
Interactive Search for One of the Top-k 阅读笔记 (更新中)
论文作者: Weicheng Wang, Raymond Chi-Wing Wong, Min Xie
1. 基本思想:
-
-
通过询问用户问题, 获取在询问的集合中通过获取局部最优值, 逼近全局最优解
-
在二维平面中通过
2D-PI的算法进行计算, 在更高维度是通过HD-PI,RH进行计算
2. 相关论文:
-
对于是否需要用户进行能动地响应, 推荐算法被分为
preference-based queries和interactive queries-
preference-based queries:
-
top-𝑘 query
-
skyline query
-
similarity query [4, 32]:
通过寻找对象组之间的相似性进行推荐, 但是其前提是对象组已知以及对象之间的距离可测量
-
regret minimizing query [10, 23, 25]
通过定义一个regret ratio用于衡量用户基于该返回元组做出判断后的后悔水平, 找到一个推荐元组使得用户的后悔概率最小. 但是很难保证regret ratio和元组大小的同时较小
-
-
user interaction queries:
-
interactive skyline query: [2, 3, 18]
通过与用户进行互动地信息获取, 减小推荐元组的大小, 但是其只学习了用户对于对象属性的偏好程度
-
interactive similarity query: [5, 6, 31]
通过学习
query tuple和distance function进行更好的预测. 但是需要训练的数据量很大, 而且需要用户对于推荐元组进行可量化的打分, 以此衡量推荐元组与最优元组之间的距离 -
interactive regret minimizing query: [22]
通过询问用户问题, 令其选择集合中最想要的对象进行建模. 但是其会伪造出一些不切实际的数据使用户感到被欺骗
为了解决数据不切实际的问题 [36] 提出了UH-Simplex and UH-Random 算法使用数据库中的已有数据进行训练. 但是还是需要巨量的训练数据. 这两个算法在文献[40]中有改进函数:Sorting-Simplex 和 Sorting-Random. 虽然在思路上试图减小用户参与, 但是实际上效果不佳
-
interactive preference learning:[15, 27]
[27]提出Preference-Learning算法通过进行每对比较学习用户的preference信息. 但是由于其倾向于建立一个全局的描述函数, 而忽视了实际只需要推荐的K个项目总体较佳, 导致其用户参与量更大
[15]中是基于未定义的属性进行用户需求的学习
-
learning to rank [12, 14, 19, 21]
[12, 19, 21]只是基于推荐元素之间的关系进行学习, 而没有基于一些
内在规律– 个人认为这里是使用统计学的一些定性参数 -
本文中的模型设计:
-
不需要用户提供显式的utility function
-
模型的目标是返回的目标是全局最优的K个目标之一
-
只使用真实数据进行推荐
-
对于用户交互的量要求较少
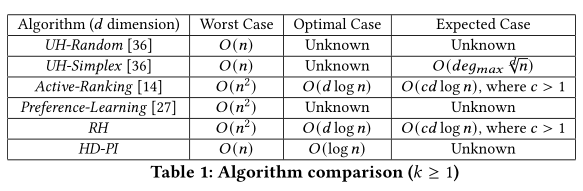
以下是各个算法对于用户参与量的要求(来自论文)
![]()
-
-
-
3. 问题定义:
-
问题的输入是一个大小为n的集合D, 集合中的元素是对象的特征向量, 特征向量的长度为d. 每个向量被认为是d维空间内的点
-
特征向量 p 的第 i 维度的值是 p[i] (𝑖 ∈ [1,𝑑] 且为整数), 且在处理本问题时认为 p[i] 被正则化到 (0,1] 区间之中, 且如果 p[i] 的值越大则意味着该对象的该维度的属性更加受到人们喜欢
-
对于用户的兴趣大小的函数(utility function)是一个对象的向量的各个维度的兴趣的加权和: f(p) = Σ(i from 1 to d) u[i]*p[i]. 也可以写成向量内积的形式: 𝑓 (𝑝) = 𝑢 · 𝑝 , 这里的f是一个从d维到1维的映射, 这里的权重向量u是一个d维度且每个维度大于零的向量 (为什么大于零: 因为已知f随p的任何一项的增大而增大, 所以系数大于零)
-
u[i] 表示的是用户对于 p[i] 维度的感兴趣程度 (这里就和协同过滤的思路是一致的) 在本文中 u 被称为 utility vector, 并且将 v 的域称为 utility space
-
通过对对象的基本属性进行获取从而得到p, 然后对于u进行学习从而可以获得全局最优的k个解
-
由于对于u进行任意整数的数乘, 其最后得到的全局最优的k是不变的, 所以人为规定 u 的各个维度的和等于1, 所以 u 的空间是一个 d-1 维的可剖分空间 (例如, 当d = 2时, u[1] + u[2] = 1, 是一条一维的直线)
-
模型的目标是基于一个点集D, 返回一个点, 该点是用户全局的top k
-
模型获取信息的逻辑是在每一轮选取一对点作为问题提供给用户, 令其选择其更喜欢哪个, 并且尽可能地减少问题的数量
-
模型主要解决的问题以及其解决思路:
-
问题: 尽可能地减少提问的数量
-
解决理论: 对于任意一个大小为n的集合, 至少需要询问 log2(n/k) 个问题以获取一个位于全局topk中的点 由这里可以看出, 其基本思路是二分法的不完全搜索
-
简单证明: 对于一个集合D, 其中有 k-1 个点 q 使得 对于 p 中的任意维度, p[i] = q[i]. 所以可以证明至少需要 log2(n/k) 就可以获取 topk 元素
原文:
![]()
-

4. 二维下的算法:
-
𝑢[1] + 𝑢[2] = 1 -> 𝑓 (𝑝) = 𝑢[1]𝑝[1] + (1 − 𝑢[1])𝑝[2] -> 𝑓 (𝑝) = (𝑝[1] − 𝑝[2])𝑢[1] + 𝑝[2]
-
优化的目标是通过调整 𝑢[1] 使得 𝑓 (𝑝1) 和 𝑓 (𝑝2) 之间的大小关系和用户评价的大小关系一致
References (从论文中拷贝)
[1] Abolfazl Asudeh, Azade Nazi, Nan Zhang, Gautam Das, and H. V. Jagadish. RRR: Rank-Regret Representative. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 263–280.
[2] Wolf-Tilo Balke, Ulrich Güntzer, and Christoph Lofi. 2007. Eliciting Matters – Controlling Skyline Sizes by Incremental Integration of User Preferences. In Advances in Databases: Concepts, Systems and Applications. Springer Berlin Hei- delberg, Berlin, Heidelberg, 551–562.
[3] Wolf-Tilo Balke, Ulrich Güntzer, and Christoph Lofi. 2007. User Interaction Support for Incremental Refinement of Preference-Based Queries. In Proceedings of the First International Conference on Research Challenges in Information Science. 209–220.
[4] Ilaria Bartolini, Paolo Ciaccia, Vincent Oria, and M. Tamer Özsu. 2007. Flexible integration of multimedia sub-queries with qualitative preferences. Multimedia Tools and Applications 33, 3 (2007), 275–300.
[5] Ilaria Bartolini, Paolo Ciaccia, and Marco Patella. 2014. Domination in the Probabilistic World: Computing Skylines for Arbitrary Correlations and Ranking Semantics. ACM Transactions on Database System 39, 2 (2014).
[6] Ilaria Bartolini, Paolo Ciaccia, and Florian Waas. 2001. FeedbackBypass: A New Approach to Interactive Similarity Query Processing. In Proceedings of the 27th International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 201–210.
[7] Stephan Börzsönyi, Donald Kossmann, and Konrad Stocker. 2001. The Skyline Operator. In Proceedings of the International Conference on Data Engineering. 421–430.
[8] Wei Cao, Jian Li, Haitao Wang, Kangning Wang, Ruosong Wang, Raymond Chi-Wing Wong, and Wei Zhan. 2017. k-Regret Minimizing Set: Efficient Algo- rithms and Hardness. In 20th International Conference on Database Theory. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany, 11:1–11:19.
[9] Bernard Chazelle. 1993. An Optimal Convex Hull Algorithm in Any Fixed Dimension. Discrete Computational Geometry 10, 4 (1993), 377–409.
[10] Sean Chester, Alex Thomo, S. Venkatesh, and Sue Whitesides. 2014. Computing K-Regret Minimizing Sets. In Proceedings of the VLDB Endowment, Vol. 7. VLDB Endowment, 389–400.
[11] Mark De Berg, Otfried Cheong, Marc Van Kreveld, and Mark Overmars. 2008. Computational geometry: Algorithms and applications. Springer Berlin Heidel-berg.
[12] Brian Eriksson. 2013. Learning to Top-k Search Using Pairwise Comparisons. In Proceedings of the 16th International Conference on Artificial Intelligence and Statistics, Vol. 31. PMLR, Scottsdale, Arizona, USA, 265–273.
[13] Yunjun Gao, Qing Liu, Baihua Zheng, Li Mou, Gang Chen, and Qing Li. 2015. On processing reverse k-skyband and ranked reverse skyline queries. Information Sciences 293 (2015), 11–34.
[14] Kevin G. Jamieson and Robert D. Nowak. 2011. Active Ranking Using Pair-wise Comparisons. In Proceedings of the 24th International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA, 2240–2248.
[15] Bin Jiang, Jian Pei, Xuemin Lin, David W. Cheung, and Jiawei Han. 2008. Mining Preferences from Superior and Inferior Examples. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, New York, NY, USA, 390–398.
[16] Georgia Koutrika, Evaggelia Pitoura, and Kostas Stefanidis. 2013. Preference-Based Query Personalization. Advanced Query Processing (2013), 57–81.
[17] Jongwuk Lee, Gae-won You, and Seung-won Hwang. 2009. Personalized top-k skyline queries in high-dimensional space. Information Systems 34 (2009), 45–61.
[18] Jongwuk Lee, Gae-Won You, Seung-Won Hwang, Joachim Selke, and Wolf-Tilo Balke. 2012. Interactive skyline queries. Information Sciences 211 (2012), 18–35.
[19] Tie-Yan Liu. 2010. Learning to Rank for Information Retrieval. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, New York, NY, USA, 904.
[20] Alchemer LLC. 2021. https://www.alchemer.com/resources/blog/how-many-survey-questions/
[21] Lucas Maystre and Matthias Grossglauser. 2017. Just Sort It! A Simple and Effective Approach to Active Preference Learning. In Proceedings of the 34th International Conference on Machine Learning. 2344–2353.
[22] Danupon Nanongkai, Ashwin Lall, Atish Das Sarma, and Kazuhisa Makino. 2012. Interactive Regret Minimization. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 109–120.
[23] Danupon Nanongkai, Atish Das Sarma, Ashwin Lall, Richard J. Lipton, and Jun Xu. 2010. Regret-Minimizing Representative Databases. In Proceedings of the VLDB Endowment, Vol. 3. VLDB Endowment, 1114–1124.
[24] Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger. 2005. Progres-sive Skyline Computation in Database Systems. ACM Transactions on Database Systems 30, 1 (2005), 41–82.
[25] Peng Peng and Raymond Chi-Wing Wong. 2014. Geometry approach for k-regret query. In Proceedings of the International Conference on Data Engineering. 772–783.
[26] Peng Peng and Raymong Chi-Wing Wong. 2015. K-Hit Query: Top-k Query with Probabilistic Utility Function. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 577–592.
[27] Li Qian, Jinyang Gao, and H. V. Jagadish. 2015. Learning User Preferences by Adaptive Pairwise Comparison. In Proceedings of the VLDB Endowment, Vol. 8. VLDB Endowment, 1322–1333.
[28] QuestionPro. 2021.https://www.questionpro.com/blog/optimal-number-of-survey-questions/
[29] Melanie Revilla and Carlos Ochoa. 2017. Ideal and Maximum Length for a Web Survey. International Journal of Market Research 59, 5 (2017), 557–565.
[30] J.-R. Sack and J. Urrutia. 2000. Handbook of Computational Geometry. North-Holland, Amsterdam.
[31] Gerard Salton. 1989. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer. Addison-Wesley Longman Publishing Co.,Inc., USA.
[32] Thomas Seidl and Hans-Peter Kriegel. 1997. Efficient User-Adaptable Similarity Search in Large Multimedia Databases. In Proceedings of the 23rd International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 506–515.
[33] Mohamed A. Soliman and Ihab F. Ilyas. 2009. Ranking with uncertain scores. In Proceedings of the International Conference on Data Engineering. 317–328.
[34] Weicheng Wang, Raymond Chi-Wing Wong, and Min Xie. 2021. Interactive Search for One of the Top-k. Technical Report. http://www.cse.ust.hk/~raywong/paper/interactiveOneOfTopK-technical.pdf
[35] Min Xie, Tianwen Chen, and Raymond Chi-Wing Wong. 2019. FindYourFavorite: An Interactive System for Finding the User’s Favorite Tuple in the Database. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 2017–2020.
[36] Min Xie, Raymond Chi-Wing Wong, and Ashwin Lall. 2019. Strongly Truthful Interactive Regret Minimization. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 281–298.
[37] Min Xie, Raymond Chi-Wing Wong, and Ashwin Lall. 2020. An experimental survey of regret minimization query and variants: bridging the best worlds between top-k query and skyline query. VLDB Journal 29, 1 (2020), 147–175.
[38] Min Xie, Raymond Chi-Wing Wong, Jian Li, Cheng Long, and Ashwin Lall. Efficient K-Regret Query Algorithm with Restriction-Free Bound for Any Dimensionality. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, New York, NY, USA, 959–974.
[39] Min Xie, Raymond Chi-Wing Wong, Peng Peng, and Vassilis J. Tsotras. 2020. Being Happy with the Least: Achieving 𝛼-happiness with Minimum Number of Tuples. In Proceedings of the International Conference on Data Engineering. 1009–1020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号