicRes;
for (Object o : params) {
int i = hashCodeHelper.applyAsInt(o);
res = 37 * res + i;
}
return res;
}
}
17.10 选择接口的不同实现
一般是根据特定容器的特定操作的频率和操作的效率进行不同实现的选择
17.10.1 性能测试框架
使用循环测试实现的特定接口, 查看其时间消耗
17.10.2 对于List的选择
对于Vector类型不要进行使用, 其是之前遗留代码.
应当使用ArrayList进行默认首选, LinkedList是只在需要进行插入和删除的性能需求的时候才进行使用. 对于固定长度的数组需要使用Arrays.asList进行包装. CopyOnWriteArrayList是进行并发编程的类型
对于已排序的列表, 使用静态函数Arrays.binarySearch()进行快速搜索
17.10.3 微基准测试的危险
对于使用循环进行微基准测试不能使用太多的假设. 只在感兴趣的事项上花费精力. 而且需要运行的时间足够长, 由于Java的HotSpot技术, 所以只有运行一段时间之后才能找到问题
例如对于随机值是否包含上界和下界, 需要足够的测试才能得到结果
17.10.4 对于Set的选择
总体上来说HashSet的性能比TreeSet好, 特别在添加和查询元素. TreeSet的唯一优势是其可以维持元素的排序状态
17.10.5 对于Map的选择
除了IdentityHashMap插入的操作都会随着Map的尺寸的变大而变慢.
使用Arrays.binarySearch中快速搜索已排序列表中的对象
HashMap的性能因子
可以手工调整HashMap中的参数来调节性能. 容量(表中的桶的个数), 初始容量(在创建时的桶数), 负载因子(当容器中的数据量到达桶位中的一定比例时添加桶)
17.11 实用方法
Collections中含有对于容器的辅助函数. 下面是一些比较常用的一些函数
checkedCollection, checkedList, checkedMap, checkedSet,checkedSortedMap, checkedSortedSet用于进行容器泛型的类型检查, 用于生成确认符合类型的容器. 如果出错会报出异常- 获取最大最小值并可以使用自定义的比较器进行比较:
min, max - indexOfSubList: 和字符串的比较类似
- replaceAll: 进行数据的替换
- reverseOrder
- Rotate : 将所有元素向后移动一位, 将最后元素移到最前
- Shuffle: 对于队列进行随机重排
- swap: 进行id对应元素的交换
- nCopies: 返回一个大小为n的只读List, 其中每一个对象都指向同一个引用
- emptyList, emptyMap, emptySet: 返回一个不可变的空容器
- 这些Collections辅助函数获得的容器大多是只读的
17.11.1 List的排序和查询
这是一个使用功能Comparator, binarySearch, shuffle 的使用示例
17.11.2 设定Collections或Map为不可修改
这是使用unmodifiableList函数将容器设置为不可修改, 任何试图更改容器内容的操作会发起UnsupportedOperationException
17.11.3 Collection或Map的同步控制
这是使用Collections中的辅助函数将容器更改为线程同步的内容.
Collections.synchronizedCollection, Collections.synchronizedList
Collections.synchronizedSet,Collections.synchronizedMap
线程同步的快速报错: 为了保护容器防止多个进程同时修改同个容器中的内容. Java容器类库采用快速报错. 其会探查容器上除了当前线程外其他线程的更改, 如果发现其他线程修改了容器, 则会报出ConcurrentModificationException
一个发生异常的示例: 当创建了一个迭代器之后再将数据放入容器则会报错.
为了保证避免出现上面问题定义的其他类型: ConcurrentHashMap, CopyOnWriteArrayList, CopyOnWriteArraySet
17.12 持有引用
java.lang.ref中包含了一组类, 为垃圾回收提供了更大的灵活性. 有三个继承于抽象类Reference的类型, SoftReference, WealReference, PhantomReference
当一个对象只有通过Reference对象获取的时候, 根据上述不同的类型对于垃圾回收器进行不同级别的回收.
持有引用是指想要继续持有某个对象的引用, 希望以后还能继续访问到该对象, 但是也希望在内存吃紧的时候进行释放.
使用Reference对象作为对象和普通引用之间的媒介. SoftReference, WeakReference, PhantomReference是由强到弱排列.
- SoftReference: 用于实现内存敏感的高速缓存
- WeakReference: 为实现规范映射而设计的, 规范映射中的对象的实例可以在程序中多次被使用, 节省存储空间
- PhantomReference: 用于调度回收前的清理工作, 能够提供比Java更加灵活的终止机制
可以将SoftReference, WeakReference放入ReferenceQueue进行回收前清理工作, 而PhantomReference只能依赖于ReferenceQueue进行使用
17.12.1 WeakHashMap
这是容器中的特殊Map, 用来保存WeakReference, 可以使得规范映射更易于使用. 可以用于内存缓存的实现, 而且在这映射中每个值只保存一个实例以节省空间. 需要实现hashCode, equals的函数
17.13 Java 1.0/1.1 的容器
这儿是一些已经过时了的老容器, 但是在一些老代码中进行了使用
17.13.1 Vector和Enumeration
Vector是ArrayList的之前版本的自动增长序列. 其设计中有很多问题
Enumeration是老版本的Interator接口, 只有两个名字很长的方法hasMoreElements, nextElement
可以使用Collections.enumeration方法从Collection中生成一个Enumeration
17.13.2 HashTable
在新的程序中没有理由再使用HashTable二部使用HashMap
17.13.3 Stack
由于Stack是继承于Vector, 所以其功能设计较差, 应当不要再任何代码中使用该类型
在代码中使用栈的行为, 应当使用LinkedList或者从其中创建Stack类型
17.13.4 BitSet
这是用于高效存储大量开关信息. 其效率是针对空间而言, 其访问的时间比数组较慢. BitSet的最小容量是64位开关信息.
只有在创建包含开关信息列表的大量对象, 并且因为性能以及其他度量因素时才使用这个类型. 如果是因为其某些对象太大而使用这个类型, 会造成不需要的复杂性, 而且会花费掉大量时间.
BitSet中是将其中每一个位作为Flag, 当插入的数据超过64之后, 会自动扩充.
如果需要一个可以拥有命名的固定标志集合, 则可以使用EnumSet, 因为其支持其按照名字而不是数字位数进行设置.
应当使用BitSet而不是使用EnumSet的唯一原因是: 只有在运行时才知道需要多少标志
17.14 总结
该章节中重要的内容是能够自己编写hashCode的方法. 以及对于不同容器类型的深入理解. 早期Java类库中的设计是复杂的利弊和仔细权衡的产物.
19 枚举类型 P590 ~ P619
枚举类型是一种新的类型, 其是通过将具名的值作为常规程序组件进行使用. 是一种非常有用的功能
19.1 基本enum特性
可以使用enum.values进行枚举实例的遍历, 其返回的结果数组是保持其在enum中声明的顺序.
当创建enum类型时, 编译器会为其创建一个相关的类, 其类型继承于java.lang.Enum
使用enum.ordinal返回一个int值, 获取在enum中声明时的顺序, 从0开始进行标记. 编译器会自动实现equals, hashCode函数. 而且Enum自动实现了Comparable接口和Serializable接口
使用enum.getDeclaringClass就能获取其所属的enum类型. 可以使用name返回enum实例声明时的名字.
19.1.1 将静态导入用于enum
使用static import将enum的标识带入当前的命名空间. 直接使用import则需要使用枚举类型名称和枚举值两个字段进行定义.
19.2 向enum中添加新方法
enum的类型不允许进行继承, 除此之外可以将枚举类型看做一个常规的类型. 甚至enum中可以添加main方法.
一般而言每个枚举实例都要能够返回对于自身的描述, 而不是进行默认的toString的实现.
当需要定义自己的方法, 需要在enum的实例序列的最后添加一个分号.
枚举类型中的构造器只有在类型定义内部才能够进行使用. 一旦枚举类型定义结束编译器就不能使用构造器创建任何实例.
这下面两种实现方式基本是等效的
enum EnumClass{
A(0, "name_a"), B(1, "name_b");
private int id;
private String name;
private EnumClass(int id, String name){this.id = id; this.name = name;}
public int getId() {
return id;
}
public String getName() {
return name;
}
}
final class EnumClass_1{
public final EnumClass_1 A = new EnumClass_1(0,"name_a");
public final EnumClass_1 B = new EnumClass_1(1, "name_b");
private int id;
private String name;
private EnumClass_1(int id, String name){
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
}
19.2.1覆盖enum的方法
可以自己使用toString, name进行函数的覆盖
19.3 在switch语句中使用的enum
以为枚举类型可以使用ordinal功能获取其整形数值, 所以其可以是用于switch语句中.
19.4 values的神秘之处
Enum类型中没有value方法. 该方法是由编译器添加的static方法, 而且编译器将Enum标记为final类型, 由于擦除效应, 反编译时无法获取Enum的模板类型.
在进行反射的时候可以使用getEnumConstants方法, 能够获取并执行由编译器创建的values方法.
19.5 实现而非继承
所有enum类型都是继承于Enum类型. 但是在进行enum的创建时可以同时实现一个或多个接口. 但是注意需要其需要获取一个enum类型才能调用对应的接口
19.6 随机选取
可以使用枚举泛型进行实例的获取, 将枚举类型输入获取器.
public class A<T extends Enum<T>> {}
19.7 使用接口组织枚举
因为枚举类型不能进行子类的继承, 所以对于需要拓展枚举内容的时候需要使用子类对于enum中的元素进行分组
public interface Food{
enum Appetizer implements Food{
SALAS, SOUP, SPRING_SOLLS;
}
}
拓展枚举的方式:
interface Food{
enum Appetizer implements Food{
SALAD, SOUP, SPRING_ROLLS;
}
enum MainCourse implements Food{
LASAGNE, BURRITO, PAD_THAI, LENTILS, HUMMOUS, VINDALOO;
}
}
enum Course{
APPETIZER (Food.Appetizer.class),
MAINCOURSE (Food.MainCourse.class);
private final Food[] values;
private Course(Class<? extends Food> kind){
values = kind.getEnumConstants();
}
public Food getById(int id){
return values[id];
}
}
可以使用嵌套枚举类型将枚举实现为枚举的枚举
enum Course{
APPETIZER (Food.Appetizer.class),
MAINCOURSE (Food.MainCourse.class);
interface Food{
enum Appetizer implements Food{
SALAD, SOUP, SPRING_ROLLS;
}
enum MainCourse implements Food{
LASAGNE, BURRITO, PAD_THAI, LENTILS, HUMMOUS, VINDALOO;
}
}
private final Food[] values;
private Course(Class<? extends Food> kind){
values = kind.getEnumConstants();
}
public Food getById(int id){
return values[id];
}
}
19.8 使用EnumSet替代标志
enum也是具有Set的元素唯一的特性, 在Java5中引入了EnumSet, 作为enum的替代品, 用以替代基于int的标志位开关.
用于生成枚举类型组成的集合.
enum AlarmPoints{
STAIR1, STAIR2, LOBBY, OFFICE1, OFFICE2, OFFICE3
}
class MainClass{
public static void main(String[] args) {
EnumSet<AlarmPoints> emptyPoints = EnumSet.noneOf(AlarmPoints.class);
EnumSet<AlarmPoints> fullPoints = EnumSet.allOf(AlarmPoints.class);
EnumSet<AlarmPoints> points = EnumSet.of(
AlarmPoints.STAIR1,AlarmPoints.STAIR2,AlarmPoints.LOBBY);
}
}
EnumSet底层是64或者更多位的int, 和枚举类型的数值Id绑定
19.9 使用EnumMap
这是一种特殊的Map, 要求其中的键值必须来自一个enum, 因为枚举类型的特殊性, 所以其内部是通过列表进行实现的, 所以其速度特别快
使用EnumMap可以用于实现命令设计模式开发. 命令模式是只有单一方法的接口, 然后根据接口各有不同的行为分为多个子类. 通过构造命令对象进行运行
enum AlarmPoints{
A1, A2, A3
}
interface AlarmAction{
void action();
}
class MainClass{
public static void main(String[] args) {
EnumMap<AlarmPoints, AlarmAction> actionEnumMap = new EnumMap<AlarmPoints, AlarmAction>(AlarmPoints.class);
actionEnumMap.put(
AlarmPoints.A1,
new AlarmAction() {
@Override
public void action() {
System.out.println("action of A1");
// do something
}
});
actionEnumMap.get(AlarmPoints.A1).action();
}
}
19.10 常量相关的方法
通过在定义中定义抽象方法, 然后在每个枚举项目中实现该抽象方法. 因为每个枚举状态相当于 public static object, 所以其初始化时需要进行函数的定义
enum EnumClass{
APPROVAL_TYPE_1{
@Override
String getApproalTypes() {
return "ApprovalType1";
}
},
APPROVAL_TYPE_2{
@Override
String getApproalTypes() {
return "ApprovalType2";
}
};
abstract String getApproalTypes();
}
另一种定义方式 – 可以将枚举内容和动作进行绑定:
interface Interf{
void action();
}
enum EnumClass implements Interf{
ENUM_1{
@Override
public void action() {
System.out.println("action of enum 1");
}
}, ENUM_2{
@Override
public void action() {
System.out.println("action of enum 2");
}
};
}
可以覆盖外层函数的定义
interface Interf{
void action();
}
enum EnumClass implements Interf{
ENUM_1, ENUM_2{
@Override
public void action() {
System.out.println("action of enum 2");
}
};
@Override
public void action() {
System.out.println("default action of enums");
}
}
19.10.1 使用enum的职责链
职责链的设计模式可以使用不同的方式来解决一个问题. 将不同方式链接到一起, 当收到一个请求的时候遍历整个处理链条, 直到其中某个节点对于请求进行处理
@Data
@AllArgsConstructor
class Mail{
enum Address{HAS_ADDRESS, MISSING}
private Address hasAddress;
private String message;
}
class PostOffice{
enum OfficeHandler{
MESSAGE_HANDLER{
@Override
Mail handleMail(Mail m) {
if (m == null || m.getMessage() == null || m.getMessage().isEmpty()){
return null;
}
return m;
}
},
ADDRESS_HANDLER{
@Override
Mail handleMail(Mail m) {
if (m != null && m.getHasAddress().equals(Mail.Address.HAS_ADDRESS)){
return m;
}
return null;
}
};
abstract Mail handleMail(Mail m);
}
static Mail handleMail(Mail m){
Mail res = m;
for (OfficeHandler handler : OfficeHandler.values()) {
res = handler.handleMail(m);
}
return res;
}
public static void main(String[] args) {
Mail mail = new Mail(Mail.Address.HAS_ADDRESS,"hello world");
System.out.println(handleMail(mail));
}
}
19.10.2 使用enum的状态机
枚举类型非常适合用于创建状态机. 状态机是拥有有限个限定的状态, 其根据输入状态会转移到下一个状态. 不过也可存在瞬时状态
状态机的接口特征: 每个状态都可以接受输入, 不同的输入会使得状态机从当前状态转换到不同的新状态.
class VendingMachine{
enum State{
STARTING{
@Override
State next(Input input) {
return RUNNING;
}
},
RUNNING{
@Override
State next(Input input) {
return POST_RUNNING;
}
},
POST_RUNNING{
@Override
State next(Input input) {
return STOP;
}
},
STOP{
@Override
State next(Input input) {
return null;
}
};
abstract State next(Input input);
}
private State state = State.STARTING;
public void nextStep(Input input){
if (state == null){
return;
}
state = state.next(input);
}
}
19.11 多路分发
Java只支持单路分发, 如果是需要执行的操作包含了不止一个类型未知的对象时, Java的动态绑定机制只能处理其中一个类型
多路分发指的是对于动态绑定的对象, 可以选择特定的绑定对象进行函数的执行.
enum OutCome{WIN, LOSE, DRAW}
interface Item{
OutCome complete(Item i);
OutCome eval(Paper p);
OutCome eval(Scissors p);
OutCome eval(Stone p);
}
class Paper implements Item{
public OutCome complete(Item i) {
// 这个函数将按照this类型映射到下面三个函数
return i.eval(this);
}
public OutCome eval(Paper p) {
return OutCome.DRAW;
}
public OutCome eval(Scissors p) {
return OutCome.LOSE;
}
public OutCome eval(Stone p) {
return OutCome.WIN;
}
}
class Scissors implements Item{
// ...
}
class Stone implements Item{
// ...
}
19.11.1 使用enum分发
enum OutCome{WIN, LOSE, DRAW}
enum RoShamBo{
SCISSORS(OutCome.WIN,OutCome.DRAW,OutCome.LOSE),
PAPER(OutCome.DRAW,OutCome.LOSE,OutCome.WIN),
ROCK(OutCome.LOSE,OutCome.WIN,OutCome.DRAW);
private final OutCome vPaper;
private final OutCome vScissors;
private final OutCome vRock;
RoShamBo(OutCome paper, OutCome scissors, OutCome rock){
vPaper = paper;
vScissors = scissors;
vRock = rock;
}
public OutCome compete(RoShamBo it){
switch (it){
default: throw new IllegalArgumentException("illegal argument of RoShamBo");
case ROCK:return vRock;
case PAPER:return vPaper;
case SCISSORS:return vScissors;
}
}
public static void main(String[] args) {
System.out.println(SCISSORS.compete(SCISSORS));
}
}
19.11.2 使用常量相关的方法
19.11.3 使用EnumMap进行分发
使用双层的EnumMap形成了基于两个键值的搜索条件, 获取结果
19.11.4 使用二维数组
直接显式定义二维数组然后通过枚举变量的整形ID进行结果的获取.
19.12 总结
枚举可以与多态, 泛型, 反射进行灵活使用. 枚举是一个相对较小的功能, Java在没有枚举功能之前已经存在很久, 这一部分详细讲解了当引入这个小功能后对于代码设计的提升.
20 注解 P620 ~ P649
注解也被称为元数据, 是在代码中添加一些附加信息的方法, 使得我们可以在稍后的某个时刻方便的使用这些数据
注解在一定程度上把元数据和源代码文件结合在一起, 而不是将这些数据保存在外部文档中.
注解可以由编译器在测试和验证格式, 存储有关程序的额外信息, 注解可以用来描述文件, 新类型的定义, 减轻编写样板的负担
注解的语法比较简单: 使用@符号进行开头, 其他用法基本和java固有语法一致.
Java SE5内置了三种注解: @Override: 覆盖超类方法, @Desprecated: 如果使用了注解的信息会报出警告, @SuppressWarnings: 关闭不当的编译器警告信息
另外还有四种注解, 用于新注解的创建.
20.1 基本语法
例如测试工具中可以通过@Test注解, 使用反射而运行对应的函数. 注解可以与各种修饰符共同作用, 从语法角度而言, 注解的使用方式和修饰符的使用方式一模一样
20.1.1 定义注解
注解的定义和接口非常类似, 其使用中也会和其他接口一样被编译为class文件.
@Target(ElementType.METHOD) // 定义注解将应用于什么地方
@Retention(RetentionPolicy.RUNTIME) // 定义注解在哪个级别可用, 分为 source, class, runtime
public @interface TEST{
public int id();
public String description() default "NONE";
}
注解的元素在使用是表现为键值对的形式, 需要通过括号进行输入. 可以通过这种方式来勾勒出其需要建造的系统.
20.1.2 元注解
Java目前只内置了三种标准注解1以及四种元注解.
Target:CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPERetention:SOURCE, CLASS, RUNTIMEDocumented: 将其注解包含在javadoc中Inherited: 允许子注解继承父注解的注解
20.2 编写注解处理器
使用注解的过程中最重要的就是对于注解的处理器. 以下是一个非常简单的注解处理器
getDeclaredMethod: 是获取所有任何访问限制的函数,getMethod: 只是获取public的函数
@interface UseCase{
int id();
}
class Main{
public static void trackUserCases(Class<?> clz){
for(Method m : clz.getDeclaredMethod()){
UseCase annotation = m.getAnnotation(UseCase.class);
if (annotation != null){
// DO SOMETHING
}
}
}
}
20.2.1 注解元素
注解中只能使用以下几种类型:
- 基本类型:
int, float, boolean 等 - String, Class, enum, Annotation
- 以上所有类型的数组类型
@interface CallBackAnnotation{
Class<?>[] parameters();
int id() default 0;
}
class Main{
@CallBackAnnotation(parameters = {TrialHash.class, MapableClass.class})
public void funct(){
// DO SOMETHING
}
}
20.2.2 默认值的限制
编译器对于元素的默认值有些过分挑剔, 元素中不允许存在不确定的值, 元素必须要有默认值或者是在注解时提供元素的值.
对于非基本类型的元素, 无论是在源代码中声明或者在接口中定义默认值, 都不能以null为其值(因为null值需要被用于区分对象是否存在). 如果想要定义一些空值只能自己手动定义.
class NullClass{}
@interface UseCase{
Class<?> clz() default NullClass.class;
}
20.2.3 生成外部文件
注解的一个重要应用场景是通过添加一些额外信息, 与代码进行协同工作, 用于导出外部文件. 其优势在于描述和代码内容集合在一起, 减小了对于文件消息的同步.
20.2.4 注解不支持继承
不能使用extend继承某个接口
20.2.5 实现处理器
注解处理器例子, 通过读取类文件, 检查其数据库注解, 并且生成用于创建数据库表的SQL. 通过函数访问注解中的类型定义, 字段名称, 然后进行字符串的拼接
20.3 使用apt处理注解
这是一个sun提供的帮助注解处理过程提供的工具, 操作对象为java源文件. 在操作的过程中是一次次地扫描源文件以及内容, 然后根据注解自动创建新的源文件. 会不断检查新增的文件直到没有文件增加后才将所有的文件一同编译.
这是通过定义并实现AnnotationProcessorFactory的工厂类的, 实例化正确的注解处理器, 然后对于注解进行处理.
相当于是定义预处理器对于注解进行解析和处理. 其对应的注解为保留到Source的注解.
通过定义AnnotationProcessorFactory向apt中添加自定义的预处理功能, 然后对于代码进行处理.
20.4 将观察者模式应用于apt
以观察者的设计思路编写apt中的处理逻辑, 对于源代码进行处理.
20.5 基于注解的单元测试
一个典型的基于注解的单元测试就是JUnit的单元测试.通过单元测试的@Unit的注解, 其能够在对象代码内部进行测试的函数, 而且因为可以使用任务访问权限所以其还能够不影响任何的外部使用.
对于非嵌入式的测试, 一般都是通过继承进行类型的测试.
对于使用非嵌入式测试需要使用JavaAssert进行结果的判断.
20.5.1 将@Unit用于泛型
对于泛型的测试需要针对泛型的某个特定版本, 而不是针对笼统的泛型进行测试
20.5.2 不需要任何套件
不需要任何测试套件, 只是简单地搜索文档中的注解, 然后对于文档中的标记进行对应的执行
20.5.3 实现@Unit
通过反射机制抽取需要测试的对象, 根据注解中的参数决定如何进行对象的构造并且在测试对象上进行测试
20.5.4 移除测试代码
通过开源的Javassist工具库对于字节码能够进行操作, 删除@Test相关的内容
可以操作类的字节码, 对于字节码进行处理, 然后将处理后的
20.6 总结
注解是一种结构化具有类型检查功能的新的编写途径, 可以以更加内聚的方式进行与类有关信息的说明
可以使用apt工具对于代码进行重新编译生成新的class文件, 使用mirrorAPI对于构建过程进行简化, 使用功能Javassist进行字节码的操作
21 并发 P650 ~ P767
当在处理一些问题的时候并行的执行部分内容, 可以能够在多处理器环境下进行高效地运行
并发具有可论证的正确性但是实际上具有不可确定性. 通过仔细设计和代码审查编写能够正确工作的并发代码是可能的, 但是实际情况中容易发生编写的并发程序在某些特定的工作条件的时候会工作失败.
研究并发问题的最大理由: 如果视而不见, 你就会遭到反噬
21.1 并发的多面性
使用并发解决的问题主要分为速度和设计可管理性两种问题
21.1.1 更快的执行
由于摩尔定律在单核处理器上已经过时, 所以需要了解如何充分利用多核处理器的处理性能, 以及在出现IO阻塞情况下的单核处理性能.
并发通常是提高单处理器上的程序性能. 因为有阻塞情况, 所以并发能够充分利用单核性能
在单处理器系统中的性能提升的常见示例为事件驱动编程. 并发之所以进入大家视野最主要的是在进行GUI编程的时候需要产生可实时响应的用户界面. 只用单独的执行线程来响应用户的输入, 即使该线程在大多数时间内都是阻塞的, 但是程序可以保持有一定程度的可响应性.
实现先并发分为不同层次: 最直接的方式是操作系统级别使用的进程, 通过操作系统周期性的将CPU从一个进程切换到另一个进程进行多个程序的并行. 和其不同Java中的并发系统会共享内存以及IO资源, 使得编写多线程的最基础困难是协调不同线程驱动任务之间对这些资源的使用.
有些人认为应当将进程作为实现并发的唯一方式, 但是由于系统中对于进程的数量和开销限制, 所以这种思路会出现很多问题.
某些被设计为可以将并发任务彼此隔离的语言, 通常被称作函数型语言, 因为其中任何一个函数的调用都不会产生任何的副作用. 可以完全按照独立任务进行驱动. Erlang就是这样的编程语言.
当在程序的某个部分遇到了过多的问题时可以考虑使用专门设计的并发语言进行这部分的编程.
Java采用了更加传统的实现方式: 在顺序形语言的基础上对于线程提供支持.
和使用进程实现并发不同, 线程的并发是在单一进程中创建任务, 其好处是有操作系统的透明性, 即使操作系统原生并不支持多线程, 但是可以通过JVM的线程系统达到进行并发的效果.
21.1.2 改进代码设计
理论上可以使用线性编程不用任何并行编写出相同功能的程序. 但是使用了并发结构之后程序设计可以极大地简化, 例如仿真或者画面生成. 因为其中每一个交互元素都有自己的想法,
Java的线程是协作多线程, 通过抢占式线程调度将线程的上下文进行转换. 由于是协作式多线程每个任务都会自动放弃控制, 要求在么个任务中插入某种类型的让步语句. 协作式的系统优势是上下文开销比抢占式系统低廉许多, 对于协作系统的线程数量在理论上没有任何限制.
当需要使用大量的仿真元素的时候, 协作式多线程是一种理想的解决方案,
在消息系统工作时, 由于消息系统分布在整个网络中多态独立计算机, 使用并发是一种非常有用的模型.
21.2 基本的线程机制
通过时间片分配机制在多个线程中构建并发的运行模式
21.2.1 定义任务
通过Runnable接口提供线程的定义, 实现run方法之后运行对应函数任务.
Thread.yield是对线程调度器, 其是Java线程机制一部分, 可以将CPU从一个线程转移给另一个线程, 是通过声明我已经执行完生命周期的最重要部分, 让资源自动传递给其他线程
直接使用Main函数调用该函数接口的时候是直接在主线程上进行运行. 如果需要产生内在的线程能力, 需要将任务依附到一个线程上
21.2.2 Thread类
Thread是一个构造器, 通过start在进行线程的创建和运行.
class LiftOff implements Runnable {
private static int taskCount = 0;
private final int id = taskCount++;
protected int countDown = 10;
@Override
public void run() {
while (countDown-- > 0) {
System.out.printf("#%d(%s),", id, (countDown > 0 ? Integer.toString(countDown) : "LiftOff!"));
Thread.yield();
}
}
}
public class ThreadTestMain {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
Thread thread = new Thread(new LiftOff());
thread.start();
}
System.out.println("Waiting for LiftOff");
}
}
21.2.3 使用Executor
可以使用Executor管理Thread对象. 在Executor在客户端和任务执行之间提供了连接层, 使用CashedThreadPool为每个任务创建一个线程
class CachedThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 3; i++) {
executorService.submit(new LiftOff());
}
executorService.shutdown(); // 用于防止新的任务被提交为Executor
}
}
使用FixedThreadPool提供有限的线程在执行所提交的任务, 如果超过线程限制, 不会报错, 但不会运行. 使用awaitTermination用于等待线程执行完毕, 可以设置执行超时时间
class TestThreadPool {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
for (int i = 0; i < 3; i++) {
executorService.submit(new LiftOff());
}
executorService.shutdown();
System.out.println("finish shutdown");
executorService.awaitTermination(3, TimeUnit.SECONDS);
System.out.println("finish termination");
}
}
21.2.4 从任务中产生返回值
可以使用Callabel设置有返回值无参数值的函数
class TaskWithResult implements Callable<String>{
private static int counter = 0;
private final int id = counter++;
@Override
public String call() throws Exception {
return String.format("result of TaskWithResult # %d", id);
}
}
class TestThreadPool {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executorService = Executors.newCachedThreadPool();
ArrayList<Future<String>> futures = new ArrayList<>();
for (int i = 0; i < 10; i++) {
futures.add(executorService.submit(new TaskWithResult()));
}
System.out.println("flag 1");
for (Future<String> f : futures) {
System.out.println(f.get());
}
executorService.shutdown();
}
}
21.2.5 休眠
使用Thread.sleep进行线程的休眠
21.2.6 优先级
可以设置线程的重要性, 通过调度器倾向于将优先权最高的线程先执行, 对于低权限线程也不会造成死锁.
在绝大多数时间内, 线程应当使用默认优先级进行运行, 试图设置线程优先级通常是一种错误
可以使用getPriority来读取线程的优先级, 通过setPriority进行优先级的设置, 其权重范围为1~10的int
class TaskWithResult implements Callable<String>{
private static int counter = 0;
private final int id = counter++;
@Override
public String call() throws Exception {
Thread.currentThread().setPriority(id % 9 + 1);
return String.format("result of TaskWithResult # %d", id);
}
}
由于Java中优先级的数目和操作系统中的线程优先级的数目不同. 映射是不确定的. 推荐只使用三个优先级的值: MAX_PRIORITY, NORM_PRIORITY, MIN_PRIORITY
21.2.7 让步
使用yield作为让步提示只是对于当前运行状态的一个暗示, 针对不同CPU不同系统可能其不会对运行调度进行更改.
21.2.8 后台线程
后台线程指的是在程序运行时在后台提供通用服务的线程, 并且该线程不属于程序中不可或缺的部分. 只要有任何非后台线程还在运行, 程序就不会终止. 只有当所有非后台的线程还在运行, 程序就不会终止
main函数就是一个典型的非后台线程
创建一个后台线程的方式
class TestThreadPool {
public static void main(String[] args) {
Thread thread = new Thread(new LiftOff());
thread.setDaemon(true);
thread.start();
}
}
可以看到当main关闭后后台线程也关闭了
class LiftOff implements Runnable {
private static int taskCount = 0;
private final int id = taskCount++;
protected int counter = 0;
@Override
public void run() {
while (true) {
counter ++;
System.out.printf("id:%d#counter%d", id, counter);
try {
Thread.sleep(1000*1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class TestThreadPool {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new LiftOff());
thread.setDaemon(true);
thread.start();
Thread.sleep(1000*10);
}
}
可以调用isDaemon来确定线程是否是一个后台线程, 如果一个线程是一个后台线程, 其创建的任何线程被自动设置为后台线程.
21.2.9 编码的变体
目前的所有示例都是通过实现Runnable在这种, 但是可以使用继承拓展Thread实现线程对象
class SimpleThread extends Thread {
private static int threadCount = 0;
private int countDown = 10;
public SimpleThread() {
super(Integer.toString(threadCount++));
start();
}
public static void main(String[] args) {
new SimpleThread();
}
public void run() {
while (true) {
System.out.println(this);
if (countDown-- == 0) {
return;
}
}
}
@Override
public String toString() {
return "#" + getName() + "(" + countDown + "),";
}
}
需要注意在构造器中开启线程, 可能会造成访问不完整的对象的情况
class SimpleThread implements Runnable {
private static int threadCounter = 0;
private final int threadNumber = threadCounter++;
private final int countDown = 10;
private Thread thread;
public SimpleThread(){
thread = new Thread(this);
thread.start();
}
@Override
public void run() {
for (int i = 0; i < countDown; i++) {
System.out.printf("#%d:%d,",threadNumber,i);
}
}
public static void main(String[] args) {
new SimpleThread()
}
}
因为可能会导致访问不完整对象, 应当尽量使用Executor而不是显式的创建Thread.
21.2.10 术语
java类库中对于Thread类型没有任何的实际控制权. Thread类型自身并不执行任何操作, 只是驱动其任务, Runnable的类型和“任务”类型的概念相当接近. Java的线程机制基于来自C的低级的p线程方式.
在进行这些讨论的时候, 对于需要执行的工作使用术语任务, 只有在驱动任务的具体机制时才使用术语线程
21.2.11 加入一个线程
一个线程可以在其他线程上调用join方法. 其效果是等待一段时间直到第二个线程接收
可以设置超时参数, 如果目标时间线程还没有结束的时候, join方法也能够进行返回
class Sleeper implements Runnable {
private final Thread thread;
private final int duration;
public Sleeper(String name, int sleepTime) {
duration = sleepTime;
thread = new Thread(this, name);
thread.start();
}
public static void main(String[] args) throws InterruptedException {
Sleeper thread_1 = new Sleeper("thread_1", 1000);
System.out.println(123);
thread_1.getThread().join();
System.out.println(1234);
}
@Override
public void run() {
System.out.println(thread.getName() + " has started");
try {
Thread.sleep(duration);
} catch (Exception e) {
e.printStackTrace();
return;
}
System.out.println(thread.getName() + " has awakened");
}
public Thread getThread() {
return thread;
}
}
21.2.12 创建有响应的用户界面
class ReactiveUi implements Runnable {
private static double value = 1;
private final Thread thread;
public ReactiveUi() {
thread = new Thread(this);
thread.start();
}
public static void main(String[] args) throws IOException {
new ReactiveUi();
while (true) {
System.in.read();
System.out.println(value);
}
}
@Override
public void run() {
try {
while (true) {
Thread.sleep(1000);
value = value + (Math.PI + Math.E) / value;
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
21.2.13 线程组
线程组是通过一个线程集合对于线程进行管理, 其设计有问题, 价值不高
21.2.14 捕获异常
由于线程的本质特征, 所以无法从线程捕获逃逸的异常. 对于向外传播的异常, 当越过run方法之后就会传递到控制台.
目前对于线程异常的处理, 可以通过Executor进行处理, 所以不再需要使用线程组进行执行. 在Java 5中有Thread.UncauchtExceptionHandler对于线程中的异常进行处理
@Slf4j
class TestThreadPool {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new LiftOff());
thread.setDaemon(true);
thread.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
log.error(t.getName(),e);
}
});
thread.start();
Thread.sleep(1000 * 10);
}
}
21.3 共享受限资源
21.3.1 不正确的访问资源
对于基础类型的更新操作是原子性的, 所以可以使用对于boolean标志的状态更改进行对象的加锁解锁
21.3.2 解决共享资源竞争
对于并发工作需要以某种方式防止两个任务访问相同的资源. 当一个资源被一个任务使用的时候需要对其进行上锁.
基本上所有并发模式在解决线程冲突的时候都是采用序列化访问共享资源的. 通过在代码之前加上一条锁语句, 使得在同一时间中只有一个任务能够访问对应代码. 因为锁语句产生了一些相互排斥的效果, 其机制经常被称为互斥量
Java提供关键字synchronized的形式. 为了防止资源冲突提供了内部的支持. 对于该关键字修饰的代码块在运行时会先查询锁是否可用, 获取锁, 执行代码, 释放锁.
synchronized只能够修饰函数, 如果对于一些字段需要使其成为线性访问的, 需要设置getter, setter并且将函数设置为线性访问.
class TestClassSync {
private String value;
public synchronized String getValue() {
return value;
}
public synchronized void setValue(String value) {
this.value = value;
}
}
针对每一个类, 也有一个锁, 所以synchronized static可以在类的范围内防止对于static数据的并发访问.
使用显示的Lock对象进行加锁:需要被显式的创建锁定和释放.
class MutexTestClass{
private Lock lock = new ReentrantLock();
public int funct(){
lock.lock();
try{
return 0;
}catch (Exception e){
return 1;
}finally{
lock.unlock();
}
}
}
21.3.3 原子性与易变性
一个不正确的知识是原子操作不操作进行同步控制.
如果你可以编写用于现代微处理器的高性能JVM, 那么就有资格去考虑是否可以避免同步
原子性可以应用于除long和double之外的所有基本类型的简单操作. 因为JVM可以将64位的数据当做两个分离的32位数值进行执行, 所以可能会发生看到不正确的结果, 这种由于两个分离操作导致的错误被称为字撕裂
当使用long和double时, 如果可以使用volatile关键字, 可以获得操作的原子性.
原子操作可以由线程机制来保证其不会出错. 专家级的程序员可以使用这一点编写无锁的代码, 但是部分看似安全的方式其实也会造成访问的问题.
volatile关键字还保证了应用中的可见性, 当将一个域声明为volatile时, 当对这个域进行写入操作, 所有的读操作都可以看到其的修改.
需要注意java中的++, --操作并不是原子操作
21.3.4 原子类
指的是java中提供的AtomaticInteger, AtomaticLong, AtomaticReference的原子类型.
通过以下的原子性操作进行更新: compareAndSet(expectedValue, updateValue)
一般而言对于编程而言, 其是并不常用的, 但是对于需要进行性能调优的时候, 由于这些原子类都是在机器码上的原子性, 所以效率比手写的原子性操作更好
21.3.5 临界区
临界区语法用于防止多个进程访问方法内部的部分代码的情况, 是一种在方法内部进行加锁的方式
synchronized (targetObj){ // 在进入后续代码之前需要得到targetObject对象的锁, 并在完成后进行释放
// 这部分代码只能被单一线程访问
}
String s = "";
synchronized (s) {
System.out.println(s);
}
21.3.7 线程的本地存储
通过根除变量的共享属性来解决多线程场景下对象访问的冲突. 需要使用java.lang.ThreadLocal类进行实现
其中的ThreadLocal对象是一个泛型类, 通过传入需要存储的数据的类型, 在底层维护一个并行的Map, 针对每个ThreadId构建其独有的对象. 其通过get, set进行对象的访问, 通过get获取对象的一个可读副本, 通过set将对象写入到对应空间.
一般ThreadLocal被当做静态域进行存储, 因为其性质决定其存储的内容应当是在每个线程中都存在的内容, 所以当作为动态对象存储的时候其可能会出现有字段为空的情况.
21.4 终结任务
传统上而言是通过一个canceledFlag对于任务的执行状态进行配置, 然后根据这个结束Flag进行关闭流程的处理. 但是有时我们需要更加突然的关闭行为.
21.4.2 在阻塞时终结
在代码中存在sleep的时候, 由于其会使得线程成为阻塞状态, 需要特别设计使其能够正确返回
一个运行时的线程可以是以下四种状态之一:
- 新建状态: 只当线程被创建时其会短暂存在于该状态
- 就绪状态: 该状态指的是线程在等待时间片分配器对于时间片的分配
- 阻塞状态: 线程能够运行, 但是某个条件阻止其运行
- 死亡状态: 该线程是不可被调度的, 也不再会接收到CPU的时间分配
进入阻塞状态的方式:
- 通过sleep进行阻塞
- 通过wait使线程挂起, 直到得到notify后才会开启
- 任务在等待某个输入或者输出完成
- 任务试图在访问一个对象的锁, 但是其锁已经被占用.
如果希望终止处于阻塞状态的任务, 需要令其主动跳出阻塞状态然后进行终止
21.4.3 中断
对于保存了Thread对象的情况, 可以通过手动调用interrupt方法来终止其执行. 对于保存在Executor中的多线程情况, 可以通过executo.shutdownNow由Executor替代用户向所有线程发送interrupt
21.5 线程之间的协作
21.5.1 wait与notifyAll
通过wait将线程进行阻塞, 然后通过notifyAll进行继续的执行
调用notifyAll比调用notify更加安全.
21.5.3 生产者与消费者
这是一种设计思路, 其可以通过wait-notify进行实现或者是使用生产者-消费者队列进行实现.
21.5.4 任务间使用功能管道进行输入和输出
使用PipedWriter可以使用管道进行数据的输入和输出, 或者使用BlockingQueue进行数据的输入或者输出
21.6 死锁
死锁发生的四个条件:
- 互斥条件: 使用的资源中至少有一个是不可共享的
- 至少有一个任务必须持有一个资源且正在等待另一个被其他应用持有的资源
- 资源无法被强行抢占, 一个任务只能通过等待的方式获取其他任务所持有的资源
- 必须有循环等待
21.7 使用新库中的构建进行并发的实现
21.7.1 CountDownLatch
其有一个计数值, 在该对象上调用wait方法, 只有在其值到达0的时候, 其才能进行后续执行. 其是一个不能被重置的触发器
可以使用CyclicBarrier进行可重置的触发
21.7.2 CyclicBarrier
这是一个可以重置计数器的CountDownLatch, 可以手动进行任务的重置.
21.7.3 DelayQueue
这是一个无界的BlockQueue, 用于防止实现了Delay接口的对象, 其中的对象只能在其到期时才能从队列中取走. 该队列是有序的. 队头对象的延迟到期时间最长.
21.7.4 PriorityBlockingQueue
基础的优先级队列, 其读取操作可被阻塞. 通过一定的优先级数值进行任务的排序.
21.7.5 ScheduledExecutor
该模块可以指定任务触发执行的时间, 可以通过设置进行定时任务的实现.
21.7.6 Semaphore
该对象是一个计数信号量, 可以运行N个任务访问该资源, 是一种限定总数的协议分发方式
可以用其进行对象池的实现, 当用户需要使用某个对象的时候, 使用Semaphore进行对象的签出, 当使用完成后进行对象的释放.
21.7.7 Exchanger
两个任务在进入Exchanger时都持有一个对象, 当两个线程离开Exchanger的时候其持有的对象发生互换.
21.8 仿真
并发最有价值的应用方式就是仿真
通过并行的线程对于实际生活中的每个执行者的行为进行仿真, 可以得到最终的总体结果
21.9 性能调优
21.9.1 各种互斥技术之间的比较
使用Lock通常比使用synchronized要高效很多, 而且synchronized的开销看起来变化范围太大. 但是相比而言, 使用synchronized的方式的可读性更高. 一般在实现的时候以synchronized进行入手, 当需要进行性能调优的时候再改为使用Lock
21.9.2 免锁容器
免锁容器的策略是: 对于容器的修改和访问是可以同时发生的, 只要读者被限制只能访问修改完成后的结果即可.
例如CopyOnWriteArrayList中进行写入会导致创建整个底层数组的副本, 源数据被临时保存, 使得读操作可以被安全地执行, 当修改完成后使用一个原子性的操作将新的数组进行换入, 进行源数据的更新.
因为线性化的操作被省略掉了, 所以对于免锁容器的读取, 其效率是更高的. 但是由于其对于写入有换入操作, 其写入操作不能过多.
21.9.3 乐观加锁
所谓乐观加锁指的是当执行某个计算的时候实际上没有使用互斥, 但是当计算完成后想要使用该对象的时候会存在一个compareAndSet的方法, 如果发现其他任务在操作期间操作了对象就会执行失败.
其加锁逻辑是乐观的, 即是认为没有人来操作数据. 其应用范围是受到局限的, 只有能够对于操作失败的情况进行恢复的业务中才能够使用这种设计方式.
21.9.4 读写锁
对于不需要频繁写入但是需要频繁读取的数据可以使用读写锁进行加锁. 当对象被写入的时候任何读取者都不能读取.
一般用于程序性能优化时进行使用.
21.10 活动对象
这是一种用于替代并发的编程思路, 其产生原因是面向对象的编程思想. 而线程并发的思想是一种面向过程编程的思想.
其中的设计逻辑是每个活动的对象维护其自己的工作线程和输入队列. 在活动对象中的所有通信都是通过消息的形式进行传输. 任何的消息在被处理之前都要进行排队.
21.11 总结
并发编程设计的功能
- 可以运行多个独立的任务
- 必须考虑当需要关闭这些任务的时候, 可能出现的所有问题
- 任务可能会在共享资源生彼此干涉, 使用互斥锁进行解决这种冲突
- 当程序设计得不恰当的时候会出现死锁
多线程的主要缺陷
- 等待共享资源会导致性能降低
- 需要处理线程的额外CPU花费
- 如果使用糟糕的程序设计会导致不必要的性能花费
- 有可能早出一些病态行为: 饿死, 竞争, 死锁, 活锁
- 不同平台之间的表现不一致: 由于对于线程的操作方式不同, 在不同平台上出现的表现不同.
线程应用上的一些技巧:
- 理论上Java支持任意数量的对象来解决问题(但是在进行有限元分析时的百万级对象的情景下会出现问题)
- 线程的声明数量是有不明确的上界的, 当线程声明过多, 会导致性能的骤降, 一般线程数在一百以下
2022.10.24 完成了对于以上内容的阅读和学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号